文章目录
- 一、数据表结构相关优化
- 建字段类型注意事项
- 1. int类型的选择
- 2.varchar、char、text类型
- 3.date、datetime、timestamp类型
- 表规划
- 1. 垂直分表
- 2. 水平分表
- 二、查询语句优化
- 1.对于字段多的表,避免使用SELECT *
- 2.避免使用!=操作符
- 3.避免使用null做条件
- 4.like查询如何优化
- 5.在查询子句中避免使用函数操作
- 6.尽量避免在where子句中使用or
- 7.经量避免使用in或not in,因为这个也是属于or的操作
- 8.尽量避免在where子句中使用表达式,函数
- 9.尽量避免在大量重复数据的字段建立索引
- 10.联合索引
- 11.索引也是要适可而止
- 12.尽量避免使用临时表(create temporary table...select...)
- 13.尽量避免使用order by rand()
- 14.拆分大的 DELETE、INSERT、update语句
- 15.尽量避免客户端返回大数据量
- 16.避免使用大事务
- 17.避免使用查询缓存
- 三、数据库配置参数优化
- 2. innodb_buffer_pool_size innodb缓存空间优化(重要)
- 3. max_connections数据库最大并发连接数(重要)
- 4. 优化请求堆栈back_log(重要)
- 5. 修改连接超时时间wait_timeout(重要)
- 6. 修改并发线程数innodb_thread_concurrency
- 7. innodb_log_file_size redo日志大小优化
- 8. innodb_flush_log_at_trx_commit刷新redo日志配置
- 四、正确选择引擎
- 读多写少
- 写多读少
- 读多写多
- 五、数据库的问题如何分析
- 1. 先看错误日志
- 2. 开启慢查询日志
- 3. 如何通过数据库进程查看问题
- show full processlist
- show profile
- 4. explain工具的使用
- id
- select_type
- table
- type
- possible_keys
- key
- key_len
- Extra
- 六、表修复相关
- 1.数据表修复
- 2. 数据表空间优化
- innodb_file_per_table表空间的配置
- OPTIMIZE TABLE优化表空间
- 结语
一、数据表结构相关优化
建字段类型注意事项
1. int类型的选择
字段的容量存储尽可能小,这样子可以减少磁盘IO的开销,以提高数据表读写性能,提高索引的利用率。
在数据类型中,整型类型占用空间比较小是占4个字节,所以在理想状态下用整型来作为表字段类型是表结构最优的。在使用整型的时候也是有区别的,遵循一个原则,int类型也是越短越好。
- 像ip可以用int类型来代替varchar类型,可以用PHP函数ip2long可以把字符串转化成int类型。
- 像金额可以decimal类型来代替float,也可以用int来存储,以分为单位来存储金额。主要是为了精度精确
- 像状态值可以用tinyint类型来存储。
- 像订单号可以用bigint来存储
- 像int类型最好是设置成not null,然后默认值设置为0。因为像有些int类型字段要被当做索引来用,如果int类型出现null值导致索引失效
下面是int类型的存储结构图:
| 类型 | 含义说明(带符号的) |
|---|---|
| tinyint | 1字节,范围(-128~127) |
| smallint | 2字节,范围(-32768~32767) |
| mediumint | 3字节,范围(-8388608~8388607) |
| smallint | 3字节,范围(-8388608~8388607) |
| bigint | 8字节,范围(±9.22*10的18次方) |
2.varchar、char、text类型
在我们建表的时候,字符串类型使用频率最高的。主要是有varchar,char,text3种类型组成。按照查询速度:char的速度最快,varchar次之,text最慢。由于char类型的容量较小,并且是固定长度所以速度会比较快点。
