目录
一、程序地址空间
1、虚拟地址
Makefile新写法
2、进程地址空间分布
3、栈&堆
4、static修饰局部变量
5、字符串常量不可修改
6、虚拟地址与物理地址的联系
二、CPU读取程序全过程
1、形成可执行程序
2、生成虚拟地址
3、程序的启动
4、创建进程
5、地址映射(虚拟内存管理)
6、程序执行
7、数据的存取
8、进程切换
内存管理单元(MMU)和页表
三、为什么需要地址空间?
原因1:地址空间+页表对非法访问进行有效拦截 ,有效的保护了物理内存。
原因2、内存管理和进程管理解耦
原因3、维护进程独立性
四、重新理解“新建状态”和“挂起”概念
一、程序地址空间
1、虚拟地址
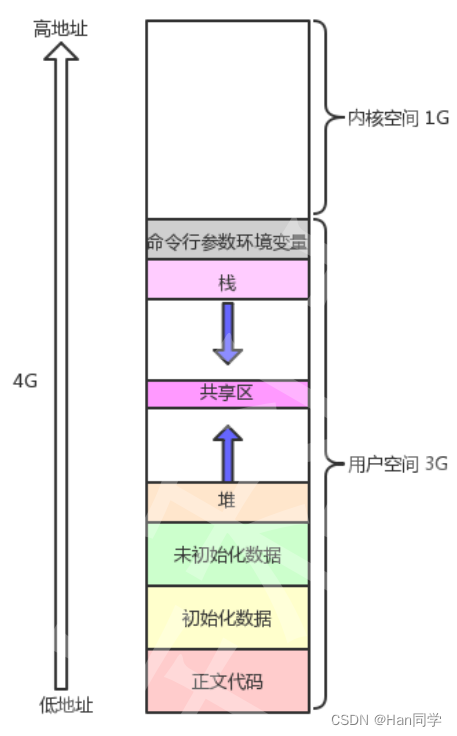
在32位下,一个进程的地址空间,取值范围是0x0000 0000 ~ OxFFFF FFFF,0,3GB]:用户空闻 ,[3GB,4GB]:内核空间。
#include <stdio.h>
#include <unistd.h>
int g_val=100;
int main()
{
pid_t id=fork();
if(id==0)
{
int n=0;
while(1)
{
printf("I am child. pid: %d, ppid %d, g_val: %d, &g_val: %p\n",\
getpid(),getppid(),g_val,&g_val);
sleep(1);
n++;
if(n==5)
{
g_val=200;
printf("child change g_val 100 -> 200 success\n");
}
}
}
else
{
while(1)
{
printf("I am father. pid: %d, ppid %d, g_val: %d, &g_val: %p\n",\
getpid(),getppid(),g_val,&g_val);
sleep(1);
}
}
return 0;
}
根据运行结果发现,当子进程修改了全局变量的值之后,同时读取同一个全局变量时,g_val的值不同,但子进程和父进程的g_val的地址仍然相同,这是为什么呢?

- 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量
- 如果这里的地址是物理地址,那么读取的g_val的值应该相同。
所以答案只有一个,这里的地址绝对不是物理内存的地址。而是虚拟地址。
我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理OS必须负责将虚拟地址转化成物理地址 。
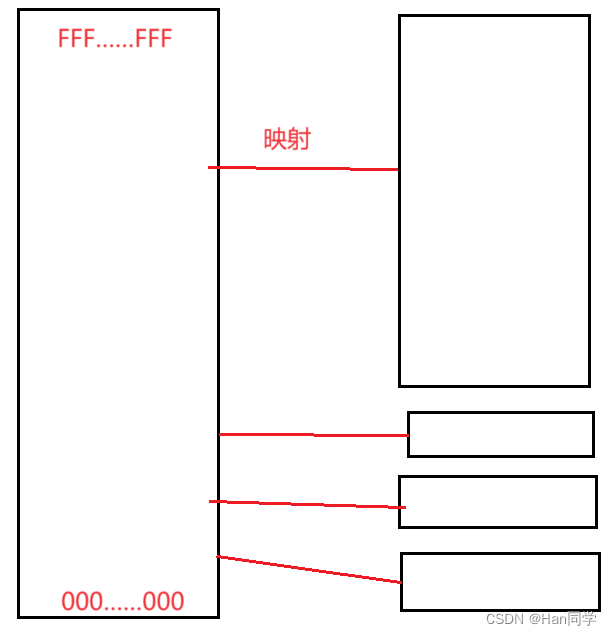
- 虚拟地址空间是操作系统为每个进程分配的地址空间,它将内存和外设(如磁盘、网卡等)的寄存器从0开始一一映射到进程的地址空间中。这种映射使得进程可以通过访问虚拟地址来访问实际的内存和外设寄存器,而不需要了解物理地址的具体情况。
- 当进程访问虚拟地址时,操作系统会将虚拟地址转换为对应的物理地址,这个过程称为地址转换。对于内存,操作系统会将虚拟地址映射到物理内存中的对应位置;对于外设寄存器,操作系统会将虚拟地址映射到外设的寄存器地址,从而实现对外设的控制和访问。
- 通过虚拟地址空间的映射,操作系统可以实现进程间的隔离和保护,每个进程都认为自己拥有整个地址空间,但实际上它们共享物理内存和外设资源。这种机制使得操作系统能够有效管理系统资源,并提高系统的安全性和稳定性。
Makefile新写法
Makefile可以使用这种写法
mytest:test.c
gcc -std=c99 -o $@ $^
.PHONY:clean
clean:
rm -f mytest
-
$@表示目标,即当前规则中的目标。在这个Makefile中,目标是mytest。 -
$^表示所有的依赖项,即当前规则中列出的所有文件。在这个Makefile中,依赖项是test.c。
2、进程地址空间分布
通过下面程序我们来了解一下 :
#include <stdio.h>
#include <stdlib.h>
int g_unval;
int g_val=100;
int main(int argc,char* argv[],char* env[])
