文章目录
- 发现宝藏
- 一、ddddOcr(针对图形验证码)
- 1. 工具介绍
- 2. 安装及环境支持
- 3. 识别示例1
- 4. 识别示例2
- 二、Tesseract(标准OCR识别)
- 1. 工具介绍
- 2. 配置系统环境
- 3. 识别示例1
- 4. 识别示例2
- 3. 识别示例3
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。
一、ddddOcr(针对图形验证码)
1. 工具介绍
相信做自动化测试的同学一定不可忽视的问题就是验证码,他几乎是一个网站登录的标配,当然,我一般是不建议在这上面浪费时间去做识别的。
举个例子,现在你的目的是进入自己家的房子,房子为了防止小偷进入于是上了一把锁。我们没必要花费力气去研究开锁技术。去找锁匠配置一把万能钥匙(让开发设置验证码的万能码),或者干脆先去上锁匠把验证码去掉(让开发暂时屏蔽验证码)。严格来说识别验证码不是我们自动化测试的重点。除非你是验证码厂商的员工,破解识别验证码是你的工作。
那么,如果有很简单的方式去识别验证码的话,我们其实就可以不用麻烦开发针对验证码做屏蔽开关了。
ddddocr: 带带弟弟OCR通用验证码识别SDK 就是这样一款强大验证码识别工具。
