文章目录
- urllib库
- 1、基本使用
- 2、一个类型、六个方法
- 3、下载操作
- 4、请求对象的定制
- 5、get请求的quote方法
- 6、get请求的urlencode方法
- 7、post请求百度翻译
- 8、post请求百度翻译之详细翻译
- 小技巧:正则替换
- 9、agax的get请求豆瓣电影第一页
- **10、agax的get请求豆瓣电影的前十页(综合案例)**
- 11、agax的post请求肯德基官网
- 12.微博的cookie登录
- 13.Handler处理器
urllib库
1、基本使用

import urllib.request
# 利用urllib来获取百度首页的源码
# 1、定义一个url 就是你要访问的地址
url = "http://www.baidu.com"
# 2、模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 3、获取响应中的页面的源码
# read 返回的是字节形式的二进制数据
# 我们要将二进制的数据转换成字符串,叫做解码 decode('编码的格式')
content = response.read().decode('utf-8')
#4、打印数据
print(content)
2、一个类型、六个方法
import urllib.request
url = "http://www.baidu.com"
response = urllib.request.urlopen(url)
# 一个类型和6个方法{
# 一个类型 HTTPResponse
# 六个方法 read readline readlines getcode geturl getheaders
# }
# response是HTTPResponse的类型# <class 'http.client.HTTPResponse'>
print(type(response))
# # 按照一个字节一个字节的去读
# content = response.read
# print(content)
#返回多少个字节
content=response.read(5)#5代表只读5个字节
print(content)
# 只读取一行
content=response.readline()#只能读取一行
print(content)
# 全读完
content=response.readlines()
print(content)
# 返回状态码 比如200
print(response.getcode())
# 返回的是url地址 http://www.baidu.com
print(response.geturl())
# 获取的是一个状态信息
print(response.getheaders())
3、下载操作
import urllib.request
# 下载网页
url_page="http://www.baidu.com"
# 下面这个方法很重要!!!
#url代表的是下载的路径,filename文件的名字
#在python中,可以写变量的名字,也可以直接写值
urllib.request.urlretrieve(url_page,'baidu.html')
# 下载图片
url_img=""
urllib.request.urlretrieve(url_img,'图片.jpg')
# 下载视频
url_video=""
urllib.request.urlretrieve(url_video,'bili.mp4')
4、请求对象的定制
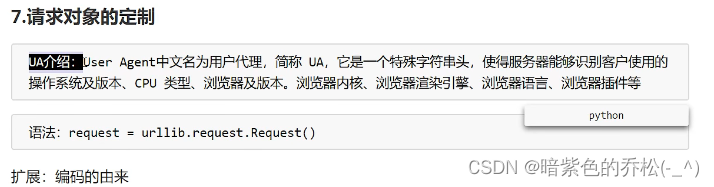
直接访问带有https的百度页面(http没有影响),会遇到UA反爬,所以要进行伪装,在自己的浏览器中找到UA,复制,然后定制request对象,把这个request传参进去,就可以正常的爬取百度网页了
import urllib.request
url="https://www.baidu.com"
#url的组成
# http/https www.baidu.com 80/443
# 协议 主机 端口号 路径 参数 锚点
# http 80
# https 443
# mysql 3306
# oracle 1521
# redis 6379
# mongodb 27017
headers={
"User-Agent": ""
}
# 因为urlopen方法中不能存储字典,所以headers不能传递进去
# 所以要进行请求方法的定制
# 注意:因为参数顺序的问题,不能直接写url和headers,中间还有data 所以我们要关键字传参
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
print(content)
5、get请求的quote方法
import urllib.request
import urllib.parse
# 获取周杰伦网页的源码
url=""
#请求对象的定制,为了解决反爬的第一种手段
headers={
"User-Agent": ""
}
#将周杰伦三个字变成unicode编码的格式
# 我们需要urllib.parse.quote将周杰伦变成unicode编码
name=urllib.parse.quote('周杰伦')
url=url+name
#请求对象的定制
request=urllib.request.Request(url=url,headers=headers)
#模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
#获取响应的内容
content=response.read().decode('utf-8')
print(content)
6、get请求的urlencode方法
import urllib.parse
import urllib.request
# urlencode方法应用场景:多个参数的时候
# https://www.baidu.com/s?wd=周杰伦&sex=男
# data={
# 'wd':'周杰伦',
# 'sex':'男',
# 'locatio':'中国台湾省'
# }
# a=urllib.parse.urlencode(data)
# print(a)
#获取https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7&location=%E4%B8%AD%E5%9B%BD%E5%8F%B0%E6%B9%BE%E7%9C%81的网页源码
base_url=""
data={
'wd':'周杰伦',
'sex':'男',
'locatio':'中国台湾省'
}
new_data=urllib.parse.urlencode(data)
#请求资源的路径(url)
url=base_url+new_data
headers={
"User-Agent": ""
}
#请求对象的定制
request=urllib.request.Request(url=url,headers=headers)
#模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
#获取网页源码的数据
content=response.read().decode('utf-8')
print(content)
7、post请求百度翻译
import urllib.request
import urllib.parse
url = ""
headers = {