{
printf("code addr: %p\n",main);
printf("init gloval addr: %p\n",&g_val);
printf("uninit gloval addr: %p\n",&g_unval);
char *heap_mem=(char*)malloc(10);
printf("heap addr: %p\n",heap_mem);
printf("stack addr: %p\n",&heap_mem);
for(int i=0;i<argc;i++)
{
printf("argv[%d]: %p\n",i,argv[i]);
}
for(int i=0;env[i];i++)
{
printf("env[%d]: %p\n",i,env[i]);
}
return 0;
}
-
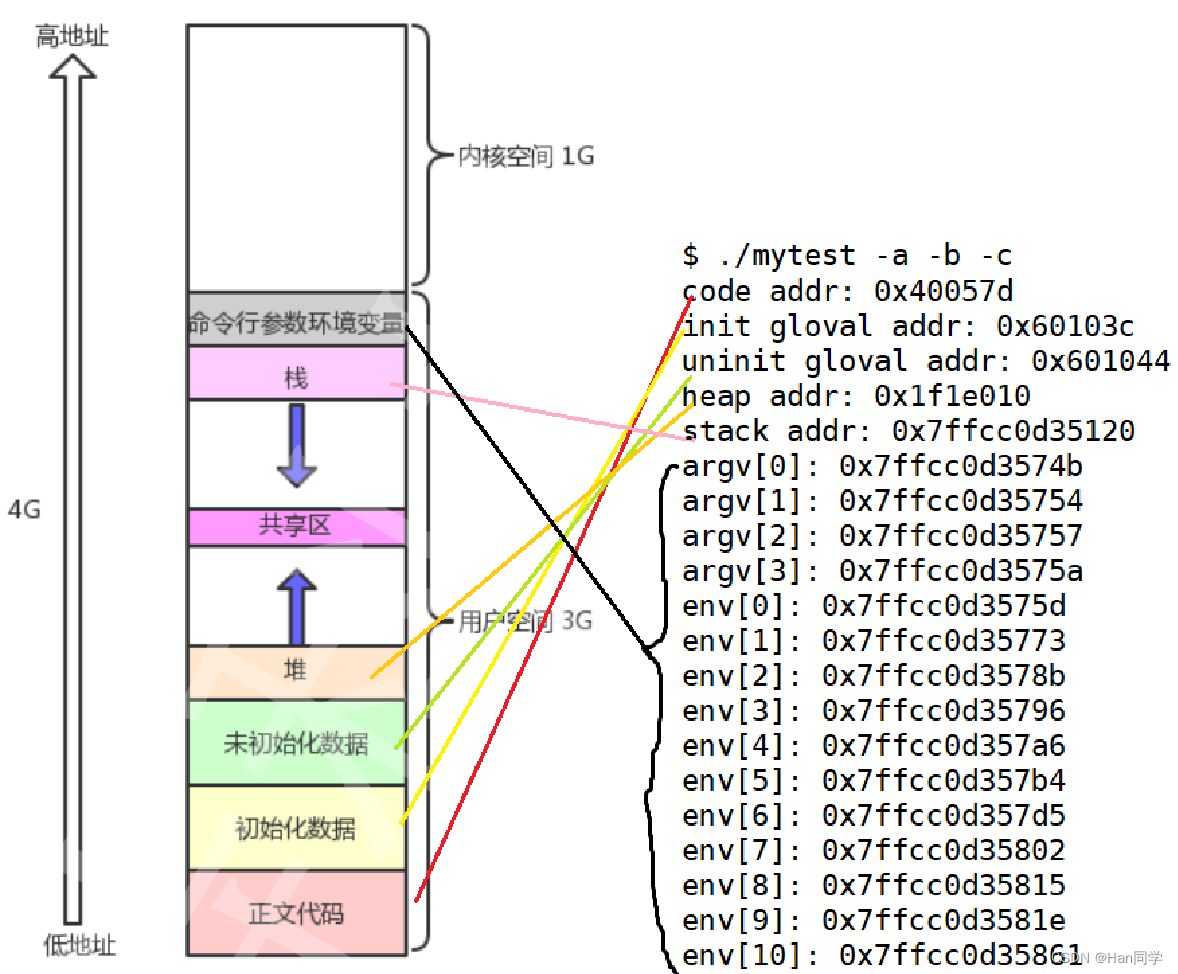
main函数中打印了一些地址信息:code addr打印了main函数的地址。init gloval addr打印了初始化的全局变量g_val的地址。uninit gloval addr打印了未初始化的全局变量g_unval的地址。
-
动态内存分配:
- 使用
malloc分配了 10 字节的堆内存,并打印了分配的地址。
- 使用
-
堆和栈地址:
stack addr打印了指向heap_mem变量的地址,这是在栈上的地址。heap addr打印了分配的堆内存地址。
-
参数和环境变量:
- 通过
argc和argv打印了命令行参数的地址。 - 通过
env打印了环境变量的地址。
- 通过
最后,程序运行时提供了一些命令行参数 -a -b -c 和一些环境变量的地址。
输出结果:
[hbr@VM-16-9-centos distribution]$ ./mytest -a -b -c
code addr: 0x40057d
init gloval addr: 0x60103c
uninit gloval addr: 0x601044
heap addr: 0x1f1e010
stack addr: 0x7ffcc0d35120
argv[0]: 0x7ffcc0d3574b
argv[1]: 0x7ffcc0d35754
argv[2]: 0x7ffcc0d35757
argv[3]: 0x7ffcc0d3575a
env[0]: 0x7ffcc0d3575d
env[1]: 0x7ffcc0d35773
env[2]: 0x7ffcc0d3578b
env[3]: 0x7ffcc0d35796
env[4]: 0x7ffcc0d357a6
env[5]: 0x7ffcc0d357b4
env[6]: 0x7ffcc0d357d5
env[7]: 0x7ffcc0d35802
env[8]: 0x7ffcc0d35815
env[9]: 0x7ffcc0d3581e
env[10]: 0x7ffcc0d35861
env[11]: 0x7ffcc0d35dfd
env[12]: 0x7ffcc0d35e16
env[13]: 0x7ffcc0d35e70
env[14]: 0x7ffcc0d35ea7
env[15]: 0x7ffcc0d35eb8
env[16]: 0x7ffcc0d35ec0
env[17]: 0x7ffcc0d35ecf
env[18]: 0x7ffcc0d35edf
env[19]: 0x7ffcc0d35eeb
env[20]: 0x7ffcc0d35f1a
env[21]: 0x7ffcc0d35f3d
env[22]: 0x7ffcc0d35faf
env[23]: 0x7ffcc0d35fce
env[24]: 0x7ffcc0d35fe4
3、栈&堆
栈:
- 栈是一种后进先出(LIFO)的数据结构,用于存储函数调用时的局部变量、函数参数、返回地址等信息。
- 栈向地址减小方向增长,也就是说,栈顶的地址比栈底的地址小。当新的数据被压入栈时,栈指针向低地址方向移动。
堆:
- 堆是用于动态分配内存的区域,通常由程序员手动管理(例如使用
malloc、calloc、realloc等函数)。 - 堆向地址增大方向增长,也就是说,分配的内存地址会逐渐变大。当程序请求更多的堆内存时,操作系统会在堆的较高地址处分配新的内存块。