- char类型最大长度是255个字符,默认是占用255 * 2个字节,如果是utf-8方式那么最多存储,255 * 3个字节。像手机号码,身份证号,带字母的订单号可以用char类型存储。
- varchar类型的长度是可变的,可以设置最大长度,大部分字符串类型都用它。注意现在mysql的版本对于utf-8字符也是按字符数来算,不是字节数。
- text类型,尽量少用,在做表读写操作时,其操作较慢,一般是存储大容量的字段内容,比如文章。
下面是int类型的存储结构表:
| 类型 | 含义说明 |
|---|---|
| char(n) | 固定长度,最多255个字符 |
| varchar(n) | 可变长度,最多65535个字符 |
| text | 可变长度,最多65535个字符 |
| mediumtext | 可变长度,最多2的24次方-1个字符 |
| longtext | 可变长度,最多2的32次方-1个字符 |
3.date、datetime、timestamp类型
日期、时间类型非字符串类型,这个是程序员最容易犯的错误。建议我们在设计时间类型相关的字段时候,建议用日期类型。
网上说时间用int类型的时间戳要优于日期类型,这其实在性能上相差不大,因为时间戳的int长度也较大,占用的字节数和日期相差不大。日期类型也是支持索引的。
- 像每日统计的数据在日期上展示的时候可以用date类型
- 像订单生成时间,支付时间,可以用datetime类型
- 像日志的生成时间,订单最后更新时间可以用timestamp类型
下面是int类型的存储结构图:
| 类型 | 含义说明 |
|---|---|
| date | 3字节,日期,格式:2017-09-18 |
| datetime | 8字节,日期时间,格式:2014-09-18 08:42:30 |
| timestamp | 4字节,自动存储记录修改的时间 |
补充
- 在表中添加字段时候,最好要not null;主要是null会增大表的占用容量,最主要的是带有null值的字段,加索引失效。
- 对于大容量表,不能取操作修改表,像加字段,添加索引等,一定要在业务空档期的时候加;利用percona toolkit工具里的
pt-online-schema-change命令 - 字段容量计算公式,比如int类型占4个字节,1字节=8位,4个字节就是32位,那么长度是从0开始到31,即最大值如果不带符号,20~231位,如果是带符号的是 -231~231。
表规划
1. 垂直分表
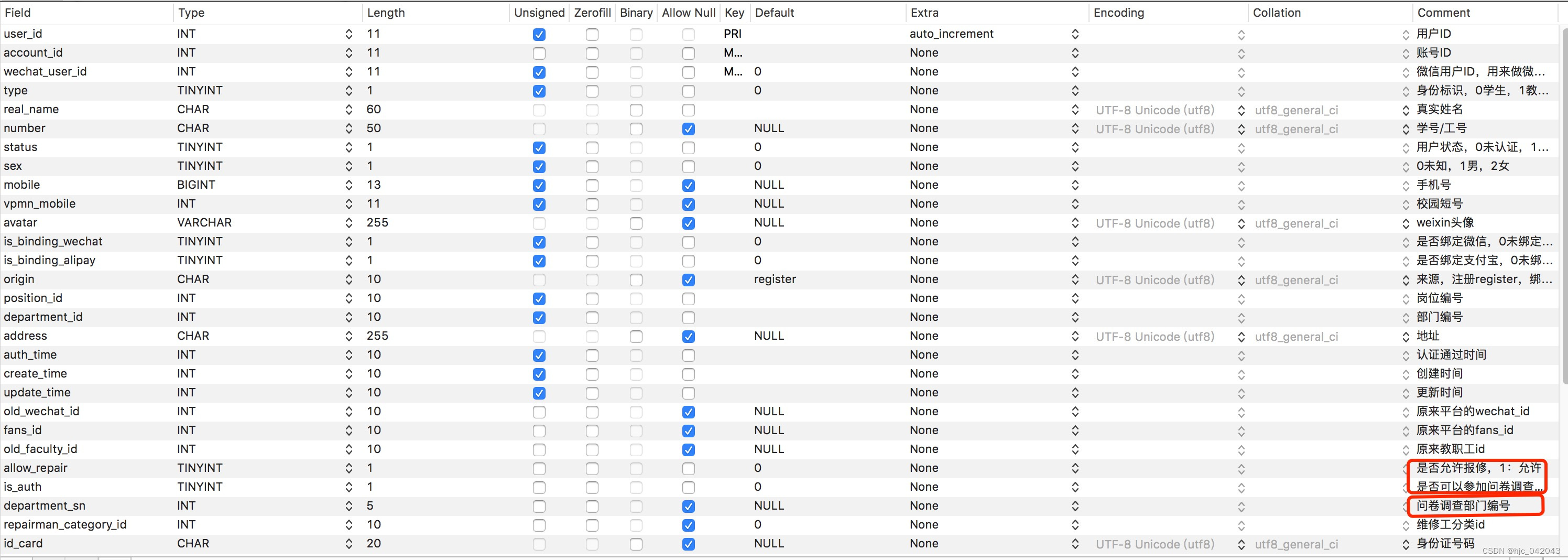
随着需求量的增大,我们表字段也会越来越多,性能也会越来越慢。反面教材就是我们的这个用户表。这个时候我们就需要拆表,垂直分表的原则是,动静分离,就是将频繁读写的字段单独建成一个表,一些不怎么变动的字段再单独建成一个表。
这样子可以提高数据库的性能。比如商品表,库存就应该单独建一个表,里面就存商品id,和对应的库存。在读、写操作的时候可以加快速度。
如下图,下面的某些字段不应该加在用户主表中
2. 水平分表
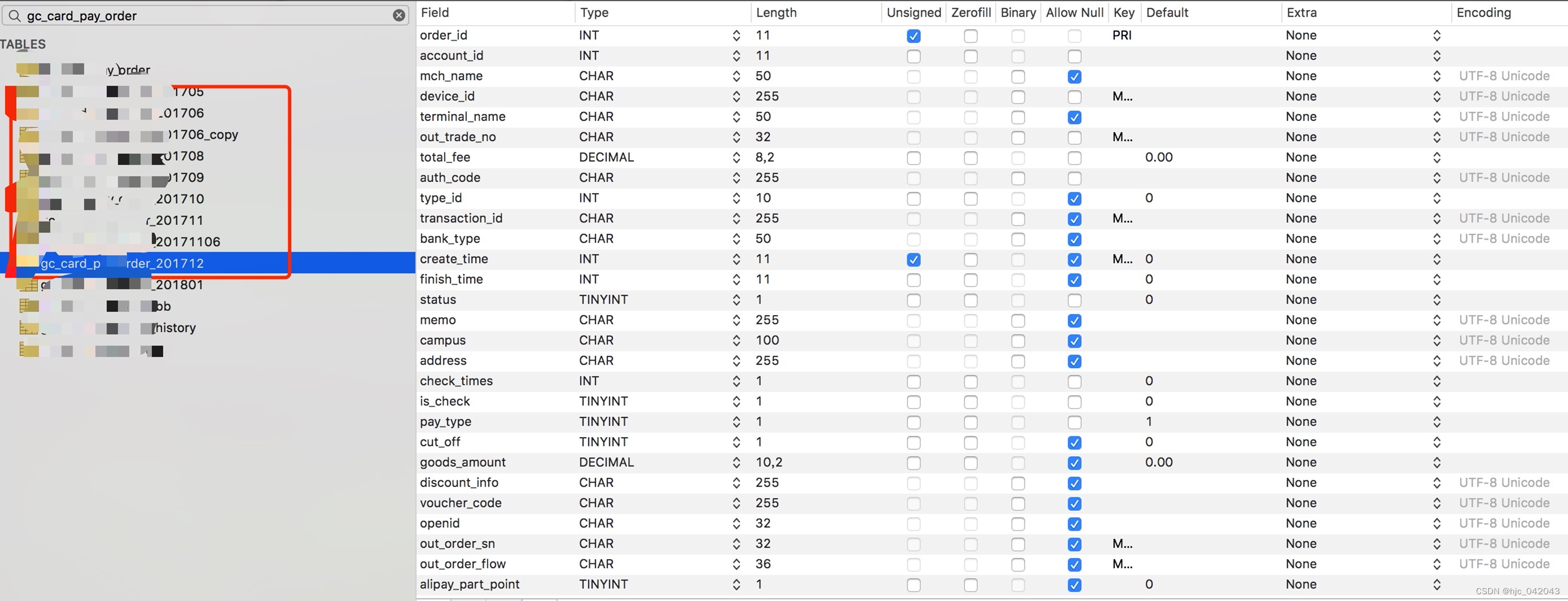
随着业务亮越来越多,数据量也随之疯长,单表的磁盘IO开销加大,导致系统访问变慢,这个时候我们就需要来对数据表进行水平分表,也叫数据分片。分表的相关业务操作是我们数据库维护和操作中交为复杂的,对于单节点服务器的分表操作还算简单,但对于读写分离的多服务器在做分表之后,操作是比较复杂的,不管是运维还是程序的实现。
分表的好处就是,减少数据库的磁盘IO,加快数据表的查询性能。主要的案例就是我们的无卡支付订单表,以前在订餐高峰,系统会变得很卡,经常被客户投诉,优化之后,系统也变得稳定了。
如下图,就是水平分表后的无卡支付表
补充
如果对于主键要求唯一的情况下,那么分表处理要求又提高了,每次添加数据的时候,主键一定要唯一。目前主流的有两种方式可以来处理,一种是利用redis计数,另外一种采用算法来计算。如果想看分布式ID生成方法,可以看下这篇文章:
https://mp.weixin.qq.com/s/0H-GEXlFnM1z-THI8ZGV2Q
