一、数据持久化
1、为什么要持久化
redis 重启后,redis 存在内存数据中数据丢失,不管之前是多少G数据,秒丢,而且无法恢复,数据在内存中
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> MSET k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> MGET k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> exit
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> MGET k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> exit
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> shutdown
not connected> exit
[root@86-5-master ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> MGET k1 k2 k3
1) (nil)
2) (nil)
3) (nil)
127.0.0.1:6379>
2、Redis持久的两种方式
RDB的持久化优缺点
可以在指定的时间间隔内升成数据集的 时间点快照
可以理解为rbd就是将当前进程数据生成快照保存到硬盘的过程,触发RBD持久化过程 分为手动触发和自动触发
优点:速度快,是一个压缩的二进制文件,适用于备份特别是全量备份,恢复很快,主从复制也是基于rdb持久化功能实现的,对性能影响最小 RDB文件进行数据恢复比使用AOF要快很多
缺点:会有数据丢失,如果数据集非常大且CPU不够强(比如单核 CPU),Redis在fork子进程时可能会消耗相对较长的时间,影响Redis对外提供服务的能力。bgsave是重量级的操作,因为要将内存中的数据完整复制一份到本地。新版本可以用老版本的RDB文件,老的不兼容新的
AOF的持久化优缺点
相当于mysql的 binlog,每一个记录都记录下来,这样只记录你的操作,而不是实际数据
缺点:无限制追加 binlog 会无限制增大,mysql 会设置 binlog 的最大大小,满足后会进行切割。而 Redis 会触发 rewrite进行压缩数据,但是还是比较大,恢复的时候没有RBD快
优点:最多只会损失1s内的数据
注意:RDB、AOF是可以同时并存的,完全没问题,而且不冲突
3、RDB 持久化配置
1、手动触发机制
Redis客户端直接通过命令BGSAVE或者SAVE来创建一个内存快照
- BGSAVE 调用fork来创建一个子进程,子进程负责将快照写入磁盘,而父进程仍然继续处理命令。是一个全量复制。
-
SAVE 执行SAVE命令过程中,不再响应其他命令。
save和bgsave区别
save:
优点:节约系统资源
缺点:直接调用 rdbSave ,阻塞 Redis 主进程,直到保存完成为止。在主进程阻塞期间,服务器不能处理客户端的任何请求。
bgsave:
优点:fork 出一个子进程,子进程负责调用 rdbSave ,并在保存完成之后向主进程发送信号,通知保存已完成。 Redis 服务器在BGSAVE 执行期间仍然可以继续处理客户端的请求
缺点:由于会fork一个进程,因此更消耗内存
综上:
还是推荐使用bgsave命令,毕竟save命令阻塞其他请求是我们无法接受的
在BGSAVE执行期间,再执行SAVE/BGSAVE/BGREWRITEAOF时的方式:
1、SAVE:会被服务器拒绝,服务器禁止SAVE和BGSAVE同时执行,防止竞争。
2、BGSAVE:会被服务器拒绝,同时执行两个BGSAVE也会产生竞争。
3、BGREWRITEAOF:会被延迟到BGSAVE执行完毕之后执行,如果BGREWRITEAOF在执行,那再发送BGSAVE命令会被服务器直接拒绝。
注:BGSAVE和BGREWRITEAOF其实都是子进程在执行,并不会冲突,但是他们同时执行会有大量的写入操作,影响性能
RDB对过期键的处理:
Redis 4.0 内核开始进行 RDB 导出逻辑修改,导出时不再判断键空间中的 key 是否过期,对于所有 key 都会导出到 RDB 中。
1.执行save或bgsave时,过期的键不会被保存到RDB文件里。
2.在Redis主服务器启动时会载入RDB文件,如果RDB文件里有过期的键,则会忽略过期的键。
3.在Redis从服务器启动时,如果RDB文件里有过期的键,那还是会载入,但是主从在数据同步时,从服务器的数据会被清空,所以不影响。
bgsave 案例
127.0.0.1:6379> BGSAVE Background saving started 127.0.0.1:6379>[root@86-5-master ~]# ll /data/redis_cluster/redis_6379/redis_6379.rdb -rw-r--r-- 1 root root 16885 10月 23 04:41 /data/redis_cluster/redis_6379/redis_6379.rdb [root@86-5-master ~]## 将 redis 重启服务后,数据还在,因为有了redis_6379.rdb,重启后会重新导入到内存中
[root@86-5-master ~]# redis-cli -p 6379 127.0.0.1:6379> shutdown not connected> exit [root@86-5-master ~]# ps -ef |grep redis root 16229 16093 0 04:44 pts/3 00:00:00 grep --color=auto redis [root@86-5-master ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf [root@86-5-master ~]# ps -ef |grep redis root 16263 1 0 04:45 ? 00:00:00 redis-server 127.0.0.1:6379 root 16270 16093 0 04:45 pts/3 00:00:00 grep --color=auto redis [root@86-5-master ~]# redis-cli -p 6379 127.0.0.1:6379> keys * 1) "k_{829}" 2) "k_{898}" 3) "k_{628}"
# 问题:在插入一条,在重启 redis 服务后,新插入的数据是不会存在的,因为没有保存在redis_6379.rdb
999) "k_{308}"
1000) "k_{120}"
127.0.0.1:6379> set k_{2000} v_{2000}
127.0.0.1:6379> keys *
1000) "k_{308}"
1001) "k_{120}"
127.0.0.1:6379> shutdown
not connected> exit
[root@86-5-master ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> keys *
999) "k_{308}"
1000) "k_{120}"bgsave 的存储流程:
执行bgsave 后,创建一个fork进程,由子进程生成rdb文件,原来的主进程继续处理自己的工作。所以当你持久化的时候还需要额外的空间,所以比如物理机器是30G内存,一般控制 redis 使用 15G 空间,剩下的15G,一部分是Linux自己的用的,另外一部不是用来bgsave
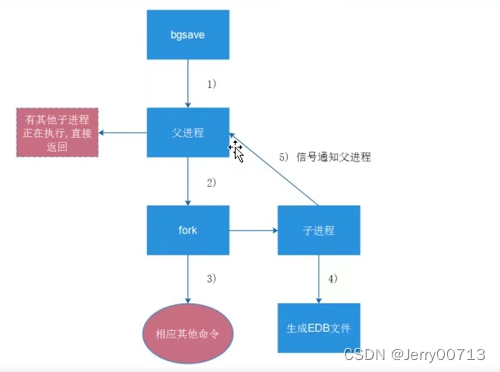
2、配置文件自动触发
[root@86-5-master ~]# vim /etc/redis/6379.conf # 如下则是配置持久化配置
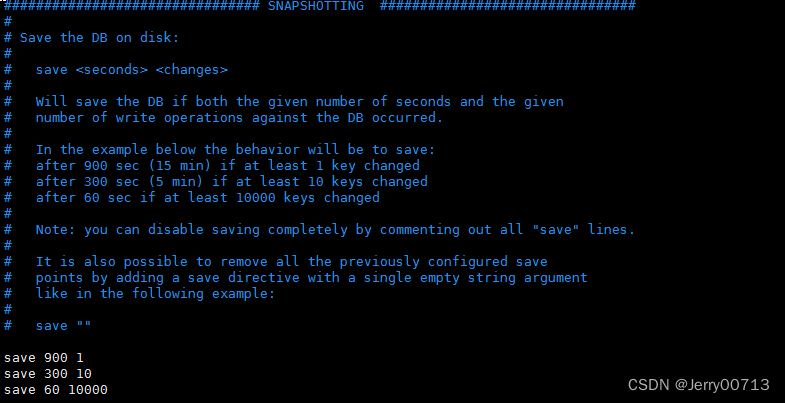
官方配置
# In the example below the behavior will be to save:
# after 900 sec (15 min) if at least 1 key changed
在900秒(15分钟)后,如果至少有1个键已更改
# after 300 sec (5 min) if at least 10 keys changed
300秒(5分钟)后,如果至少有10个钥匙更换
# after 60 sec if at least 10000 keys changed
60秒后,如果至少10000个密钥已更改
save 900 1 # 在距离上一次备份的900秒(15分钟)内,期间至少有1个键已更改,则保存
save 300 10 # 在距离上一次备份的300秒(5分钟)内,期间至少有10个钥匙更换,则保存
save 60 10000 # 在距离上一次备份的60秒内,期间至少有10000个钥匙更换,则保存
解释:
主要满足上述的一个条件,则就会触发bgsave,因为bgsave是重量级的操作,将内存持久化到本地,
如果每秒都这么操作,系统就会响应不过来修改自己的配置文件
[root@86-5-master ~]# tail -n 4 /opt/redis_cluster/redis_6379/conf/redis_6379.conf
### 配置RBD持久化参数
save 900 1
save 300 10
save 60 10000
[root@86-5-master ~]#
重启 redis 服务
[root@86-5-master ~]# redis-cli -p 6379 shutdown
[root@86-5-master ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf 注意,如下我在短时间内插入一条数据,然后关闭了redis服务,为什么数据还保存了 ,并没有触发配置文件的 save?原因是执行shtudown后,执行了两条命令,先执行bgsave,在执行 shtudown。
[root@86-5-master ~]# ll /data/redis_cluster/redis_6379/redis_6379.rdb
-rw-r--r-- 1 root root 35885 10月 23 05:42 /data/redis_cluster/redis_6379/redis_6379.rdb
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> set k_{3000} v_{3000}
OK
127.0.0.1:6379> shutdown
not connected> exit
[root@86-5-master ~]# ll /data/redis_cluster/redis_6379/redis_6379.rdb
-rw-r--r-- 1 root root 35904 10月 23 05:47 /data/redis_cluster/redis_6379/redis_6379.rdb
[root@86-5-master ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> get k_{3000}
"v_{3000}"
127.0.0.1:6379>
注意
1、当通过 killall -9 redis 的 pid 后,是将redis的所有的进程,包括父进程都杀死调。这种情况,是不会执行shtudown,所以也不会执行bgsave,所以期间不会保存数据。 类似生产的断电、异常退出redis。所以工作中一点不要使用killall -9 ,特别是数据库redis mysql mongodb,数据丢失后,如果是固态硬盘数据很难恢复
2、当通过 killall redis 和 killall -15 redis 的 pid 后,是能够 bgsave保存数据,因为 killall 和 killall -15 会给redis发送一个信号,告诉redis退出,redis会触发shutdown,故bgsave保存数据
3、案例,先将RDB文件dump.rdb删除后,在kill redis ,在启动数据库后,数据没清空。因redis 已经启动了,内存中已经有数据了,此时删除dump.rdb后,kill redis 就是 shutdown,会做一次bgsave,所以下次重启Redis数据不会丢失
4、AOF 持久化配置
AOF持久化,以独立日志的方式记录每次写的命令,重启时在执行AOF文件中的命令打道回府数据的的目的AOF的主要解决了数据 持久化的实时性,目前已经是Redis持久化的主流方式
相当于 mysql 的 binlog,每秒把你的更新的内容操作写入到文件中(只记录你的操作,而不是实际数据)
缺点:无限制追加 binlog 会无限制增大,mysql 会设置 binlog 的最大大小,满足后会进行切割。而 Redis 会触发 rewrite进行压缩数据,但是还是比较大,恢复的时候没有RBD快
优点:最多只会损失1s内的数据
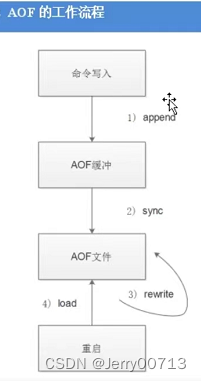
1、工作流程
set k1
set k2
get k2
del k1
最总结果是只有k2
但是记录的是4条操作
1、AOF会先将写入操作做记录,将所有的写入命令追加到aof_buf 缓冲区
2、AOF缓冲区根据对应的策略向硬盘做同步操作
3、随着AOF文件越来越大,需要定期(满足触发条件,比如del k1)对AOF文件,执行一个重写的过程(rewrite),把当时记录的无效的过程删除(set k1 get k1),达到压缩目录
4、当Redis服务重启的时候,可以加载AOF文件进行数据恢复重写机制
AOF对过期键的处理:
1.当服务器以AOF持久化模式运行时,如果某个键过期,但还没有被删除时,不会对AOF文件产生影响。
2.当过期键被删除之后,程序会向AOF文件追加一条DEL命令,显示地记录该键已被删除。如果客户端使用GET message命令,试图通过客户端访问一个过期的键,服务器会执行以下步骤:
1.从数据库中删除该过期键
2.追加一条del key命令到AOF文件
3.向执行get命令的客户端返回空回复AOF重写对过期键的处理:
1.已过期的键不会被保存到重写后的AOF文件中复制对过期键的处理:(为了保证主从数据的一致性)
1.主服务器删除一个过期键之后,会显式地向从服务器发送一个DEL命令,告知从服务器删除这个过期键。
2.客户端通过从服务器获取某个过期键时,是把这个过期键当成正常键返回给客户端,而且不会把它删除。
3.从服务器只有在接收到主服务器发来的DEL命令之后,才会删除过期键。(主服务器通过惰性删除、定期删除或者get了这个过期键,会发送DEL命令)
2、开启AOF
### 是否打开AOF日志功能
appendonly yes
### 指定文件名
appendfilename "appendonly.aof"
### 每一个命令,都立即同步到aof
appendfsync always
### 每秒写入1次
appendfsync everysec
### 写入工作交给操作系统,由操作系统判断缓存区大小,统一写入到aof
appendfsync no
# no:重写时会阻塞appendfsync;
# yes:不会阻塞appendfsync,最多可能出现30秒的数据延迟,甚至丢失30秒数据
### 如果将主节点的no-appendfsync-on-rewrite 设置为yes,添加从节点。
no-appendfsync-on-rewrite no
### aof重写触发条件,生产环境一定要修改这两个值
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64M# 不要再配置文件中参数后面加注释,会报错
[root@86-5-master ~]# tail -n 5 /opt/redis_cluster/redis_6379/conf/redis_6379.conf
### 配置AOF持久化参数
# 是否打开AOF日志功能
appendonly yes
# 每一个命令,都立即同步到aof
appendfsync always
# 每秒写入1次
appendfsync everysec
# 写入工作交给操作系统,由操作系统判断缓存区大小,统一写入到aof
appendfsync no
# 指定文件名
appendfilename "appendonly.aof"重启 Redis 服务
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> shutdown
[root@86-5-master ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf插入一些数据
[root@86-5-master ~]# cat redis.sh
#! /bin/bash
for i in {1..100}
do
redis-cli -h 127.0.0.1 set k_{$i} v_{$i} &>/dev/null
done
[root@86-5-master ~]# ./redis.sh
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> keys*
98) "k_{6}"
99) "k_{49}"
100) "k_{81}"
127.0.0.1:6379>
[root@86-5-master ~]# ll /data/redis_cluster/redis_6379/appendonly.aof
-rw-r--r-- 1 root root 7408 10月 23 06:59 /data/redis_cluster/redis_6379/appendonly.aof
[root@86-5-master ~]# head -n 10 /data/redis_cluster/redis_6379/appendonly.aof
*2
$6
SELECT
$1
0
*3
$3
set
$5
k_{1}
....