我们观察一下栈区和堆区的增长方式。
#include <stdio.h>
#include <stdlib.h>
int main(int argc,char* argv[],char* env[])
{
char *heap_mem=(char*)malloc(10);
char *heap_mem1=(char*)malloc(10);
char *heap_mem2=(char*)malloc(10);
char *heap_mem3=(char*)malloc(10);
printf("heap addr: %p\n",heap_mem);
printf("heap addr: %p\n",heap_mem1);
printf("heap addr: %p\n",heap_mem2);
printf("heap addr: %p\n",heap_mem3);
printf("stack addr: %p\n",&heap_mem);
printf("stack addr: %p\n",&heap_mem1);
printf("stack addr: %p\n",&heap_mem2);
printf("stack addr: %p\n",&heap_mem3);
return 0;
}
- 由于云服务器是64位,所以堆区和栈区的地址相差好几位,可以证明两个区域之间存在较大镂空区域
- 还可以观察到堆向高地址方向增长,栈向低地址方向增长。
heap addr: 0x2480010
heap addr: 0x2480030
heap addr: 0x2480050
heap addr: 0x2480070
stack addr: 0x7ffeca94bce0
stack addr: 0x7ffeca94bcd8
stack addr: 0x7ffeca94bcd0
stack addr: 0x7ffeca94bcc8为什么每次只请求十个字节,但每个分配的内存块之间相差20个字节呢?
- 堆内存分配不仅涉及分配请求的内存量,还包括额外的开销,用于管理堆内存空间。当你请求分配一定大小的内存时,内存管理系统(如malloc库)可能会在分配的内存块中添加额外的信息,如用于维护分配状态、大小和边界对齐的元数据。因此,实际分配的内存块大小可能会比请求的大小更大。
- 在上述例子中,尽管每次调用
malloc(10)只请求10个字节的内存,但每个分配的内存块之间相差20个字节。这个额外的10个字节(20个字节减去请求的10个字节)很可能是由于内存管理系统用于存储管理信息和/或满足对齐要求的开销。这种开销和对齐策略可以根据不同的系统、编译器和内存管理实现而有所不同。 - 堆管理器可能会采取不同的策略来优化性能、减少内存碎片或满足对齐要求,这也会影响到分配的内存块之间的实际距离。因此,不同的环境和配置可能会导致不同的结果。
拓展:
- 当使用
free函数释放内存时,不需要指定要释放的字节数,这是因为内存管理系统(如C语言的malloc库)在分配内存时会记录分配的大小。这种记录通常以一种内部的、对程序员透明的方式进行。- 具体来说,当你调用
malloc或相关函数申请内存时,内存管理系统不仅分配了你请求的字节数,还额外分配了一些内存来存储管理信息,包括分配的内存大小和其他可能的元数据,如分配的内存块的状态。这些信息通常存储在分配给你的内存块附近的位置,但对程序员来说是不可见的。- 因此,当你调用
free释放内存时,内存管理系统可以查阅它之前存储的这些管理信息,了解要释放的内存块的确切大小和位置。这样,free就能正确地释放分配的内存,而不需要程序员指定要释放多少字节。
4、static修饰局部变量
在C和C++中,static 关键字用于修改变量的存储方式和生命周期,具体效果取决于它所修饰的上下文。
-
静态生存期:使用
static关键字修饰的局部变量具有静态生存期,意味着它们在程序的整个执行过程中都存在,而不是在它们所在的作用域结束时被销毁。它们在程序初始化时被分配内存,在程序结束时才释放。 -
作用域限制:
static关键字还可以用于限制变量的作用域。在函数内部,使用static修饰的局部变量的作用域被限制在声明它们的函数内部,不能被其他函数访问。这样可以确保局部静态变量对外部代码是隐藏的。 -
