计算存储分离已经成为云计算的一种发展趋势。在计算存储分离之前,普遍采用的是传统的计算存储相互融合的架构,但是这种架构存在一定的问题,比如在集群扩容的时候会面临计算能力和存储能力相互不匹配的问题。用户在某些情况下只需要扩容计算能力或者存储能力,而传统的融合架构不能满足用户的这种需求,进行单独的扩充计算或者存储能力;其次在缩容的时候可能会遇到人工干预,人工干预完后需要保证数据在多个节点中同步,而当有多个副本需要同步时候,可能会造成的数据丢失。而计算存储分离架构则可以很好的解决这些问题,使得用户只需要关心整个集群的计算能力。
1 Alluxio
Alluxio支持在任何云中进行计算的数据编排,统一了本地和跨任何云的数据孤岛,为您提供所需的数据本地性、可访问性和弹性,以降低为当今大数据和 AI/ML 工作负载编排数据相关的复杂性。

统一的数据编排层:抽象的数据层为数据分析和AI提供统一的数据访问接口
高效的数据访问 & 便捷的数据管理:定制化数据策略,提供完整的数据呈现、加速数据访问
异构环境的支持:实现跨数据中心、跨云等异构体系敏捷数据集成和编排
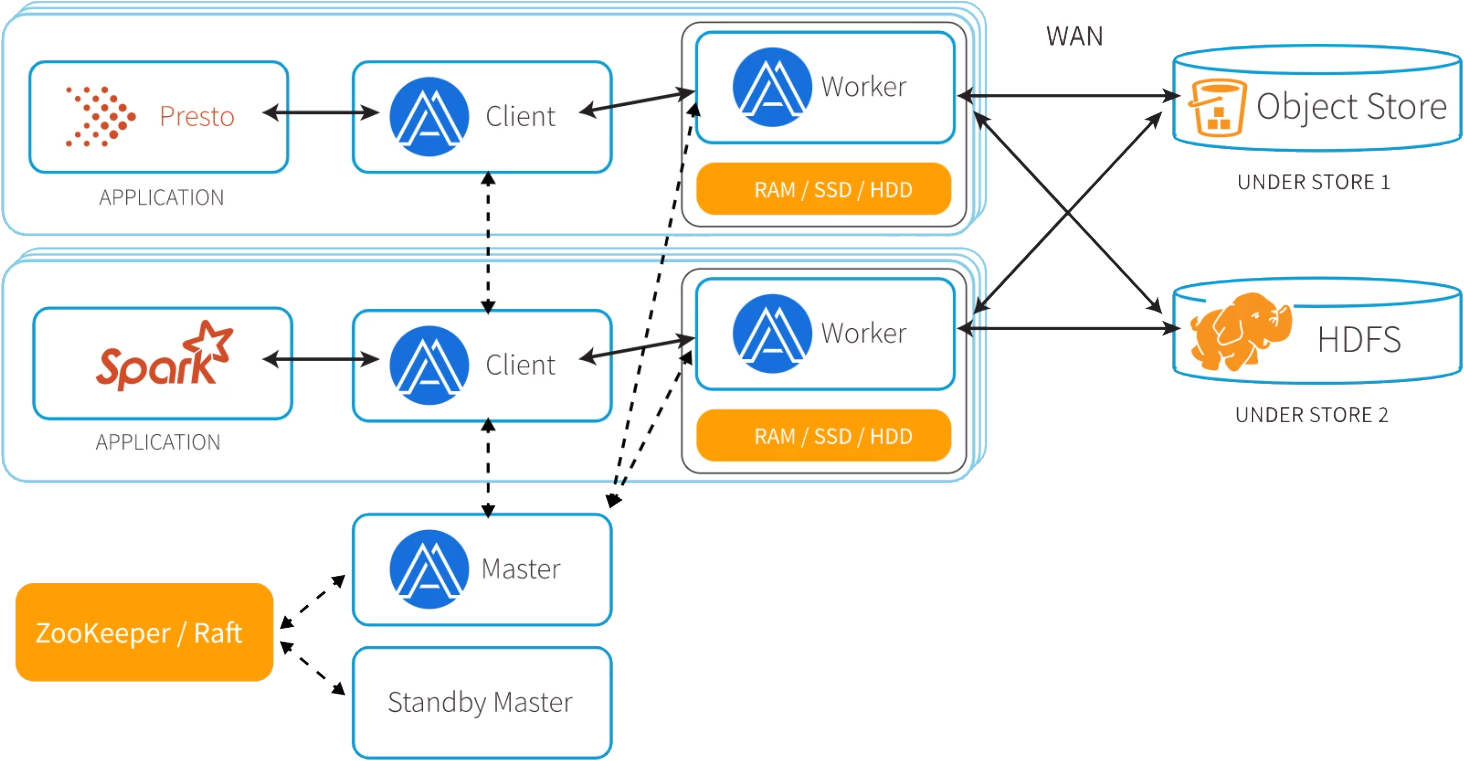
说明:
Alluxio并不改变文件组织方式,只是通过缓存加速数据数据访问。
2 Juicefs
JuiceFS 是一款面向云原生设计的高性能分布式文件系统,在 Apache 2.0 开源协议下发布。提供完备的 POSIX 兼容性,可将几乎所有对象存储接入本地作为海量本地磁盘使用,亦可同时在跨平台、跨地区的不同主机上挂载读写。