[root@86-5-master ~]#
问题:如果RBD跟AOF同时存在,重启Redis服务,Redis会无条件选择只读AOF的备份内容,因为AOF是1s内存储,而RBD只会小于等于此备份,不会读RBD。并且Redis不会判断两个文件的时间选择读哪个。
二、Redis 安全认证
Redis 安全认证,只要能访问 redis,后续没有阻拦。不像 mysql 还会限制使用哪个数据库、只能查询、只能修改等等。
redis 默认开启了保护模式,只允许本地回环地址登录并访问数据库
1、protected-mode yes/no 保护模式,是否只允许本地访问
2、Bind 指定IP 监听
3、requirepass {password}
在 redis.conf 中创建密码,在redis中使用 AUTH {password} 才可以访问 ,如果在外面执行命令 redis-cli -a {password}
[root@86-5-master ~]# grep "requirepass" /opt/redis_cluster/redis_6379/conf/redis_6379.conf requirepass 123456 [root@86-5-master ~]# redis-cli -p 6379 shutdown # 重启redis服务 [root@86-5-master ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf [root@86-5-master ~]# redis-cli -p 6379 127.0.0.1:6379> set k1 v1 # 提示没有权限 (error) NOAUTH Authentication required. 127.0.0.1:6379> AUTH 123456 # 输入密码 OK 127.0.0.1:6379> set k2 v2 # 在没退出此redis-cli,后续不会在输入密码 OK 127.0.0.1:6379> # 如果在外面执行命令 -a 密码 [root@86-5-master ~]# redis-cli -p 6379 -a 123456 get k2 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe "v2" [root@86-5-master ~]# Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.警告:在命令行界面上使用带有“-a”或“-u”选项的密码可能不安全
三、Redis 主从复制
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离
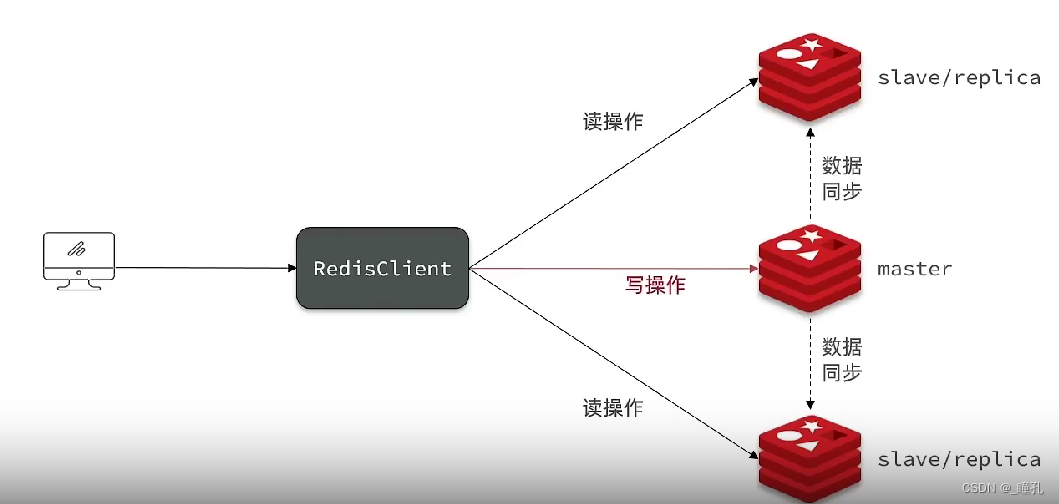
mongodb 叫做副集,最少需要三台,要仲裁、要选举
Redis 的主从比较简单2步,第一步,把从库装好,第二步,执行一条语句
1、备机安装Redis
192.168.78.5 为主,192.168.78.6 为备
[root@86-5-master ~]# tar zcvf redis_86.5.tar.gz /opt/redis_cluster/
[root@86-5-master ~]# scp redis_86.5.tar.gz root@192.168.86.6:/opt
[root@86-6-slave ~]# tar -zxvf redis_86.5.tar.gz
[root@86-6-slave ~]# ll /opt/
-rw-r--r-- 1 root root 36639584 10月 23 08:32 redis_86.5.tar.gz
drwxr-xr-x 4 root root 57 10月 22 10:30 redis_cluster
# 注意关闭备机的防火墙和SELinux
[root@86-6-slave ~]# ll /opt/redis_cluster/
lrwxrwxrwx 1 root root 13 10月 22 10:30 redis -> redis-6.0.16/
drwxrwxr-x 7 root root 4096 10月 22 11:18 redis-6.0.16
drwxr-xr-x 5 root root 41 10月 22 10:26 redis_6379
[root@86-6-slave ~]# yum -y install centos-release-scl
[root@86-6-slave ~]# yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
[root@86-6-slave ~]# scl enable devtoolset-9 bash
[root@86-6-slave ~]# gcc --version
[root@86-6-slave ~]# cd /opt/redis_cluster/redis
[root@86-6-slave redis]# make install # 不需要make安装了
[root@86-5-slave ~]# mkdir /data/redis_cluster/redis_6379 -p
[root@86-6-slave redis]# grep "^bind" /opt/redis_cluster/redis_6379/conf/redis_6379.conf
bind 127.0.0.1 192.168.86.6
[root@86-6-slave redis]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@86-6-slave redis]# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
2、建立主从
[root@86-5-master ~]# redis-cli -p 6379 # 主服务有10条数据
127.0.0.1:6379> keys *
1) "k_{9}"
2) "k_{10}"
3) "k_{8}"
4) "k_{3}"
5) "k_{4}"
6) "k_{5}"
7) "k_{1}"
8) "k_{2}"
9) "k_{6}"
10) "k_{7}"
127.0.0.1:6379>
[root@86-6-slave redis]# redis-cli -p 6379 # 备服务器没有数据
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379>
同步命令 SLAVEOF,备机执行,格式(SLAVEOF 主机地址 端口号)
[root@86-6-slave redis]# redis-cli -p 6379
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> SLAVEOF 192.168.86.5 6379 # 其中192.168.86.5可以写域名,别忘记配置hosts
OK
127.0.0.1:6379> keys * # 已经同步过来
1) "k_{2}"
2) "k_{4}"
3) "k_{9}"
4) "k_{6}"
5) "k_{8}"
6) "k_{10}"
7) "k_{7}"
8) "k_{1}"
9) "k_{5}"
10) "k_{3}"
127.0.0.1:6379>
3、查看主、从日志分析过程
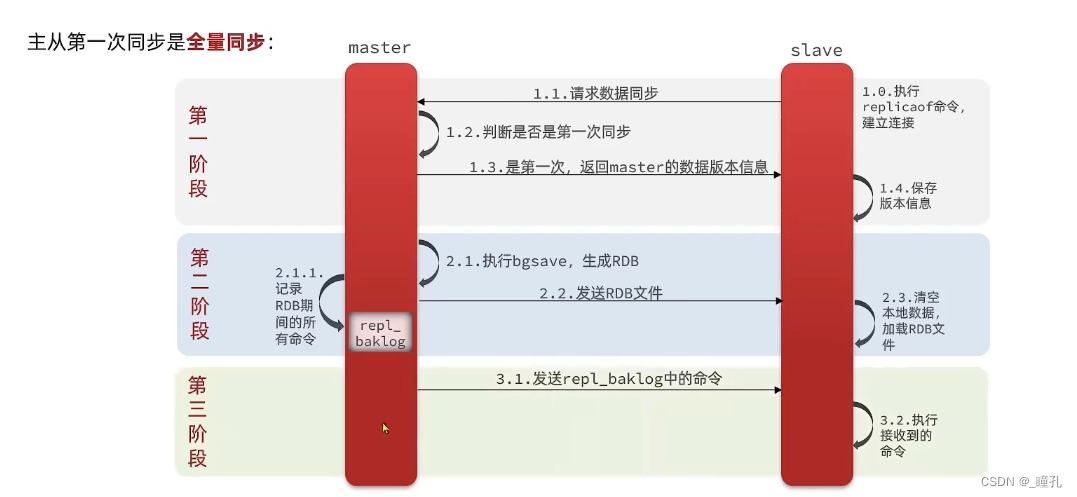
第一次同步此过程是全量同步
1、从库发起同步请求
2、主库收到请求后执行bgsave保存当前内存里的数据到磁盘
3、将持久化的RDB文件发送给从库
4、从库收到主库的持久化数据,清空从的内存/备的持久化数据清空
5、从库使用主的持久化数据并加载到内存中redis 的 copy-on-write 机制 https://blog.csdn.net/Jerry00713/article/details/127471248?spm=1001.2014.3001.5502

4、同步是实时的
同步之后,主从的同步是实时的
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> keys *
1) "k_{10}"
2) "k_{6}"
3) "k_{4}"
4) "k_{7}"
5) "k_{2}"
6) "k_{9}"
7) "k_{8}"
8) "k1"
9) "k_{1}"
10) "k_{5}"
11) "k_{3}"
127.0.0.1:6379>
[root@86-6-slave ~]# redis-cli -p 6379
127.0.0.1:6379> keys *
1) "k1"
2) "k_{3}"
