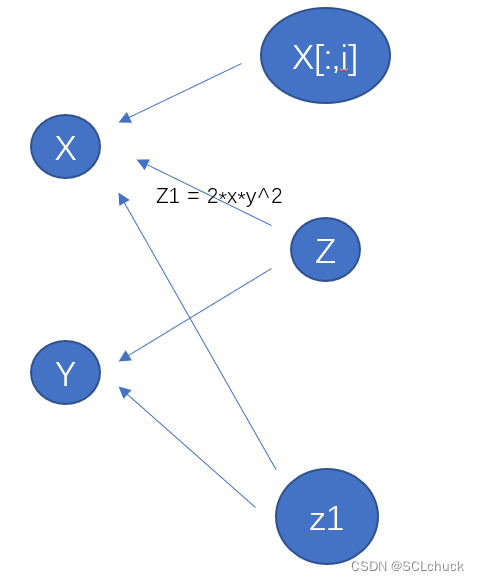
【例子】1.为了反向传播求梯度保存x,y(因为我们知道
d
z
/
d
x
=
2
∗
x
∗
y
2
,
d
z
/
d
y
=
2
∗
y
∗
x
2
dz/dx=2*x*y^2, dz/dy=2*y*x^2
dz/dx=2∗x∗y2,dz/dy=2∗y∗x2), 2.return
(
x
∗
y
)
2
(x*y)^2
(x∗y)2
比如,
z
=
x
∗
y
z=x*y
z=x∗y,若x,y都require_grad=False,则根本不会建立计算图,若x的requires_grad=True,则该计算会建立z->x的计算图
梯度函数,grad_fn
当你进行了建立了计算图的计算,比如x.requires_grad=True,
z
=
x
∗
y
z=x*y
z=x∗y, 那么z.grad_fn就会有函数指针指向反向传播的计算,这里就是这个
x
∗
y
x*y
x∗y
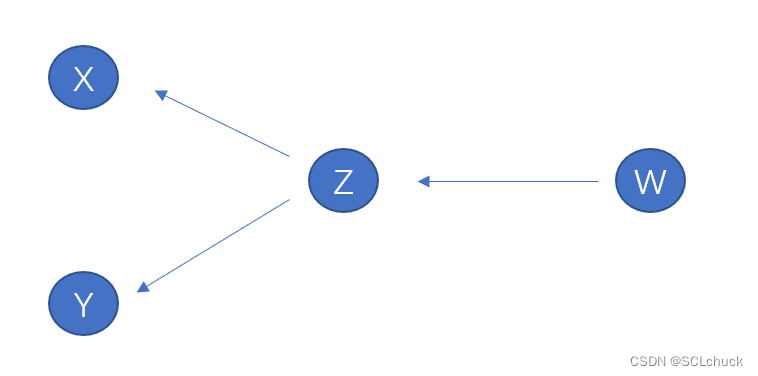
在上图中一个节点虽然向回指向多个变量,但其实对应函数指针,其实是指向一个函数
x
∗
x
∗
y
∗
y
x*x*y*y
x∗x∗y∗y,2个箭头对应的是2个返回值
(
d
z
/
d
x
,
d
z
/
d
y
)
(dz/dx,dz/dy)
(dz/dx,dz/dy),函数指针可以在运算完了后在tensor.grad_fn看到
pytorch中求导的因变量必须是一个shape为[1]的tensor,所以比如当backward时,我们往往取loss.sum() 或者mean(), 那么这里y是个大小不定的tensor,那么这个参数就是和y的shape一样,先令(g代表grad_outputs)
L
=
∑
g
i
j
∗
y
i
j
L=∑g_{ij}*y_{ij}
L=∑gij∗yij, 然后L在对x求导,这里求和往往我们取g=torch.ones_like(y), 相当于y.sum()
一般情况下,不同batch之间的计算是独立的,所以得到的y就算sum后,每个x的得到的梯度其实是batch独立的,但是batch_norm除外,因为batch_norm,不同batch的x会与整个batch的均值做运算, 除非你手写batch_norm,并将数据均值对应的tensor mu detach掉,此时mu对于整个梯度图就是一个常数,否则mu会指向不同batch的x,导致每个x的得到的梯度其实不是batch独立的