二、查询语句优化
1.对于字段多的表,避免使用SELECT *
使用SELECT * FROM table,会把不需要用到的字段也查出来,如果有的字段容量比较大,这样子就增加磁盘的IO,影响性能
2.避免使用!=操作符
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描,
select order_id,order_number,user_id where user_id <> 23
可以用下面的语句替换
select order_id,order_number,user_id where user_id < 23 and user_id > 23
3.避免使用null做条件
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
4.like查询如何优化
尽量避免like查询,对于like比较频繁的字段应该建立索引,并且在SQL写法上主要采用左前缀的优化原则
select * from t where order_title like '%abc%';
上面的SQL语句索引是失效的,应该改成这样子
select id from t where name like 'abc%';
5.在查询子句中避免使用函数操作
应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where datediff(day,createdate,'2005-11-30')=1
应该改成
select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'
6.尽量避免在where子句中使用or
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以用union all来代替:
select id from t where num=10
union all
select id from t where num=20
7.经量避免使用in或not in,因为这个也是属于or的操作
用union all语句替换:
select num from a where a=6
union all
select num from a where a=7
union all
select num from a where a=8
8.尽量避免在where子句中使用表达式,函数
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
9.尽量避免在大量重复数据的字段建立索引
并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,status等,在此字段上建了索引也对查询效率起不了作用。
10.联合索引
数据表查询,尽量采用单表查询,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引,如果同时需要在条件字段和order_by字段让索引都有效,那么就建立组合索引。
11.索引也是要适可而止
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
12.尽量避免使用临时表(create temporary table…select…)
在做数据迁移或临时数据存储操作时,避免使用临时表,(create temporay table [临时表名] select [fields] from [原始表])
应该先建一张物理表,然后(insert into [物理表] select [fields] from [原始表])
13.尽量避免使用order by rand()
不要用随机排序,就是order by rand()
MySQL去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
$r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1");
// 这要会更好:
$res = mysql_query("SELECT count(*) FROM user");