3) "k_{8}"
4) "k_{1}"
5) "k_{6}"
6) "k_{7}"
7) "k_{2}"
8) "k_{4}"
9) "k_{5}"
10) "k_{9}"
11) "k_{10}"
127.0.0.1:6379>
5、全量同步原理
第一次是全量同步,主节点把RDB发送给从节点,从节点获取主节点
这里有两个很重要的概念:
Replication ld:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slive的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id和offset,master才可以判断到底需要同步哪些数据那么怎么判断slave是不是第一次来同步数据呢,可以用Replication ld,下图是上图的详细描述,slave建立连接后,向master发送自己的replid和offset,如果slave的replid和master的不一致,则为第一次同步数据,并返回master的replid和offset
简述全量同步的流程:
slave节点请求增量同步
master节点判断replid,发现不一致,拒绝增量同步
master将完整内存数据生成RDB,发送RDB到slave
slave清空本地数据,加载master的RDB
master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
slave执行接收到的命令,保持与master之间的同步

6、增量同步原理
主从第一次同步是全量同步,后续都是增量同步,即使slave重启后同步,也是执行增量同步(主备数据差异不大的情况下)
需要注意的是,repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。
可以从以下几个方面来优化Redis主从就集群:
在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO
Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
简述全量同步和增量同步区别?
全量同步:master将完整内存数据生成RDB,发送RDB到slave。后
续命令则记录在repl_baklog,逐个发送给slave。
增量同步:slave提交自己的offset到master, master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?slave节点第一次连接master节点时
slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?slave节点断开又恢复,并且在repl baklog中能找到offset时

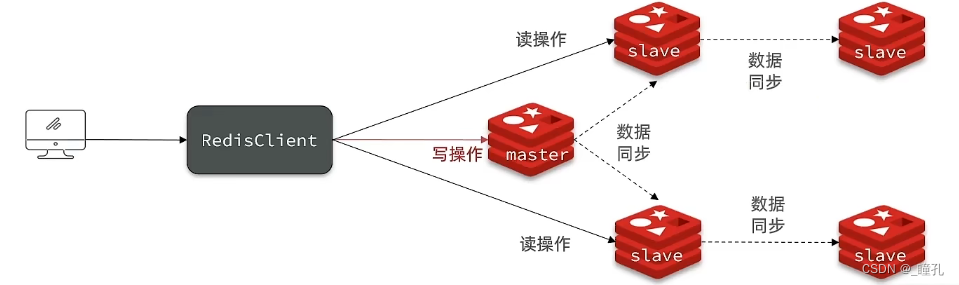
7、从库只读不能写
从库:变成只能读,不能写的库。因为要保证主从的数据一致性,主可以写可以读,从库只能读。不像 mysql 可以配置互相为主互为从。
[root@86-6-slave ~]# redis-cli -p 6379
127.0.0.1:6379> set k10 v10
(error) READONLY You can't write against a read only replica.
127.0.0.1:6379> get k_{10}
"v_{10}"
127.0.0.1:6379>
(error) READONLY You can't write against a read only replica.
(错误)只读您不能对只读副本进行写入。8、配置文件加载主从
从库重启服务后,会断开主从关系,故从库可继续写入数据
[root@86-6-slave ~]# redis-cli -p 6379 shutdown
[root@86-6-slave ~]# ps -ef |grep redis
root 2420 2384 0 10:25 pts/0 00:00:00 grep --color=auto redis
[root@86-6-slave ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@86-6-slave ~]# redis-cli -p 6379
127.0.0.1:6379> keys *
1) "k_{3}"
2) "k_{8}"
3) "k_{1}"
4) "k_{6}"
5) "k_{7}"
6) "k_{4}"
7) "k_{2}"
8) "k_{5}"
9) "k_{9}"
10) "k_{10}"
127.0.0.1:6379> set k10 v10
OK
127.0.0.1:6379>
如何重启 redis 服务,继续保证主从关系,在配置文件中加上主从语句,但注意,重启 redis 服务就会触发全量同步
[root@86-6-slave ~]# tail -n 1 /opt/redis_cluster/redis_6379/conf/redis_6379.conf
slaveof 192.168.86.5 63799、主从复制全量同步的问题
主从复制过程中,从库发起同步请求、清空从的内存、备的持久化数据,清空都是很快的。但是主库收到请求后执行bgsave保存如果数据量很大几十个G、将持久化的RDB文件几十个G发送给从库、从库将bgsave导入到内存中,这个时间将会很大,所以如果第一次同步,会走全量同步,建议业务低峰期操作主从同步
10、查看主从状态、主动关闭主从
info replication # 查看主从状态
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.86.6,port=6379,state=online,offset=8914,lag=1
master_replid:c6341fb0674a5968d85bb7f78c06f2af4f2ab642
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:8914
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:8914
127.0.0.1:6379>
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.86.5
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:8900
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:c6341fb0674a5968d85bb7f78c06f2af4f2ab642
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:8900
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:5895
repl_backlog_histlen:3006
127.0.0.1:6379>
SLAVEOF no one # 主动关闭主从,在从节点 slave 上执行,因为默认redis认为自己是主
127.0.0.1:6379> SLAVEOF no one
OK
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_replid:f8cc746686053bc20c85352f7d92232b129ee10b
master_replid2:c6341fb0674a5968d85bb7f78c06f2af4f2ab642
master_repl_offset:9236
second_repl_offset:9237
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:5895
repl_backlog_histlen:3342
127.0.0.1:6379>
11、主从不能自动完成主从切换
主库宕机后,从库依旧尝试连接,不会停止
[root@86-5-master ~]# redis-cli -p 6379
127.0.0.1:6379> shutdown
not connected> exit
[root@86-5-master ~]#
[root@86-6-slave ~]# tail -f /opt/redis_cluster/redis_6379/logs/redis_6379.log
2422:S 23 Oct 2022 11:40:40.873 * Non blocking connect for SYNC fired the event.
