目录
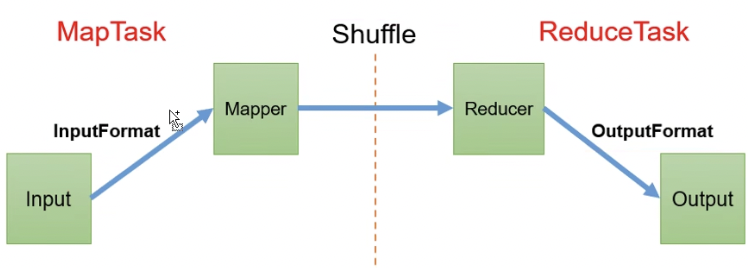
1.InputFormat数据输入
1.1.切片与MapTask并行度决定机制
1.2.Job提交流程源码和切片源码
1.3.FileInputFormat切片机制
1.4.TextInputFormat
1.5.CombineTextInputFormat切片机制
1.6.CombineTextInputFormat
1.InputFormat数据输入
1.1.切片与MapTask并行度决定机制
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
MapTask并行度决定机制
数据块:Block是HDFS物理上的数据分割,数据块是HDFS存储数据单位
数据切片:数据切片是MapReduce程序计算输入数据的单位,一个切片会对应一个MapTask(逻辑切分,并非物理切分)
1.一个Job的Map阶段并行度由客户端在提交Job时的切片数决定
2.每一个Split切片分配一个MapTask并行实例处理
3.默认情况下,切片大小=BlockSize
4.切片时不考虑数据集整体,而是逐个针对每个文件单独切片
1.2.Job提交流程源码和切片源码
1)Job提交流程源码
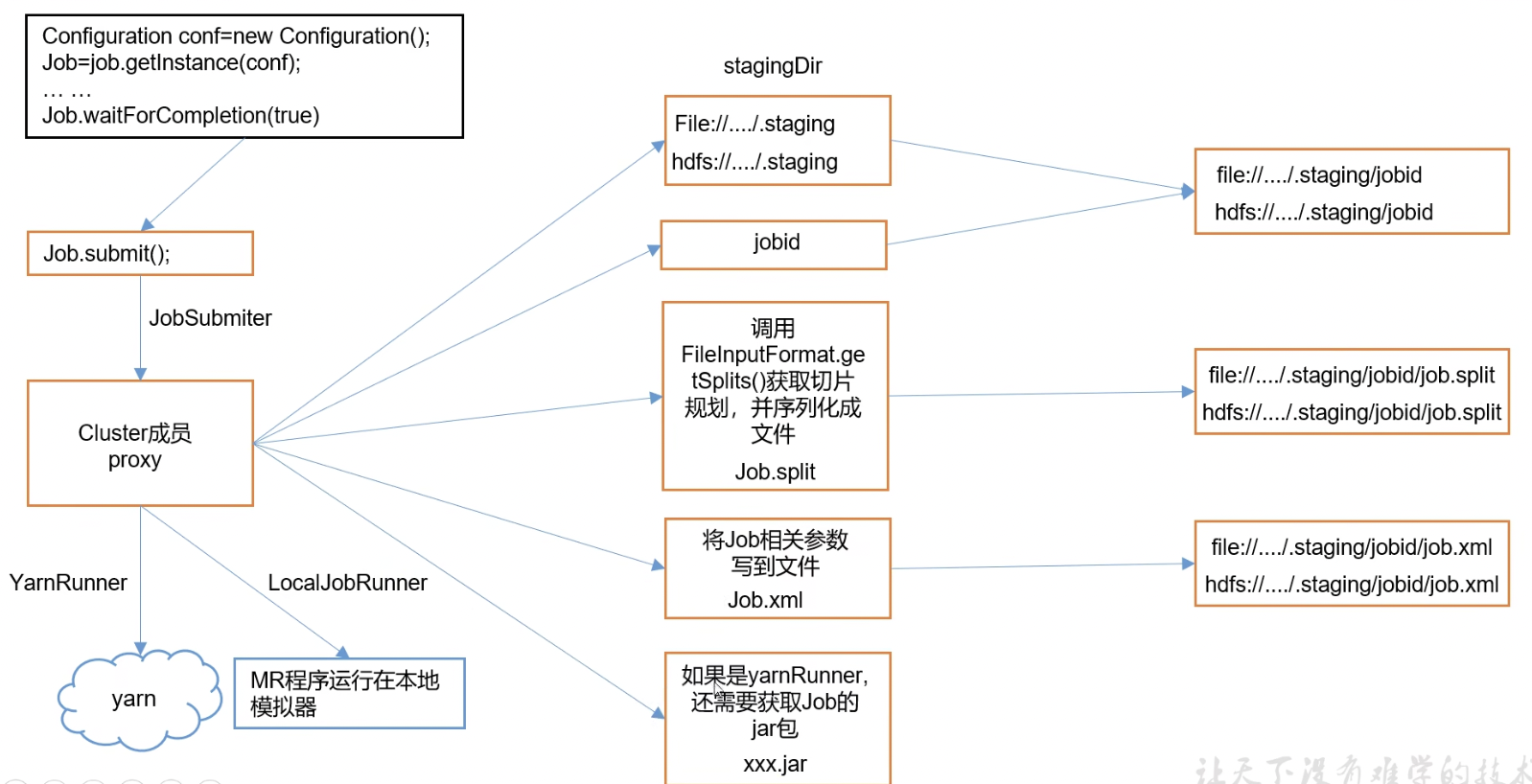
2)FileInputFormat切片源码
1.程序先找到数据存储的目录
2.开始遍历处理(规划切片)目录下的每一个文件
3.遍历第一个文件
3.1.获取文件大小fs.sizeOf(txt)
3.2.计算切片大小computeSplitSize(Math.max(minSize.Math.min(maxSize.blocksize)))=blocksize=128M
3.3.默认情况下,切片大小=blocksize
3.4.开始切片,(0-128M)(128-256M)(256-300M)每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分一块切片
3.5.将切片信息写到一个切片规划文件中
3.6.InputSplit只记录切片的元数据信息,比如起始位置、长度以及所在节点列表
4.提交切片规划文件到Yarn上,Yarn上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数
1.3.FileInputFormat切片机制
1)切片机制
1.简单的按照文件的长度进行切片
2.切片大小,默认等于bolck大小
3.切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
2)FileInputFormat切片大小的参数配置
源码中计算切片大小的公式
Math.max(minSize,Math.min(maxSize,blockSize))
mapreduce.input.fileinputformat.split.minsize=1(默认值为1)
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue(默认值Long.MAXValue)
因此,默认情况下, 切片大小=blockSize
切片大小设置
maxsize(切片最大值):参数如果调的比blockSize小,则会让切片变小,而且等于配置的这个参数的值
minSize(切片最小值):参数调的比blockSize大,则可以让切片变得比blockSize大
获取切片信息API
//获取切片的文件名称
String name = inputSplit.getPath().getName();
//根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit)context.getInputSplit();1.4.TextInputFormat
1.5.CombineTextInputFormat切片机制
1)应用场景
用于小文件过多的场景,可以将多个小文件从逻辑上规划到一个切片中,这样多个小文件就可以交给一个MapTask处理
2)虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job,4194304);//4M
3)切片机制
生成切片过程包括:虚拟存储过程和切片过程两部分