$d = mysql_fetch_row($r);
$rand = mt_rand(0,$d[0] - 1);
$res = mysql_query("SELECT username FROM user LIMIT $rand, 1");
14.拆分大的 DELETE、INSERT、update语句
如果你需要在一个在线的网站上去执行一个大的 DELETE/INSERT/UPDATE操作,你需要非常小心,因为这是锁表操作。要避免你的操如果表一锁住了,别的连接只能等待了,这样的后果严重点就是让整个网站停止响应。
如果一个操作把表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊WEB服务Crash,还可能会让你的整台服务器马上挂了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。
下面是一个PHP代码示例:
while(1) {
//每次只做1000条
mysql_query("DELETE FROM logs WHERE log_date <= '2009-11-01' LIMIT 1000");
if(mysql_affected_rows() == 0) {
// 没得可删了,退出!
break;
}
// 每次都要休息一会儿
usleep(50000);
}
15.尽量避免客户端返回大数据量
尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
16.避免使用大事务
尽量避免大事务操作,如果可以,使用分布式事务,提高系统并发能力。
17.避免使用查询缓存
- Mysql的缓存是KV结构的,Key是执行过程中的SQL语句,Value是查询的结果。
- 如果对一个表执行添加,修改,删除或者修改表结构,都会造成这个表的缓存清空。
- 所有对加锁的事务不会使用缓存,比如一个事务中同时有Update和Select操作,那么这个Select就不会使用缓存
- 在mysql8.0之后查询缓存是去掉了的,如果出现大面积的数据删改,就会导致缓存失效,这样子增大了内存和磁盘的IO开销。在使用热数据缓存时,可以用redis来代替。
在数据库中查看查询缓存的设置
SHOW VARIABLES LIKE '%query_cache%';
补充
在集群环境下,用单表操作来代替 联表、子查询。像联表虽然比较方便,但是其内部算法两个foreach循环,比如A表有100条数据,B表有1000条数据,那么A表在连接B表的时候,其实100 * 1000的操作,其实可以采用现将100条数据查出来,作为查询1000条数据的条件。最后通过程序来进行组合
三、数据库配置参数优化
2. innodb_buffer_pool_size innodb缓存空间优化(重要)
- 它属于MySQL的核心参数, 它不是缓存查询结果集,它是来缓存部分数据和部分索引,这样子加快了查询速度,提高了性能,当然缓存空间设置越大,它命中缓存概率也就越大。同时,它不会因为修改了数据导致大面积的数据失效。
- 他默认为128MB,正常的情况下这个参数设置为物理内存的
60%~70%(这个是针对数据库专用服务器,不过我们的实例基本上都是多实例混部的,所以这个值还要根据业务规模来具体分析)。 - 在数据库中查看变量值
show variables like 'innodb_buffer_pool_size';
3. max_connections数据库最大并发连接数(重要)
- 修改参数的注意事项:
- MySQL服务器默认连接数比较小,以mysql8.0为例是最小是151个,最大值是16384;每一个连接都会占用一定的内存,比如连接值=3000为例,大概占用800M内存,所以这个参数也不是越大越好。应该需要结合服务器的内存大小,以及实际连接数的值来进行修改。
- 有的人遇到too many connections会去增加这个参数的大小,但其实如果是业务量或者程序逻辑有问题或者sql写的不好,即使增大这个参数也无济于事,再次报错只是时间问题。在应用程序里使用连接池或者在MySQL里使用进程池有助于解决这一问题。
- 如何来确定max_connections值的修改范围?