2422:S 23 Oct 2022 11:40:40.873 * Master replied to PING, replication can continue...
2422:S 23 Oct 2022 11:40:40.873 * Trying a partial resynchronization (request f8cc746686053bc20c85352f7d92232b129ee10b:9237).
2422:S 23 Oct 2022 11:40:40.873 * Master is currently unable to PSYNC but should be in the future: -NOMASTERLINK Can't SYNC while not connected with my master
2422:S 23 Oct 2022 11:40:41.882 * Connecting to MASTER 192.168.86.6:6379
2422:S 23 Oct 2022 11:40:41.882 * MASTER <-> REPLICA sync started
2422:S 23 Oct 2022 11:40:41.882 * Non blocking connect for SYNC fired the event.
2422:S 23 Oct 2022 11:40:41.882 * Master replied to PING, replication can continue...
2422:S 23 Oct 2022 11:40:41.882 * Trying a partial resynchronization (request f8cc746686053bc20c85352f7d92232b129ee10b:9237).
2422:S 23 Oct 2022 11:40:41.882 * Master is currently unable to PSYNC but should be in the future: -NOMASTERLINK Can't SYNC while not connected with my master
2422:S 23 Oct 2022 11:40:42.892 * Connecting to MASTER 192.168.86.6:6379
2422:S 23 Oct 2022 11:40:42.892 * MASTER <-> REPLICA sync started
2422:S 23 Oct 2022 11:40:42.892 * Non blocking connect for SYNC fired the event.
2422:S 23 Oct 2022 11:40:42.892 * Master replied to PING, replication can continue...
而且从库还不能写入数据,还是只能读数据,必须手动执行主从关系SLAVEOF no one,从库才能使用,但是代码连接的地址还是主的库,这就是主从复制的一些局限性
四、Redis 哨兵
主从复制问题:资源利用率低,主宕机,备也不能继续写只能读,故障转移需要人工介入。为了解决这个问题,官方推出哨兵技术。
1、介绍
1、Redis 主从模式下,主节点一旦发生故障不能提供服务,需要人工介入,将从节点晋升为主节点,同时 还需要修改客户端的配置,对于很多应用 场景这种方式无法接受。
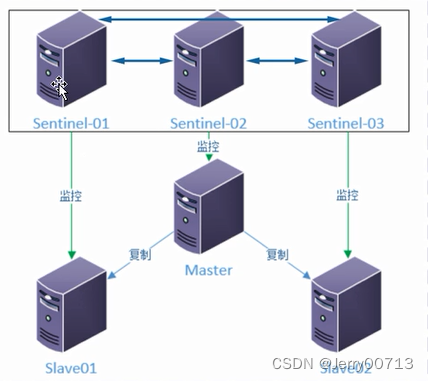
Sentinel 哨兵架构解决了Redis主从人工干预问题
Redis Sentinel 是Redis 的高可用实现方案,实际生产环境中,对提高整体系统可用性非常有帮助
2、主要功能
Redis Sentinel 是一个分布式系统,Redis Sentinel 为Redis 提供高可用性,可以在没有人为干预的情况下组织某种类型的故障
Redis 的哨兵系统用于 管理多个 Redis 服务器,该系统执行以下三个任务:
1、监控:哨兵 会不断定期检查你的主服务器和从服务器是否运行正常
2、提醒:当某个监控的某个Redis 服务器出现问题,哨兵可以通过API 向管理员或者 其他应用程序发送通知
3、自动故障迁移
当一个服务器不能正常工作时,哨兵会开始一次故障迁移操作,他会将失效主服务器的其中一个从服务器升级为主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使的集群可以使用新服务器代替失效服务器
4、哨兵也是一个redis节点,只不过不负监控,只负责通告处理故障节点转移的动作
5、代码直接连接哨兵,哨兵返回的主的IP,一旦master节点故障,返回的哨兵是下一次的master的IP。哨兵可以有多个,同时他们信息互相
2、节点规划
三台物理节点做redis一主两从端口6379
每台物理节点启动一个哨兵,三台物理节点组成哨兵集群端口26379
3、部署
确定主从
slave01:
[root@db02 conf]# head -n 2 /opt/redis_cluster/redis_6379/conf/redis_6379.conf
### bind的意思不是绑定外部服务器的IP,而是redis规定允许哪些IP访问redis
bind 192.168.86.6 127.0.0.1
[root@db02 redis_cluster]# tail -n 2 /opt/redis_cluster/redis_6379/conf/redis_6379.conf
# 主从
slaveof 192.168.86.5 6379
[root@db02 redis_cluster]# redis-cli -p 6379 shutdown
[root@db02 redis_cluster]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@db02 redis_cluster]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.86.5
master_port:6379
master_link_status:up
master_last_io_seconds_ago:5slave02:
[root@86-7-slave conf]# head -n 2 /opt/redis_cluster/redis_6379/conf/redis_6379.conf
### bind的意思不是绑定外部服务器的IP,而是redis规定允许哪些IP访问redis
bind 192.168.86.7 127.0.0.1
[root@db02 redis_cluster]# tail -n 2 /opt/redis_cluster/redis_6379/conf/redis_6379.conf
# 主从
slaveof 192.168.86.5 6379
[root@db02 redis_cluster]# redis-cli -p 6379 shutdown
[root@db02 redis_cluster]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@86-7-slave conf]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.86.5
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
哨兵也是依赖于主从架构
# mymaster 主节点别名 主节点 ip 和 端口 ,判断主节点失败,两个sentinel节点同意
# 定义谁是主节点,如果主节点失败,需要有2个哨兵决定谁是下一个主
sentinel monitor mymaster 192.168.86.5 6379 2
# 选项指定了 Sentinel 认为服务器已经断线所需的毫秒数
sentinel down-after-milliseconds mymaster 30000
# 向新的主节点发起复制操作的从节点个数,1轮训发起复制
# 发生复制的时候,一个一个进行复制
sentinel parallel-syncs mymaster 1
# 故障转移超时时间
sentinel failover-timeout mymaster 180000
master01:
[root@k8s-master ~]# mkdir -p /data/redis_cluster/redis_26379/
[root@k8s-master ~]# mkdir -p /opt/redis_cluster/redis_26379/{conf,pid,logs}
[root@k8s-master ~]# cat /opt/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.86.5
port 26379
daemonize yes
logfile /opt/redis_cluster/redis_26379/logs/redis_26379.log
dir /opt/redis_cluster/redis_26379
sentinel monitor mymaster 192.168.86.5 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 18000slave01:
[root@k8s-master ~]# mkdir -p /data/redis_cluster/redis_26379/
[root@k8s-master ~]# mkdir -p /opt/redis_cluster/redis_26379/{conf,pid,logs}
[root@k8s-master ~]# cat /opt/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.86.6
port 26379
daemonize yes
logfile /opt/redis_cluster/redis_26379/logs/redis_26379.log
dir /opt/redis_cluster/redis_26379
sentinel monitor mymaster 192.168.86.5 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 18000slave02:
[root@k8s-master ~]# mkdir -p /data/redis_cluster/redis_26379/
[root@k8s-master ~]# mkdir -p /opt/redis_cluster/redis_26379/{conf,pid,logs}
[root@k8s-master ~]# cat /opt/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.86.7
port 26379
daemonize yes
logfile /opt/redis_cluster/redis_26379/logs/redis_26379.log
dir /opt/redis_cluster/redis_26379
