Python 基于 OpenCV 视觉图像处理实战 之 背景知识
目录
Python 基于 OpenCV 视觉图像处理实战 之 背景知识
一、简单介绍
二、人工智能(Artificial Intelligence,AI)
三、OpenCV
四、计算机视觉任务的主要类型
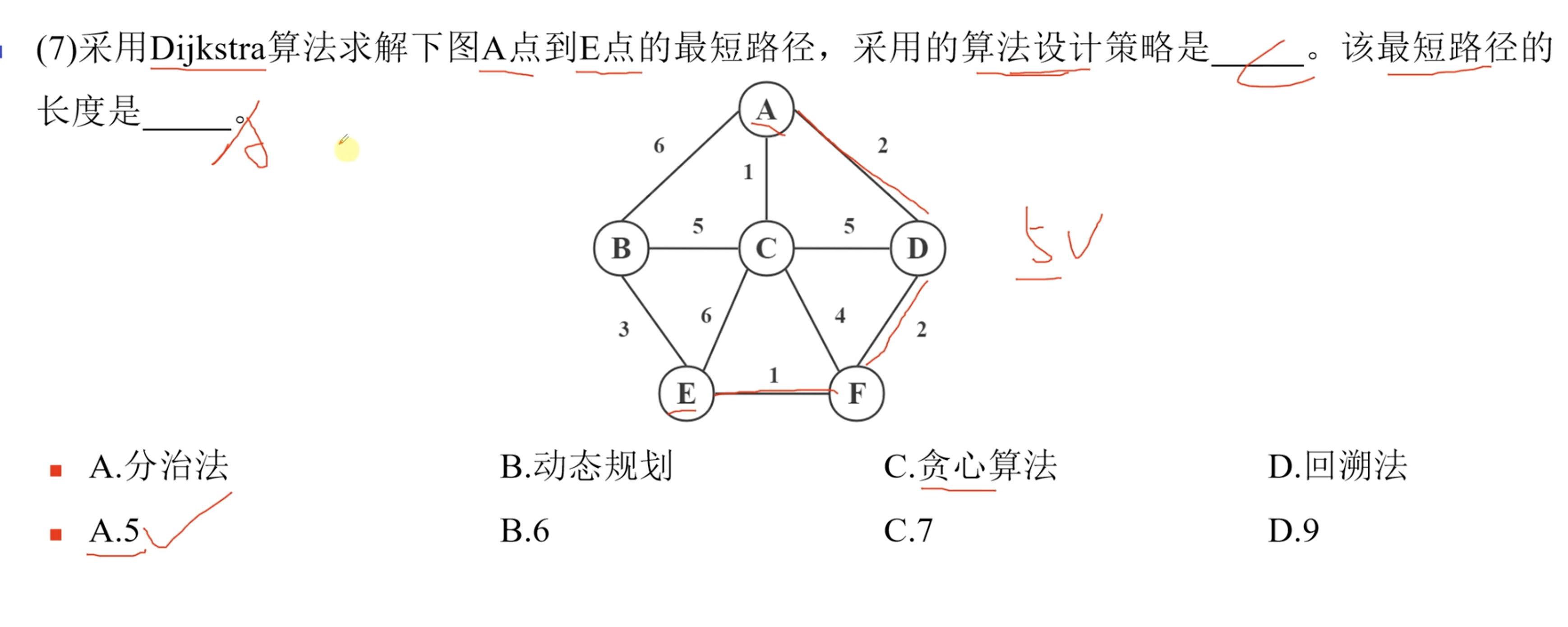
五、计算机视觉是通过创建人工模型来模拟本该由人类执行的视觉任务。
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
这里使用 Python 基于 OpenCV 进行视觉图像处理,......