先在数据库配置文件my.cnf修改成大一点5000或8000,然后再根据实际连接数max_used_connections的值具体是多少,再来设置max_connections值(如果max_connections太小会导致一些连接不上得不到真实的max_used_connections)。一般来说,max_used_connections的值是max_connections的85%比较合适,假如max_used_connections的值=500,max_connections=500/0.85,差不多600个,下面是查看这两个指标的SQL语句
实际连接数的大小
SHOW STATUS LIKE 'max_used_connections';
最大连接数
SHOW VARIABLES LIKE 'max_connections';
4. 优化请求堆栈back_log(重要)
back_log参数表示请求的堆栈大小,当请求达到max_connections的阀值,数据库连接就会拒绝,而数据库会把新的请求存放在堆栈中,等空闲的时候,再分配给堆栈中的请求,其修改的标准是max_connections的30%,其使用场景在MySQL服务器在短时间内有大量的连接进来的时候,可以增加这个参数的值。
SHOW VARIABLES LIKE 'back_log';
5. 修改连接超时时间wait_timeout(重要)
wait_timeout参数表示连接的超时时间,单位是秒;其连接默认超时时间是8小时,即在什么都不做的情况下,8个小时才会切断连接,这比较浪费连接资源,所以需要修改连接时间,一般设置成10-20分钟
在SQL语句中查看参数
SHOW VARIABLES LIKE 'wait_timeout';
在my.conf的设置成10分钟
wait-timeout=600
6. 修改并发线程数innodb_thread_concurrency
- innodb_thread_concurrency是用来来限制并发线程的数量,这个参数默认值是0,表示不限制;如过不限制线程数量,会调用大量的线程,导致损耗CPU的性能,使得系统变慢。
所以给分配并发线程的数量应该是CPU核心数的两倍,不如数据库服务器的CPU是8核心,那么其值可以设置为16。 - 当然在一旦执行线程的数量达到这个限制,其他线程在被放入队列之前会休眠若干微秒(由配置参数innodb_thread_sleep_delay设置)。
SHOW VARIABLES LIKE 'innodb_thread_concurrency';
SHOW VARIABLES LIKE 'innodb_thread_sleep_delay';
7. innodb_log_file_size redo日志大小优化
这是redo日志的大小。redo日志被用于确保写操作快速而可靠并且在崩溃时恢复。
如果你知道你的应用程序需要频繁地写入数据并且你使用的是MySQL 5.6以上,那么你可以一开始就把它这是成4G。(具体大小还要根据自身业务进行适当调整)
8. innodb_flush_log_at_trx_commit刷新redo日志配置
默认值为1,表示InnoDB完全支持ACID特性。当你的主要关注点是数据安全的时候这个值是最合适的,比如在一个主节点上。但是对于磁盘(读写)速度较慢的系统,它会带来很巨大的开销,因为每次将改变flush到redo日志都需要额外的fsyncs。
如果将它的值设置为2会导致不太可靠(unreliable)。因为提交的事务仅仅每秒才flush一次到redo日志,但对于一些场景是可以接受的,比如对于主节点的备份节点这个值是可以接受的。如果值为0速度就更快了,但在系统崩溃时可能丢失一些数据:只适用于备份节点。说到这个参数就一定会想到另一个sync_binlog。
补充
数据库性能问题最主要的还是在SQL语句的性能上,数据库配置优化也只是辅助
四、正确选择引擎
读多写少
就用innodb引擎,普遍来说,大部分系统都是读多写少的,像电商系统,在线教育,小说网站,论坛,新闻站等等。对于一些访问量大的页面,但不经常变的网站可以使用页面缓存。对于一些热门数据,排行榜可以使用redis。对于数据库并发量大了,可以使用mysql集群。