sentinel monitor mymaster 192.168.86.5 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 18000启动哨兵
master01:
[root@k8s-master ~]# redis-sentinel /opt/redis_cluster/redis_26379/conf/redis_26379.conf
[root@k8s-master ~]# ps -ef |grep redis
root 1036 1 0 04:31 ? 00:00:01 redis-server 192.168.86.5:6379
root 1053 1 0 04:46 ? 00:00:00 redis-sentinel 192.168.86.5:26379 [sentinel]
root 1059 915 0 04:46 pts/0 00:00:00 grep --color=auto redis
[root@k8s-master ~]#
slave01:
[root@db02 redis_cluster]# redis-sentinel /opt/redis_cluster/redis_26379/conf/redis_26379.conf
[root@db02 redis_cluster]# ps -ef |grep redis
root 1219 1 0 04:39 ? 00:00:00 redis-server 192.168.86.6:6379
root 1232 1 0 04:46 ? 00:00:00 redis-sentinel 192.168.86.6:26379 [sentinel]
root 1238 1078 0 04:47 pts/0 00:00:00 grep --color=auto redis
[root@db02 redis_cluster]#
slave02:
[root@86-7-slave conf]# redis-sentinel /opt/redis_cluster/redis_26379/conf/redis_26379.conf
[root@86-7-slave conf]# ps -ef |grep redis
root 1011 1 0 04:40 ? 00:00:00 redis-server 192.168.86.7:6379
root 1022 1 0 04:46 ? 00:00:00 redis-sentinel 192.168.86.7:26379 [sentinel]
root 1028 907 0 04:47 pts/0 00:00:00 grep --color=auto redis
[root@86-7-slave conf]#
查看哨兵配置文件
master01:
[root@k8s-master ~]# cat /opt/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.86.5
sentinel myid 944e241a003f80ac289e095b4789a4f0c5ed640f
# Generated by CONFIG REWRITE
protected-mode no
pidfile "/var/run/redis.pid"
user default on nopass ~* +@all
sentinel failover-timeout mymaster 18000
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-replica mymaster 192.168.86.6 6379
sentinel known-replica mymaster 192.168.86.7 6379
sentinel known-sentinel mymaster 192.168.86.6 26379 be307b68008f3cded9d877a9f6648361546877b8
sentinel known-sentinel mymaster 192.168.86.7 26379 096cef202e0dd83944497b325fdf34202c952168
sentinel current-epoch 0
slave01:
[root@db02 redis_cluster]# cat /opt/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.86.6
sentinel myid be307b68008f3cded9d877a9f6648361546877b8
# Generated by CONFIG REWRITE
protected-mode no
pidfile "/var/run/redis.pid"
user default on nopass ~* +@all
sentinel failover-timeout mymaster 18000
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-replica mymaster 192.168.86.7 6379
sentinel known-replica mymaster 192.168.86.6 6379
sentinel known-sentinel mymaster 192.168.86.5 26379 944e241a003f80ac289e095b4789a4f0c5ed640f
sentinel known-sentinel mymaster 192.168.86.7 26379 096cef202e0dd83944497b325fdf34202c952168
sentinel current-epoch 0
slave02:
[root@86-7-slave conf]# cat /opt/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.86.7
sentinel myid 096cef202e0dd83944497b325fdf34202c952168
# Generated by CONFIG REWRITE
protected-mode no
pidfile "/var/run/redis.pid"
user default on nopass ~* +@all
sentinel failover-timeout mymaster 18000
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-replica mymaster 192.168.86.6 6379
sentinel known-replica mymaster 192.168.86.7 6379
sentinel known-sentinel mymaster 192.168.86.6 26379 be307b68008f3cded9d877a9f6648361546877b8
sentinel known-sentinel mymaster 192.168.86.5 26379 944e241a003f80ac289e095b4789a4f0c5ed640f
sentinel current-epoch 0
[root@86-7-slave conf]#
登录
redis-cli -p 26379 -h 192.168.86.5 # 指定端口号26379
查看状态
master:
[root@k8s-master ~]# redis-cli -p 26379 -h 192.168.86.5
192.168.86.5:26379> info Sentinel
# Sentinel
sentinel_masters:1 # 有一个master
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.86.5:6379,slaves=2,sentinels=3
slave01:
[root@db02 redis_cluster]# redis-cli -p 26379 -h 192.168.86.6
192.168.86.6:26379> info Sentinel
# Sentinel
sentinel_masters:1 # 有一个master
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.86.5:6379,slaves=2,sentinels=3
192.168.86.6:26379>
# master01:name=mymaster代表的是此哨兵属于mymaster组下的成员,意味着可以存在多个组
# status=ok 状态无问题
# address=192.168.86.5:6379 目前的redis主节点192.168.86.5:6379
# slaves=2 有两个从节点,3个哨兵
显示组信息
192.168.86.6:26379> Sentinel masters # 显示所有组中master节点相关的信息
1) 1) "name"
2) "mymaster"
3) "ip"
4) "192.168.86.5"
5) "port"
6) "6379"
7) "runid"
8) "8702547eca7721ef088c666031dd1eb6810d44bb"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
192.168.86.6:26379> Sentinel masters mymaster # 显示mymaster组中master节点相关的信息
192.168.86.6:26379> Sentinel slaves mymaster # 显示mymaster组中slaves节点相关的信息简易信息
192.168.86.6:26379> Sentinel get-master-addr-by-name mymaster
1) "192.168.86.5"
2) "6379"
192.168.86.6:26379>
代码通过 redis 的 Sentinel get-master-addr-by-name mymaster 中的 api 接口的信息,得知现在谁是 master
4、模拟redis主故障转移
关闭主节点 redis
[root@k8s-master ~]# redis-cli -p 6379 shutdown查看哨兵日志
[root@db02 redis_cluster]# tail -f /opt/redis_cluster/redis_26379/
conf/ logs/ pid/
[root@db02 redis_cluster]# tail -f /opt/redis_cluster/redis_26379/logs/redis_26379.log
1232:X 31 Oct 2022 04:46:45.338 # Configuration loaded
1232:X 31 Oct 2022 04:46:45.339 * Increased maximum number of open files to 10032 (it was originally set to 1024).
