简介
ControlNet旨在控制预训练的大型扩散模型,以支持额外的输入条件。ControlNet能够以端到端的方式学习特定任务的条件,即使在训练数据集很小的情况下(<50k),也能保持稳健性。此外,训练ControlNet的速度与微调扩散模型一样快,并且该模型可在个人设备上进行训练。同时,如果有强大的计算集群可用,模型可以扩展到大规模数据(从百万到数十亿)。研究结果显示,像Stable Diffusion这样的大型扩散模型可以通过ControlNet进行增强,从而实现对边缘图、分割图、关键点等条件输入的控制。这一进展可能会丰富这些方法,进而提高对大型扩散模型的控制能力,并促进相关应用的发展。
1.概述
随着大型文本到图像模型的出现,作者发现通过仅提供用户输入的简短描述性prompt就可以生成视觉上具有吸引力的图像。然而,这引发了一系列问题:
-
基于prompt的控制方式是否足够满足需求?
需要评估基于prompt的控制方式是否能够准确地满足用户需求,并在各种情境下保持灵活性和可控性。 -
大型模型在特定任务上的应用性如何?
大型模型是否适用于解决具有明确问题定义的长期存在的图像处理任务?特别是考虑到许多特定任务领域的数据规模可能较小,这需要研究鲁棒的训练方法以避免过拟合,并确保模型的泛化能力。 -
构建何种框架来处理广泛的问题条件和用户控制?
需要设计一种框架,能够处理各种形式的问题条件和用户控制,以实现对图像生成过程的更精细控制。这可能需要结合手工制作的规则和端到端学习方法。
这些问题的解决需要对图像处理应用程序进行调查,并在实践中得出结论。同时,也需要考虑到在特定任务中,大型模型如何保持其从数十亿图像中获得的优势和功能,并相应地调整我们的方法。
作者提出了一种名为ControlNet的端到端神经网络架构,用于控制大型图像扩散模型,以学习特定任务的输入条件。ControlNet通过将大型扩散模型的权重分为“可训练副本”和“锁定副本”来实现控制。锁定副本保留了从数十亿张图像中学习到的网络能力,而可训练副本在特定任务的数据集上进行训练,以学习条件控制。这两个副本通过一种名为“零卷积”的独特类型的卷积层相连接,其中卷积权值逐渐从零增长到优化参数,这保证了训练的鲁棒性。由于零卷积不会向深度特征添加新的噪声,因此与从头开始训练新的层相比,ControlNet的训练速度与微调一个扩散模型相当快。
作者在不同条件下使用各种数据集对多个ControlNets进行了训练,如Canny边缘、霍夫线、用户涂鸦、人体关键点、分割图、形状法线和深度图等。实验包括使用小数据集(样本小于50k甚至1k)和大数据集(数百万个样本)。结果表明,在一些任务中,例如从深度到图像的转换,在个人电脑上使用ControlNets进行训练,可以获得与在具有大规模计算资源的商业模型相竞争的结果,而不需要大型计算集群的支持。
2. 算法相关工作
2.1.HyperNetwork与神经网络架构
HyperNetwork起源于一种神经语言处理方法,其思想是通过训练一个较小的循环神经网络(RNN)来影响一个较大的神经网络的权值。这种方法在图像生成和其他机器学习任务上也取得了成功。受到这些想法的启发,一些研究提出了一种方法,将一个较小的神经网络连接到Stable Diffusion上,以改变其生成图像的艺术风格。随着HyperNetwork预训练权重的提供,这种方法变得更加受欢迎。
与此类似,ControlNet和HyperNetwork在影响神经网络行为方面有一些相似之处。ControlNet通过使用特殊类型的卷积层,即“零卷积”,来实现对大型图像扩散模型的控制。早期的神经网络研究已经广泛讨论了网络权值的初始化,包括用高斯分布初始化权值的合理性,以及用零初始化权值可能产生的风险。最近的一些研究也讨论了在神经网络中对初始卷积权值进行操作的方法,其中一些与零卷积的想法相似。这些研究表明,在训练神经网络时,对于权重的初始化和处理可以起到重要的作用,这与ControlNet和HyperNetwork的思想密切相关。
2.2.扩散概率模型
在扩散概率模型(DPM)中,图像生成的成功结果首先是在小规模数据集上训练测试,随后在相对较大规模数据集上进行了训练测试。这种体系结构通过重要的训练和采样方法得到了改进,例如去噪扩散概率模型(DDPM)、去噪扩散隐式模型(DDIM)和基于分数的扩散。
图像扩散方法可以直接使用像素颜色作为训练数据。在处理高分辨率图像时,研究人员经常考虑节省计算资源的策略,或直接使用基于金字塔或多阶段的方法。这些方法通常使用U-net作为神经网络结构。
为了降低训练扩散模型所需的计算资源,一种基于潜在图像的思想被提出,即潜在扩散模型(LDM)。进一步地,这个方法发展成了Stable Diffusion。
2.3.文本到图像扩散