ddddocr是由sml2h3开发的专为验证码厂商进行对自家新版本验证码难易强度进行验证的一个python库,其由作者与kerlomz共同合作完成,通过大批量生成随机数据后进行深度网络训练,本身并非针对任何一家验证码厂商而制作,本库使用效果完全靠玄学,可能可以识别,可能不能识别。
ddddocr奉行着开箱即用、最简依赖的理念,尽量减少用户的配置和使用成本,希望给每一位测试者带来舒适的体验
OCR部分应该已经有很多人做了测试,在这里就放一部分网友的测试图片。

2. 安装及环境支持
python <= 3.9
Windows/Linux/Macos..
暂时不支持Macbook M1(X),M1(X)用户需要自己编译onnxruntime才可以使用
安装命令
pip install ddddocr
以上命令将自动安装符合自己电脑环境的最新ddddocr
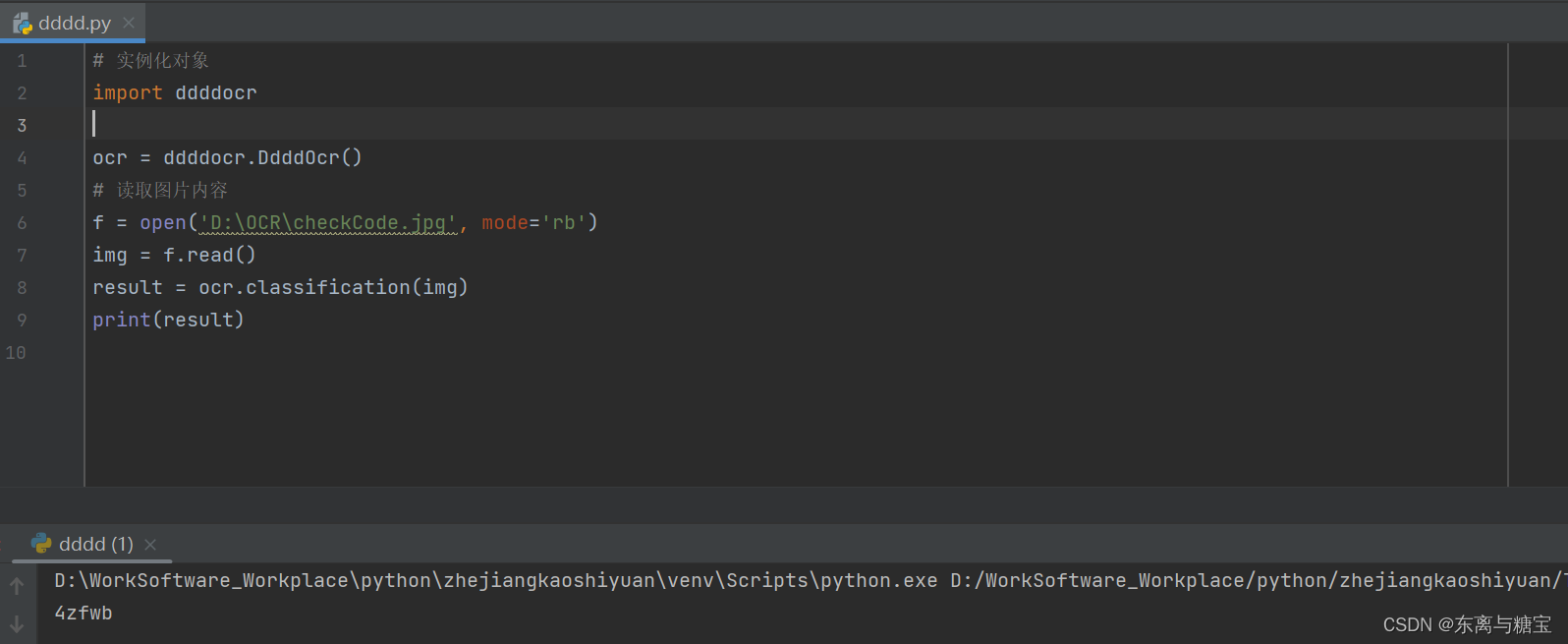
3. 识别示例1
- 代码示例
# 实例化对象
import ddddocr
ocr = ddddocr.DdddOcr()
# 读取图片内容
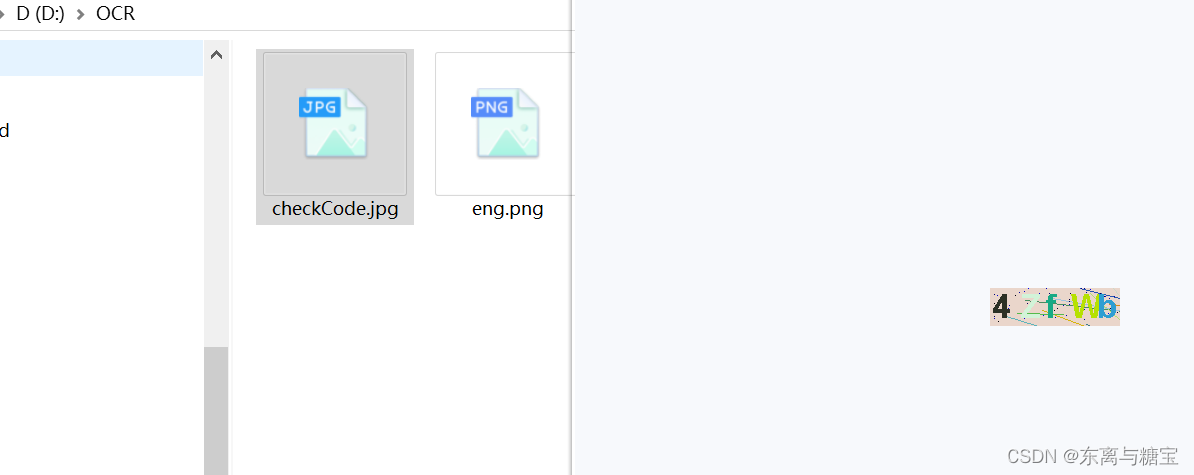
