一、调度器演进
1.1 什么是IO调度器?

传统的磁盘因为有磁头,磁头移动有开销。最早的调度器会对访问磁盘的IO做基于磁盘访问位置的排序和合并, 让磁头以最少的移动来完成最大的IO量, 以提升系统IO带宽。


现在的SSD, 物理上已没有磁头的概念, 访问的位置也是LBA(Logical block address), 器件内部负责找到LBA到物理位置的映射关系。排序就没有太大作用, 随机访问的速度也接近顺序读写。IO调度主要是以服务应用场景为主(读优先,VIP线程优先,时间片/带宽公平调度等) 。
IO scheduler处于内核IO栈 中block layer的一部分,主要作用就是对IO 进行qos, 根据不同的qos目标(延迟、公平、带宽、功耗等)有各种各样的调度器:历史到现在mainline出现过(红色是现存的):noop(只做简单的merge )/deadline(排序,读写区分对待,延迟控制)/cfs(时间片公平)/mq-deadline/bfq(带宽公平)/kyber(不同的IO类型 q不同的延迟)
未进mainline的调度器:
SIO(不合并IO)、VR(翻转磁头惩罚机制)、Row(read over write)、Zen(不合并也不排序,仅有超期处理) 、Maple(不合并不排序,亮屏和灭屏策略不一样) 、FIO(基于IOPS指标 进程公平)等。
这些调度器随着发展, 目前只有右图这样子:
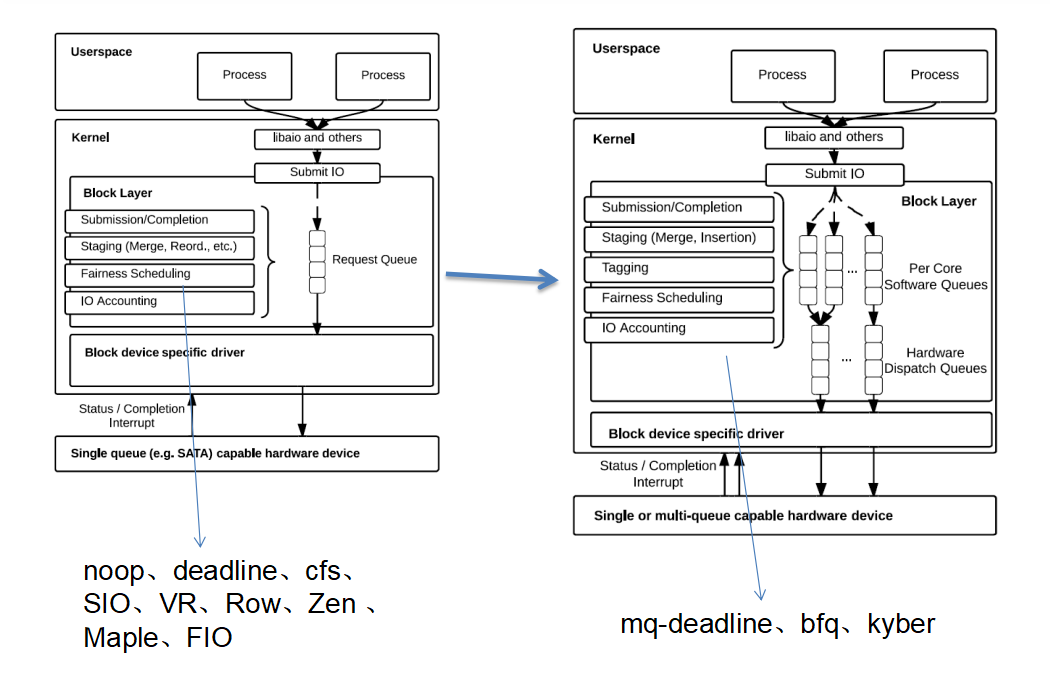
现在看看这些调度器的策略有什么不同:
1.2 kernel 6.1 社区调度器
Kyber调度器
2017年引入,2018后就不怎么修改(目前为止,没有支持io priority /blk cg)。核心思想, 就是把IO分成不同的类型(读、写、擦除、其他), 每个类型的队列单独控制延时, q的是不同的延迟, 所有策略围绕这个目标展开。