写多读少
写多读少场景是根据区分数据的价值程度来技术选型。写多读少比如像滴滴的顾客实时数据上报,大学食堂的无卡支付都是属于写多读少场景。
如果低价值的,像用户的滴滴实时坐标位置,用户的点赞,评论记录就写入到Nosql数据库,比如像mongodb,因为其结构简单,不想Mysql表结构复杂,还涉及到事务的提交。所以速度比较快。
如果数据是高价值的,必须要做到数据的安全,这个时候可以采用TokuDB引擎。同样的事务机制下他的写入速度是innodb的9-20倍,压缩比是innodb的14倍,比如学校食堂的消费记录,用户的订单记录等等。它还适合存储重要且不怎么经常读的历史归档数据。像mysql单表数据超过了2000万,我们可以把不常用的历史数据转义到归档表,这个时候可以使用TokuDB引擎。它需要单独安装扩展,只支持linux环境。
读多写多
读多写多的场景,是指像新浪微博,微信朋友圈,微信,QQ的聊天,抽奖活动等等都是属于读多写多,这个时候使用关系型数据库就不适合了,这个时候就要采用Nosql数据库了。
五、数据库的问题如何分析
1. 先看错误日志
查看错误日志,定位问题,有的日志里面会提示连接数太多了,磁盘不够用了之类的,这个需要修改配置参数了。它一般和数据库文件放在一起。
1. 查看数据存储位置
SHOW VARIABLES LIKE 'datadir'
2. 查看错误存储位置
SHOW VARIABLES LIKE 'log_error'
2. 开启慢查询日志
[mysqld]
slow-query-log=1
slow_query_log_file=/data/logs/mysql-slow
long_query_time=2
log-queries-not-using-indexes #未使用索引
查看慢查询日志状态:
show variables like '%slow%';
结果:
| Variable_name | Value | 说明 |
|---|---|---|
| log_slow_queries | ON | 开启慢查询 |
| slow_launch_time | 2 | 代表着捕获所有执行时间超过2秒的查询 |
| slow_query_log | ON | 代表开启满查询日志写入 |
| slow_query_log_file | /data/mysql-slow/slow.log | 日志路径 |
在my.cnf配置中将上述4个配置写入进去。
mysql慢查询日志分析工具之pt-query-digest出自percona-toolkit
1.下载
wget http://www.percona.com/get/pt-query-digest
2.分析
./pt-query-digest 【慢查询日志路径】| more
3.将慢查询日志生成报表
./pt-query-digest 【满查询日志路径】 > /data/slow_report.log
3. 如何通过数据库进程查看问题
show full processlist
此命令比较好用,可以监控目前正在活动的数据库操作,主要看的是state和info两个信息,state表示这条SQL语句的问题。info表示具体的SQL语句
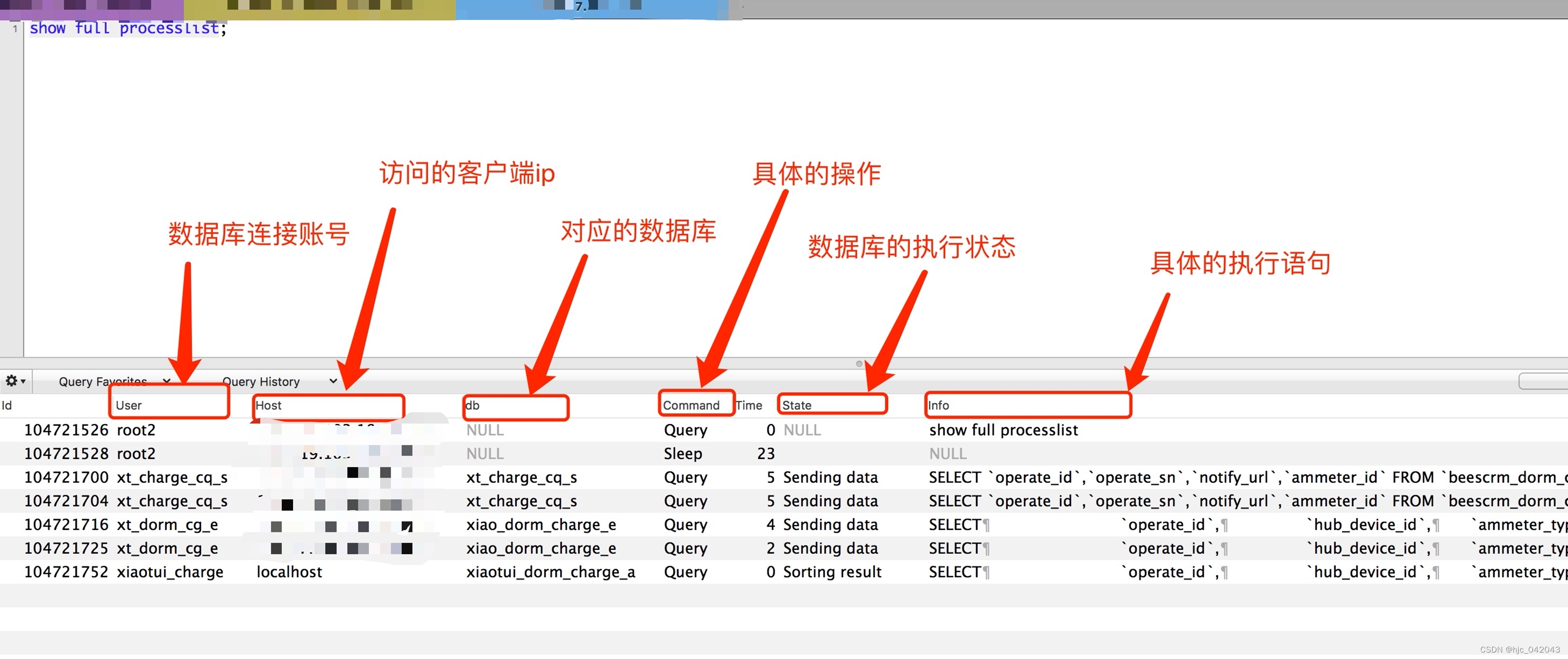
主要来说说state
| 字段名 | 说明 |
|---|---|
| Checking table | 正在检查数据表(这是自动的 |
| Closing tables | 正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中 |
| Sending data | 正在处理SELECT查询的记录,同时正在把结果发送给客户端,如果一直处于这个状态就是索引失效或者字段太大的问题 |
| Connect Out | 复制从服务器正在连接主服务器 |
| Copying to tmp table on disk | 由于临时结果集大于tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存 |
| Creating tmp table | 正在创建临时表以存放部分查询结果 |
