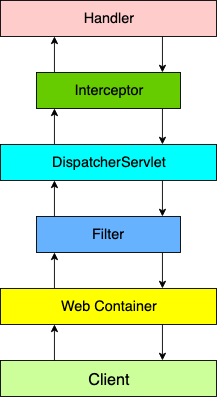
一、问题描述
最近发现我们的生产环境 Service Monitor 的监控报表数据无法正常显示,有很多的断点,有很多数据没有被正常采集到,最后定位到是 service monitor 的JVM 内存使用率过高,导致频繁GC,使得 Service Monitor 极不稳定。
开始的时候,没有过多考虑,只是增加了 JVM 的堆内存大小,但是过段时间有出现,从 16G -> 32G -> 64G,问题还是没有解决,看来必须更深的追一下了。
二、环境信息
cloudera manager 7.4.4cdp 7.1.7
三、解决思路
通过了解 Servcie Monitor 具体的监控指标项,以及每个监控指标项对应的监控 Entity 的数量,来判断是那个监控指标项引起的Service monitor 内存使用率过高。
四、具体实践
1. 修改配置
这一步是要能够通过 rest 请求来查看 监控 Entity 的详情。
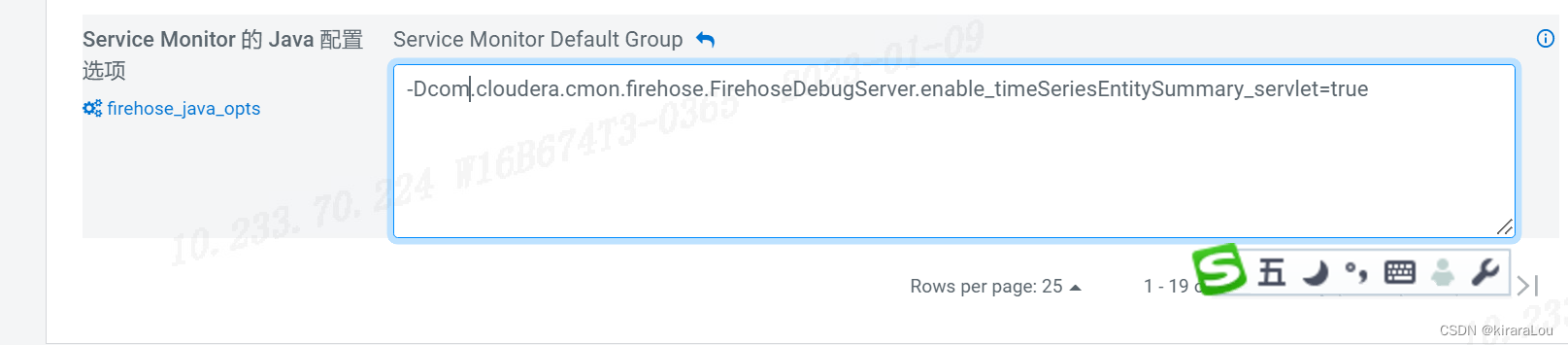
CM -> Cloudera Management Service -> 配置 -> Service Monitor 的 java 配置选项
新增如下内容:
-Dcom.cloudera.cmon.firehose.FirehoseDebugServer.enable_timeSeriesEntitySummary_servlet=true
2. 重启service Monitor 服务
CM -> Cloudera Management Service -> 实例 -> Service Monitor 重启。
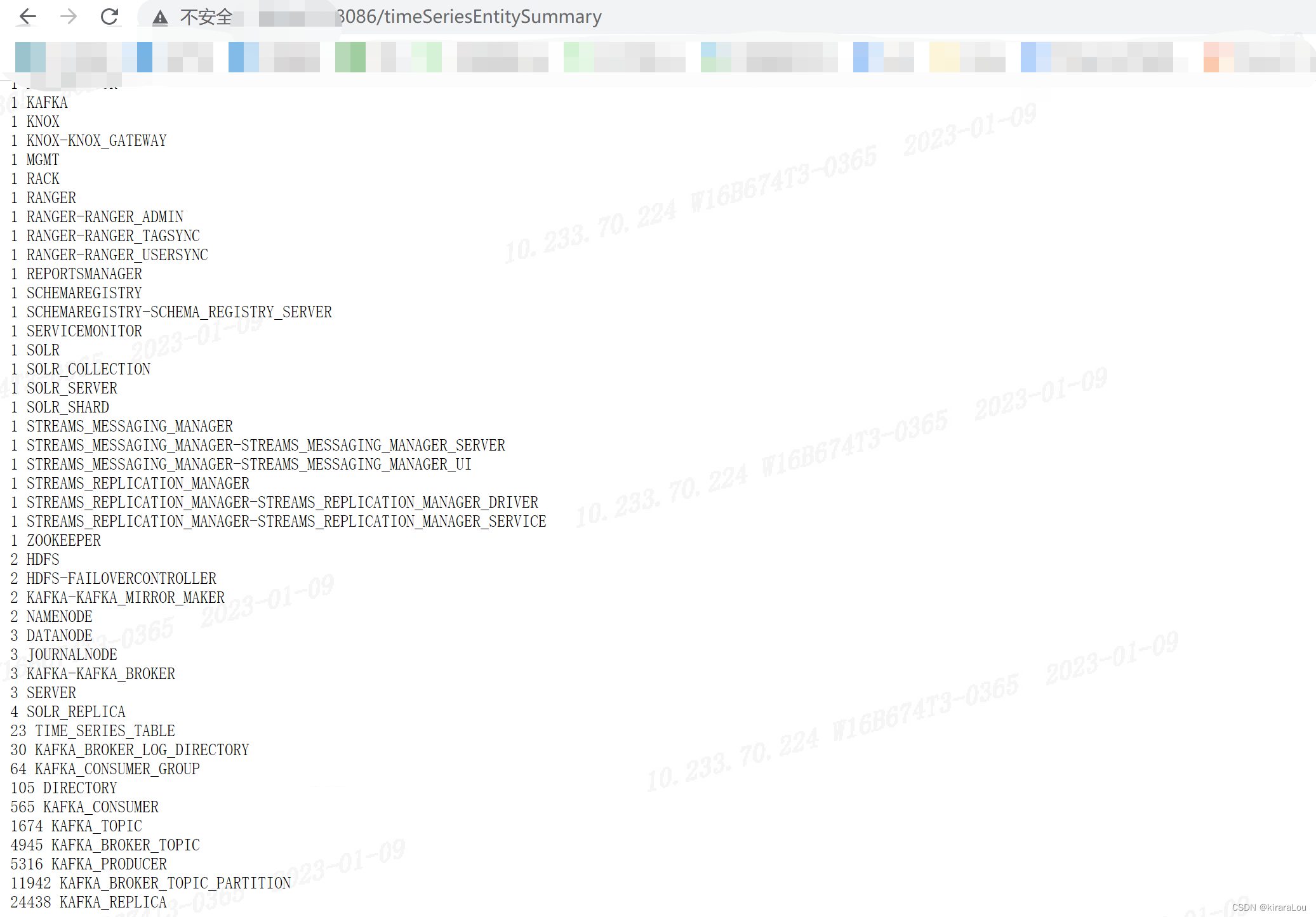