初始化:静态变量在第一次使用前会被初始化。如果没有显式地初始化,静态变量会被初始化为零值(全局静态变量和局部静态变量)或者空指针(静态指针变量)。
-
存储位置:静态变量通常存储在程序的静态存储区,这意味着它们的内存分配发生在编译时而不是运行时。
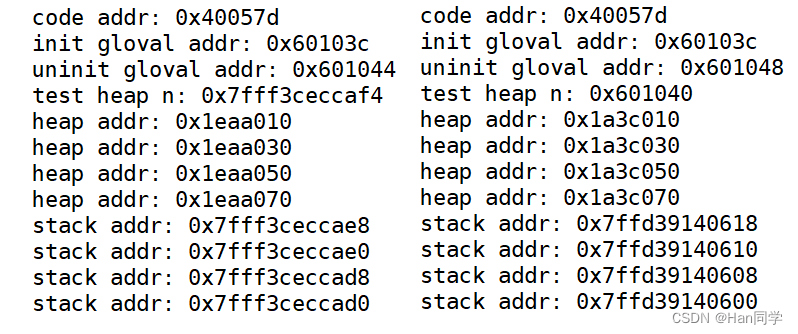
int n=10;//第一次
printf("test heap n: %p\n",&n);
static int n=10;//第二次
printf("test heap n: %p\n",&n);
通过下图可以发现,变量n被static修饰之后,从栈区转移到初始化代码区(静态区的一部分)。
5、字符串常量不可修改
int main(int argc,char* argv[],char* env[])
{
char* str="hello";
printf("read only string addr: %p\n",str);
printf("code addr: %p\n",main);
return 0;
}
输出结果:
read only string addr: 0x400770
code addr: 0x40057d
我们可以看到,字符串跟main函数一样,都存储在只读数据段(静态区) 。
-
只读字符串常量:
char* str = "hello";定义了一个指向常量字符串的指针str,指向的字符串是 "hello"。- 字符串常量通常存储在只读数据段(也称为常量数据段),它们在程序运行期间保持不变,因此被视为静态区的一部分。
- 在这个示例中,
str指向的字符串 "hello" 存储在只读数据段中,其地址被打印出来。
-
代码段地址:
printf("code addr: %p\n", main);打印了main函数的地址,这个地址指向程序的代码段,也被视为静态区的一部分。- 代码段包含程序的机器语言指令,这些指令是编译后生成的,并且在程序运行时保持不变。
6、虚拟地址与物理地址的联系
当进程直接使用物理地址时,存在几个安全性和稳定性方面的问题:
-
缺乏隔离:直接使用物理地址可能会导致进程之间的内存隔离问题。如果一个进程可以直接访问物理地址,它可能会访问到另一个进程的内存,这可能导致信息泄露或修改其他进程的数据,从而破坏系统安全性。
-
不可移植性:直接使用物理地址会使代码与特定硬件平台紧密耦合。这意味着在不同的硬件平台上运行时,代码可能会失效或产生不可预测的行为。
-
难以维护:直接使用物理地址的代码通常更难以理解和维护。由于直接访问物理地址需要更多的手动管理和细节处理,因此代码更容易出错,并且更难以进行调试和维护。
-
缺乏保护机制:操作系统通常会使用虚拟内存机制来提供对内存的保护和隔离。直接使用物理地址会绕过这些保护机制,从而增加系统受到恶意攻击的风险。
因此,为了提高系统的安全性、可移植性和可维护性,通常建议使用虚拟地址而不是直接访问物理地址。操作系统会负责将虚拟地址映射到物理地址,同时提供必要的保护机制和隔离,从而确保系统的稳定性和安全性
二、CPU读取程序全过程
在这整个过程中,虚拟地址的形成是一个逐步的过程,涉及编译器、链接器和操作系统的协作。编译器和链接器负责确定代码和数据在程序内部的相对位置,而操作系统则负责将这些位置映射到虚拟地址空间,并在运行时通过页表将虚拟地址转换为物理地址。
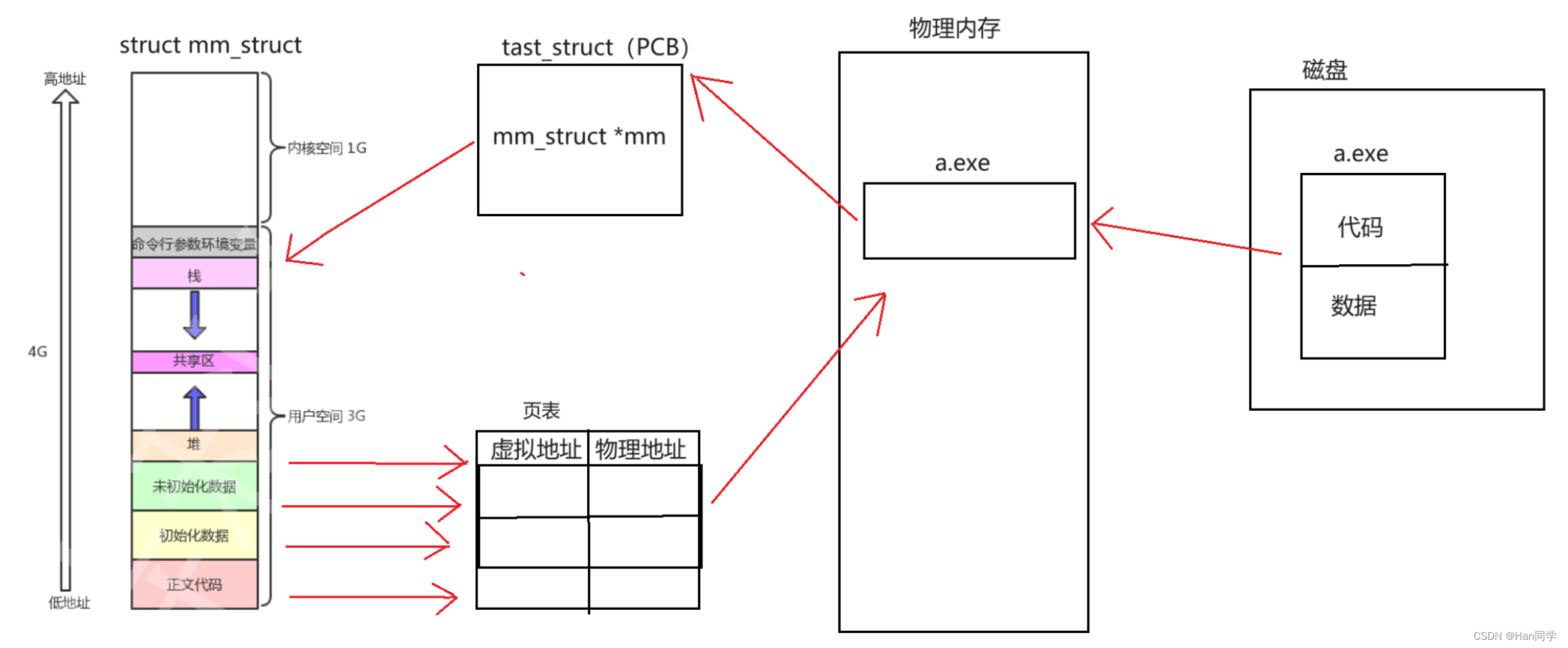
1、形成可执行程序
编译阶段:编译器将源代码转换成机器代码。在这个阶段,编译器主要处理代码逻辑,并生成相对地址或符号引用。这些相对地址和符号引用并不是实际的内存地址;它们只是标记,用于表示数据和函数之间的位置关系。
链接阶段:链接器将多个编译后的代码文件(对象文件)合并为一个单一的可执行文件。在这个过程中,链接器会解析之前编译阶段生成的符号引用,将它们转换成相对于可执行文件起始的偏移量。这些偏移量表明了代码和数据在可执行文件内的位置。
2、生成虚拟地址
装载阶段:当可执行文件被操作系统装载到内存中执行时,装载器负责将文件中的代码和数据放置到进程的虚拟地址空间中。此时,上述偏移量会转化为虚拟地址。这些虚拟地址是进程地址空间中的位置,它们由操作系统根据当前的内存使用情况和程序的需求决定。
到底是编译器编译时分配了虚拟地址还是装载到内存时由偏移量转化为虚拟地址?