扩散模型在文本到图像生成任务中取得了重要进展,实现了最先进的图像生成结果。通常,这是通过使用预训练的语言模型(例如CLIP)将文本输入编码为潜在向量来实现的。
例如,GLIDE是一个文本引导的扩散模型,支持图像生成和编辑。Disco Diffusion是一个CLIP引导的扩散模型的实现,用于处理文本提示。而Stable Diffusion是潜在扩散的一个大规模实现,用于实现文本到图像的生成任务。
另外,Imagen是一种不使用潜在图像的文本到图像生成架构,而是直接在像素级别上使用金字塔结构进行扩散。这些方法为文本到图像生成任务提供了多样化的选择,各自在不同方面具有优势和特点。
2.4. 个性化,定制化,以及预训练扩散模型的控制
目前最前沿的图像扩散模型主要由文本到图像的方法主导,因此增强对扩散模型的控制的最直接方法通常是文本引导的。这种类型的控制也可以通过操纵CLIP特性来实现。图像扩散过程本身也可以提供一些功能,以实现颜色水平的细节变化(Stable Diffusion社区称之为img2img)。图像扩散算法天然支持将修补(inpainting)作为控制结果的重要方式。此外,文本反转和DreamBooth被提出用于使用具有相同主题或对象的一小组图像对生成结果中的内容进行自定义或个性化。
2.5. 图像到图像转换
尽管ControlNet和图像到图像转换可能有几个重叠的应用,但它们的动机本质上是不同的。图像到图像转换的目标是学习不同域图像之间的映射,而ControlNet的目标是使用特定任务条件来控制扩散模型。
Pix2Pix提出了图像到图像转换的概念,早期的方法以条件生成神经网络为主。随着Transformer和视觉Transformer(ViTs)的普及,使用自回归方法获得了成功的结果。一些研究还表明,多模态方法可以从各种翻译任务中学习一个鲁棒的生成器。
在图像到图像转换领域,ControlNet讨论了一些当前最强大的方法。Taming Transformer是一种视觉Transformer,既能生成图像,又能执行图像到图像的转换。Palette是一个统一的基于扩散的图像到图像转换框架。PITI是一种基于扩散的图像到图像的转换方法,它利用大规模的预训练来提高生成结果的质量。在特定领域,例如草图引导扩散,Sketch-guided text-to-image diffusion models是一种基于优化的方法,用于操纵扩散过程。这些方法都经过了实验验证。
3.实现方法
3.1 模型设计

ControlNet的输入与原始的Stable Diffusion(SD)相同,包括噪声潜变量(noisy latents)、时间嵌入(time embedding)和文本嵌入(text embedding)。除此之外,ControlNet还引入了额外的条件(condition),这个条件是与原始图像大小相同的图像,例如Canny边界图或人体骨架图。与SD不同的是,ControlNet并不使用VAE对条件进行编码,而是直接采用一个小的卷积网络来提取条件的特征,并将这些特征加在经过第一个卷积层处理后的噪声潜变量上。由于经过VAE编码后的潜变量分辨率降低了8倍,因此这个小卷积网络需要将条件进行8倍下采样,并输出与噪声潜变量相同维度的特征(对于SD 1.5,512x512的输入特征维度是64x64x320)。下面是这个小卷积网络的结构示意图,其中包含3个步长为2的卷积层用于下采样:
input_hint_block = TimestepEmbedSequential(
conv_nd(dims, hint_channels, 16, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 16, 16, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 16, 32, 3, padding=1, stride=2),
nn.SiLU(),
conv_nd(dims, 32, 32, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 32, 96, 3, padding=1, stride=2),
nn.SiLU(),
conv_nd(dims, 96, 96, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 96, 256, 3, padding=1, stride=2),
nn.SiLU(),
zero_module(conv_nd(dims, 256, model_channels, 3, padding=1))
)