二、人工智能(Artificial Intelligence,AI)
人工智能(Artificial Intelligence,AI)的定义,百度百科是这样解释的:
它是一门研究和开发用于模拟和拓展人类智能的理论方法和技术手段的新兴科学技术。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,其理论和技术日益成熟,应用领域也不断扩大,可以设想,未来,人工智能带来的科技产品将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程进行模拟。人工智能不是人的智能,但能像人那样思考,也可能超过人的智能。
三、OpenCV
OpenCV 是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。 它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
OpenCV用C++语言编写,它具有C ++,Python,Java和MATLAB接口,并支持Windows,Linux,Android和Mac OS,OpenCV主要倾向于实时视觉应用,并在可用时利用MMX和SSE指令, 如今也提供对于C#、Ch、Ruby,GO的支持。
OpenCV提供的视觉处理算法非常丰富,并且它部分以C语言编写,加上其开源的特性,处理得当,不需要添加新的外部支持也可以完整的编译链接生成执行程序,所以很多人用它来做算法的移植,OpenCV的代码经过适当改写可以正常的运行在DSP系统和ARM嵌入式系统中,这种移植在大学中经常作为相关专业本科生毕业设计或者研究生课题的选题。
2022年12月8日,龙芯中科宣布,近期,OpenCV 开源社区正式合入了对 LoongArch 架构支持的代码,基于龙架构自主指令系统,优化后的 OpenCV 性能显著提升。
为什么有OpenCV,它有什么优势
计算机视觉市场巨大而且持续增长,且这方面没有标准API,如今的计算机视觉软件大概有以下三种:
1、研究代码(慢,不稳定,独立并与其他库不兼容)
2、耗费很高的商业化工具(比如Halcon, MATLAB+Simulink)
3、依赖硬件的一些特别的解决方案(比如视频监控,制造控制系统,医疗设备)这是如今的现状,而标准的API将简化计算机视觉程序和解决方案的开发,OpenCV致力于成为这样的标准API。
OpenCV致力于真实世界的实时应用,通过优化的C代码的编写对其执行速度带来了可观的提升,并且可以通过购买Intel的IPP高性能多媒体函数库(Integrated Performance Primitives)得到更快的处理速度。图1为OpenCV与当前其他主流视觉函数库的性能比较。
四、计算机视觉任务的主要类型
计算机视觉的主要任务就是通过对采集的图片或视频进行处理以获得相应场景的信息。
1.物体检测
物体检测是视觉感知的第一步,也是计算机视觉的一个重要分支。物体检测的目标就是用框去标出物体的位置,并给出物体的类别。
物体检测和图像分类不一样,检测侧重于物体的搜索,而且物体检测的目标必须要有固定的形状和轮廓。图像分类可以是任意目标,这个目标可能是物体,也可能是一些属性或者场景。
2.物体识别(狭义)
计算机视觉的经典问题便是判定一组图像数据中是否包含某个特定的物体、图像特征或运动状态。这一问题通常可以通过机器自动解决,但是到目前为止,还没有哪个单一的方法能够广泛地对各种情况进行判定:在任意环境中识别任意物体。
现有技术能够很好地解决特定目标的识别,比如简单几何图形的识别、人脸识别、印刷或手写文件识别和车辆识别。而且这些识别需要在特定的环境中,具有指定的光照、背景和目标姿态等要求。
3.图像分类
一张图像中是否包含某种物体,以及对图像进行特征描述,是物体分类的主要研究内容。一般来说,物体分类算法通过手工特征或者特征学习方法对整个图像进行全局描述,然后使用分类器判断是否存在某类物体。
图像分类问题就是给输入的图像分配标签的任务,这是计算机视觉的核心问题之一。这个过程往往与机器学习和深度学习不可分割。
4.物体定位
如果说图像识别解决的是What的问题,那么物体定位解决的则是Where的问题。利用计算视觉技术找到图像中某一目标物体在图像中的位置,即定位。
目标物体的定位对于计算机视觉在安防、自动驾驶等领域的应用有着至关重要的意义。
5.图像分割
在图像处理过程中,有时需要对图像进行分割,从中提取出有价值的用于后续处理的部分,例如筛选特征点,或者分割一幅或多幅图片中含有特定目标的部分等。
图像分割指的是将数字图像细分为多个图像子区域(像素的集合,也被称为超像素)的过程。图像分割的目的是简化或改变图像的表示形式,使图像更容易被理解和分析。更精确地说,图像分割是对图像中的每个像素添加标签的一个过程,这一过程使得具有相同标签的像素具有某种共同的视觉特性。
“图像语意分割”是一个像素级别的物体识别,即每个像素点都要判断它的类别。它和物体检测的本质区别是,物体检测是一个物体级别的,它只需要一个框去框住物体的位置;而分割通常比检测更复杂。
五、计算机视觉是通过创建人工模型来模拟本该由人类执行的视觉任务。
其本质是模拟人类的感知与观察的过程。这个过程不仅是识别,而且还包含了一系列其他过程,并且最终是可以在人工系统中被理解和实现的。