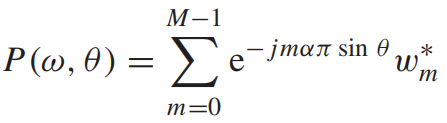对于解决该方法我们一般如下操作,不需要知道为什么,有模板(个人观点)
使用BufferedReader代替Scanner:Scanner类在读取大量输入时性能较差,而BufferedReader具有更高的读取速度。可以使用BufferedReader的readLine()方法逐行读取输入数据。
使用StringTokenizer:StringTokenizer是一个用于分割字符串的工具类,相比正则表达式或者String的split()方法,它具有更高的执行效率。可以使用StringTokenizer来分割输入数据。
目录
一、读取基本数据类型
二、String类型
(1)以回车为结束符
(2)以空格为结束符
一、读取基本数据类型
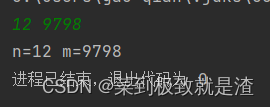
import java.util.*; import java.io.*; public class Main { public static void main(String[] args) throws IOException { BufferedReader br=new BufferedReader(new InputStreamReader(System.in)); StringTokenizer st=new StringTokenizer(br.readLine()); int n=Integer.parseInt(st.nextToken()); long m=Long.parseLong(st.nextToken()); System.out.print("n="+n+" m="+m); } }
二、String类型
(1)以回车为结束符
注意这个读取字符串是以回车结尾的,遇到空格也是会读进去的
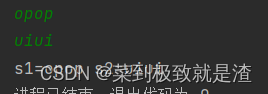
import java.util.*; import java.io.*; public class Main { public static void main(String[] args) throws IOException { BufferedReader br=new BufferedReader(new InputStreamReader(System.in)); String s1=br.readLine(); String s2=br.readLine(); System.out.print("s1="+s1+" s2="+s2); } }
(2)以空格为结束符
import java.util.*; import java.io.*; public class Main { public static void main(String[] args) throws IOException { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); StringTokenizer st = new StringTokenizer(br.readLine()); String s1 = st.nextToken(); String s2 = st.nextToken(); System.out.println("s1=" + s1 + " s2=" + s2); } }