ControlNet没有采用VAE而是重新设计了一个小型卷积网络来编码条件图像,可能是因为条件图像通常相对简单,如Canny边缘图,使用小型卷积网络提取特征已经足够。此外,采用VAE编码可能会引入信息损失,因为它需要对条件图像进行压缩表示,而这种表示可能不够精确或丰富。
另一个重要的设计考虑是如何将ControlNet中提取的特征嵌入原始Stable Diffusion(SD)的UNet中。这里借鉴了UNet中skip connection的设计,即在UNet的Encoder中的中间输出特征以跳连的方式连接到Decoder中。对于SD 1.5,UNet的Encoder包含4个阶段,每个阶段包含2个blocks,前三个阶段的blocks由ResBlock和Attention Block组成,最后一个阶段的block仅为ResBlock且没有Down操作。UNet的Decoder也包含4个阶段,但每个阶段包含3个blocks,所以与Encoder有些不对称。每个UNet的Encoder阶段的第一个Conv层的输出、每个block的输出以及每个Down操作的输出将以skip connection的方式连接到Decoder中对应的block中(以concat的方式)。如果输入是512x512图像,那么UNet的Decoder将产生64x64、32x32、16x16和8x8尺度的特征各3个,与Encoder的skip connection数对应,这样设计可以有效地传递特征信息并保持尺度一致性。
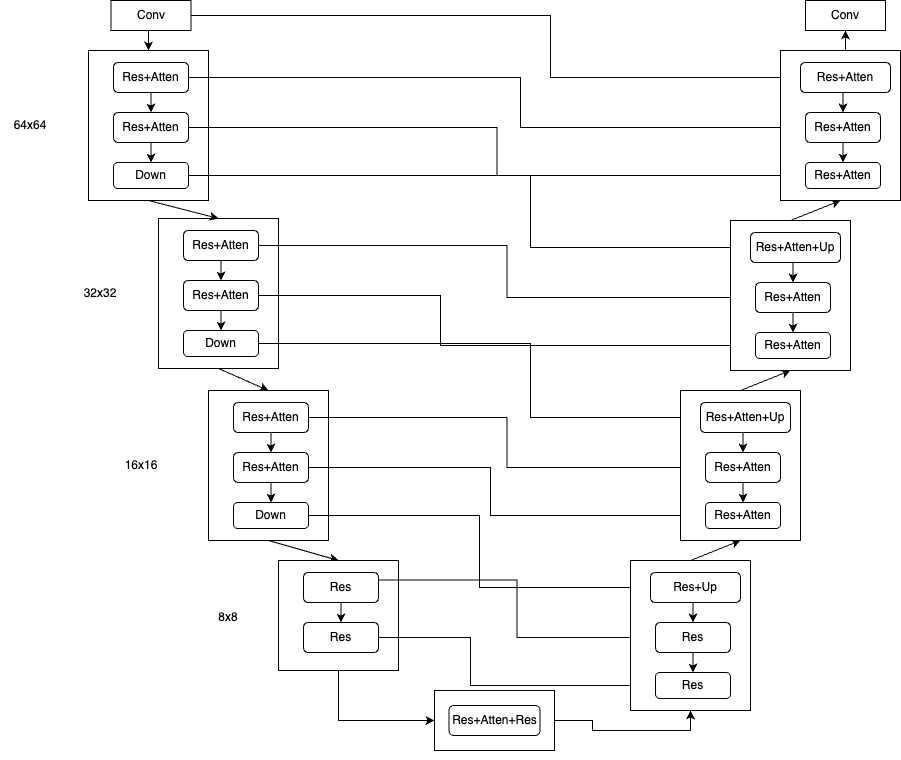
ControlNet复制了UNet的Encoder结构,并因此可以提取出与原始UNet相同数量的特征,即12个特征。这些特征可以与原始UNet的Encoder相应的12个特征输出进行连接,以skip connection的方式嵌入到UNet的Decoder中。此外,由于ControlNet还包括一个额外的Middle Block,因此还会产生一个额外的特征。因此,ControlNet共产生了13个skip connection,使得它能够更好地利用来自不同层次的特征信息,并更好地适应不同尺度的输入图像。
class ControlledUnetModel(UNetModel):
def forward(self, x, timesteps=None, context=None, control=None, only_mid_control=False, **kwargs):
hs = []
with torch.no_grad():
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
emb = self.time_embed(t_emb)
h = x.type(self.dtype)
for module in self.input_blocks:
h = module(h, emb, context)
hs.append(h)
h = self.middle_block(h, emb, context)
# hs是SD UNet encoder产生的12个skip connection
# control是ControlNet产生的13个skip connection
if control is not None:
h += control.pop() # controlnet mid block skip connection
for i, module in enumerate(self.output_blocks):
if only_mid_control or control is None:
h = torch.cat([h, hs.pop()], dim=1)
else:
# 将controlnet的skip connection加在UNet encoder对应的skip connection
h = torch.cat([h, hs.pop() + control.pop()], dim=1)
h = module(h, emb, context)
h = h.type(x.dtype)
return self.out(h)
ControlNet复制了UNet结构,并且继承了UNet的权重来进行初始化。此外,ControlNet还采用了zero初始化策略。在condition的特征输出后加入了一个zero conv层,同时在13个skip connection的特征输出上也分别加上了一个zero conv层。通过zero初始化,整个网络在训练开始时的输出与原始UNet相同,这有助于尽量减少初始训练时噪音对ControlNet复制结构和权重的影响。这样的设计能够提高ControlNet的稳定性,并使其更好地适应于特定任务的训练过程。