f = open('D:\OCR\checkCode.jpg', mode='rb')
img = f.read()
result = ocr.classification(img)
print(result)
- 运行结果
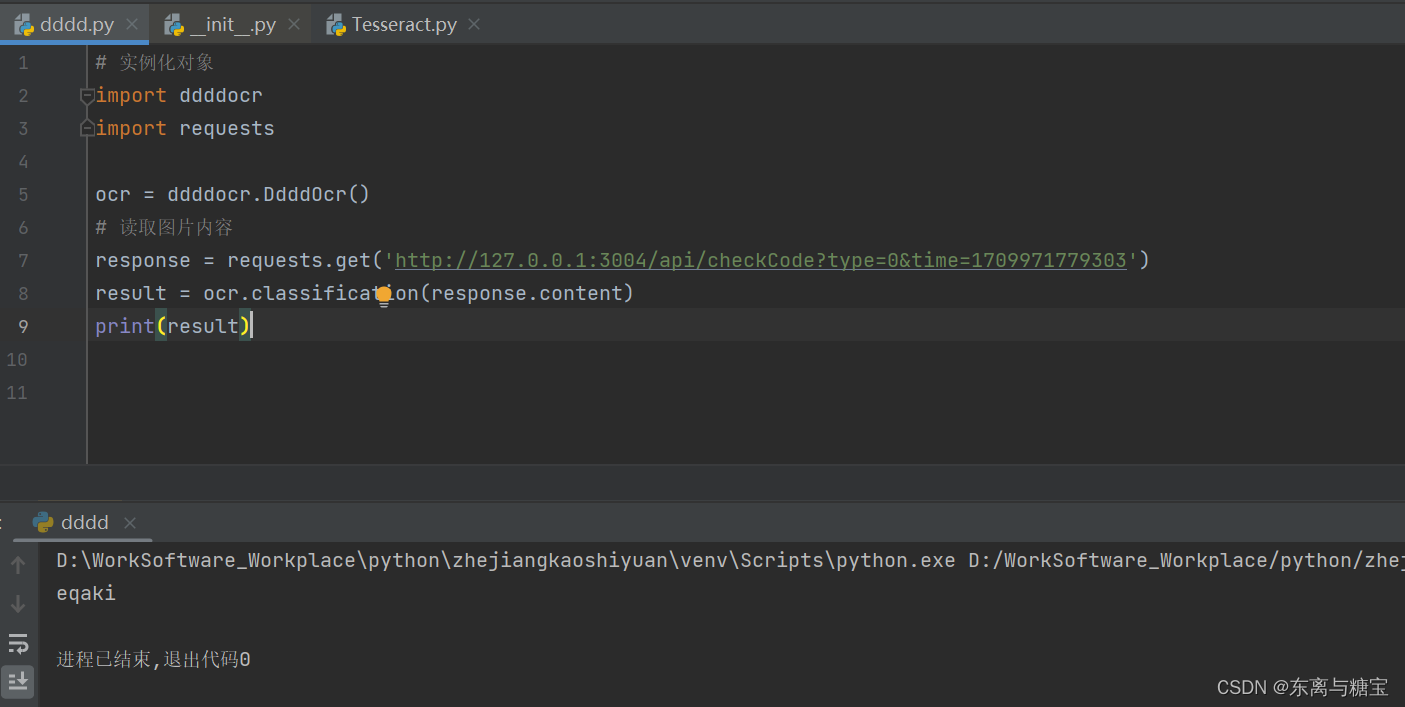
4. 识别示例2
- 代码示例
# 实例化对象
import ddddocr
import requests
ocr = ddddocr.DdddOcr()
# 读取图片内容
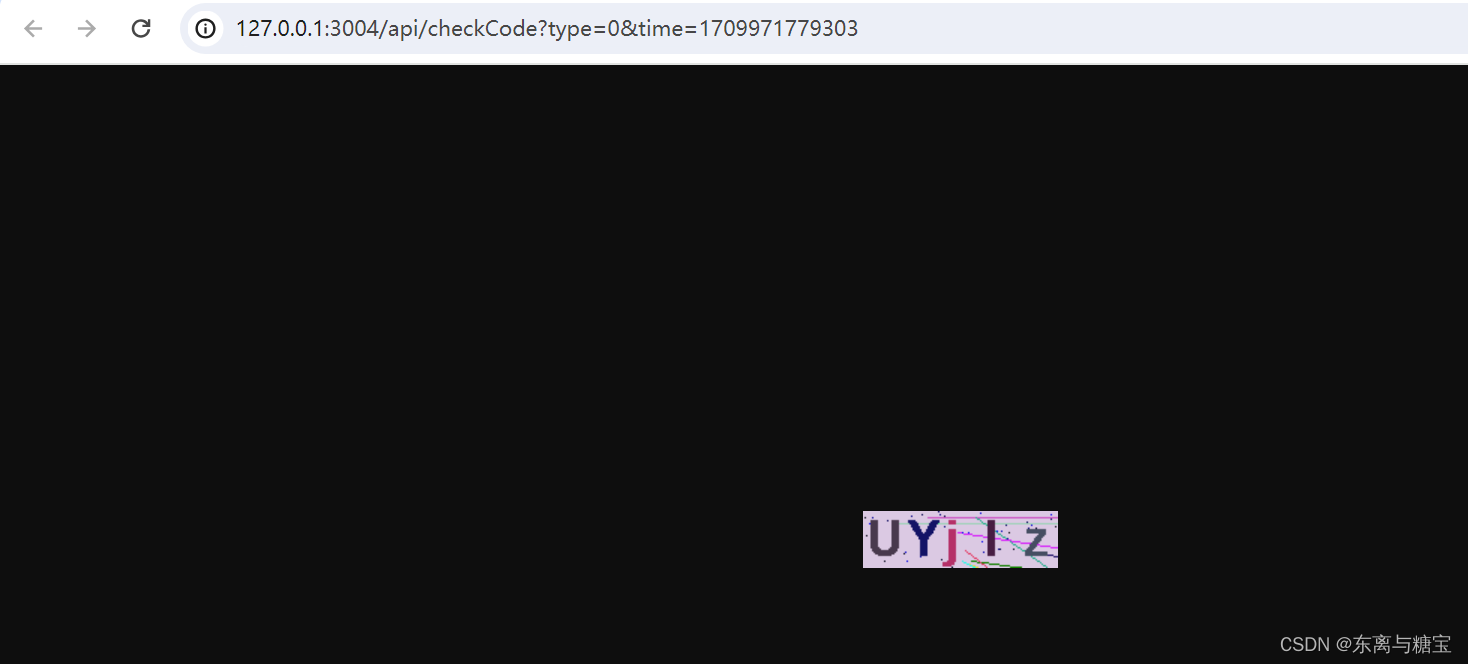
response = requests.get('http://127.0.0.1:3004/api/checkCode?type=0&time=1709971779303')
result = ocr.classification(response.content)
print(result)
二、Tesseract(标准OCR识别)
1. 工具介绍
Tesseract-OCR(Optical Character Recognition)是一个开源的光学字符识别引擎,由Google开发并维护。它用于将图像中的文字转换为可编辑文本,可以识别各种语言的文本,并且在适当的情况下,也可以用于识别印刷体和手写体。