| Flushing tables | 正在执行FLUSH TABLES,等待其他线程关闭数据表 |
| Killed | 发送了一个kill请求给某线程,那么这个线程将会检查kill标志位,同时会放弃下一个kill请求。MySQL会在每次的主循环中检查kill标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么kill请求会在锁释放时马上生效 |
| Locked | 被其他查询锁住了 |
| Sorting for group | 正在为GROUP BY做排序 |
| Sorting for order | 正在为ORDER BY做排序 |
| Sleeping | 正在等待客户端发送新请求 |
| System lock | 正在等待取得一个外部的系统锁。如果当前没有运行多个mysqld服务器同时请求同一个表,那么可以通过增加–skip-external-locking参数来禁止外部系统锁 |
| Waiting for net / reading from net / writing to net | 主要是网络状态的描述,如大量出现,要检查数据库网络连接状态和流量 |
show profile
此命令分析当前数据库登陆会话下的执行语句的资源消耗情况(注意只能是当前会话下)
1. 输出当前连接下所有执行中sql
show profiles //会列出所有查询id,执行时间,执行语句
| Query ID | Duration | Duration |
|---|---|---|
| 1 | 0.05912400 | select count(1) from user |
| 2 | 5.82553775 | select count(1) from order |
2. 输出指定SQL语句的信息
show profile for query n
查看指定query_id的sql的执行消耗情况(默认输出Status和Duration columns两列信息)
show profile for query 2
| Status | Duration |
|---|---|
| starting | 0.000095 |
| checking permissions | 0.000011 |
| Opening tables | 0.017916 |
| init | 0.000028 |
| System lock | 0.000018 |
| optimizing | 0.000010 |
| statistics | 0.000021 |
| preparing | 0.000020 |
| executing | 0.000005 |
| Sending data | 5.794340 |
| end | 0.000025 |
| query end | 0.000014 |
| closing tables | 0.000026 |
| freeing items | 0.000045 |
| logging slow query | 0.012937 |
| cleaning up | 0.000028 |
4. explain工具的使用
语法:EXPLAIN [EXTENDED] SELECT select_options
下面就是在查询分析器分析的一个例子
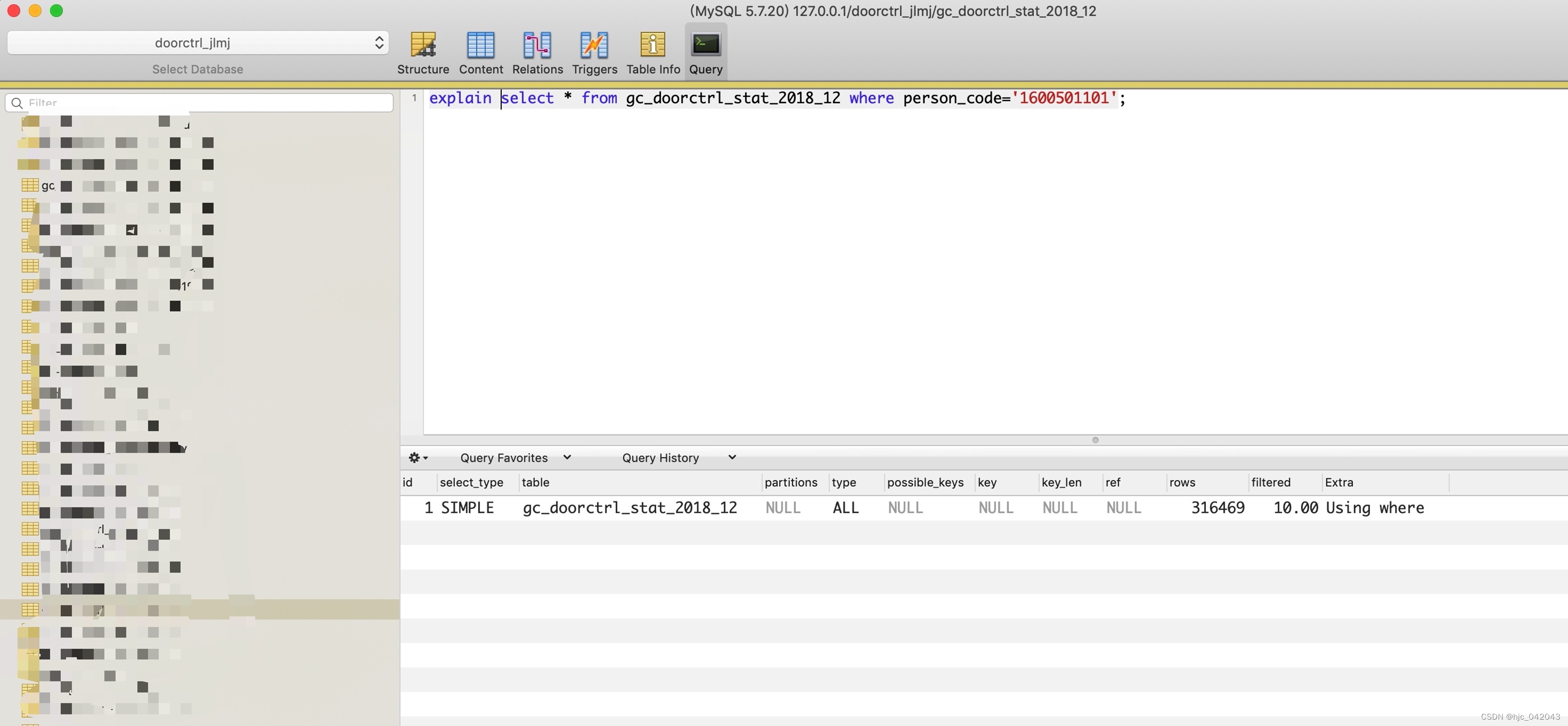
如何分析SQL查询
下面所列就是explain返回各列的含义:
id
SELECT识别符。这是SELECT的查询序列号
select_type
SELECT类型,可以为以下任何一种:
SIMPLE:简单SELECT(不使用UNION或子查询)
PRIMARY: 最外面的SELECT
UNION: UNION中的第二个或后面的SELECT语句
DEPENDENT UNION: UNION中的第二个或后面的SELECT语句,取决于外面的查询
UNION RESULT: UNION 的结果
SUBQUERY: 子查询中的第一个SELECT
DEPENDENT SUBQUERY: 子查询中的第一个SELECT,取决于外面的查询
DERIVED: 导出表的SELECT(FROM子句的子查询)
