nlpcver
忠于理想
关注他
106 人赞同了该文章
文章地址:Scalable Diffusion Models with Transformers
简介
文章提出使用Transformers替换扩散模型中U-Net主干网络,分析发现,这种Diffusion Transformers(DiTs)不仅速度更快(更高的Gflops),而且在ImageNet 512×512和256×256的类别条件图片生成任务上,取得了更好的效果,256×256上实现了SOTA的FID指标(2.27)。
Transformers已经广泛应用于包括NLP、CV在内的机器学习的各个领域。然而,很多图片level的生成模型还坚持使用卷积神经网络,比如扩散模型采用的就是U-Net的主干网络架构。经过演化,扩散模型中的U-Net网络增加了稀疏的自注意力模块,此外 Dhariwal and Nichol 也尝试过在U-Net模型上的一些改变,比如通过增加适配的正则化层来注入条件信息和Channel数量。尽管如此,U-Net的顶层设计还是与原始U-Net相差无几。
文章的目标就是要揭开扩散模型架构选择的神秘面纱,提供一个强有力的baseline。文章发现U-Net并非不可替代,并且很容易使用诸如Transformers的结构替代U-Net,使用Transformers可以很好地保持原有的优秀特性,比如可伸缩性、鲁棒性、高效性等,并且使用新的标准化架构可能在跨领域研究上展现出更多的可能。文章从网络复杂度和采样质量两个方面对DiTs方法进行评估。
相关工作
Transformers
当前,Transformers架构已经应用在了文本、视觉、强化学习、元学习等多个领域,同时模型的大小、训练开销、数据量等也不断地上涨。在语言模型的启发下,有些工作在视觉任务上训练离散的codebook,这种架构可以同时应用在自回归模型和masked生成模型。本文将研究在扩散模型的主干网络上应用Transformers。
DDPMs
扩散模型是借鉴了物理学上的扩散过程,在生成模型上,分为正向和逆向的过程。正向过程是向信号中逐渐每步加少量噪声,当步数足够大时可以认为信号符合一个高斯分布。所以逆向过程就是从随机噪声出发逐渐的去噪,最终还原成原有的信号。
去噪过程一般采用UNet或者ViT,使用t步的结果和条件输入预测t-1步增加的噪声,然后使用DDPM可以得到t-1步的分布,经过多步迭代就可以从随机噪声还原到有实际意义的信号。如果使用原始DDPM速度会慢很多,所以很多工作如DDIM、FastDPM等工作实现了解码加速。
在图像的无条件生成任务上,扩散模型的性能已经超过了GANs,并且在有条件生成如文图生成任务上大放异彩。
架构复杂度
对于图片生成的迭代过程,我们可以使用参数量来衡量不同模型的复杂度。一般而言,参数量来评估模型复杂度不是很合适,因为参数量并不能代表模型的计算复杂度,比如当模型参数量相同时,图片分辨率不同会导致计算复杂度上较大的差异。所以文章采用Gflops来衡量模型架构的复杂度。
方法
扩散模型基础
前向过程是一个T步逐渐加噪的马尔科夫链,公式如下

给定前向扩散过程作为先验,扩散模型训练反转的过程,可以通过去除所加噪声从XT恢复成X0,并且每步的扩散过程都采样自特定的高斯分布,其期望和方差如下:

优化目标是负的X0概率似然,其上界如下所示:

并且其目标可以简化为预测和ground truth之间的l2 loss。
![]()
Classifier-free guidance
条件扩散模型是将条件信息作为额外的输入,比如一个分类标签c。这种情况下反向过程变为了
![]()
根据贝叶斯规则
![]()
因此
![]()
所以在想要条件的概率较大,就可以将条件的梯度增加到优化目标里,最终可以表示成如下形式:
![]()
模型在训练时,使用一个网络架构优化两个模型(uncond,cond)。
Latent diffusion models