以下是一些关于Tesseract-OCR工具的介绍:
开源性质: Tesseract-OCR是一个免费的开源工具,可以自由地使用和分发。这意味着你可以在自己的项目中免费使用它,也可以根据需要进行修改和定制。
跨平台支持: Tesseract-OCR可在多个操作系统上运行,包括Windows、Linux和macOS等。这使得它成为一个跨平台的解决方案,可以在各种环境中使用。
多语言支持: Tesseract-OCR支持超过100种语言的文字识别,包括中文、英文、法文、德文、日文等。这使得它在全球范围内都有广泛的应用。
高准确性: Tesseract-OCR经过多年的开发和改进,具有较高的文字识别准确性。它能够识别多种字体和字型,即使在低分辨率或模糊的图像中也能表现良好。
简单易用: 使用Tesseract-OCR进行文字识别通常是非常简单的。它提供了命令行接口和API接口,可以轻松地集成到各种应用程序和开发项目中。
可定制性: 虽然Tesseract-OCR在默认配置下已经表现出色,但也可以通过配置文件和参数进行定制,以满足特定需求。你可以调整字体、语言、图像处理方法等参数,以获得更好的识别结果。
GitHub 地址: https://gitcode.com/tesseract-ocr/tesseract?utm_source=csdn_github_accelerator&isLogin=1
安装包官方下载地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
语言包下载地址:https://github.com/tesseract-ocr/tessdata
2. 配置系统环境
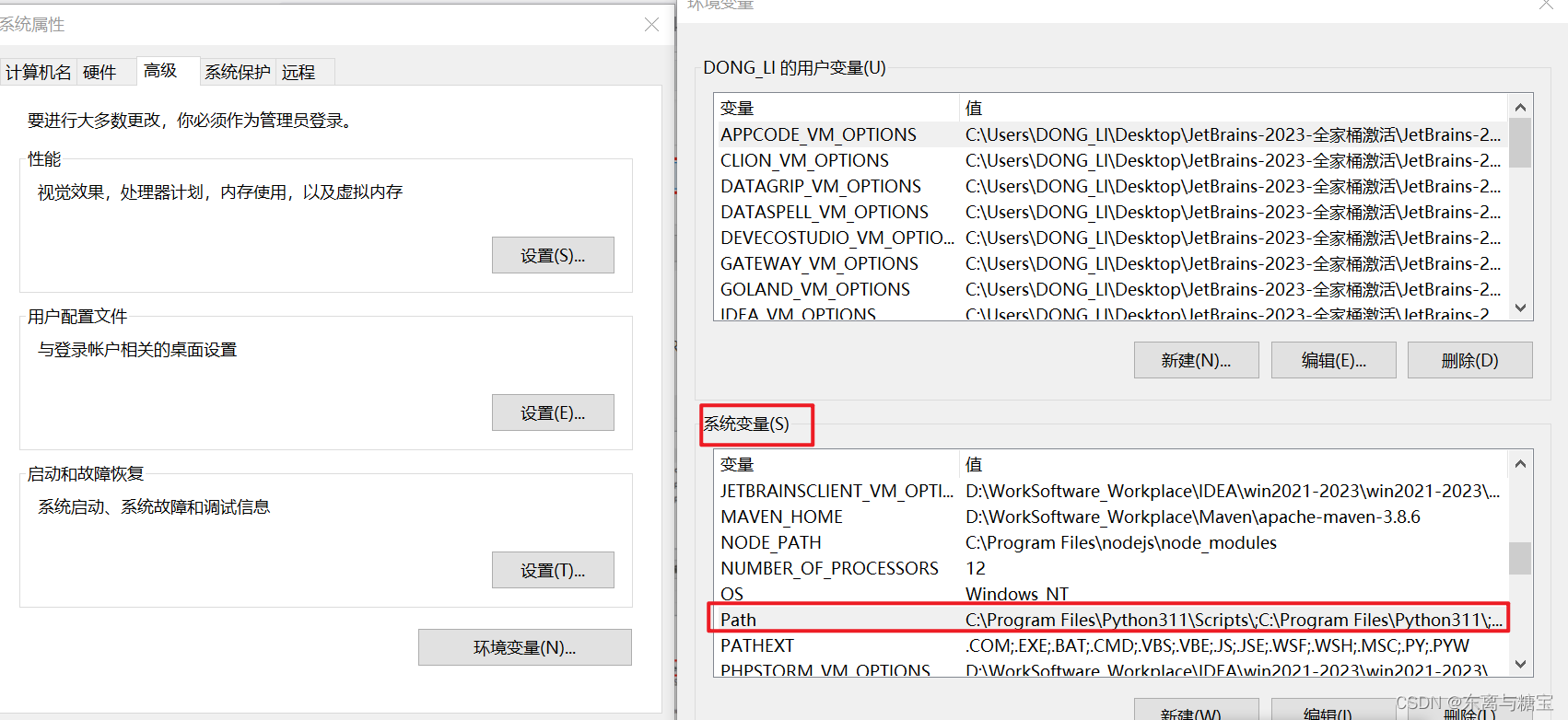
- 右击此电脑选择高级设置,在系统变量的path属性中添加安装路径
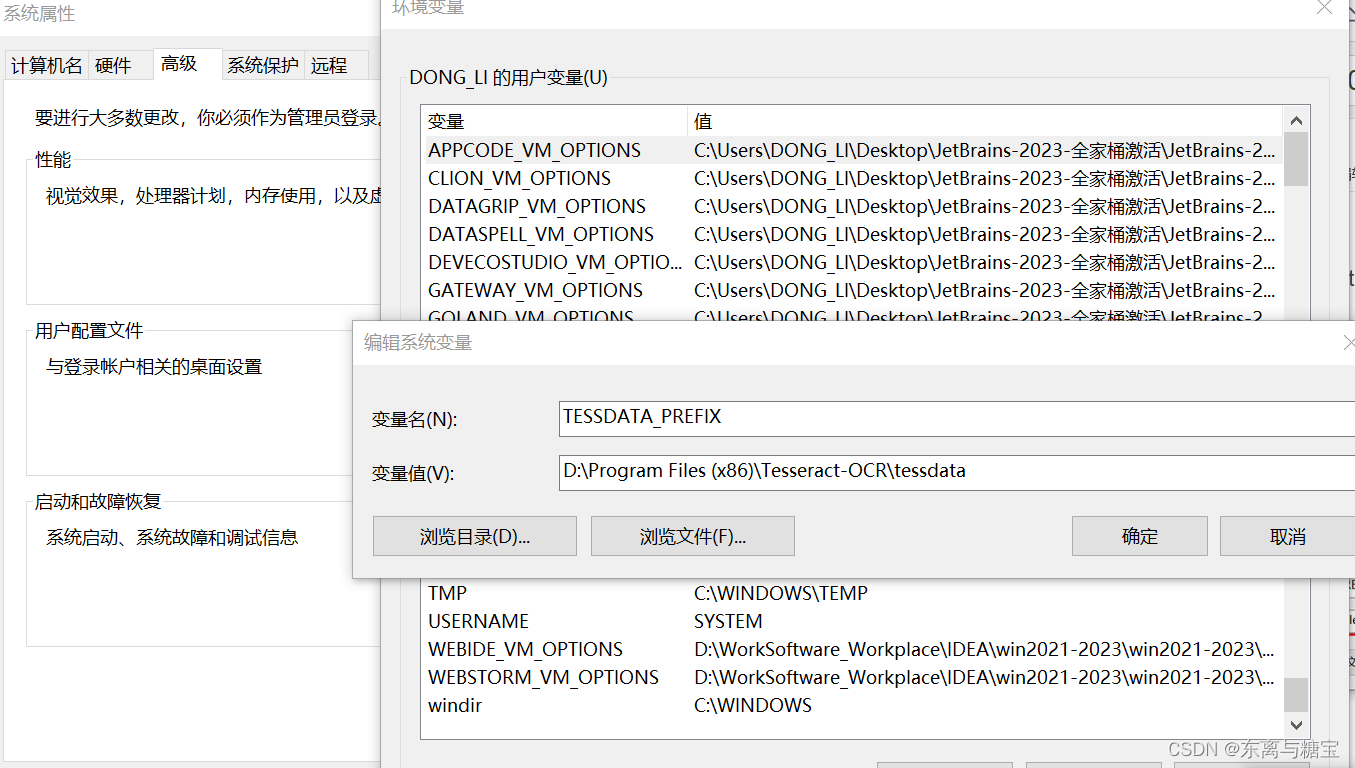
- 添加 tessdata 系统变量
如下图新建系统变量 : TESSDATA_PREFIX
变量值为 tessdata 文件夹的路径(在Tesseract-OCR的安装目录下):
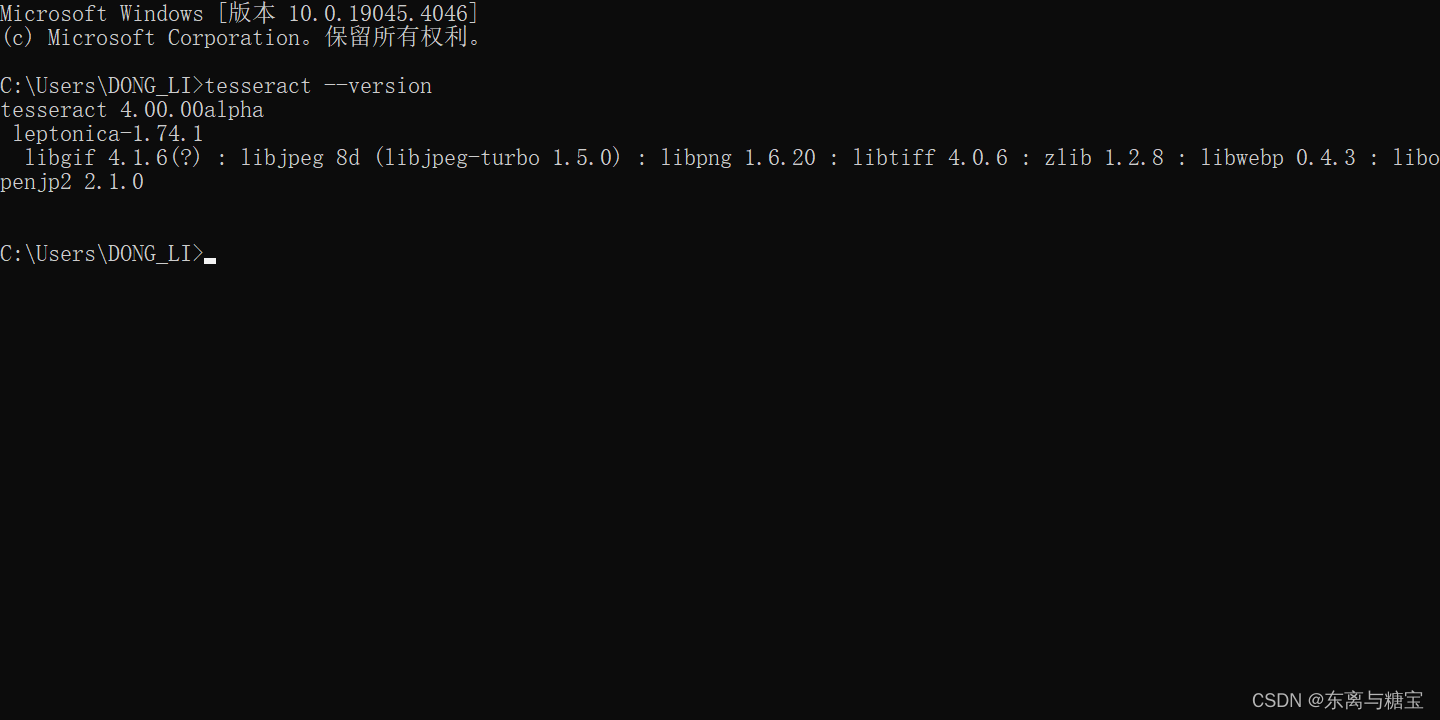
- cmd查看是否安装成功
tesseract --version
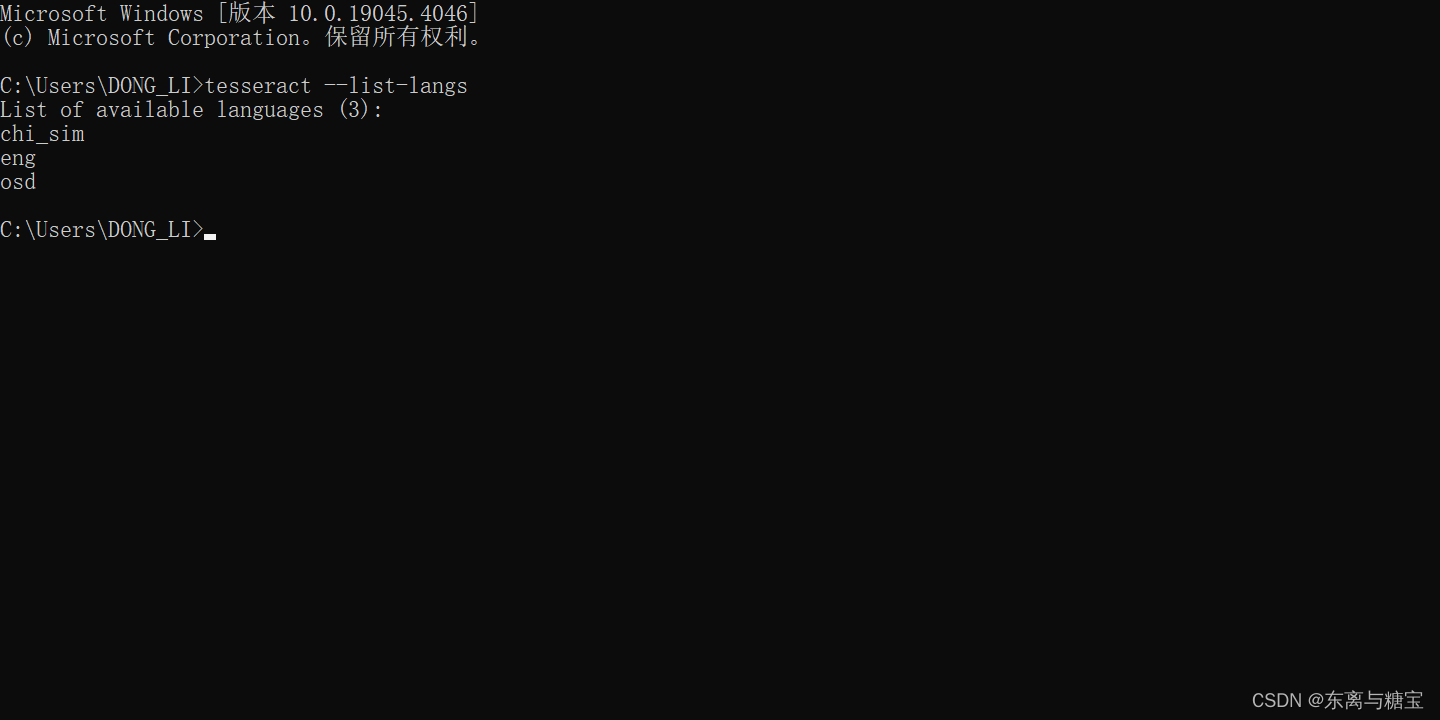