JuiceFS 采用「数据」与「元数据」分离存储的架构,从而实现文件系统的分布式设计。文件数据本身会被切分保存在对象存储(例如 Amazon S3),而元数据则可以保存在 Redis、MySQL、TiKV、SQLite 等多种数据库中,你可以根据场景与性能要求进行选择。
JuiceFS 提供了丰富的 API,适用于各种形式数据的管理、分析、归档、备份,可以在不修改代码的前提下无缝对接大数据、机器学习、人工智能等应用平台,为其提供海量、弹性、低价的高性能存储。运维人员不用再为可用性、灾难恢复、监控、扩容等工作烦恼,专注于业务开发,提升研发效率。同时运维细节的简化,对 DevOps 极其友好。
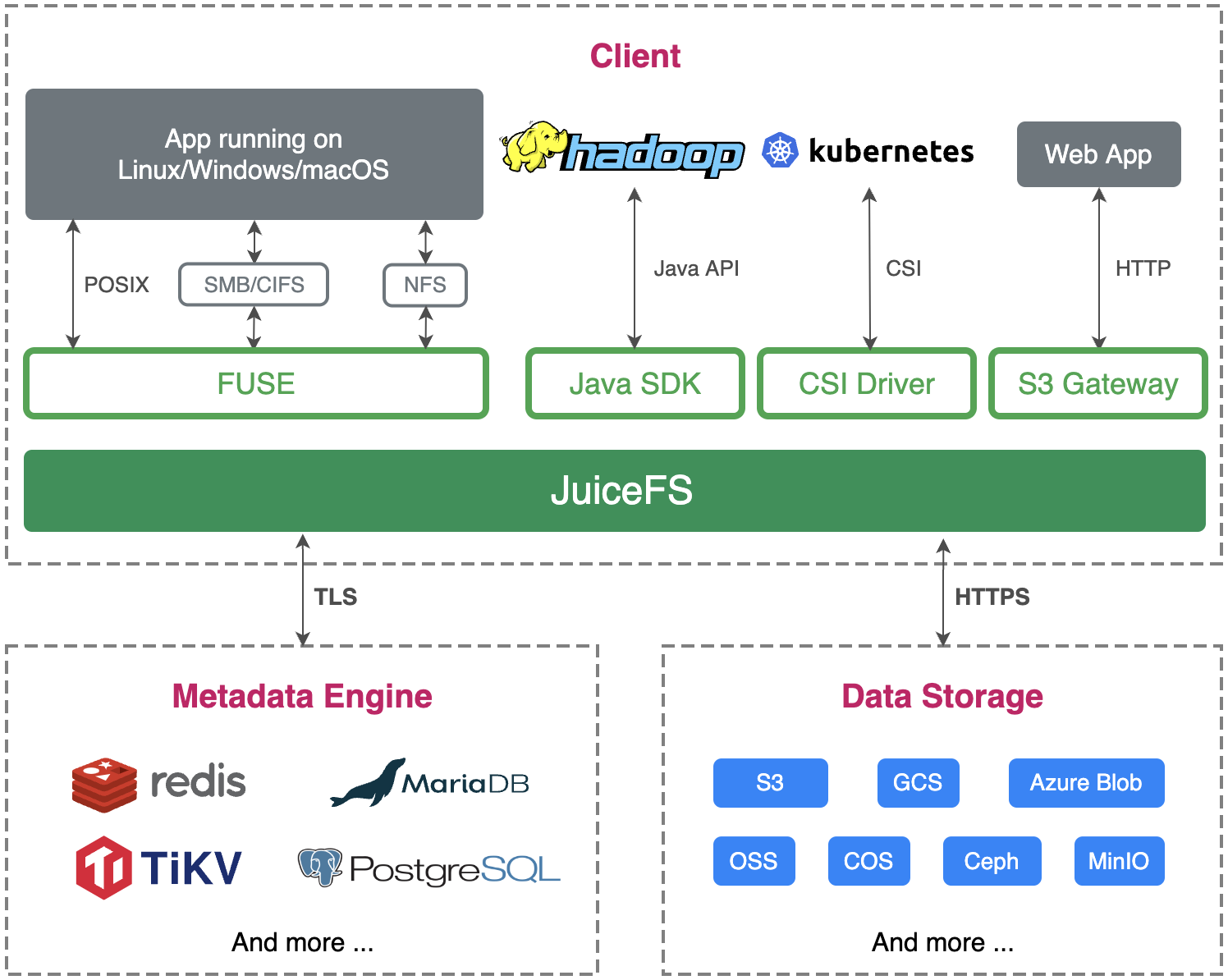
核心特性:
POSIX 兼容:像本地文件系统一样使用,无缝对接已有应用,无业务侵入性;
HDFS 兼容:完整兼容 HDFS API,提供更强的元数据性能;
S3 兼容:提供 S3 网关 实现 S3 协议兼容的访问接口;
云原生:通过 Kubernetes CSI 驱动 轻松地在 Kubernetes 中使用 JuiceFS;
分布式设计:同一文件系统可在上千台服务器同时挂载,高性能并发读写,共享数据;
强一致性:确认的文件修改会在所有服务器上立即可见,保证强一致性;
强悍性能:毫秒级延迟,近乎无限的吞吐量(取决于对象存储规模),查看性能测试结果;
数据安全:支持传输中加密(encryption in transit)和静态加密(encryption at rest),查看详情;
文件锁:支持 BSD 锁(flock)和 POSIX 锁(fcntl);
数据压缩:支持 LZ4 和 Zstandard 压缩算法,节省存储空间。
说明:
JuiceFS 基于采用「数据」与「元数据」分离存储的架构,从而实现文件系统的分布式设计。文件数据本身会被切分保存在对象存储(例如 Amazon S3),而元数据则可以保存在 Redis、MySQL、TiKV、SQLite 等多种数据库中。
3 腾讯云GooseFS
数据湖加速器(Data Lake Accelerator Goose FileSystem,GooseFS),是由腾讯云推出的高可靠、高可用、弹性的数据湖加速服务。依靠对象存储(Cloud Object Storage,COS)作为数据湖存储底座的成本优势,为数据湖生态中的计算应用提供统一的数据湖入口,加速海量数据分析、机器学习、人工智能等业务访问存储的性能;采用了分布式集群架构,具备弹性、高可靠、高可用等特性,为上层计算应用提供统一的命名空间和访问协议,方便用户在不同的存储系统管理和流转数据。
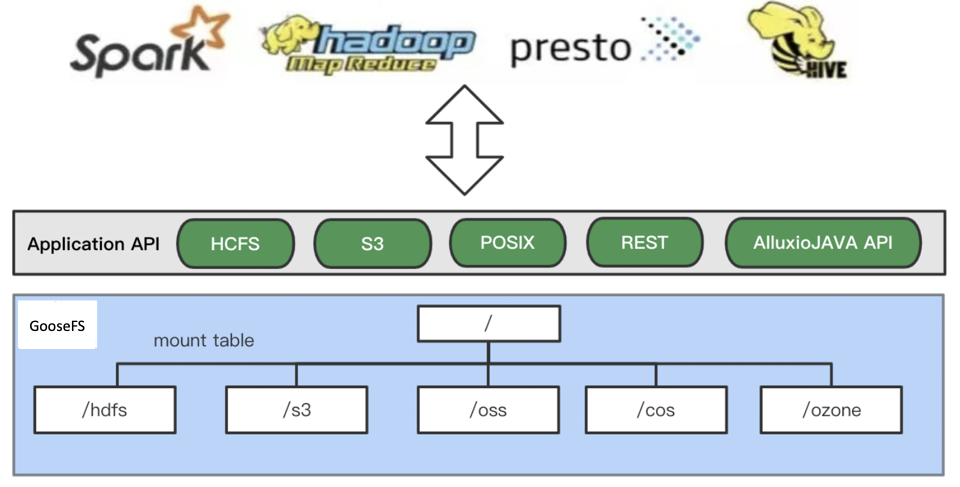
GooseFS 提供了以下功能:
- 缓存加速和数据本地化(Locality):GooseFS 可以与计算节点混合部署提高数据本地性,利用高速缓存功能解决存储性能问题,提高写入 COS 的带宽。
- 融合存储语义:GooseFS 提供 UFS(Unified FileSystem)的语义,可以支持 COS、Hadoop、S3、K8S CSI、 FUSE 等多个存储语义,使用于多种生态和应用场景。
- 统一的腾讯云相关生态服务:包括日志、鉴权、监控,实现了与 COS 操作统一。
- 提供 Namespace 管理能力,针对不同业务、不同的Under File System,提供不同的读写缓存策略以及生命周期(TTL)管理。
