llvm 18 debug 版本
build llvmorg-18.1rc4 debug
$ cd llvm-project
$ git checkout llvmorg-18.1.0-rc4
$ mkdir build_d
$ cd build_d
$ mkdir -p ../../local_d
cmake \
-DCMAKE_INSTALL_PREFIX=../../local_d \
-DLLVM_SOURCE_DIR=../llvm \
-DLLVM_ENABLE_PROJECTS="bolt;clang;clang-tools-extra;lld;mlir" \
-DLLVM_TARGETS_TO_BUILD="X86;NVPTX" \
-DLLVM_INCLUDE_TESTS=OFF \
-DCMAKE_BUILD_TYPE=Debug \
../llvm其余部分拆出来了:
cross-project-tests;libclc;lldb;polly;flang
-DLLVM_ENABLE_RUNTIMES="libunwind;libcxxabi;pstl;libcxx;openmp" \
libc;compiler-rt;
$ make -j34
$make install
llvm 18 release版本
cd llvm-project
mkdir build_r
cd build_r
mkdir -p ../../local_r
cmake \
-DCMAKE_INSTALL_PREFIX=../../local_r \
-DLLVM_SOURCE_DIR=../llvm \
-DLLVM_ENABLE_PROJECTS="bolt;clang;clang-tools-extra;lld;mlir" \
-DLLVM_TARGETS_TO_BUILD="X86;NVPTX" \
-DLLVM_INCLUDE_TESTS=OFF \
-DCMAKE_BUILD_TYPE=Release \
../llvm$ make -j34
效果:
$make install
build HIPIFY debug
$ mkdir /home/hipper/llvm_3_4_0_ex/browse_llvm_17/local_d/hipify
cmake \
-DCMAKE_INSTALL_PREFIX=/home/hipper/llvm_3_4_0_ex/browse_llvm_17/local_d/hipify \
-DCMAKE_BUILD_TYPE=Debug \
-DCMAKE_PREFIX_PATH=/home/hipper/llvm_3_4_0_ex/browse_llvm_17/local_d \
..还有一种更多配置的编译配置方法,其实用不到:
cmake
-DHIPIFY_CLANG_TESTS=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=../dist \
-DCMAKE_PREFIX_PATH=/usr/llvm/17.0.6/dist \
-DCUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda-12.3.2 \
-DCUDA_DNN_ROOT_DIR=/usr/local/cudnn-8.9.7 \
-DCUDA_CUB_ROOT_DIR=/usr/local/cub-2.1.0 \
-DLLVM_EXTERNAL_LIT=/usr/llvm/17.0.6/build/bin/llvm-lit \
..using hipify-clang
hipify-clang intro.cu --cuda-path="/usr/local/cuda-12.3" --print-stats-csv$ /home/hipper/llvm_3_4_0_ex/browse_llvm_17/local_d/hipify/bin/hipify-clang vectorAdd.cu --cuda-path="/usr/local/cuda-12.3" --clang-resource-directory="/home/hipper/llvm_3_4_0_ex/browse_llvm_17/local_d/lib/clang/18"
写成Makefile:
EXE := vectorAdd_hip
all: $(EXE)
$(EXE): vectorAdd.cu.hip
hipcc $< -o $@
%.hip: %
/home/hipper/llvm_3_4_0_ex/browse_llvm_17/local_d/hipify/bin/hipify-clang $< --cuda-path=/usr/local/cuda-12.3 --clang-resource-directory=/home/hipper/llvm_3_4_0_ex/browse_llvm_17/local_d/lib/clang/18
.PHONY: clean
clean:
${RM} $(EXE) *.hip效果:
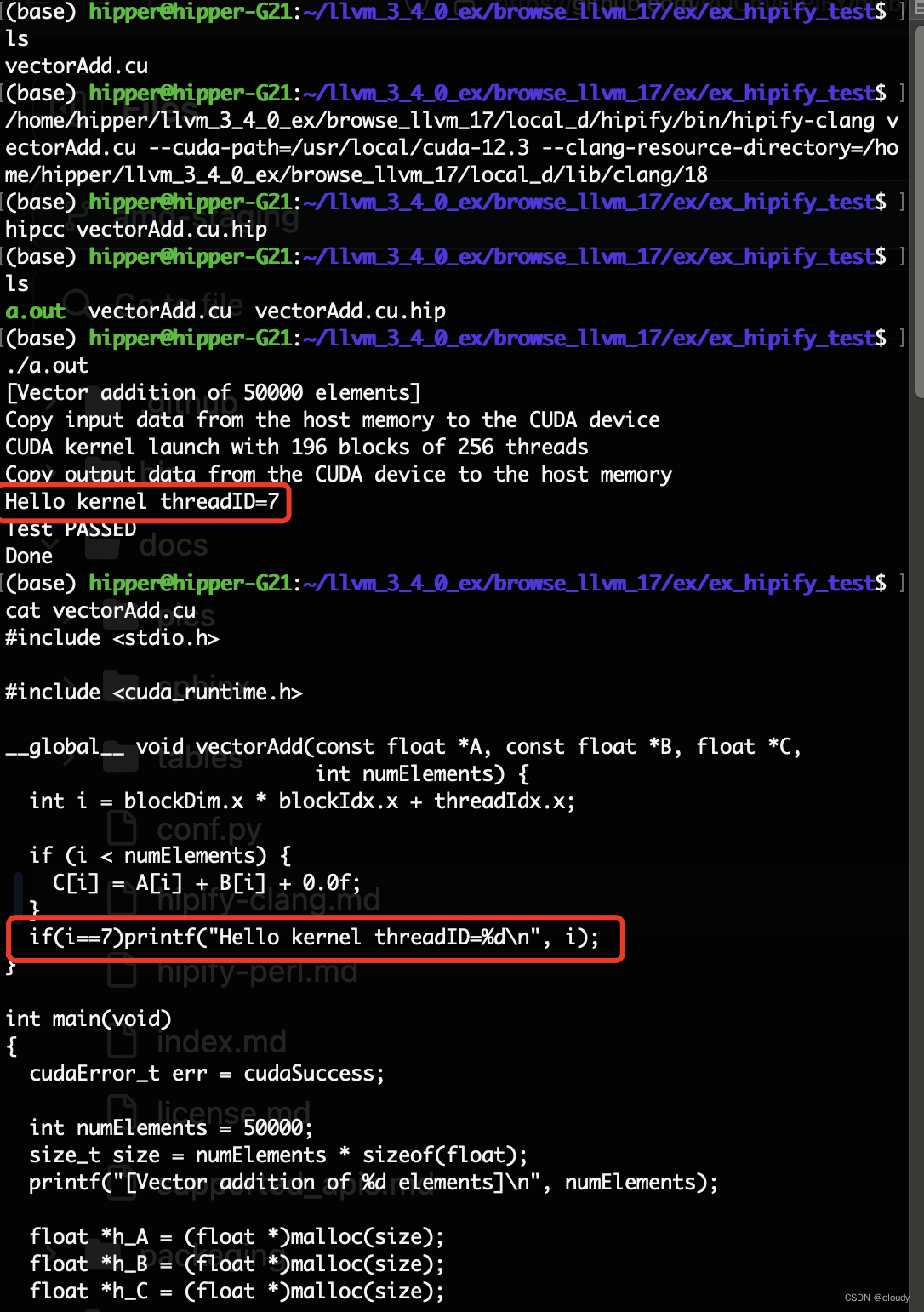
源cu代码:
#include <stdio.h>
#include <cuda_runtime.h>