- 查看已经安装的语言
在cmd中输入tesseract --list-langs回车,若显示版本号即为安装成功。
3. 识别示例1
(自带英文,无需额为下载语言包)
- 代码示例
import pytesseract
from PIL import Image
def demo():
# 打开要识别的图片
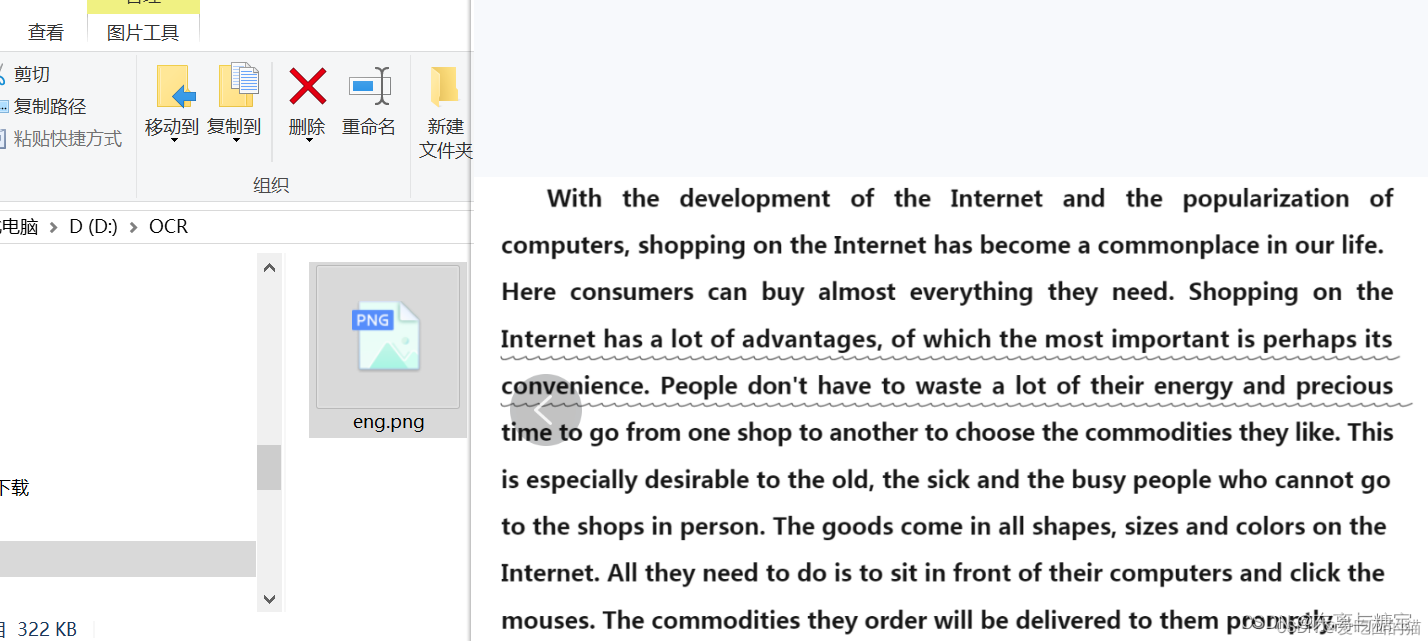
image = Image.open('D:/OCR/eng.png')
# 使用pytesseract调用image_to_string方法进行识别,传入要识别的图片,lang='chi_sim'是设置为中文识别,
text = pytesseract.image_to_string(image, lang='eng')
# 输入所识别的文字
print(text)
if __name__ == '__main__':
demo()
- 运行结果
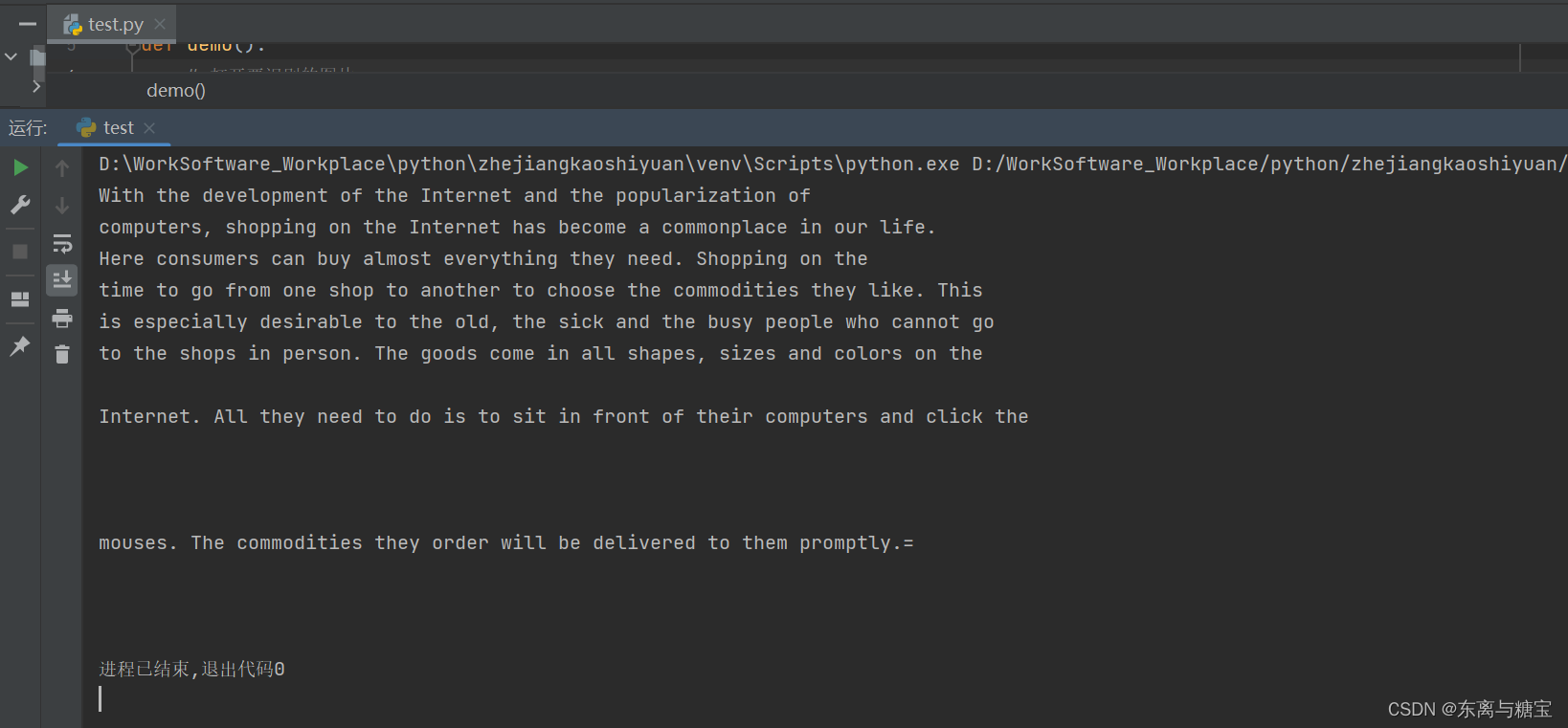
4. 识别示例2
- 在官网下载中文识别语言包,放到 D:\Program Files (x86)\Tesseract-OCR\tessdata (安装目录)下