- 感知 Table 元数据功能:对于大数据场景下数据 Table,提供 GooseFS Catalog 用于感知元数据 Table ,提供 Table 级别的 Cache 预热。
说明:
GooseFS 基于开源 Alluxio 的架构,提供强大的分布式 Cache 能力,能够帮助用户统一跨各种平台用户数据的同时,还有助于为用户提升总体 I/O 吞吐量。
4 阿里云jindoData
JindoData 是阿里云开源大数据团队自研的数据湖存储加速套件,面向大数据和 AI 生态,为阿里云和业界主要数据湖存储系统提供全方位访问加速解决方案。JindoData 套件基于统一架构和内核实现,主要包括 JindoFS 存储系统(原 JindoFS Block 模式),JindoFSx 存储加速系统(原 JindoFS Cache 模式),JindoSDK 大数据万能 SDK 和全面兼容的生态工具(JindoFuse、JindoDistCp)、插件支持。
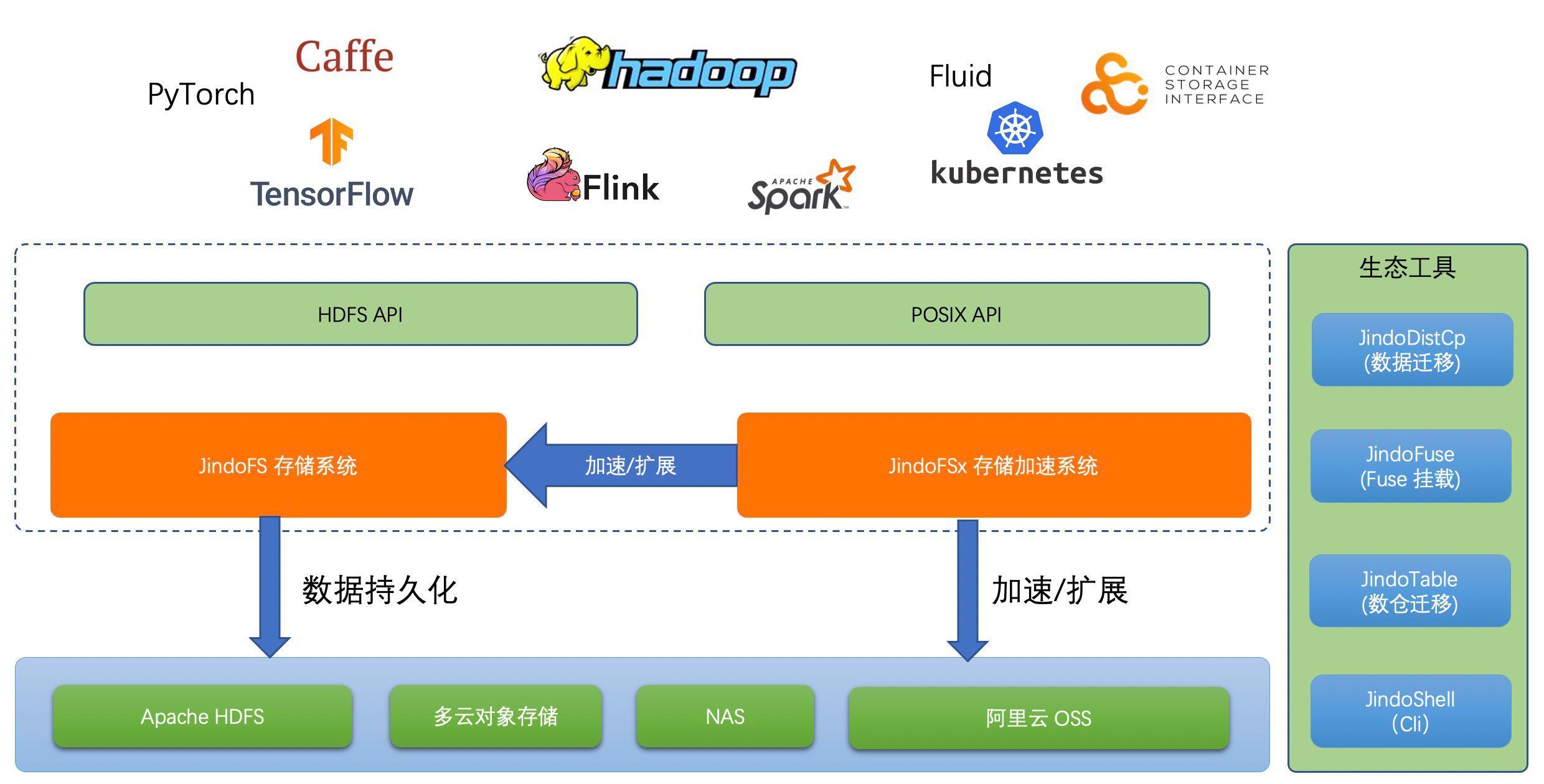
JindoFS 存储系统
基于阿里云 OSS 的云原生存储系统,二进制兼容 Apache HDFS,并且基本功能对齐,提供优化的 HDFS 使用和平迁体验。是原 JindoFS Block 模式的全新升级版本。 阿里云 OSS-HDFS 服务(JindoFS 服务) 是 JindoFS 存储系统在阿里云上的服务化部署形态,和阿里云 OSS 深度融合,开箱即用,无须在自建集群部署维护 JindoFS,免运维。
OSS-HDFS 服务具体介绍请参考 OSS-HDFS服务概述 。
JindoFSx 存储加速系统