1232:X 31 Oct 2022 04:46:45.339 * Running mode=sentinel, port=26379.
1232:X 31 Oct 2022 04:46:45.339 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1232:X 31 Oct 2022 04:46:45.345 # Sentinel ID is be307b68008f3cded9d877a9f6648361546877b8
1232:X 31 Oct 2022 04:46:45.345 # +monitor master mymaster 192.168.86.5 6379 quorum 2
1232:X 31 Oct 2022 04:46:45.350 * +slave slave 192.168.86.6:6379 192.168.86.6 6379 @ mymaster 192.168.86.5 6379
1232:X 31 Oct 2022 04:46:45.371 * +slave slave 192.168.86.7:6379 192.168.86.7 6379 @ mymaster 192.168.86.5 6379
1232:X 31 Oct 2022 04:46:47.229 * +sentinel sentinel 944e241a003f80ac289e095b4789a4f0c5ed640f 192.168.86.5 26379 @ mymaster 192.168.86.5 6379
1232:X 31 Oct 2022 04:46:49.713 * +sentinel sentinel 096cef202e0dd83944497b325fdf34202c952168 192.168.86.7 26379 @ mymaster 192.168.86.5 6379
1232:X 31 Oct 2022 05:17:58.195 # +sdown master mymaster 192.168.86.5 6379
1232:X 31 Oct 2022 05:17:58.306 # +new-epoch 1
1232:X 31 Oct 2022 05:17:58.310 # +vote-for-leader 096cef202e0dd83944497b325fdf34202c952168 1
1232:X 31 Oct 2022 05:17:58.662 # +config-update-from sentinel 096cef202e0dd83944497b325fdf34202c952168 192.168.86.7 26379 @ mymaster 192.168.86.5 6379
1232:X 31 Oct 2022 05:17:58.662 # +switch-master mymaster 192.168.86.5 6379 192.168.86.7 6379
1232:X 31 Oct 2022 05:17:58.662 * +slave slave 192.168.86.6:6379 192.168.86.6 6379 @ mymaster 192.168.86.7 6379
1232:X 31 Oct 2022 05:17:58.662 * +slave slave 192.168.86.5:6379 192.168.86.5 6379 @ mymaster 192.168.86.7 6379
1232:X 31 Oct 2022 05:18:01.671 # +sdown slave 192.168.86.5:6379 192.168.86.5 6379 @ mymaster 192.168.86.7 6379
查看哨兵配置文件
[root@k8s-master ~]# cat /opt/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.86.5
port 26379
daemonize yes
logfile "/opt/redis_cluster/redis_26379/logs/redis_26379.log"
dir "/opt/redis_cluster/redis_26379"
sentinel myid 944e241a003f80ac289e095b4789a4f0c5ed640f
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 192.168.86.7 6379 2 # redis的master节点已经切换
sentinel down-after-milliseconds mymaster 3000
# Generated by CONFIG REWRITE
protected-mode no
pidfile "/var/run/redis.pid"
user default on nopass ~* +@all
sentinel failover-timeout mymaster 18000
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
sentinel known-replica mymaster 192.168.86.6 6379
sentinel known-replica mymaster 192.168.86.5 6379
sentinel known-sentinel mymaster 192.168.86.6 26379 be307b68008f3cded9d877a9f6648361546877b8
sentinel known-sentinel mymaster 192.168.86.7 26379 096cef202e0dd83944497b325fdf34202c952168
sentinel current-epoch 1
[root@k8s-master ~]#
[root@db02 redis_cluster]# cat /opt/redis_cluster/redis_26379/conf/redis_26379.conf
bind 192.168.86.6
port 26379
daemonize yes
logfile "/opt/redis_cluster/redis_26379/logs/redis_26379.log"
dir "/opt/redis_cluster/redis_26379"
sentinel myid be307b68008f3cded9d877a9f6648361546877b8
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 192.168.86.7 6379 2
sentinel down-after-milliseconds mymaster 3000
# Generated by CONFIG REWRITE
protected-mode no
启动master01 节点,已经成为从节点
[root@k8s-master ~]# redis-server /opt/redis_cluster/redis_6379/conf/redis_6379.conf
[root@k8s-master ~]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.86.7
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:445622
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:259591fc8f84d8e52dea2cd62a6d3c38d561a04f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:445622
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:436370
repl_backlog_histlen:9253
127.0.0.1:6379>
对应的从节点么有插入的权限
[root@k8s-master ~]# redis-cli -p 6379
127.0.0.1:6379> get key
(nil)
127.0.0.1:6379> set key v1
(error) READONLY You can't write against a read only replica.
127.0.0.1:6379>
在配置文件的最后末尾,自动添加主节点是192.168.86.7 6379
5.0版本使用REPLICAOF代替了之前版本的SLAVEOF,如果使用5.0及之后版本,则建议新命令REPLICAOF。
登录 Slave Redis 命令行,执行以下命令(重启后失效),此时在 master 中的任何数据变化都会自动地同步到 slave 中
[root@k8s-master ~]# tail -n 3 /opt/redis_cluster/redis_6379/conf/redis_6379.conf
# Generated by CONFIG REWRITE
user default on nopass ~* +@all
replicaof 192.168.86.7 6379
[root@k8s-master ~]#
5、模拟主机点redis、哨兵宕机
主节点的哨兵宕机后,不会影响故障的迁移,因为哨兵是一个主从的集群
[root@86-7-slave conf]# redis-cli -p 26379 -h 192.168.86.7
192.168.86.7:26379> Sentinel get-master-addr-by-name mymaster
1) "192.168.86.7"
2) "6379"
192.168.86.7:26379> exit
[root@86-7-slave conf]# redis-cli -p 26379 -h 192.168.86.7 shutdown
[root@86-7-slave conf]# ps -ef |grep redis
root 1011 1 0 04:40 ? 00:00:10 redis-server 192.168.86.7:6379
root 1059 907 0 05:34 pts/0 00:00:00 grep --color=auto redis
[root@86-7-slave conf]# redis-cli -p 6379 shutdown
[root@86-7-slave conf]# ps -ef |grep redis
root 1062 907 0 05:34 pts/0 00:00:00 grep --color=auto redis
[root@db02 redis_cluster]# redis-cli -p 26379 -h 192.168.86.6
192.168.86.6:26379> Sentinel get-master-addr-by-name mymaster
1) "192.168.86.5"
2) "6379"
192.168.86.6:26379> exit
[root@db02 redis_cluster]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.86.5