"User-Agent": ""
}
data = {
'kw': 'spider'
}
# post请求的参数,必须要进行编码(.encode('utf-8'))
data = urllib.parse.urlencode(data).encode('utf-8')
# post的请求参数,是不会拼接在url的后面的,而是需要放在请求对象定制的参数当中
# post请求的参数,必须要进行编码
request = urllib.request.Request(url=url, data=data, headers=headers)
#模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
# 获取响应的数据
content=response.read().decode('utf-8')
print(content)
# post请求方式的参数 必须编码 data=urllib.parse.urlencode(data).encode('utf-8')
#编码之后,必须调用encode()方法
# 参数是放在请求对象定制的方法当中 request = urllib.request.Request(url=url, data=data, headers=headers)
8、post请求百度翻译之详细翻译
小技巧:正则替换

import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
headers = {
}
data = {
"from": "en",
"to": "zh",
"query": "love",
"simple_means_flag": "3",
"sign": "198772.518981",
#此处省略
"domain": "common",
}
# post请求的参数,必须进行编码,并且要调用encode方法
data = urllib.parse.urlencode(data).encode('utf-8')
# 请求对象的定制
request = urllib.request.Request(url=url, data=data, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
print(content)
9、agax的get请求豆瓣电影第一页
import urllib.request
url=""
headers={
"User-Agent": ""
}
# 请求对象的定制
request=urllib.request.Request(url=url,headers=headers)
# 获取响应的数据
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
print(content)
#数据下载到本地
# open默认情况下使用的是gbk编码,如果我们想保存汉字,那么需要在open方法中指定编码格式为utf-8
fp=open('douban.json','w',encoding='utf-8')
fp.write(content)
# 写成下面这样也行,效果一样
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
10、agax的get请求豆瓣电影的前十页(综合案例)
# 下载豆瓣电影前十页的数据
# 1、请求对象的定制
# 2、获取响应的数据
# 3、下载数据
import urllib.parse
import urllib.request
def create_request(page):
base_url = ""
data = {
'start': (page - 1) * 20,
'limit': 20
}
data = urllib.parse.urlencode(data)
url = base_url + data
# print(url)
headers = {
"User-Agent": ""
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page, content):
with open('douban_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
fp.write(content)
# 程序的入口
if __name__ == '__main__':
start_page = int(input("请输入起始的页码:"))
end_page = int(input("请输入结束的页面:"))
# 每一页都有自己的请求对象的定制
for page in range(start_page, end_page + 1):
request = create_request(page)
# 获取响应的数据
content = get_content(request)
# 下载
down_load(page, content)
11、agax的post请求肯德基官网
import urllib.request
import urllib.parse
def creat_request(page):
base_url = ''
data = {
'cname': '北京',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
"User-Agent": ""
}
request = urllib.request.Request(url=base_url, headers=headers, data=data)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page, end_page + 1):
#请求对象的定制
request=creat_request(page)
# 获取网页源码
content=get_content(request)
# 下载
down_load(page,content)
12.微博的cookie登录
import urllib.request
url = ''
headers = {
# 请求头要那个最全的
}
request = urllib.request.Request(url=url, headers=headers)
reponse = urllib.request.urlopen(request)
content = reponse.read().decode('utf-8')
with open('weibo.html', 'w', encoding='utf-8') as fp:
fp.write(content)
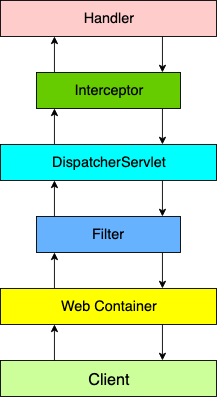
13.Handler处理器
import urllib.request
url = '';
headers = {
# 要那个短的请求头
}
request = urllib.request.Request(url=url, headers=headers)
# 获取handler对象
handler = urllib.request.HTTPHandler()
# 获取opener对象
opner = urllib.request.build_opener(handler)
# 调用open方法
response = opner.open(request)
content = response.read().decode('utf-8')
print(content)