3. 查看 entity 数量
http://service monitor ip:8086/timeSeriesEntitySummary
内容大致如下:
五、问题原因
我这里遇到的问题原因是 Kakfa Producer 的监控指标项过多导致的。SMM有一个已知问题,当匿名producer的metric被SMON收集的时候,很容易对SMON造成过压,导致SMON服务不正常。这会导致SMON 空间填满,从而导致内存消耗问题。为了解决这个问题,在CDP 7.1.7的新功能中引入了producer metric whitelisting,将您所关心的producer加入到白名单,过滤掉不需要的匿名producer。
找到监控实体数量最多的一项,问题大概就是由他引起的,可能每个人的情况不一样,这里只给一个通用的排查方向,具体的情况具体解决。
最终的解决方法
CM -> kafka -> 配置 -> producer.metrics.enable 设置为 false。
滚动重启 Kafka 集群。

六、补充
对于有些目前找不到问题原因,但又想尽快降低 Service Monitor 服务内存小伙伴,可以尝试重置Firehose LevelDB存储。具体步骤如下:
- 停止 Service Monitor 服务。
- 重命名 Service Monoitor 配置中的目录,或者直接将 /var/lib/cloudera-service-monitor 目录下的文件夹清空。
- 启动 Service Monitor 服务。
参考:
- https://my.cloudera.com/knowledge/ERROR-quotOutOfMemoryquot-in-Service-Monitor?id=338841