__global__ void vectorAdd(const float *A, const float *B, float *C,
int numElements) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements) {
C[i] = A[i] + B[i] + 0.0f;
}
if(i==7)printf("Hello kernel threadID=%d\n", i);
}
int main(void)
{
cudaError_t err = cudaSuccess;
int numElements = 50000;
size_t size = numElements * sizeof(float);
printf("[Vector addition of %d elements]\n", numElements);
float *h_A = (float *)malloc(size);
float *h_B = (float *)malloc(size);
float *h_C = (float *)malloc(size);
if (h_A == NULL || h_B == NULL || h_C == NULL) {
fprintf(stderr, "Failed to allocate host vectors!\n");
exit(EXIT_FAILURE);
}
for (int i = 0; i < numElements; ++i) {
h_A[i] = rand() / (float)RAND_MAX;
h_B[i] = rand() / (float)RAND_MAX;
}
float *d_A = NULL;
err = cudaMalloc((void **)&d_A, size);
if (err != cudaSuccess) {
fprintf(stderr, "Failed to allocate device vector A (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
float *d_B = NULL;
err = cudaMalloc((void **)&d_B, size);
if (err != cudaSuccess) {
fprintf(stderr, "Failed to allocate device vector B (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
float *d_C = NULL;
err = cudaMalloc((void **)&d_C, size);
if (err != cudaSuccess) {
fprintf(stderr, "Failed to allocate device vector C (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
printf("Copy input data from the host memory to the CUDA device\n");
err = cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
if (err != cudaSuccess) {
fprintf(stderr,
"Failed to copy vector A from host to device (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
if (err != cudaSuccess) {
fprintf(stderr,
"Failed to copy vector B from host to device (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
int threadsPerBlock = 256;
int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;
printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
err = cudaGetLastError();
if (err != cudaSuccess) {
fprintf(stderr, "Failed to launch vectorAdd kernel (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
printf("Copy output data from the CUDA device to the host memory\n");
err = cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
if (err != cudaSuccess) {
fprintf(stderr,
"Failed to copy vector C from device to host (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
for (int i = 0; i < numElements; ++i) {
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5) {
