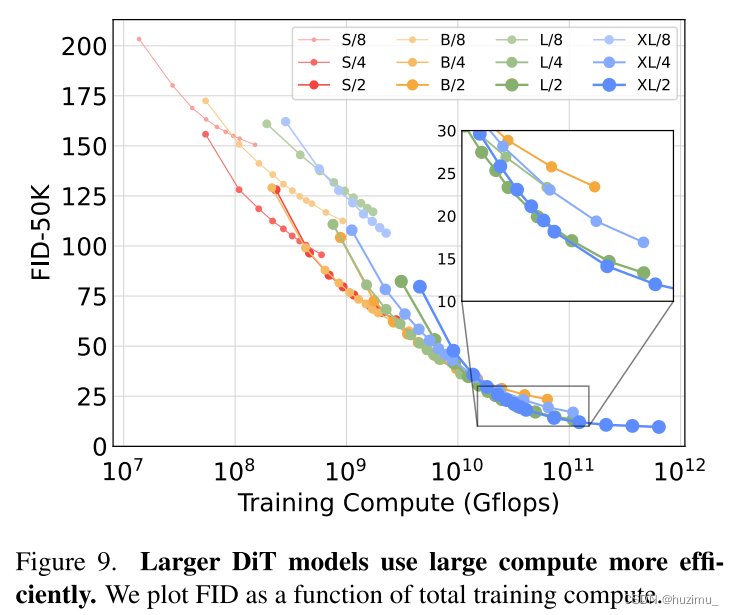
文章目录
- 一、定义模型(放在model.py文件中)
- 二、训练
- 三、测试
- 四、完整的训练和测试代码
一、定义模型(放在model.py文件中)
import torch
from torch import nn
class Guodong(nn.Module):
def __init__(self):
super(Guodong,self).__init__()
self.module = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.module(x)
return x
if __name__ == '__main__':
guodong = Guodong()
input = torch.ones((64, 3, 32, 32))
output = guodong(input)
print(output.shape)
二、训练
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from model import *
dataset_train = torchvision.datasets.CIFAR10("dataset1", train=True, transform=torchvision.transforms.ToTensor(), download=True)
dataset_test = torchvision.datasets.CIFAR10("dataset1", train=False, transform=torchvision.transforms.ToTensor(),download=False)
dataset_train_size = len(dataset_train)
dataset_test_size = len(dataset_test)
print("训练集的数据长度为{}".format(dataset_train_size))
print("测试集的数据长度为{}".format(dataset_test_size))
train_dataloader = DataLoader(dataset_train, batch_size=64)
test_dataloader = DataLoader(dataset_test, batch_size=64)
# 创建网络模型
guodong = Guodong()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(guodong.parameters(), learning_rate)
# 设置训练网络的一些参数
total_train_step =0
total_test_step = 0
epoch = 10
for i in range(10):
print("------第{}次训练开始------".format(i+1))
# 训练开始
for data in train_dataloader:
imgs, target = data
output = guodong(imgs)
loss = loss_fn(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step+1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
运行结果:(部分)



可以看到,随着训练次数的增加,loss整体上在不断变小
三、测试
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
writer = SummaryWriter("train_logs")
dataset_train = torchvision.datasets.CIFAR10("dataset1", train=True, transform=torchvision.transforms.ToTensor(), download=True)
dataset_test = torchvision.datasets.CIFAR10("dataset1", train=False, transform=torchvision.transforms.ToTensor(),download=False)
dataset_train_size = len(dataset_train)
dataset_test_size = len(dataset_test)
print("训练集的数据长度为{}".format(dataset_train_size))
print("测试集的数据长度为{}".format(dataset_test_size))
train_dataloader = DataLoader(dataset_train, batch_size=64)
test_dataloader = DataLoader(dataset_test, batch_size=64)
# 创建网络模型
guodong = Guodong()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(guodong.parameters(), learning_rate)
# 设置训练网络的一些参数
total_train_step =0
total_test_step = 0
epoch = 10
for i in range(10):
print("------第{}次训练开始------".format(i+1))
# 训练开始
for data in train_dataloader:
imgs, targets = data
outputs = guodong(imgs)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step+1
if total_train_step % 100 == 0:
# print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = guodong(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.close()
运行结果:

打开tensorboard后,结果如下:

四、完整的训练和测试代码
主要功能:
加载和准备CIFAR-10数据集,以便训练和测试深度学习模型。
创建一个自定义的深度学习模型(Guodong),并定义损失函数和优化器。
执行训练循环和测试循环,通过反向传播优化模型参数,并评估模型在测试集上的性能。
使用TensorBoard记录训练过程中的损失和准确率等信息,以便后续分析和可视化。
保存训练后的模型参数到文件中,以便后续部署和使用。
此外
在深度学习中,通常使用**.train()和.eval()**这两个方法来设置模型的训练模式和评估模式。这两个方法通常用于 PyTorch 或 TensorFlow 等深度学习框架。
.train(): 这个方法将模型设置为训练模式。在训练模式下,模型会启用训练相关的功能,比如启用 dropout 或 batch normalization 层的运算,以及计算梯度用于参数更新。当调用该方法后,模型会处于可以接受输入数据并进行前向传播、反向传播的状态。
.eval(): 这个方法将模型设置为评估模式。在评估模式下,模型会关闭一些训练过程中的特殊操作,如 dropout 或 batch normalization 的自适应性,以确保在推理阶段的一致性。评估模式通常用于模型在验证集或测试集上的性能评估,以保证评估结果的稳定性和一致性。
通过在训练和评估阶段分别调用.train()和.eval()方法,可以确保模型在不同阶段有正确的行为表现,从而提高训练和评估的效果和可靠性。
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Guodong # 导入自定义的模型类
# 创建TensorBoard的SummaryWriter,用于记录训练过程中的损失和准确率等信息
writer = SummaryWriter("train_logs")
# 加载CIFAR-10数据集
dataset_train = torchvision.datasets.CIFAR10("dataset1", train=True, transform=torchvision.transforms.ToTensor(), download=True)
dataset_test = torchvision.datasets.CIFAR10("dataset1", train=False, transform=torchvision.transforms.ToTensor(), download=False)
dataset_train_size = len(dataset_train)
dataset_test_size = len(dataset_test)
print("训练集的数据长度为{}".format(dataset_train_size))
print("测试集的数据长度为{}".format(dataset_test_size))
# 创建训练和测试数据加载器
train_dataloader = DataLoader(dataset_train, batch_size=64)
test_dataloader = DataLoader(dataset_test, batch_size=64)
# 创建网络模型实例
guodong = Guodong()
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
learning_rate = 1e-2
optimizer = torch.optim.SGD(guodong.parameters(), learning_rate)
# 设置训练网络的一些参数
total_train_step = 0
total_test_step = 0
epoch = 10
for i in range(10):
print("------第{}次训练开始------".format(i + 1))
guodong.train()
# 训练开始
for data in train_dataloader:
imgs, targets = data
outputs = guodong(imgs)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试开始
guodong.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = guodong(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / dataset_test_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / dataset_test_size, total_test_step)
# 保存模型
torch.save(guodong.state_dict(), "guodong_{}.pth".format(i))
print("模型已保存")
total_test_step += 1
writer.close()
代码运行结果: