这边有一个Unity项目用的tolua, 游戏运行后手机上lua内存占用 基本要到 189M, 之前峰值有200多。
优化点1 加快gc频度:
用uwa抓取的lua内存, 和unity的mono很像,内存会先涨 然后突然gc一下,降下来。 这样内存峰值就会比较高,再加上游戏里其他内存占用多, 3G的ios内存吃紧很不友好,容易闪退。
所以一个方法 调了lua gc的参数, 让其加快了gc频率, 由于lua这边是增量式GC的,所以gc频率高了 也没啥卡顿。 最后性能测试 发现lua 游戏里内存占用基本是 一条直线了。
参数是这么设的, 另外一个项目的lua也是这么设的,网上找到的一些例子也设了这个参数:
collectgarbage("setpause",100) --表示当收集器在总使用内存数量达到上次垃圾收集时的(100/100)一倍时再开启新的收集周期。 (默认200)
collectgarbage("setstepmul",5000) --表示垃圾收集器的运行速度是内存分配的50(5000/100)倍,如果此值小于100可能会导致垃圾回收不能形成完整的周期。 (默认200)
collectgarbage("restart")之前是默认值,回收频率比较低。
优化点2 去掉了因require路径 / 和 .的混用造成的重复加载:
参考我另外一篇文章单独说了这个问题。
发现契机是这样的, 这边点开始游戏 会初始化预处理很多数值表(原因就是 require 来 require 去, 引用关系嵌套 导致很多不一定用的表也加载了。 因为登录游戏后服务器发数据过来 必须把有的模块初始化好, 这个也是个优化点,暂时还没去处理), 卡顿很久体验不好。 所以想到刚进游戏 在登录界面等待没事做时可以 分帧加载必须的数值表。 减少一次性的卡顿。
但跟踪发现 好像优化不大,而且好多表都加载2次。
才发现 require "data/xxxx" require "data.xxxx" 在真机上会加载2次 (用的库没改好)。
简单优化方案,入口lua最开头,重写 require 把 传进来的路径 把/替换成的.
实际一跑,发现卡顿时间变少了, 内存还减少了35M左右。
优化点3 数值表lua里内存精简:
一开始看了这篇文章:
Lua性能优化(一):Lua内存优化 - 知乎
里面提到了这篇文章:
Lua配置表存储优化方案 - UWA问答 | 博客 | 游戏及VR应用性能优化记录分享 | 侑虎科技
这边项目的策划数值表是导出成protobuf的二进制格式,然后加载到内存里。方便前后端解析(因为协议都是用Protobuf)。
但项目里数值后期太多, 大头都是数值表,所以优化数值表可以省很多内存:
优化方法A 就是前面有提到的 把字段名优化掉 (这个项目很早之前就实现过了),
把解析出来的数据 每行字段值 按[1] [2] ……[n] 索引存放, 代码请求时 用了一个meta table,里面记录了 表的所有字段名及对应的索引 (从.pbc文件里解析 google.protobuf.FileDescriptorSet 得到的)
local dataMetatable = {}
dataMetatable.keys = {}
local t_pbc = protobuf.decode("google.protobuf.FileDescriptorSet", pbcBuff)
local proto = t_pbc.file[1]
for _,v in ipairs(proto.message_type[1].field) do
dataMetatable.keys[v.name] = v.number
end
dataMetatable.__index = function(t, k)
local v = rawget(t, dataMetatable.keys[k])
return v
end这样确实省下二三十M内存吧(数值不一定准)。 解析表会稍慢些。
优化方案B 每行数据按需加载
这个方案思路本来挺好的, 当时也是为了节省C#那边的mono内存。
把数值文件,预处理一下,把每行数据的各自序列化后按顺序存放成一个二进制文件, 另外还要生成一个索引对照文件,里面记录了某个key 在数值表的起止位置。
这样数值表很多暂时用不到的数据就不用加载进来。 省下很多内存。 getbykey时,找一下发现内存里没有,则用流方式去文件里读取数据,然后单行反序列化下就行了。 (只不过索引文件也会占一部分额外内存放在内存里面)
实际项目到了后期,发现内存没省多少,进游戏加载时也特别卡了。 因为很多数值表 数据需要全部遍历预处理一下一些字段, 造成不少表还是全部读取了,反而没有优化,变得更卡更占内存。 也没有 很久不用就回收 的机制。
(这个可以继续规范优化,比如个别表全部加载方式,个别表按需加载, 再实现长久不用的数据或表释放掉……)
优化方案C 每个数值表设一张默认值表:
就是前面uwa文章里提到的,一般数值表有很多字段完全一样,没必要重复存放。(这边项目后期确实很多字段虽然看起来用着但都默认填一样,基本是废的,但还占用内存)
这样就可以 把一些数据很多的表,统计一下每个字段的默认值,
导表或者解析表数据存到内存时, 发现字段和默认值一样的,就不要导出或者存到内存里,直接置空就行了: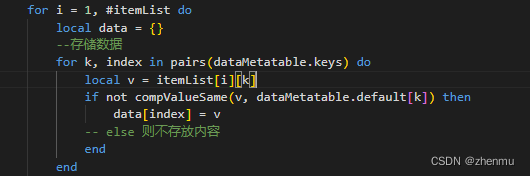
这边是这样实现的在 方案A的基础上做了调整, metatable里加了一个default表,
__index时,如果key取到数据为nil,则从default表里取:
local data_name = proto.message_type[1].name -- 数值表名
dataMetatable.default = InitDataDefault.get_data_default(data_name)
for _,v in ipairs(proto.message_type[1].field) do
dataMetatable.keys[v.name] = v.number
end
dataMetatable.__index = function(t, k)
local v = rawget(t, dataMetatable.keys[k])
if nil == v and dataMetatable.default then
v = dataMetatable.default[k];
end
return v
end
default表的结构类似这样: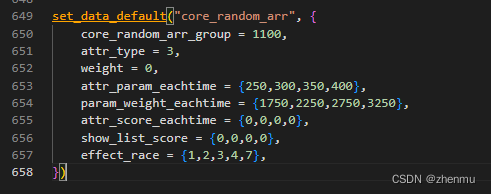
针对几个大表处理, lua gc后,内存降了有40多M, 只不过加载时间可能会变长些,所以目前只是在IOS小内存设备上开了这个处理。
内存优化量仅供参考。 具体还是看数值表的复杂情况和量级。
附带其他几个lua 优化的文章:
Lua性能优化技巧_lua 性能优化-CSDN博客
https://www.cnblogs.com/marcher/p/16866981.html