听课(李宏毅老师的)笔记,方便梳理框架,以作复习之用。本节课主要讲了回归和分类的区别,分类的过程,分类的损失函数。这节课比较简短。
1. 回归和分类的区别
- 回归只是输出一个预测的值
- 分类是输出预测的class
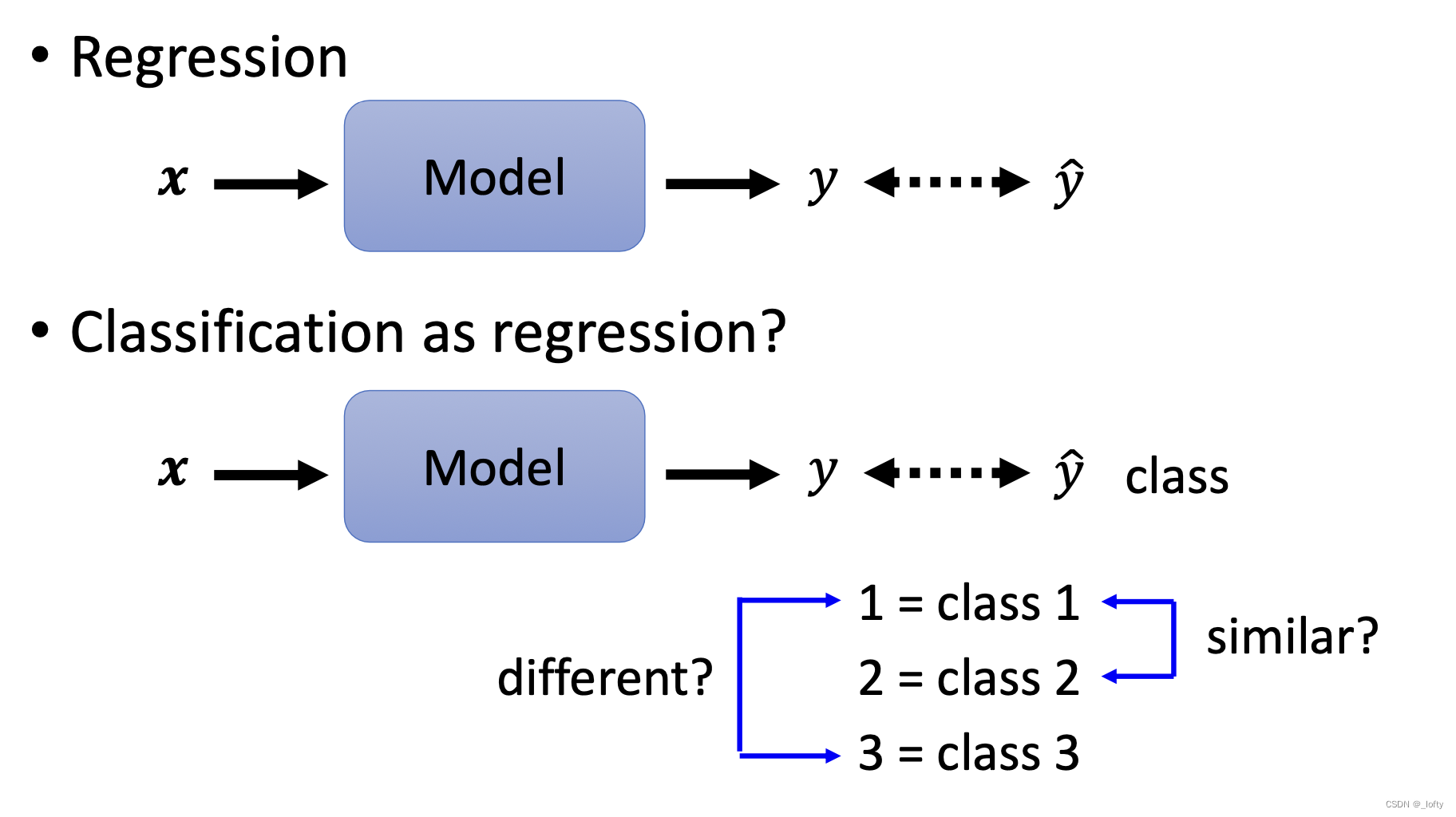
那么class用什么表示呢?用1,2,3代表class 1, class 2, class 3吗?但是这样是不行的,如果用数字代表类别,难道说class 1 与class 2 是类似的吗?因为1和2数字很接近。
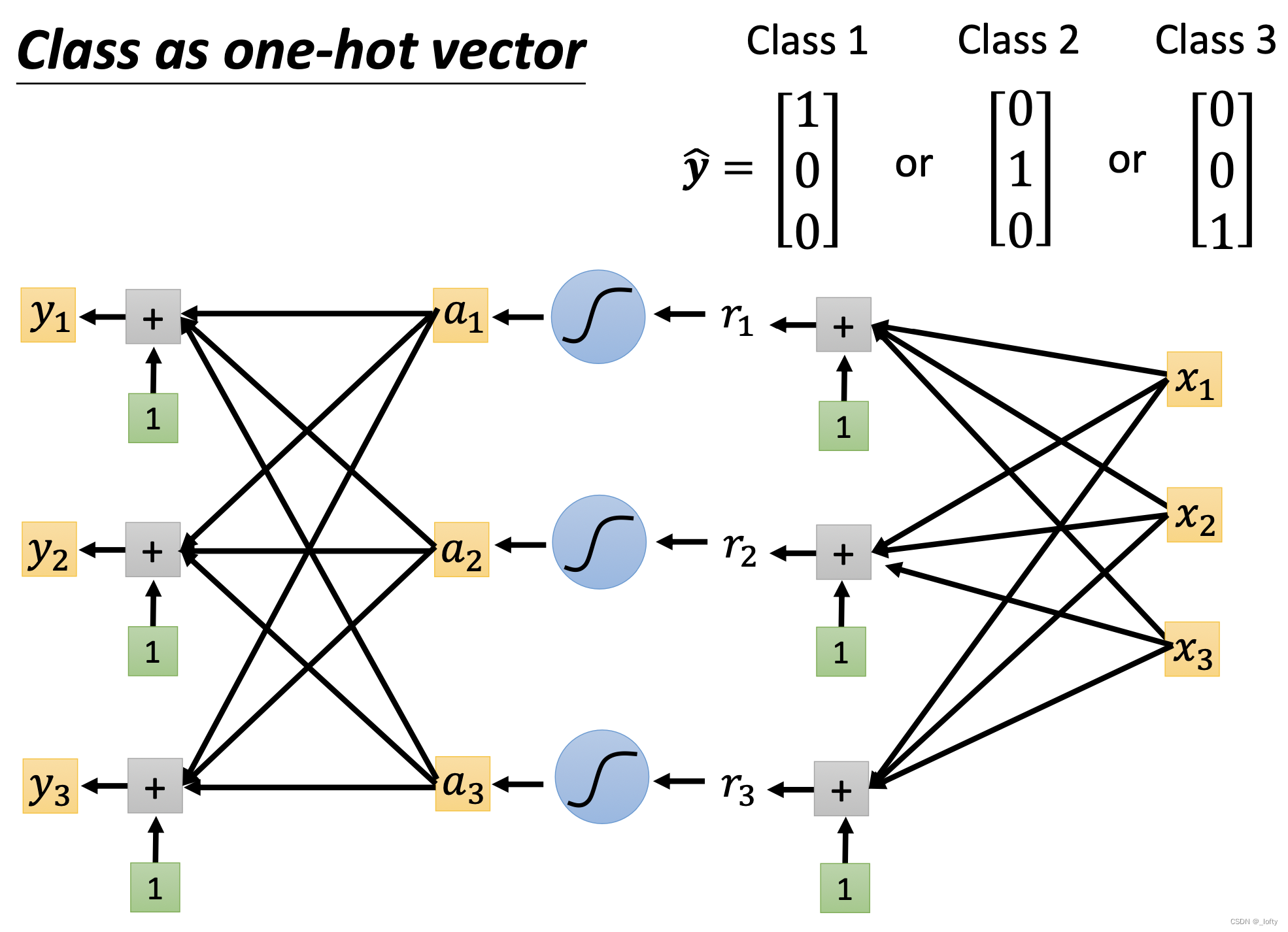
2. 使用向量表示类别
但是这里要注意a1,a2,a3是乘以不同的权重参数
a1w11,a1w12, a1*w13这样的
3. 输出的处理——softmax函数
经过上图的处理之后,得到的输出值可能是任意的,但是我们想要的向量,每一个元素都要0-1之内,所以我们需要对输出进行一些处理。
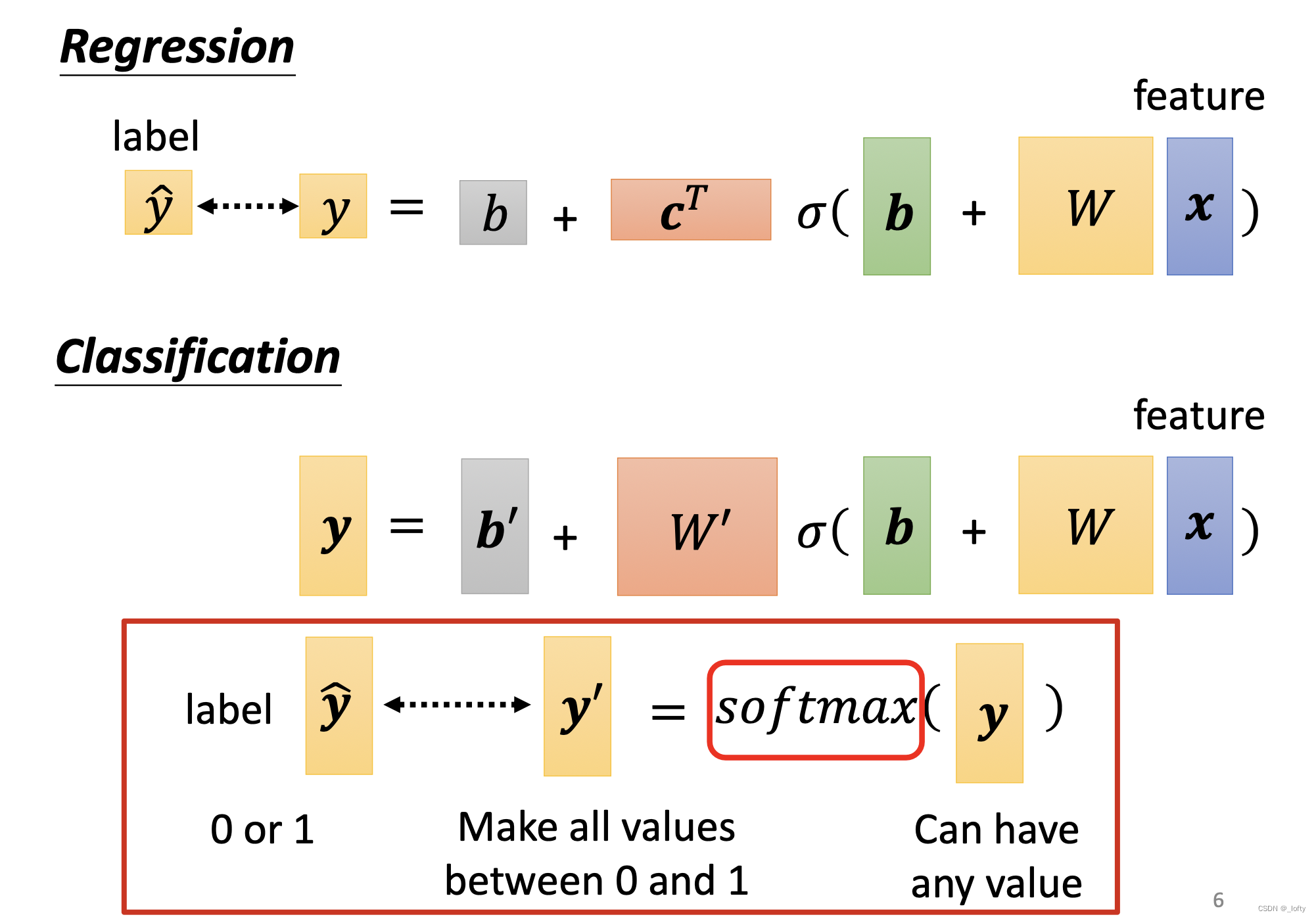
softmax函数的表达式具体如下图红框所示:
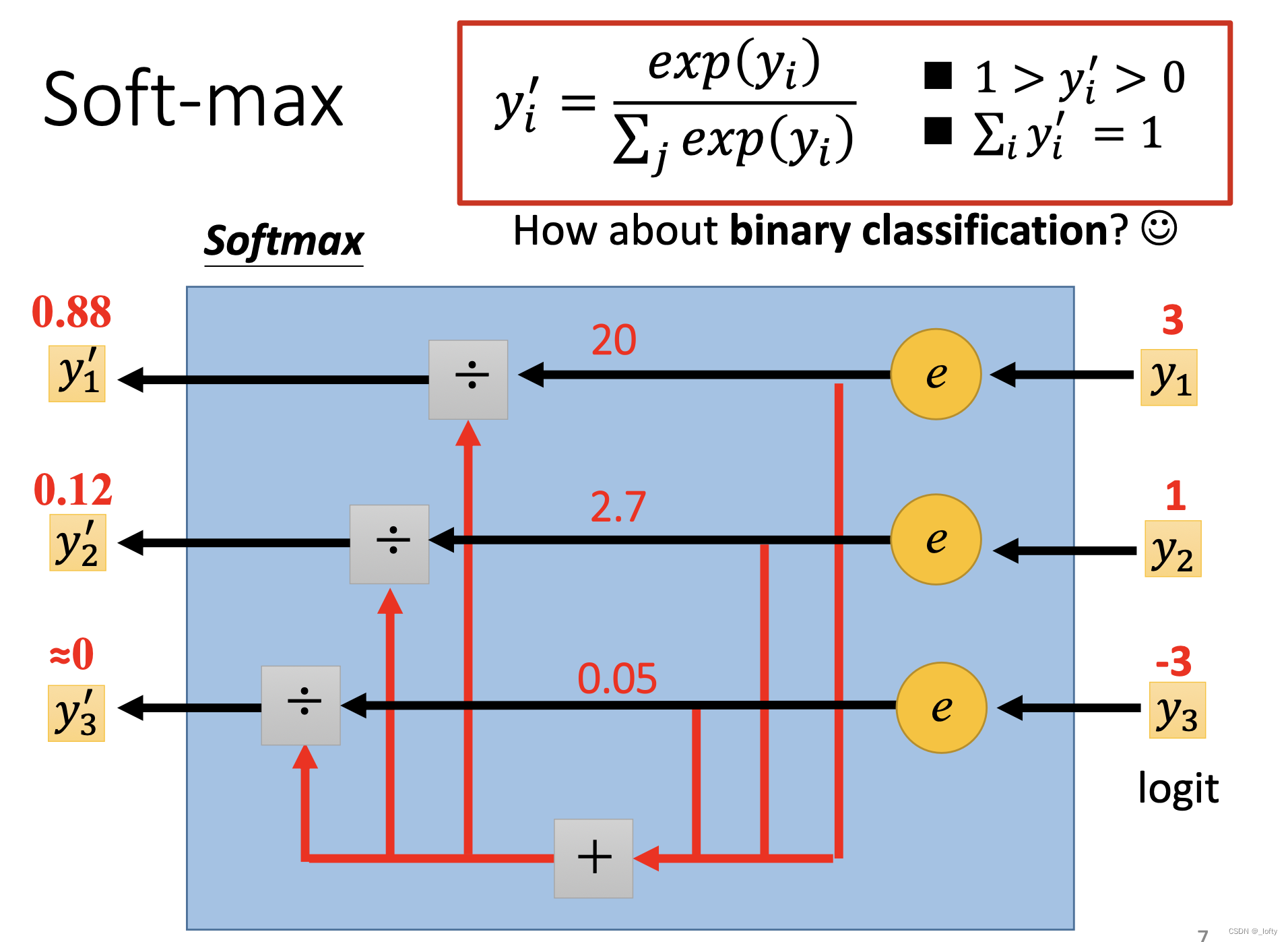
经过softmax之后,数据之间的差距会变大。具体数据差距可见上图所示。
4. 分类的损失函数
我们之前在linear model讲过损失函数的表达式,常用MSE计算,但是在分类任务里我们却倾向于采用另一种损失计算方式——cross-entropy(交叉熵),甚至在pytorch里。softmax与cross -entropy是捆绑在一起的。
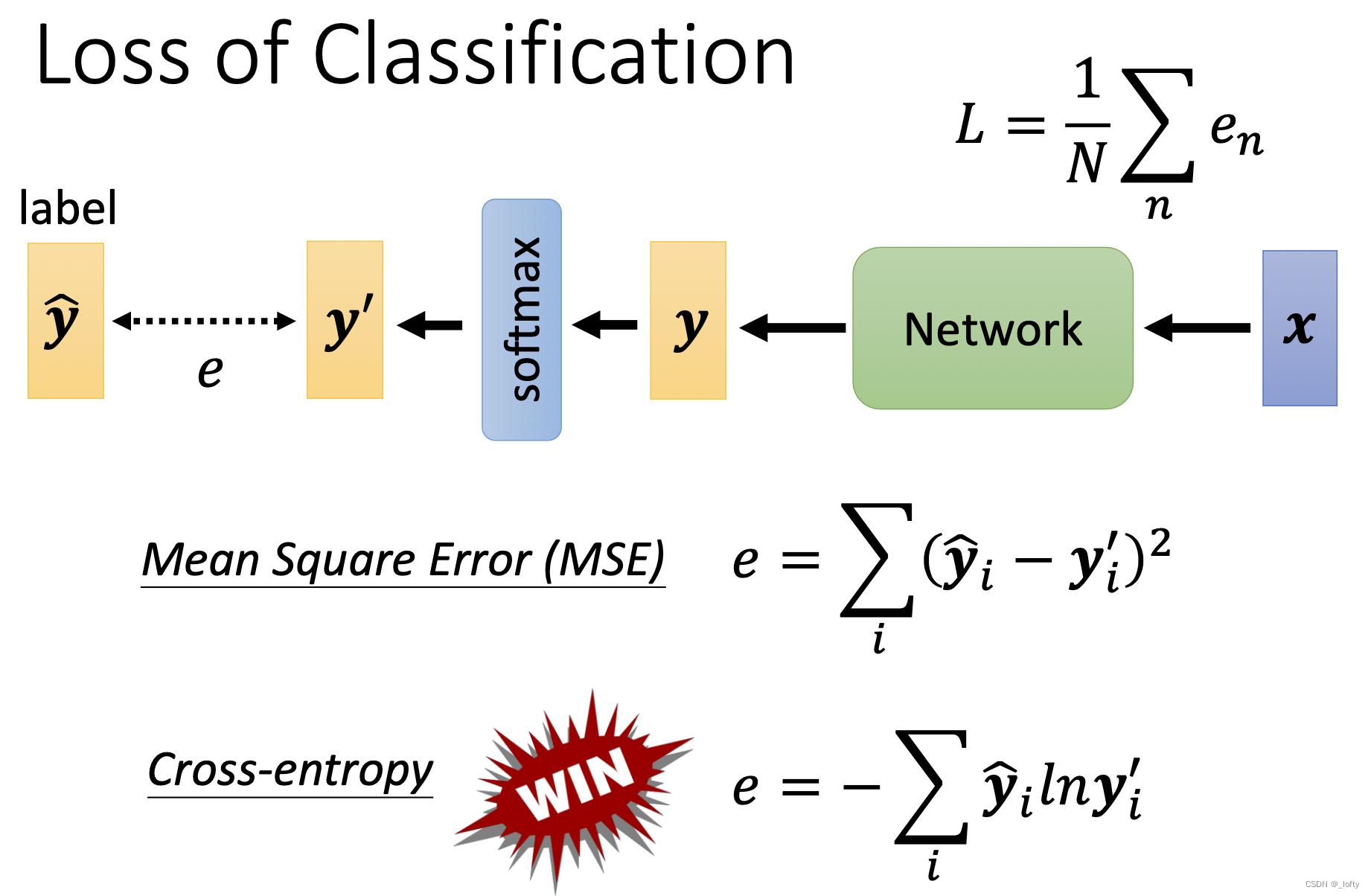
那为什么选这个呢?它的优势到底在哪里?
5. cross-entropy在分类学习中的优势
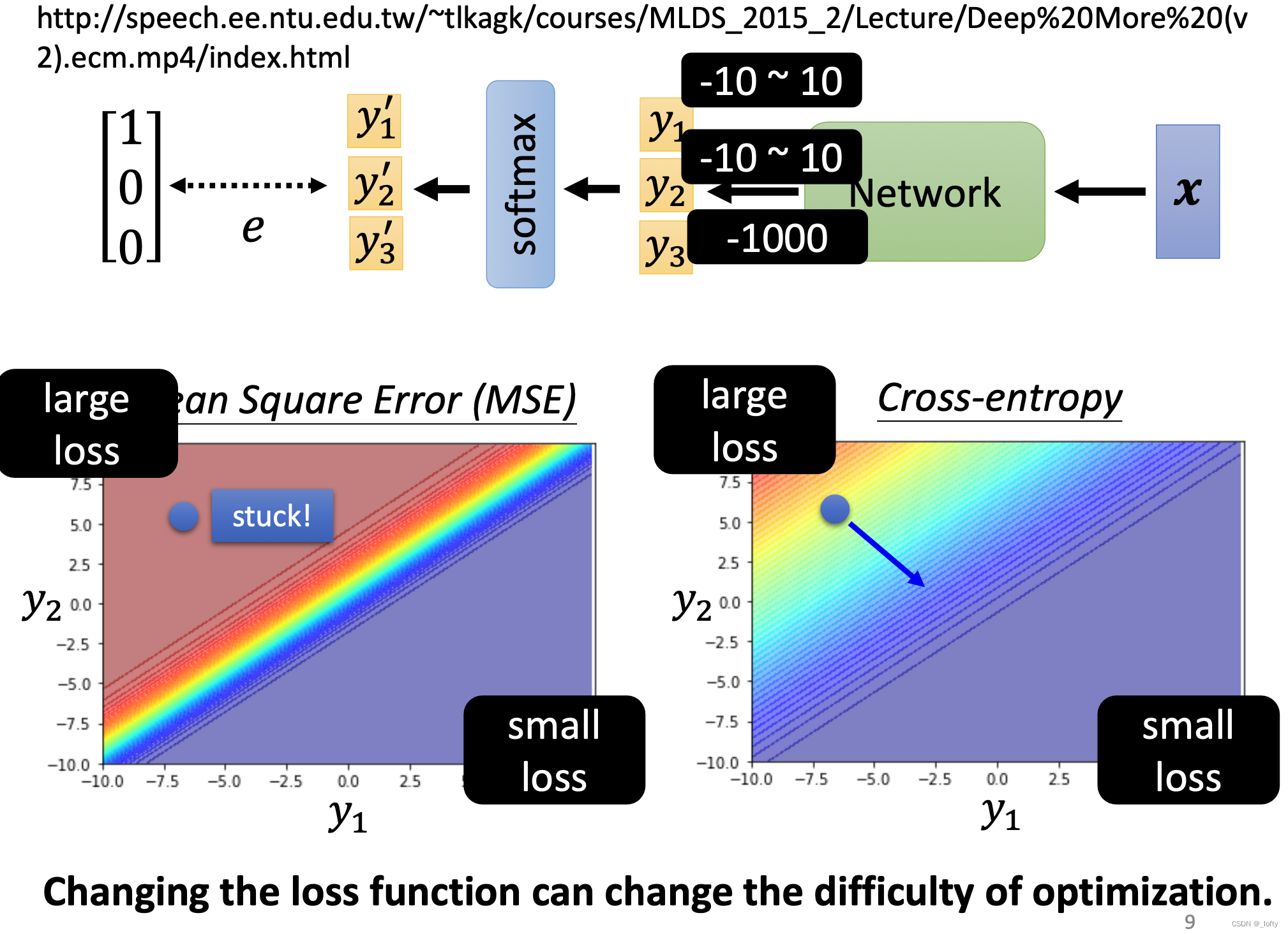
下图是实验得出的数据。
如果采用MSE那么在gradient decent中很有可能被卡住,在左上角gradient几乎为0,使用Adam的话还是有可能走到右下角的,因为会自动调大学习率。
但是如果我们采用cross-entropy就不用太担心这个问题,这个损失函数更好,那么optimization时的难度也会相对地降低