模型使用VAE(固定权重)将图片encoder到隐空间,生成结果同样也是通过VAE解码成原始大小的图片。
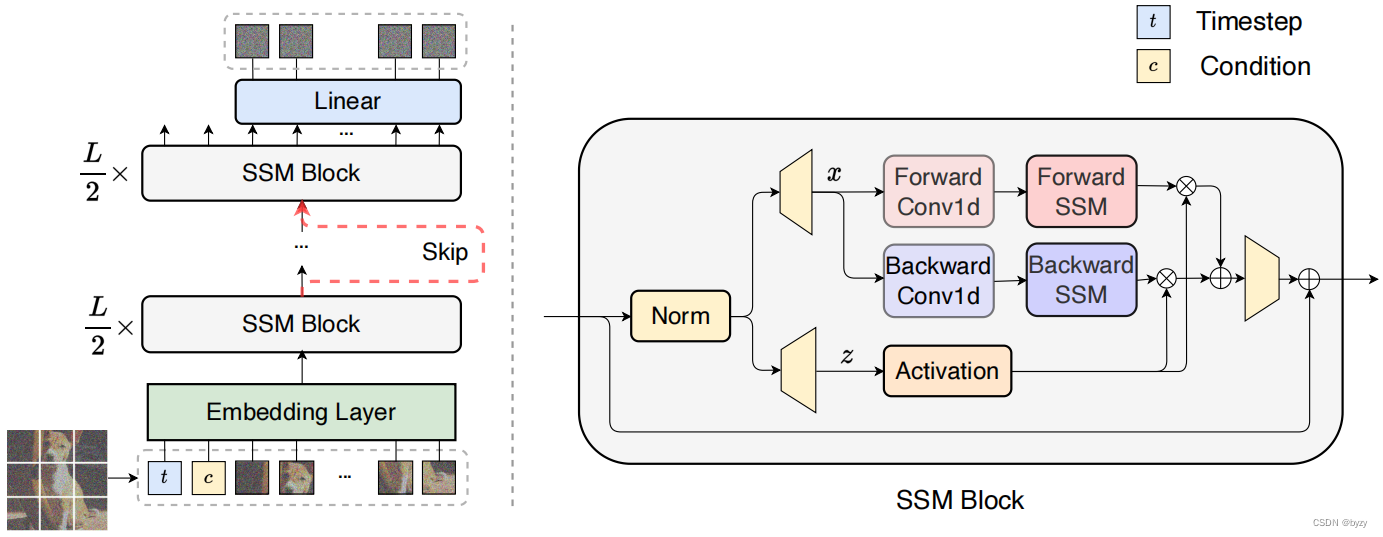
DiTs架构
文章提出DiTs模型架构,完整的架构图如下所示:

Patch化:DiT的输入是通过VAE后的一个稀疏的表示z(256×256×3的图片,z为32×32×4),类似其他ViTs的方式,首先要将输入转成patch,文章采用超参p=2,4,8进行对比实验。
DiT模块设计:
- In-context条件:in-context条件是将t和c作为额外的token拼接到DiT的token输入中;
- Cross-attention模块:DiT结构与Condition交互的方式,与原来U-Net结构类似;
- Adaptive layer norm(adaLN)模块:使用adaLN替换原生LayerNorm(NeurIPS2019的文章,LN 模块中的某些参数不起作用,甚至会增加过拟合的风险。所以提出一种没有可学习参数的归一化技术);
- adaLN-zero模块:之前的工作发现ResNets中每一个残差模块使用相同的初始化函数是有益的。文章提出对DiT中的残差模块的参数γ、β、α进行衰减,以达到类似的目的。
模型大小:与ViT大小相似,分别使用DiT-S、DiT-B、DiT-L和DiT-XL,Gflops从0.3dao118.6。
Transformer Decoder:在Transformer最上层需要预测噪音,因为Transformer可以保证大小与输入一致,所以在最上层使用一层线性进行decoder。
实验
实验设置
模型使用结构/patch数量方式表示,比如DiT-XL/2表示模型采用DiT-XL,patch size为2。
训练:在ImageNet 256×256和512×512分辨率的数据集上训练。初始化最后一层线性层为0,其他初始化都与ViT一致。训练模型采用AdamW,学习率1e-4,no weight decay,batch size为256,数据增广仅有水平翻转。无需学习率warmup和正则化。实验结果使用EMA model(decay 0.9999)。
Diffusion:使用VAE将256×256×3的图像编码到32×32×4的隐空间,经过扩散模型的逆向过程后,将32×32×4的隐空间还原到256×256×3的图像。

评价指标:使用250步DDPM采样,计算FID-50K的结果,没用特殊说明时未采用classifier-free guiance。此外还增加了Inception Score、sFID、Precision/Recall等指标。
实验结果
DiT结构:从下图可以看出adaLN-Zero方法明显好于cross-attention和in-contenxt,所以下文中均采用adaLN-Zero方法进行上下文交互。

model size and patch size评估:如下图所示,模型越大、patch size越小生成图像质量越好。

计算开销和模型效果的关系:如下图左所示,Gflops越大模型效果越好,同样如下图右所示,模型越大计算约高效(相同计算量下模型效果越好)

不同扩散模型的效果对比如下( DiT-XL/2 (118.6 Gflops) is compute-efficient relative to latent space U-Net models like LDM-4 (103.6 Gflops) ):

结论
文章提出DiTs结构进行扩散模型图像生成,在Gflops与Stable Diffusion相当的DiTs-XL/2的结构上,把ImageNet 256×256数据集上的FID指标优化到了2.27,达到了SOTA的水平。未来将进一步探索更大的DiTs模型和token数量。