table
输出的行所引用的表
type
显示连接用了哪种类型,从最好到最坏的连接类型为:
联接类型。下面给出各种联接类型,按照从最佳类型到最坏类型进行排序:
system: 表仅有一行(=系统表)。这是const联接类型的一个特例。
const: 表最多有一个匹配行,它将在查询开始时被读取。因为仅有一行,在这行的列值可被优化器剩余部分认为是常数。const表很快,因为它们只读取一次!
eq_ref: 对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。
ref: 对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。
ref_or_null: 该联接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。
index_merge: 该联接类型表示使用了索引合并优化方法。
unique_subquery: 该类型替换了下面形式的IN子查询的ref: value IN (SELECT primary_key FROM single_table WHERE some_expr) unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
index_subquery: 该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引: value IN (SELECT key_column FROM single_table WHERE some_expr)
range: 只检索给定范围的行,使用一个索引来选择行。
index: 该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。
ALL: 对于每个来自于先前的表的行组合,进行完整的表扫描。
possible_keys
显示可能应用在这张表中的索引,如果为空,则是没有可能的索引
key
实际使用到的索引。如果为NULL,则没有使用索引
key_len
使用索引的长度,在不损失精确性的情况下,索引越小越好
mysql以页为单位进行扫描,页越大,索引扫描就越慢
Extra
Using filesort
看到这这个的时候,查询就需要优化了,它根据全部行的行指针来排序全部行
Using temporary
看到这个的时候,查询需要优化了,Mysql创建一个临时表来哦存储结果,这通常发生在对不同列级进行GROUP BY, ORDER BY 上。
六、表修复相关
1.数据表修复
表修复和优化命令,如下:
REPAIR TABLE `table_name` 修复表
REPAIR TABLE 用于修复被破坏的表.
2. 数据表空间优化
innodb_file_per_table表空间的配置
- mysql的数据和索引存放在共享表空间里或者单独表空间里。共享表空间是指所有表的都在同一个数据文件中,名字是ibdata1, 而独立表空间,是一个表,一个表空间。ibdata也是分开存储。
- 使用共享表空间的坏处是在清理一些不需要的数据时,表空间并不会收缩,产生随便,这样子浪费磁盘空间。使用独立表空间的好处是,可以实现单表在不同的数据库中移动,表空间可以收回。
- 在mysql5.6以上默认开启了,在my.cnf中设置innodb_file_per_table = ON
- 在数据库的查询语句可以看开启状态
show VARIABLES like 'innodb_file_per_table';
OPTIMIZE TABLE优化表空间
用于回收闲置的数据库空间,当表上的数据行被删除时,所占据的磁盘空间并没有立即被回收,使用了OPTIMIZE TABLE命令后这些空间将被回收,而且对磁盘上的数据行进行重排(注意:是磁盘上,而非数据库).
OPTIMIZE TABLE `table_name` 优化表
结语
当前文章主要是以数据表结构优化,查询语句优化,数据库参数优化,以及数据库问题的如何分析定位来进行展开,因本人水平有限,先写到这里了,后续有新的知识点再补充。还希望各位在评论区多提改进建议!!!