JindoFSx(JindoData服务)是原JindoFS Cache模式的全新升级版本,是面向大数据和AI生态的云原生数据湖存储加速系统,为大数据和AI应用访问各种云存储提供访问加速,支持数据缓存、元数据缓存和P2P加速等功能。JindoFSx支持管理多个后端存储系统,可以通过统一命名空间进行管理,也可以兼容各系统原生的访问协议,也支持为这些系统提供统一的权限管理。原生优化支持阿里云OSS和阿里云OSS-HDFS服务,同时也支持业界多云对象存储(例如,Amazon S3)、 Apache HDFS和NAS。
生态支持和工具
- JindoSDK 支持。面向云时代的大数据 Hadoop SDK 和 HDFS 接口支持,内置优化访问阿里云 OSS,较 Hadoop 社区版本性能大幅提升;同时对接支持 JindoFS 存储系统包括服务、JindoFSx 存储加速系统;支持多云对象存储。
- JindoShell CLI 支持。JindoData 除了对接支持 Hadoop/HDFS shell 命令,同时提供一套 JindoShell CLI 命令,从功能、性能上大幅扩展和优化一些数据访问操作。
- JindoFuse POSIX 支持。JindoData 为阿里云 OSS、JindoFS 存储系统和服务、JindoFSx 存储加速系统提供的 POSIX 支持。
- JindoDistCp 数据迁移支持。IDC 机房数据(HDFS)上云迁移和多云迁移利器,支持多种存储数据迁移到阿里云 OSS 和 JindoFS 服务,使用上类似Hadoop DistCp。
- JindoTable 支持。结合计算引擎的使用推出的一套解决方案,支持 Spark、Hive、Presto 等引擎,以及表格式数据的管理功能。
- 生态插件。除了默认提供 JindoSDK 支持 Hadoop,另外还支持 Flink Connector 等插件。