- 当我们说编译器在编译时“分配了虚拟地址”,我们实际上是指它为程序中的元素分配了一种形式的地址(符号地址或偏移量),这些地址在链接和装载阶段会被进一步处理和转换。最终,当程序被装载到内存中时,这些偏移量会被转化成真正的虚拟地址,程序才能在这些地址上执行。所以,从一种角度来说,两种描述都是正确的,但它们分别强调了程序处理过程中的不同阶段。
3、程序的启动
-
从磁盘到内存:当一个程序(可执行文件)被启动时,操作系统首先从磁盘中将程序的代码和数据加载到物理内存中。这个过程涉及到文件系统和I/O系统。
4、创建进程
-
进程控制块(PCB):操作系统为新的程序执行创建一个进程实例。每个进程都有一个PCB,它包含了进程的元数据,如进程ID、进程状态、程序计数器(PC)、寄存器状态、进程优先级、地址空间信息、页表等。
-
地址空间分配:操作系统为进程分配一个虚拟地址空间,这个地址空间为进程提供了一个连续的内存视图,独立于物理内存的实际布局。
5、地址映射(虚拟内存管理)
-
页表:操作系统(内存管理单元MMU)使用页表来管理虚拟地址到物理地址的映射。页表为每个进程维护,确保了进程地址空间的隔离性。
-
内存访问:当程序需要访问内存时(例如,执行一条指令或访问一个变量),它会使用虚拟地址。CPU通过查找页表来将虚拟地址转换为物理地址,然后访问对应的物理内存。
6、程序执行
-
程序计数器(PC):PC存储了下一条要执行的指令的地址。在程序执行时,CPU使用PC来获取当前指令,然后更新PC以指向下一条指令。
-
执行指令:CPU执行指令,这可能涉及到读写内存、进行计算、条件跳转等操作。这些指令使用的地址都是虚拟地址,需要通过页表转换为物理地址。
7、数据的存取
-
从物理内存到CPU:一旦虚拟地址被转换为物理地址,CPU就可以直接访问物理内存中的数据或代码了。
-
缺页中断:如果访问的数据不在物理内存中(例如,还在磁盘上),将会触发缺页中断。操作系统会从磁盘中加载缺失的数据到物理内存,然后更新页表,并重新执行导致中断的指令。
8、进程切换
-
上下文切换:操作系统可能会进行进程切换,暂停当前进程的执行,切换到另一个进程。这涉及到保存当前进程的状态(例如,保存PCB中的程序计数器和寄存器状态)并恢复另一个进程的状态,以便之后可以继续执行。这保证了每个进程都有机会运行,同时维护各自独立的地址空间和执行状态。
内存管理单元(MMU)和页表
内存管理单元(MMU)和页表是两个相关但不同的概念:
-
内存管理单元(MMU): MMU是计算机硬件的一部分,负责处理虚拟地址到物理地址的转换。它是处理器内或与处理器紧密相关的一个硬件模块。MMU通常使用分页机制来管理内存,它使得操作系统可以实现虚拟内存系统,其中程序使用的地址(虚拟地址)和实际的物理内存地址是分开的。MMU还负责检查内存访问权限,确保进程不会访问非法的内存区域。
-
页表: 页表是内存管理中使用的一种数据结构,它存储虚拟页面和物理页面之间的映射关系。操作系统维护页表以跟踪哪些虚拟内存页映射到物理内存的哪些页上。当程序尝试访问虚拟地址时,MMU会使用页表来查找相应的物理地址,并将虚拟地址转换为物理地址。页表通常存储在内存中,MMU在执行地址转换时会查询这些表。
简而言之,MMU是负责虚拟到物理地址转换的硬件,而页表是这种转换所依赖的数据结构,它由操作系统维护并存储在内存中。两者共同工作以实现虚拟内存系统,提高内存的使用效率和安全性。
三、为什么需要地址空间?
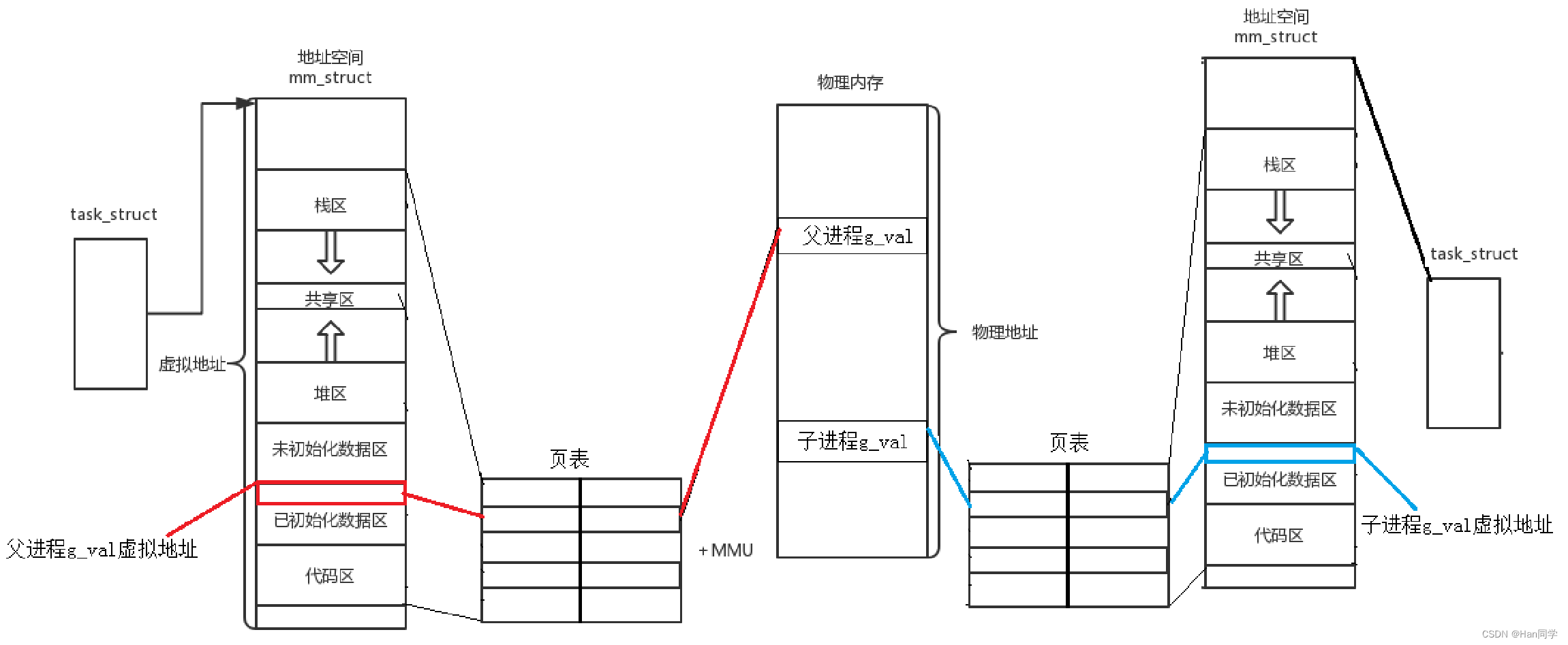
原因1:地址空间+页表对非法访问进行有效拦截 ,有效的保护了物理内存。
我们先看两个例子:
(1)根据字符常量的虚拟地址分配物理地址的过程是对其进行修改了吗,那为什么字符常量又是不能修改的呢?
- 对字符常量的虚拟地址进行分配物理地址的过程通常是在程序加载时进行的,但这个过程并不意味着对字符常量本身进行了修改。在程序加载时,操作系统会将程序的可执行文件中的代码段、数据段等部分加载到内存中,并为其分配物理地址。字符常量通常会被加载到只读的内存段中,以保证其不可修改。
- 虚拟地址和物理地址之间的映射是由操作系统的内存管理单元(MMU)来实现的,这种映射是基于页表的。当程序访问字符常量时,操作系统会根据虚拟地址找到对应的物理地址,并将数据返回给程序。但是,即使这个映射的过程会导致字符常量对应的物理地址被访问,但操作系统依然会在页表中设置对应的页面的读写权限为只读,这样即使程序尝试修改字符常量,由于页表的设置,操作系统会阻止这种修改。
- 因此,尽管虚拟地址分配给字符常量的物理地址的过程涉及到对内存映射的修改,但字符常量本身依然是不可修改的,因为操作系统确保了对字符常量所在内存页面的只读访问权限。
(2)所有的进程崩溃本质上就是进程退出,是谁让他退出了?是操作系统杀掉了这个进程,编译语言上出了问题,是系统层面干掉这个进程。
-
操作系统强制终止: 操作系统在监控进程运行过程中,如果发现进程执行了非法操作、访问了未分配的内存、耗尽了系统资源(如内存、CPU 时间等),或者出现了其他严重错误,操作系统会强制终止该进程,以保护系统的稳定性和安全性。
-
编程语言运行时错误:
当编译语言的代码在运行时出现问题时,通常是由于编译后生成的机器代码执行时发生了错误,例如访问了无效的内存地址、执行了非法操作码等。在这种情况下,操作系统可能会检测到进程的异常行为,并采取措施终止该进程,以防止对系统的进一步损害或影响。
操作系统通过监视进程的行为来检测异常情况,比如访问未分配的内存、执行了非法的指令、耗尽了系统资源等。一旦检测到异常行为,操作系统会采取相应的措施,例如向用户发送错误消息、终止进程、记录日志等。
因此,当编译语言的代码出现问题时,系统层面可能会干掉这个进程,以保护系统的稳定性和安全性,同时也为用户提供了及时的反馈和诊断信息
原因1、 地址空间+页表对非法访问进行有效拦截 ,有效的保护了物理内存。
因为地址空间和页表是OS创建并维护的,也就意味着凡是想使用地址空间和页表进行映射,也一定要在OS的监管之下来进行访问,这样便保护了物理内存中的所有的合法数据包括各个进程,以及内核的相关有效数据!