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:595550
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:6fc3d8aa6354704bd1ff9e20f3eb3408e3dfbdd4
master_replid2:259591fc8f84d8e52dea2cd62a6d3c6、故障迁移分析哨兵日志
[root@k8s-master ~]# redis-cli -p 26379 -h 192.168.86.5
192.168.86.5:26379> Sentinel get-master-addr-by-name mymaster
1) "192.168.86.5"
2) "6379"
192.168.86.5:26379> exit
[root@k8s-master ~]# ps -ef |grep redis
root 1053 1 0 04:46 ? 00:00:15 redis-sentinel 192.168.86.5:26379 [sentinel]
root 1085 1 0 05:21 ? 00:00:04 redis-server 192.168.86.5:6379
root 1106 915 0 05:44 pts/0 00:00:00 grep --color=auto redis
[root@k8s-master ~]# pkill redis
[root@k8s-master ~]# ps -ef |grep redis
root 1109 915 0 05:45 pts/0 00:00:00 grep --color=auto redis
[root@k8s-master ~]#
[root@db02 redis_cluster]# echo "" >/opt/redis_cluster/redis_26379/logs/redis_26379.log
[root@db02 redis_cluster]# tail -f /opt/redis_cluster/redis_26379/logs/redis_26379.log
1232:X 31 Oct 2022 05:45:31.216 # +sdown master mymaster 192.168.86.5 6379 # redis主机点宕机
1232:X 31 Oct 2022 05:45:31.217 # +sdown sentinel 944e241a003f80ac289e095b4789a4f0c5ed640f 192.168.86.5 26379 @ mymaster 192.168.86.5 6379 # redis主机点的192.168.86.5 26379哨兵宕机
1232:X 31 Oct 2022 05:45:31.305 # +new-epoch 3
1232:X 31 Oct 2022 05:45:31.307 # +vote-for-leader 096cef202e0dd83944497b325fdf34202c952168 3
1232:X 31 Oct 2022 05:45:32.304 # +odown master mymaster 192.168.86.5 6379 #quorum 2/2
1232:X 31 Oct 2022 05:45:32.304 # Next failover delay: I will not start a failover before Mon Oct 31 05:46:07 2022
1232:X 31 Oct 2022 05:45:32.318 # +config-update-from sentinel 096cef202e0dd83944497b325fdf34202c952168 192.168.86.7 26379 @ mymaster 192.168.86.5 6379
1232:X 31 Oct 2022 05:45:32.318 # +switch-master mymaster 192.168.86.5 6379 192.168.86.7 6379 # 切换master ,192.168.86.5 6379 变成 86.7 作为主节点
1232:X 31 Oct 2022 05:45:32.319 * +slave slave 192.168.86.6:6379 192.168.86.6 6379 @ mymaster 192.168.86.7 6379
1232:X 31 Oct 2022 05:45:32.319 * +slave slave 192.168.86.5:6379 192.168.86.5 6379 @ mymaster 192.168.86.7 6379
1232:X 31 Oct 2022 05:45:35.382 # +sdown slave 192.168.86.5:6379 192.168.86.5 6379 @ mymaster 192.168.86.7 6379
另一个86.6节点
config-update-from sentinel 096cef202e0dd83944497b325fdf34202c952168 192.168.86.7 26379 @ mymaster 192.168.86.5 6379 # 意思是更新自己的哨兵文件
看redis日志,就是redis主从复制的过程
[root@db02 redis_cluster]# tail -f /opt/redis_cluster/redis_6379/logs/redis_6379.log
1219:S 31 Oct 2022 05:45:32.317 * REPLICAOF 192.168.86.7:6379 enabled (user request from 'id=27 addr=192.168.86.7:45553 fd=15 name=sentinel-096cef20-cmd age=140 idle=0 flags=x db=0 sub=0 psub=0 multi=4 qbuf=353 qbuf-free=32415 argv-mem=4 obl=45 oll=0 omem=0 tot-mem=61468 events=r cmd=exec user=default')
1219:S 31 Oct 2022 05:45:32.320 # CONFIG REWRITE executed with success.
1219:S 31 Oct 2022 05:45:33.244 * Connecting to MASTER 192.168.86.7:6379
1219:S 31 Oct 2022 05:45:33.244 * MASTER <-> REPLICA sync started
1219:S 31 Oct 2022 05:45:33.245 * Non blocking connect for SYNC fired the event.
1219:S 31 Oct 2022 05:45:33.245 * Master replied to PING, replication can continue...
1219:S 31 Oct 2022 05:45:33.246 * Trying a partial resynchronization (request 6fc3d8aa6354704bd1ff9e20f3eb3408e3dfbdd4:688863).
1219:S 31 Oct 2022 05:45:33.246 * Successful partial resynchronization with master.
1219:S 31 Oct 2022 05:45:33.246 # Master replication ID changed to a6fb19db9d8f68801d2b90922d062f2fba1a3648
1219:S 31 Oct 2022 05:45:33.246 * MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.
7、手动故障转移
master01是一个 高性能物理机,由于宕机后,redis主节点转移到了slave02,在修复master01节点后,自动为备节点,如何实现再次切换为 master01 还是为主节点
权重:
哨兵的选举方式是,谁的ID大,选择谁为主
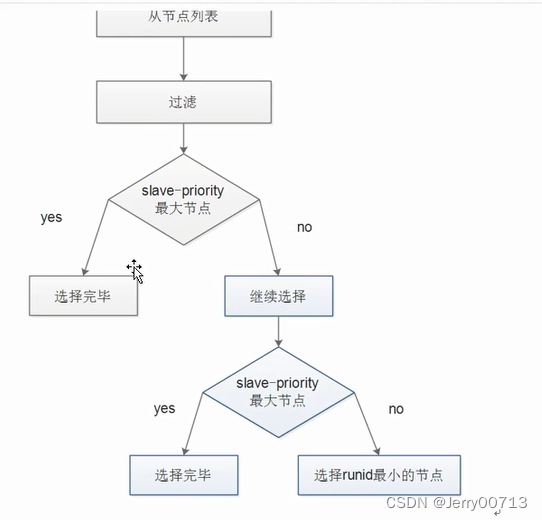
默认权重都是100,所以说他们的选举是随机的
[root@k8s-master ~]# redis-cli -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "100"
[root@db02 redis_cluster]# redis-cli -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "100"
[root@86-7-slave conf]# redis-cli -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "100"如果修改权重,选举就会偏向ID大的,所以我将slave01 和 slave02 的权重设置为0,这样master01权重还是100
[root@db02 redis_cluster]# redis-cli -p 6379 CONFIG SET slave-priority 0
OK
[root@db02 redis_cluster]# redis-cli -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "0"
[root@86-7-slave conf]# redis-cli -p 6379 CONFIG SET slave-priority 0
OK
[root@86-7-slave conf]# redis-cli -p 6379 CONFIG GET slave-priority
1) "slave-priority"
2) "0"手动强制发生故障转移sentinel failover mymaster,这样就会让权重高的作为 redis 的主
[root@k8s-master ~]# redis-cli -p 26379 -h 192.168.86.5 sentinel failover mymaster
OK
[root@k8s-master ~]# redis-cli -p 26379 -h 192.168.86.5 Sentinel get-master-addr-by-name mymaster
1) "192.168.86.5"
2) "6379"
注意:将slave01 和 slave02 的权重设置回来,否则下次master节点宕机,无法选举,因为master01的权重是100,依旧在master01
[root@db02 redis_cluster]# redis-cli -p 6379 CONFIG SET slave-priority 100
OK
[root@86-7-slave conf]# redis-cli -p 6379 CONFIG SET slave-priority 100
OK
五、redis的集群