说明:
JindoFS存储模式(Block),将JindoFS的文件切分的Block的形式存放本地磁盘以及OSS上,用户通过OSS只能看到Block的数据,该模式非常依赖于本地的Namespace的文件系统,本地的Namespace服务负责管理元数据,通过本地元数据以及Block数据构建出文件数据。
与Block模式不同的是,Cache模式将JindoFS文件以对象的形式存储在OSS上。该模式兼容现有的OSS文件系统,用户可以通过OSS访问原有的目录结构以及文件,同时该模式提供数据以及元数据的缓存,加速用户的读写数据的性能。
5 百度RapidFS
百度尚未形成专门的数据加速套件,而是通过一系列工具或其他产品的功能实现一套高性能存储解决方案——由大容量、高吞吐、低成本的存储底座,和更快的运行时存储 PFS、RapidFS 组成。
PFS是一个典型的并行文件系统,类似于业界的Lustre、GPFS,采用元数据和数据分离架构,物理网络可能是RDMA或高速 TCP。
数据湖存储加速工具(Data Lake Accelerator,RapidFS)是一款高可靠、高可用、弹性的数据湖存储加速工具。依靠对象存储BOS 作为数据湖存储底座,为数据湖生态中的计算应用提供统一数据湖入口,加速大数据、机器学习、人工智能等业务访问存储的性能。
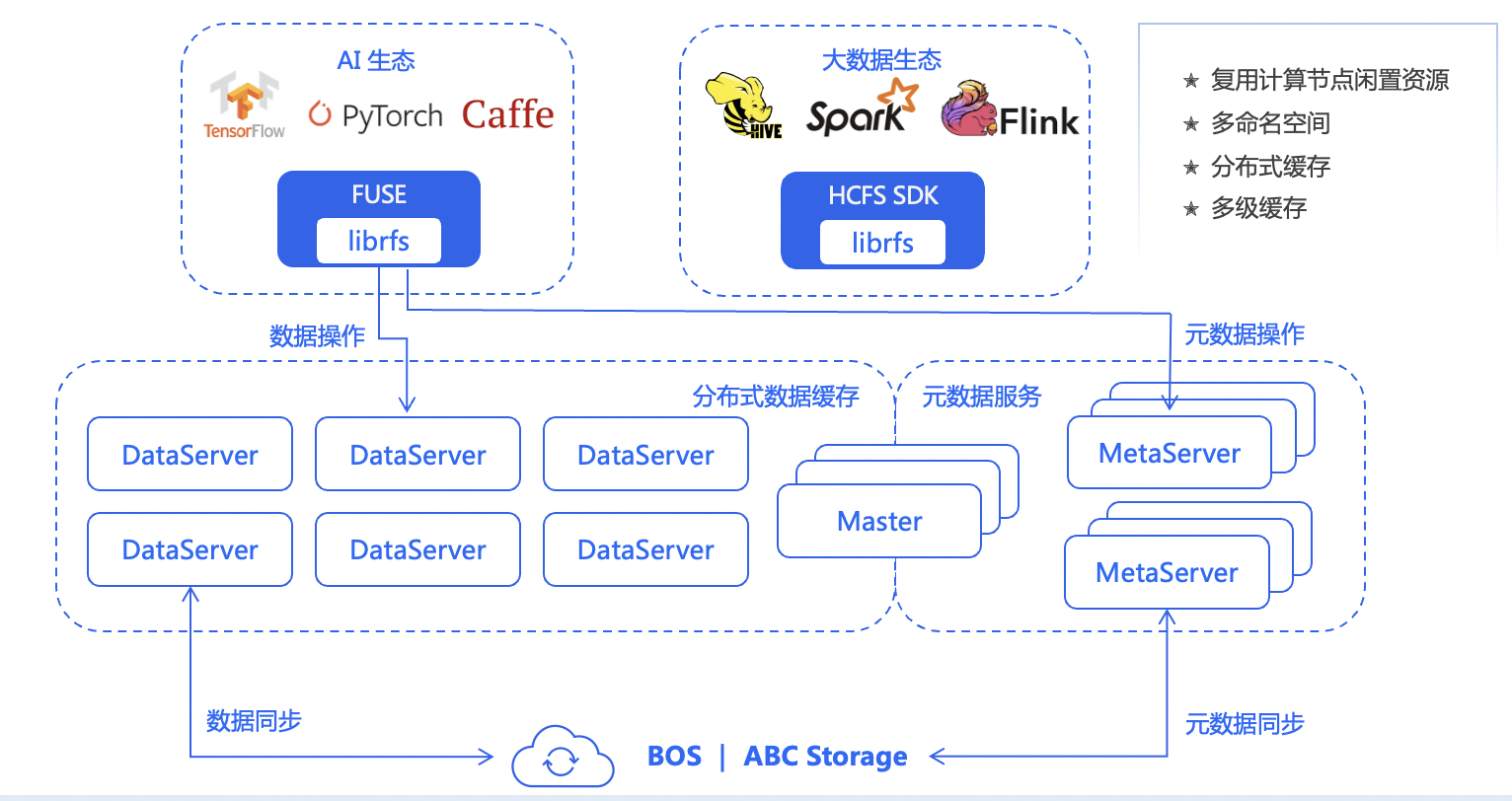
RapidFS的定位是一个缓存加速系统,原理是将用户计算节点上的冗余资源,组织成一个小的 P2P 缓存来加速计算。
RapidFS 加速的能力主要来自于两个方面:
- 第一个加速效果来自层级命名空间(namespace)的缓存——做 BOS 命名空间的缓存。