原因2、内存管理和进程管理解耦
由于地址空间和页表映射的存在,物理内存的分配和进程的管理可以独立进行,实现了两者的解耦。这使得物理内存可以灵活地加载数据,而不受进程管理的约束。例如,在C或C++语言中,使用
malloc申请内存实际上是在虚拟地址空间中进行,物理内存的分配则是延迟进行的,以提高效率。
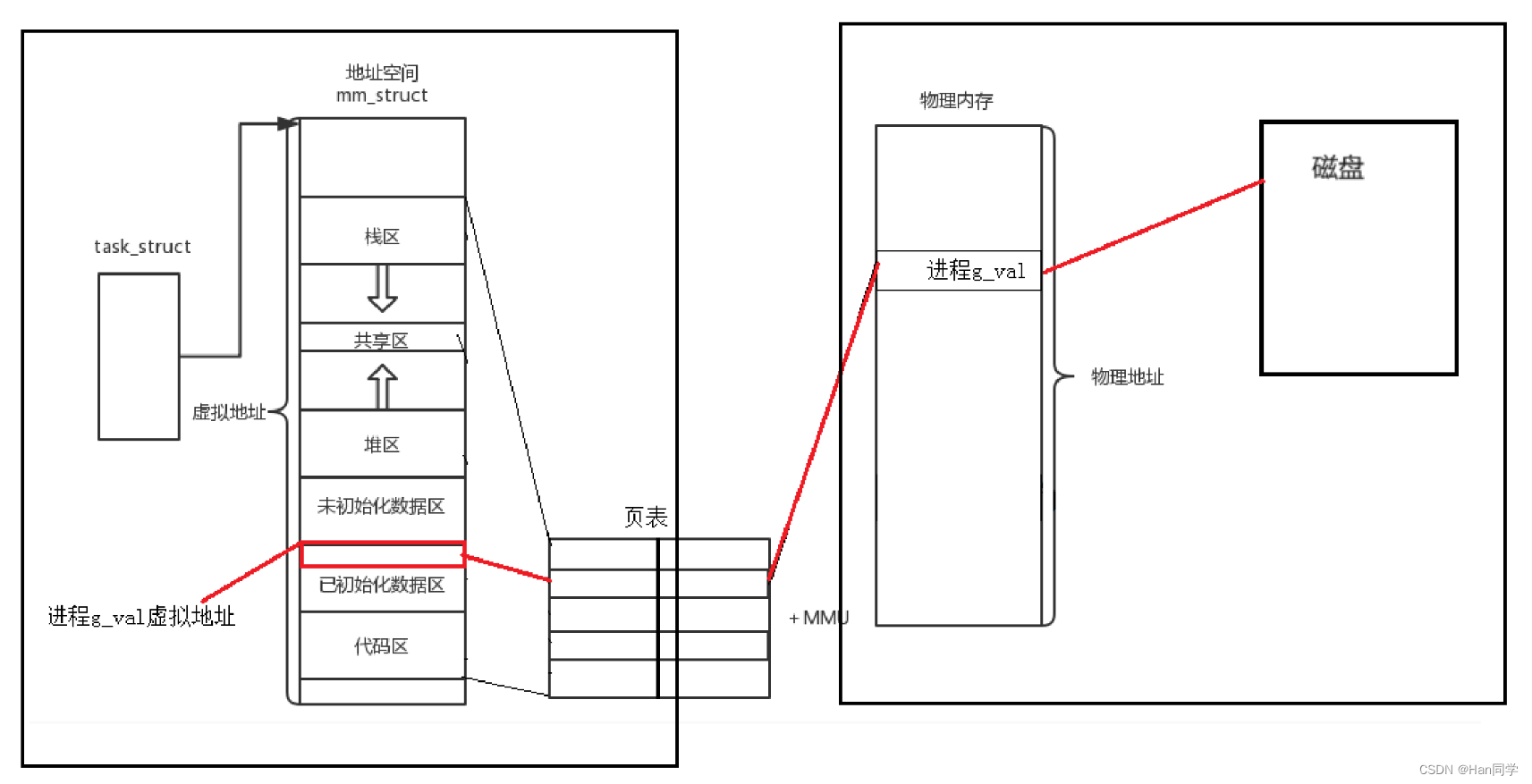
问题一:因为有地址空间的存在,因为有页表的映射的存在,我们的物理内存中,是不是可以对未来的数据进行任意位置的加载?
- 当然可以!! 物理内存的分配就可以 和 进程的管理,可以做到没有关系! !
内存管理模块进程管理模块就完成了解耦合!
所以,我们在C、C++语言上,malloc空间的时候,本质是在哪里new,申请的呢??
- 答案是虚拟地址空间
问题二:如果我申请了物理空间,但是如果我不立马使用? 是不是空间的浪费呢?
- 是的,当我们在C或C++中使用
malloc来申请内存时,实际上是在虚拟地址空间中进行操作,而不是直接在物理内存上分配。 - 这种机制允许操作系统采用延迟分配策略,即在内存被实际访问之前,不立即分配物理内存。这样,如果应用程序申请了内存空间但暂时未使用,系统可以避免不必要的物理资源分配,从而提高效率。
- 本质上,(因为有地址空间的存在,所以上层申请空间,其实是在地址空间上申请的,物理内存,甚至可以一个字节都不给你!!
- 而当你真正进行对物理地址空间访问的时候(-- 是由操作系统,自动完成,用户,包括进程,完全0感知! !),才执行内存的相关管理算法,帮你申请内存,构建页表映射关系,然后,在让你进行内存的访问。
问题三:怎么知道虚拟地址分配了,而物理地址没分配呢?