默认情况下延迟控制如上
1.3 MQ-DEADILINE调度器
作为deadline的mult queue版本。deadline在内核2.5时代已经存在。
核心思想没有变化:
1. IO进入调度器会被同时加入 读写rb tree 和fifo 队列中, 按访问sector排序。
2. 如果有超期的IO ,先发送超期的IO, 无超期的IO 按优先级发送IO, 同优先级读写非严格按照2:1 dispatch, 发送IO时 按各自rb tree 发送(sector 增长方向)。
3. 读和写的超期时间不一样。 
4. 预留了1/4 req给同步IO(除去write)。

5. dispatch先检查超期req (读和写超期时间不一样), 无超期 再按读写2:1的比例下发IO。
6. linux-5.14开始支持ioclass/ionice。
7. 不支持blk cgroup
1.4 BFQ调度器
改自CFQ,BFQ 是 带宽公平的调度器, 支持cgroup. 从4.12版本开始支持, 设计原则想兼顾带宽和响应。实际上由于算法复杂,最低lat会其他调度器多数倍。
核心特性:
1. “budget fair”策略:每个线程公平的分配sector数进行IO, 因交互式进程只需少量的budget, 交互式进程得以快速响应。
2. 优先级支持:进程bfq weight越大(新进程权重临时提升),budget增长越慢(意味着调度更频繁)。
3. 调度效率。引入idle_time,做完一个thread的IO后 。为了不让这个APP后续IO重新排队(也为了新的APP得到比较好速度), 会idle一定时间再切换下一个线程。
二、kernel6.1的elv(bfq/kyber/mq-deadline)
elv 实现其实是一套call back 嵌入在block layer, 搞清楚这些call back就可以看出不同elv的核心思想。


一笔IO 要在elv中经过:allow_megre->bio_merge->requset_merge->request_merged->limit_depth->prepare_request->insert_request->has_work->dispatch_request->completed_request->finish_request 才可以一笔IO。
在block layer, 什么时候IO 会进入调度器?
实际上有很多入口,整体上submit_bio是从fs下来的普通IO(常规的文件访问),其他一些入口主要给一些特别的IO使用,比如ioctl(查询器件状态等), flush等。这些特别的IO 虽然会经历这个flow,但通常by pass调度器。
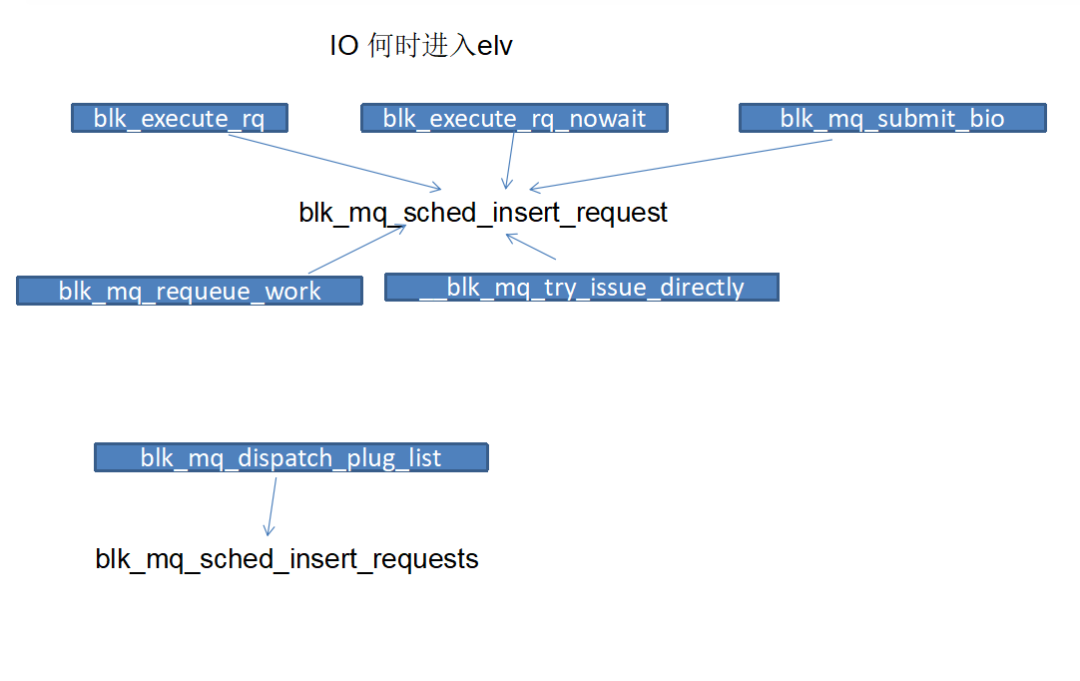
insert req就是把req挂入到elv的队列中(每种elv的队列实现方式通常都不一样), dispatch的线程不一定是IO的发起者, 有两个case:
1. IO业务发起者直接下发到设备驱动,(需要同步IO + 设备ready)
2. 经过run_work异步线程转发(异步IO,或同步IO发起时,设备没ready)

2.1 Kyber调度器
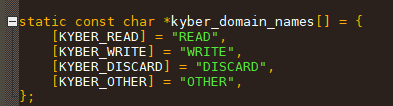
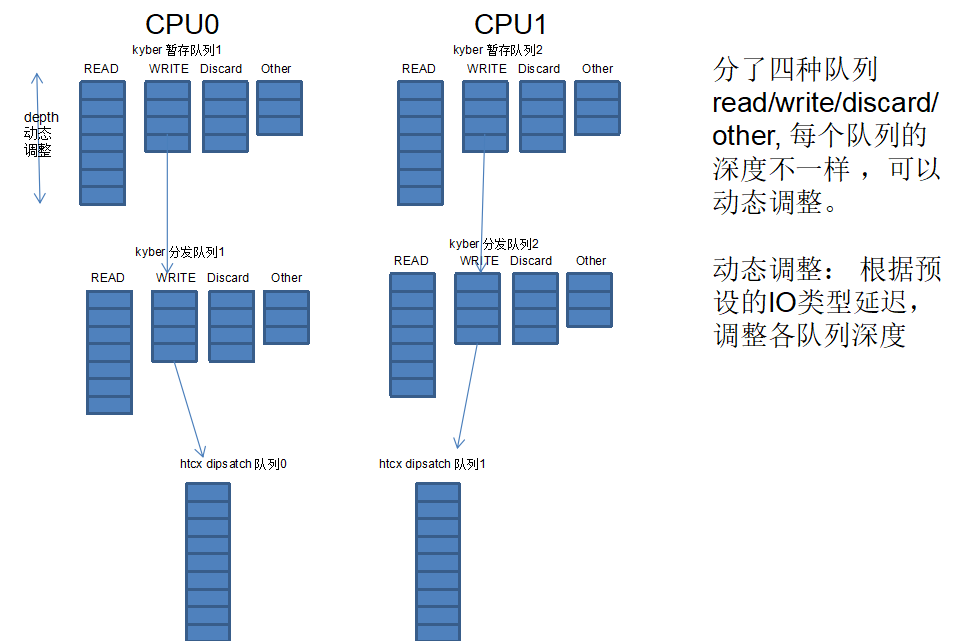
Kyber引入调度域的概念:给IO划分了4个调度域,每个域都有一个bitmap, 表示该域req 资源占用情况。
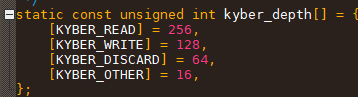
每个调度域的深度不一样, 即可用req数量不一样。插入IO实际上就是插入到这个阈所属的队列上。

每个调度域batch size不一样,即每次一个调度域单次最多dispatch处理batch_size个reqs。

异步IO 占比75%, 即总是预留25% 的req给同步IO。

不同类型IO延迟控制不一样。

Kyber insert req
可以看到就是根据IO的类型, 比如是读 还是写 或擦除操作,把IO加入到不同阈的队列当中。

Kyber dispatch
Dispatch则是根据不同阈IO的质量(kyber以IO花费的平均时间作为指标,),选择合适的队列进行dispatch
选择一个domain 最多发送batch个req.

找到队列中的req进行dispatch

kyber在选择domain时,要根据IO的质量(IO花费时间), 下面说说质量是如何算的:
Kyber 时延计算

KYBER_IO_LATENCY: rq执行的时间(类似D2C)
KYBER_TOTAL_LATENCY:rq从申请出来到执行完的时间(类似G2C)
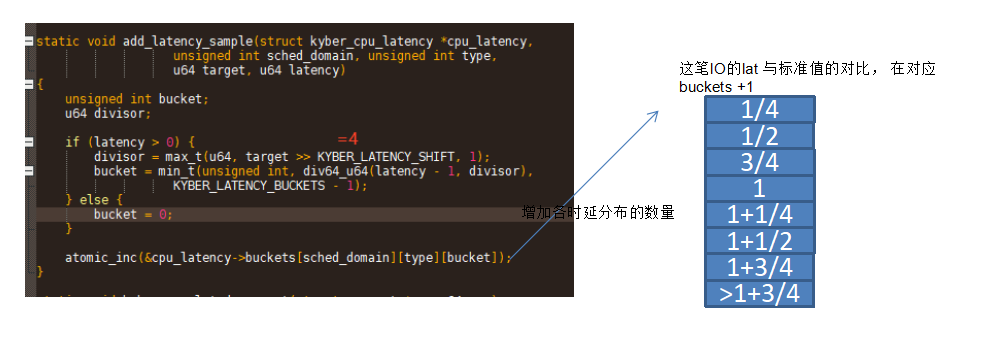
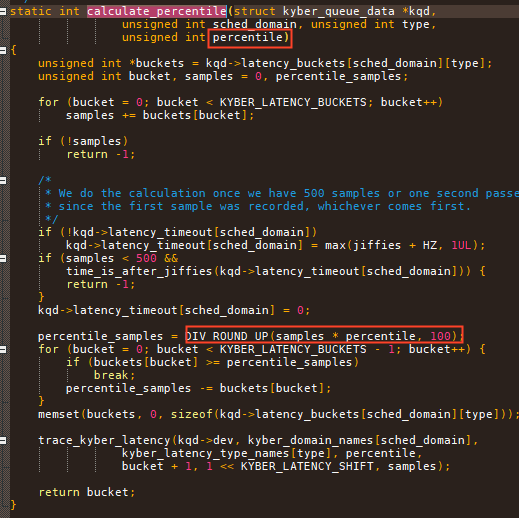
简单的可以理解为,kyber在IO完成的时候,根据IO的花费时间,在bucket中选择合适的位置进行计数。 比如1 为延迟10ms, 如果这笔IO完成在3/4 * 10ms -> 10ms之间, 则在1的bucket里+1;
这样定期查看下某个类型的buckets 比如READ domian, 就可以看到99% READ 延迟在哪个区段。如果落在1之内认为IO是好的, 如果都大于1 认为IO是坏的。
如果IO是坏的,那以后就多发这个类型的IO,少发其他类型的IO, 这类型IO的延迟就可能会好转。Kyber就是通过调整发不同类型IO的数量来完成IO的时延控制。
看下他是如何调整分发数量的:
Kyber 根据时延调整 队列深度
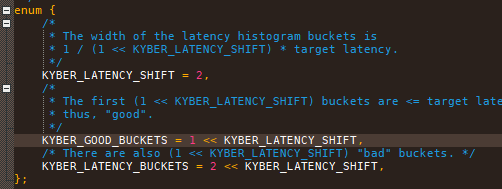
good_buckets即上述所指1的位置, 计算99%的IO和90%的IO在什么区段,来调整队列的depth
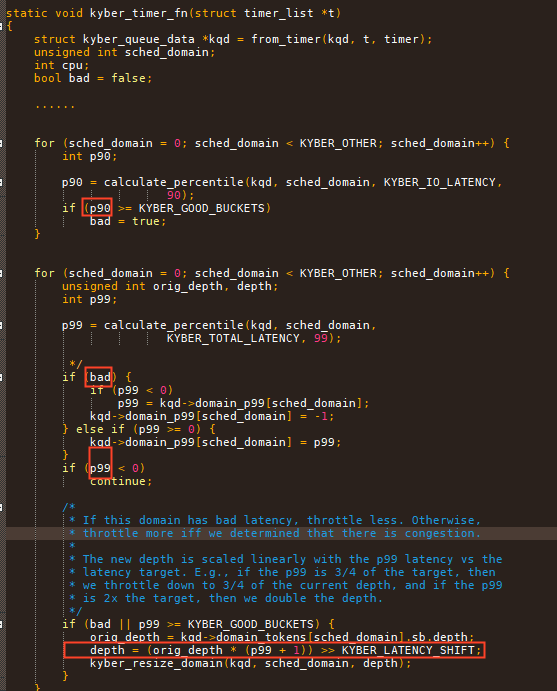
如果比较差,就增加对应队列一倍的depth. 如果很好就缩减到3/4的深度。
延迟的计算如下
Kyber小结
2.2 mq_deadline调度器
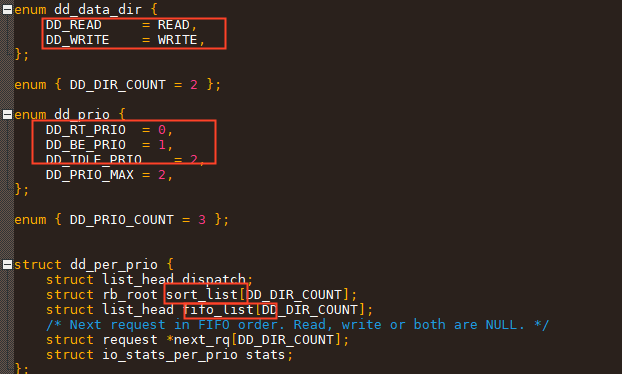
从数据结构来看, 他有优先级的概念,并且有所谓的方向(读or写)
struct deadline_data *dd = q->elevator->elevator_data;
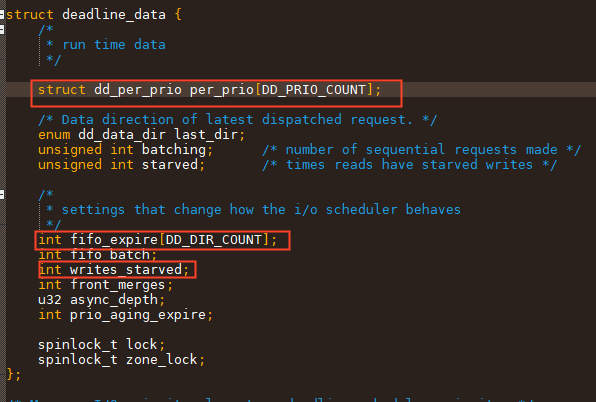
同时也有expire的概念。
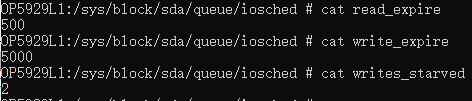
从数据上看, 总结为:
mq_deadline 三个优先级,两种队列,两种IO类型
mq_deadline 插入req, 就是根据IO是读写, 把IO插入到对应优先级的双重队列里:即插入到fifo队列 和sort队列(根据IO访问磁盘的位置)中
mq_deadline insert req

分发条件也简单, 统计进入elv的总数,有IO 就可以发
mq_deadline has work

所谓的deadline,即IO进入elv开始到dispatch有一个deadline.
因此在发送顺序上, 要先找超期的req进行发送, 如果没有超期的req,则按优先级进行发送。
mq_deadline dispatch
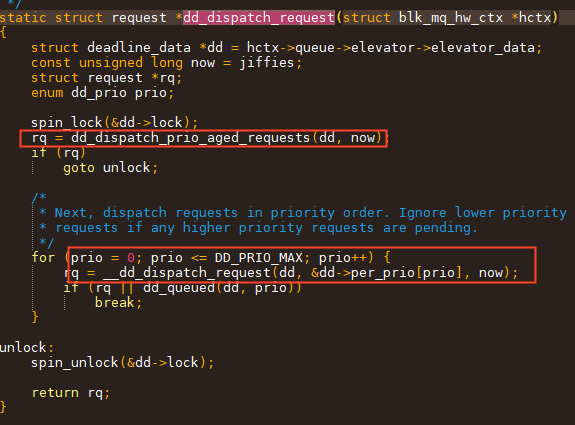
mq_deadline 小结
IO 按磁盘位置在对应优先级的sort tree上排序,发送时先发超期IO,再按优先级发送。(实际上还有write_starved的概念,deadline倾向于发读IO,为了防止写饿死, 会发write_starved次读,才会发一次写)

2.3 BFQ(Budget Fair Queueing)调度器

BFQ的核心思想,就是by thread的发送IO,有点CPU 调度的味道, 每次能发的最大IO量即所谓的Budget。BFQ想保证不同的thread在IO量上是“公平的”。
整体思想就是每个thread在IO上也有一个vtime, 每次总是选vtime小的thread进行发送IO。对于IO的vtime的增长, 在BFQ上是根据这个线程发过的IO量*系数来决定的, 每次能发的最大虚拟IO量 即所谓的buget。
而这里的系数,则比较复杂,BFQ会根据不同类型的IO负载 ,给thread打上标签,比如是交互式线程 还是IO消耗性线程,甚至是刚起来的新线程,依赖多个维度权衡去动态调整系数。从而保证整个系统有比较好的IO响应且比较好的带宽。

由于BFQ的细节流程比较复杂,这里列出其flow:
BFQ insert req
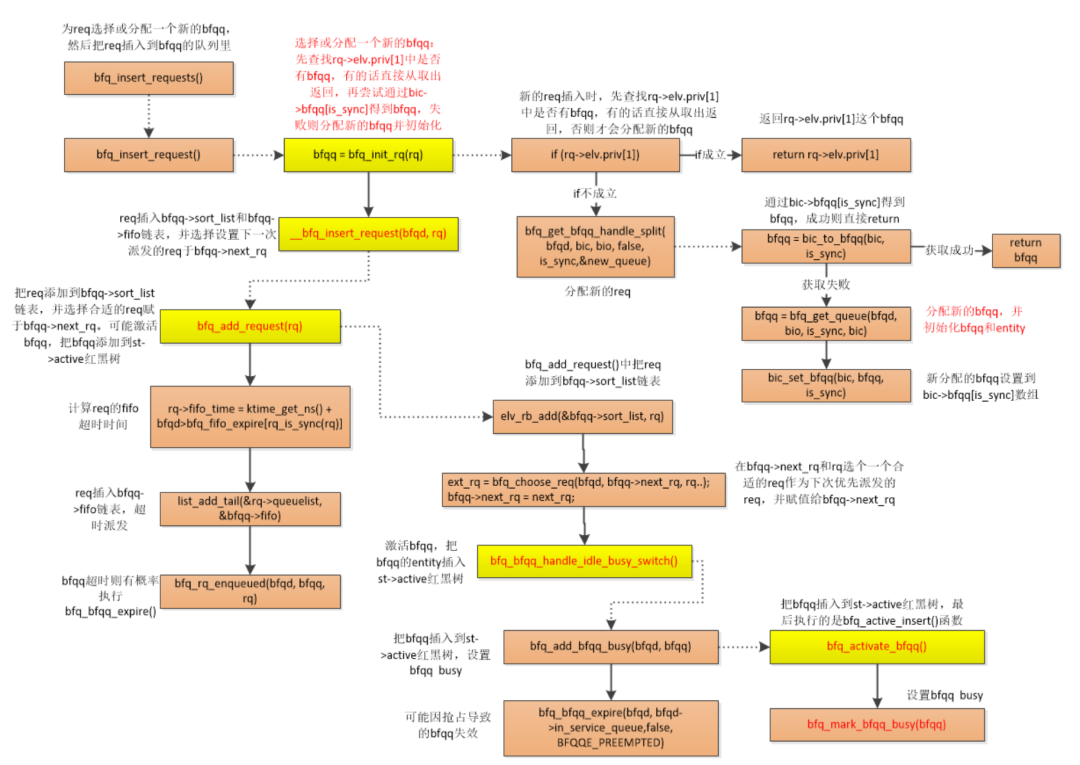
BFQ dispatch req

BFQ dispatch req
总是选vtime最小的进行发送

三、cgroup/ionice
有些调度器是支持IO优先级和cgroup的,业务方时间上可以根据这两个机制 来调整自己IO的质量。
usage: ionice [-t] [-c CLASS] [-n LEVEL] [COMMAND...|-p PID]
deadline idle/RT的带宽差距


两个cgroup: target为idle, load为RT

cgroup

 example:
example:
v1:echo 100 > /dev/blkio/target/blkio.bfq.weight
v2:echo "8:16 rbps=2097152 wiops=120" > io.max


四、other vendor elv
https://github.com/codediablos/io-scheduler/blob/master/vr-iosched.c
https://github.com/codediablos/io-scheduler/blob/master/sio-iosched.c
https://github.com/Pzqqt/android_kernel_xiaomi_whyred/blob/5e5993a2fa5c19d29fe63ee628299ff97ba910fd/block/fiops-iosched.c
https://github.com/codediablos/io-scheduler/blob/master/row-iosched.c
https://github.com/Pzqqt/android_kernel_xiaomi_whyred/blob/5e5993a2fa5c19d29fe63ee628299ff97ba910fd/block/maple-iosched.c#L4
https://github.com/codediablos/io-scheduler/blob/master/zen-iosched.c
参考资料:
1.https://elixir.bootlin.com/linux/v6.1.80/source/Documentation/block
2.BFQ:
https://blog.csdn.net/hu1610552336/article/details/125862606
往
期
推
荐
Android分区挂载原理介绍(上)
Android分区挂载原理介绍(下)
Perfetto数据流架构故障分析:带你研究 trace 为何丢失

长按关注内核工匠微信
Linux内核黑科技| 技术文章| 精选教程