- 第二个加速效果来自数据缓存——针对于 BOS 上数据访问比较慢的问题,RapidFS 将比较热的数据缓存到用户提供的冗余内存和磁盘上面,这样等用户去访问的时候,访问路径很短。
基于这两类运行时存储如何实心数据流转,通过两种机制来满足的:
(1)RapidFS的生命周期机制:PFS可以通过生命周期的功能,把近期内不再使用的数据,自动地转移到对象存储里面,让用户能够把成本降下来,用户去访问的时候,PFS 又把数据自动地给加载回来。
(2)RapidFS的Bucket Link机制:以数据入口在对象存储,将PFS的一个目录或者RapidFS的一个命名空间,和对象存储里面的一个路径做一个绑定,绑定后,PFS 和RapidFS可以自动地帮用户完成数据的加载,以及数据的预热。
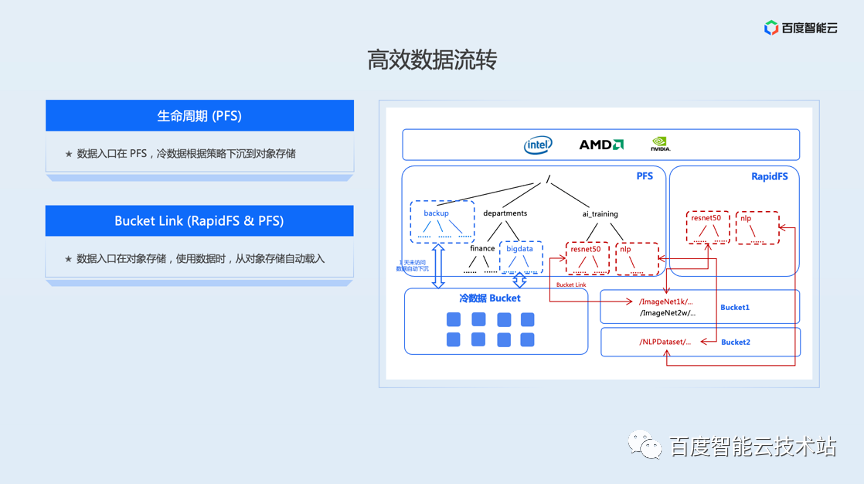
RapidFS后续将推出的Block模式,访问入口在 RapidFS,热数据缓存在计算节点本地,数据的持久化和冷数据由对象存储负责。
6 参考资料
https://github.com/qubole/rubix
Alluxio - Data Orchestration for the Cloud
https://github.com/Alluxio/alluxio
JuiceFS - Open Source Distributed POSIX File System for Cloud
https://github.com/juicedata/juicefs
https://github.com/aliyun/alibabacloud-jindodata
面向高性能计算场景的存储系统解决方案