2.代码示例
import pytesseract
from PIL import Image
def demo():
# 打开要识别的图片
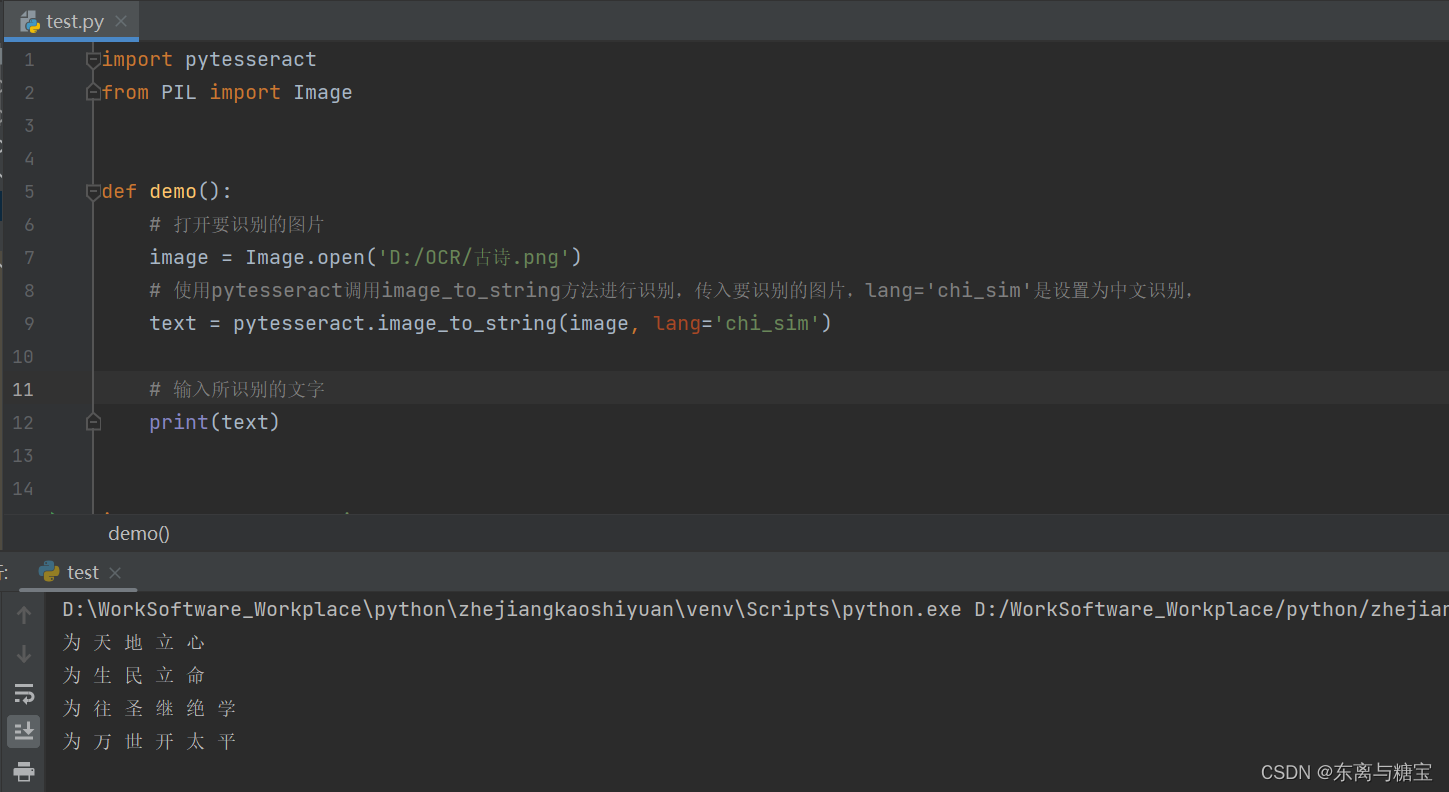
image = Image.open('D:/OCR/古诗.png')
# 使用pytesseract调用image_to_string方法进行识别,传入要识别的图片,lang='chi_sim'是设置为中文识别,
text = pytesseract.image_to_string(image, lang='chi_sim')
# 输入所识别的文字
print(text)
if __name__ == '__main__':
demo()
- 运行结果

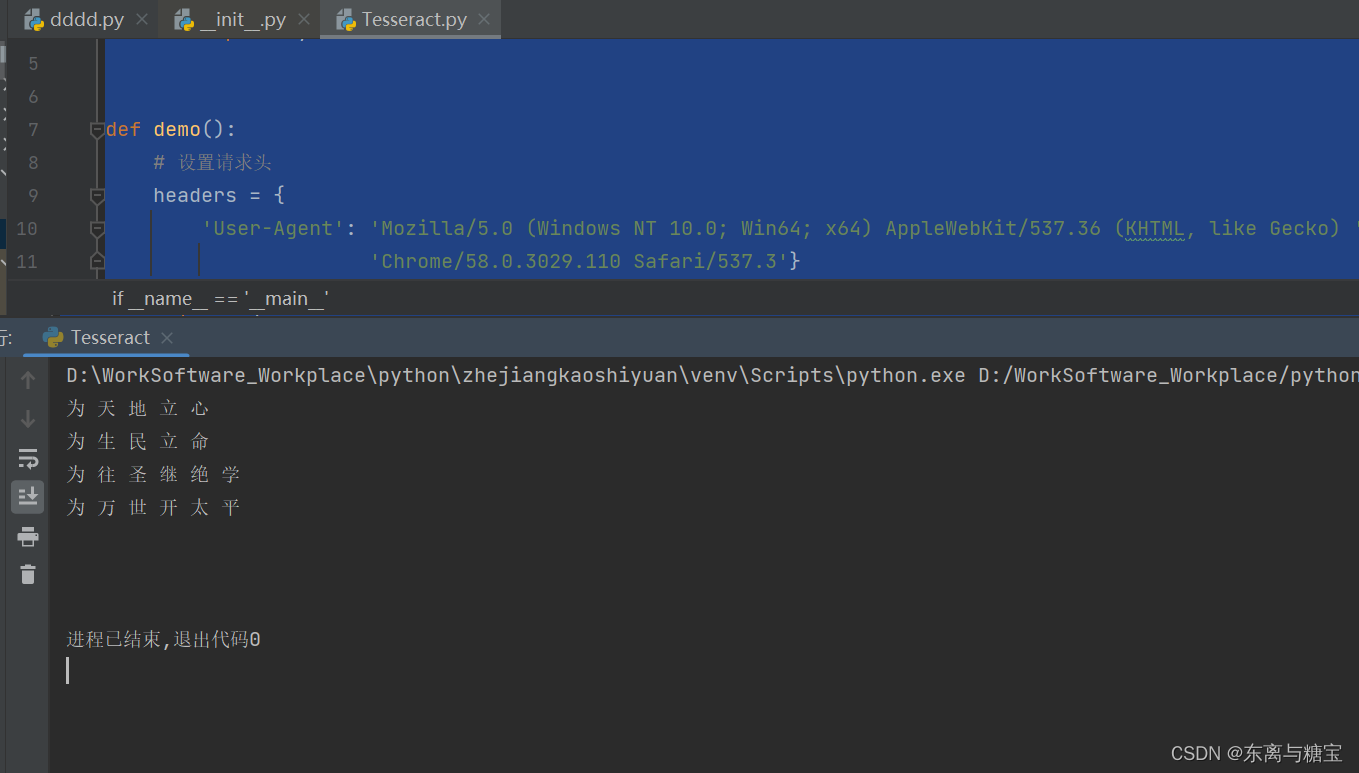
3. 识别示例3
import pytesseract
import requests
from PIL import Image
from io import BytesIO
def demo():
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/58.0.3029.110 Safari/537.3'}
# 获取图片并转换为PIL Image对象
response = requests.get(
'https://img-blog.csdnimg.cn/591e6f372b8c419fb3a00093a1f5ad92.png?x-oss-process=image/watermark,'
'type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5Y2K5aOV5pil5rC0,size_20,color_FFFFFF,t_70,g_se,'
'x_16#pic_center',
headers=headers)
image = Image.open(BytesIO(response.content))
# 使用pytesseract调用image_to_string方法进行识别,传入要识别的图片,lang='chi_sim'是设置为中文识别,
text = pytesseract.image_to_string(image, lang='chi_sim')
# 输入所识别的文字
print(text)
if __name__ == '__main__':
demo()