- 当操作系统检测到一个虚拟地址被访问,但还没有分配对应的物理内存时,会通过缺页中断机制进行处理,即在这个时刻才进行物理内存的分配和页表映射的构建,允许进程访问内存。这种方法确保了内存使用的效率几乎达到100%,因为只有在真正需要时才分配物理资源。
原因3、维护进程独立性
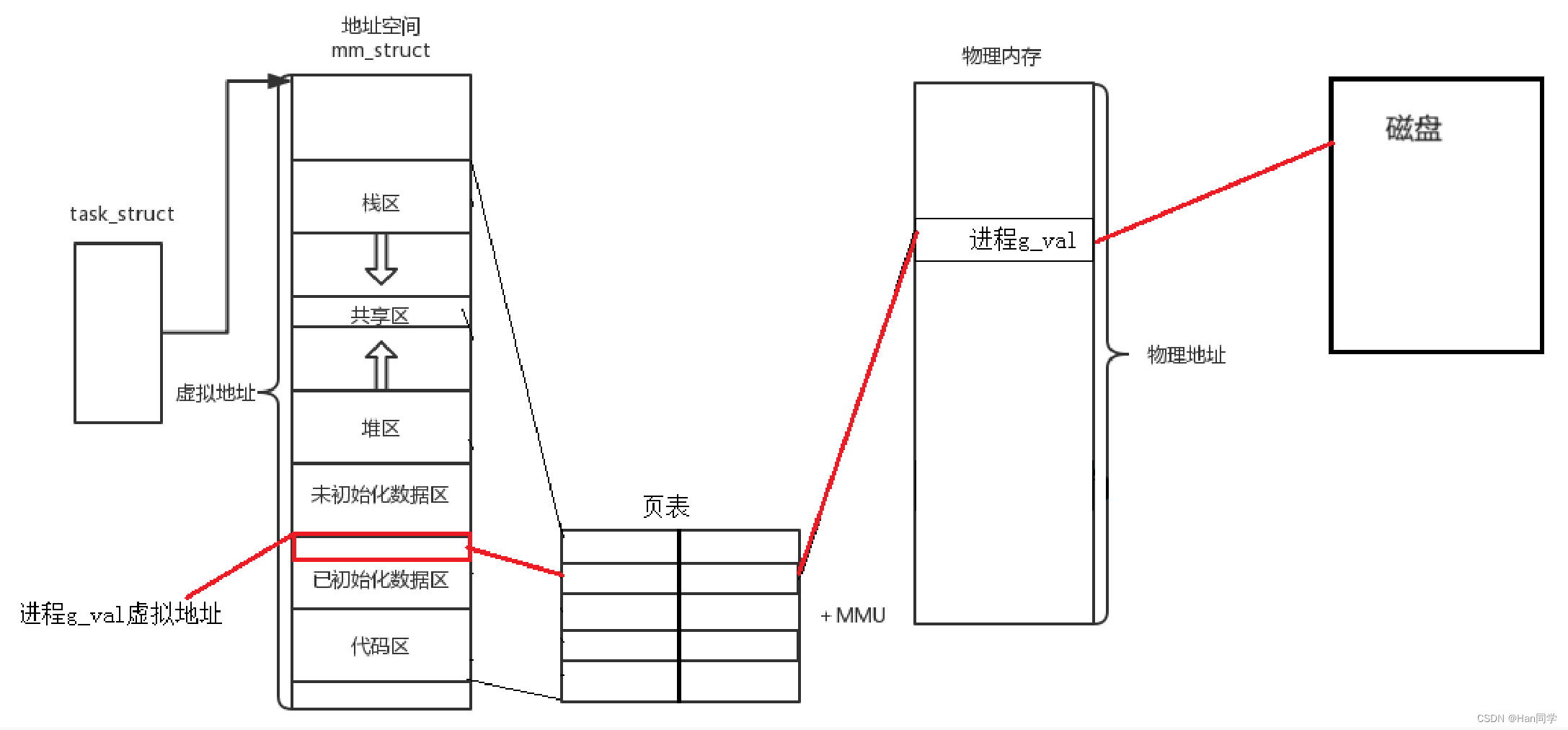
- 因为在物理内存中理论上可以任意位置加载,这意味着从物理角度看,物理内存中的几乎所有的数据和代码在内存中是乱序的,呈现出乱序的状态。
- 但是,因为页表机制的存在,它可以将地址空间上的虚拟地址和物理地址进行映射,那么是不是在进程视角所有的内存分布,因此即使物理内存中的内容是乱序的,进程视角下的内存分布却可以是有序的。
地址空间+页表的存在可以将内存分布,有序化!
可以理解为:地址空间是操作系统给进程画的大饼,
结合原因二:进程要访问的物理内存中的数据和代码,可能目前并没有在物理内存中,同样的,也可以让不同的进程映射到不同的物理内存,是不是边很容易做到,这就是进程独立性的实现!。
进程的独立性,可以通过地址空间+页表的方式实现。
因为有地址空间的存在,每个进程都认为自己拥有一个完整、有序的内存区域(例如,在32位系统中是4GB),并且各个区域是有序的,进而可以通过页表映射到不同的区域,来实现进程的独立性。每一个进程不知道,也不需要知道其他进程的存在!
地址空间的概念和实现是现代操作系统设计中的一项核心技术,它允许每个进程拥有独立的内存空间,从而实现了内存保护、内存管理的高效性和进程的独立性。这里简要整理并润色上述讨论的要点:
为什么需要地址空间?
-
内存保护: 地址空间和页表机制使操作系统能够有效地防止非法访问,保护物理内存中的有效数据,包括各个进程以及内核的相关数据。这是因为操作系统创建并维护了地址空间和页表,所有对物理内存的访问都必须通过操作系统的管理,从而保证了物理内存的安全。
-
内存管理和进程管理解耦: 由于地址空间和页表映射的存在,物理内存的分配和进程的管理可以独立进行,实现了两者的解耦。这使得物理内存可以灵活地加载数据,而不受进程管理的约束。例如,在C或C++语言中,使用
malloc申请内存实际上是在虚拟地址空间中进行,物理内存的分配则是延迟进行的,以提高效率。 -
有效利用内存: 地址空间的存在允许实现延迟分配策略,从而优化内存使用。即使在上层应用申请了大量空间,操作系统可以不立即在物理内存中分配相应空间,而是在实际访问时才进行分配和页表映射,通过缺页中断机制实现。这样做可以近乎实现100%的内存使用效率。
-
有序化内存分布: 虽然物理内存中的数据和代码可能是乱序存储的,但是通过页表映射,每个进程从自己的视角看到的内存分布都是有序的。这大大简化了程序的内存访问模式。
-
进程独立性: 每个进程都拥有自己的地址空间,仿佛它独占了整个系统资源。这种设计不仅实现了进程间的隔离,保证了进程的独立性和安全性,还使得每个进程都无需知晓其他进程的存在,每个进程都认为自己拥有完整的内存空间(如32位系统中的4GB)。
四、重新理解“新建状态”和“挂起”概念
在操作系统中,进程的创建并不意味着必须立即将所有的程序代码和数据完全加载到内存中。实际上,进程创建仅需要建立基本的内核数据结构以及必要的映射关系即可。这种最基础的形态,其中可能仅有内核数据结构被初始化(创建),被称为“新建状态”。
这种设计允许了对程序的“分批加载”,即按需逐步将程序数据从磁盘加载到内存中。相对应地,这也支持了“分批换出”的概念,即将内存中的数据按需回写到磁盘以释放内存空间。特别是在进程因阻塞等原因短时间内不会被执行时,其代码和数据可以被换出到磁盘,这一过程称为“挂起”。
在进行页表映射时,操作系统不仅映射内存中的位置,也能映射磁盘上的存储位置。这样的设计使得操作系统能有效管理内存资源,同时保证了进程执行的连续性和数据的完整性,实现了高效的内存和磁盘管理策略。