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
printf("Test PASSED\n");
err = cudaFree(d_A);
if (err != cudaSuccess) {
fprintf(stderr, "Failed to free device vector A (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_B);
if (err != cudaSuccess) {
fprintf(stderr, "Failed to free device vector B (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_C);
if (err != cudaSuccess) {
fprintf(stderr, "Failed to free device vector C (error code %s)!\n",
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
free(h_A);
free(h_B);
free(h_C);
printf("Done\n");
return 0;
}生成的vectorAdd.cu.hip代码:
#include <stdio.h>
#include <hip/hip_runtime.h>
__global__ void vectorAdd(const float *A, const float *B, float *C,
int numElements) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements) {
C[i] = A[i] + B[i] + 0.0f;
}
if(i==7)printf("Hello kernel threadID=%d\n", i);
}
int main(void)
{
hipError_t err = hipSuccess;
int numElements = 50000;
size_t size = numElements * sizeof(float);
printf("[Vector addition of %d elements]\n", numElements);
float *h_A = (float *)malloc(size);
float *h_B = (float *)malloc(size);
float *h_C = (float *)malloc(size);
if (h_A == NULL || h_B == NULL || h_C == NULL) {
fprintf(stderr, "Failed to allocate host vectors!\n");
exit(EXIT_FAILURE);
}
for (int i = 0; i < numElements; ++i) {
h_A[i] = rand() / (float)RAND_MAX;
h_B[i] = rand() / (float)RAND_MAX;
}
float *d_A = NULL;
err = hipMalloc((void **)&d_A, size);
if (err != hipSuccess) {
fprintf(stderr, "Failed to allocate device vector A (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
float *d_B = NULL;
err = hipMalloc((void **)&d_B, size);
if (err != hipSuccess) {
fprintf(stderr, "Failed to allocate device vector B (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
float *d_C = NULL;
err = hipMalloc((void **)&d_C, size);
if (err != hipSuccess) {
fprintf(stderr, "Failed to allocate device vector C (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
printf("Copy input data from the host memory to the CUDA device\n");
err = hipMemcpy(d_A, h_A, size, hipMemcpyHostToDevice);
if (err != hipSuccess) {
fprintf(stderr,
"Failed to copy vector A from host to device (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
err = hipMemcpy(d_B, h_B, size, hipMemcpyHostToDevice);
if (err != hipSuccess) {
fprintf(stderr,
"Failed to copy vector B from host to device (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
int threadsPerBlock = 256;
int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;
printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
err = hipGetLastError();
if (err != hipSuccess) {
fprintf(stderr, "Failed to launch vectorAdd kernel (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
printf("Copy output data from the CUDA device to the host memory\n");
err = hipMemcpy(h_C, d_C, size, hipMemcpyDeviceToHost);
if (err != hipSuccess) {
fprintf(stderr,
"Failed to copy vector C from device to host (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
for (int i = 0; i < numElements; ++i) {
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5) {
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
printf("Test PASSED\n");
err = hipFree(d_A);
if (err != hipSuccess) {
fprintf(stderr, "Failed to free device vector A (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
err = hipFree(d_B);
if (err != hipSuccess) {
fprintf(stderr, "Failed to free device vector B (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
err = hipFree(d_C);
if (err != hipSuccess) {
fprintf(stderr, "Failed to free device vector C (error code %s)!\n",
hipGetErrorString(err));
exit(EXIT_FAILURE);
}
free(h_A);
free(h_B);
free(h_C);
printf("Done\n");
return 0;
}其他参考选项示例:
指示头文件文件夹
./hipify-clang square.cu --cuda-path=/usr/local/cuda-12.3 -I /usr/local/cuda-12.3/samples/common/inc指示C++标准
./hipify-clang cpp17.cu --cuda-path=/usr/local/cuda-12.3 -- -std=c++17多个 .cu 文件一起编译
./hipify-clang cpp17.cu ../../square.cu /home/user/cuda/intro.cu --cuda-path=/usr/local/cuda-12.3 -- -std=c++17统计修改的信息
$ /home/hipper/llvm_3_4_0_ex/browse_llvm_17/local_d/hipify/bin/hipify-clang vectorAdd.cu --cuda-path=/usr/local/cuda-12.3 --clang-resource-directory=/home/hipper/llvm_3_4_0_ex/browse_llvm_17/local_d/lib/clang/18 --print-stats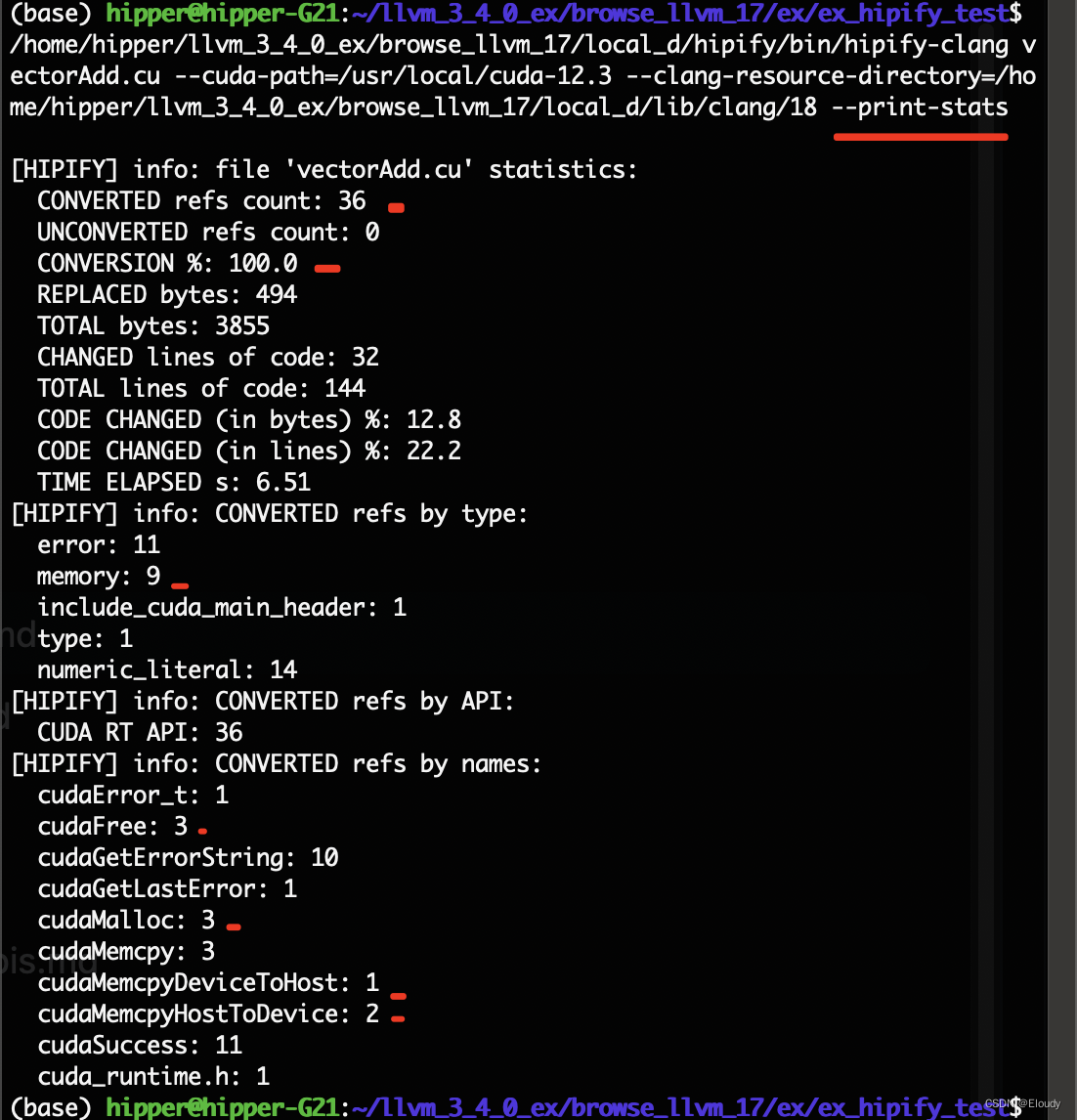
将 统计信息存入 .csv文件中
--print-stats
改成
--print-stats-csv遗留问题
llvmorg-18.1.rc release 配置有问题:
cmake \
-DCMAKE_INSTALL_PREFIX=../../local \
-DLLVM_SOURCE_DIR=../llvm \
-DLLVM_ENABLE_PROJECTS="bolt;clang;clang-tools-extra;cross-project-tests;libclc;lld;mlir;polly;flang" \
-DLLVM_ENABLE_RUNTIMES="libc;libunwind;libcxxabi;pstl;libcxx;compiler-rt;openmp" \
-DLLVM_TARGETS_TO_BUILD="X86;NVPTX" \
-DLLVM_INCLUDE_TESTS=OFF \
-DCMAKE_BUILD_TYPE=Release \
../llvm
lldb;