TensorRT 是由 NVIDIA 提供的一个高性能深度学习推理(inference)引擎。它专为生产环境中的部署而设计,用于提高在 NVIDIA GPU 上运行的深度学习模型的推理速度和效率。以下是关于 TensorRT 的详细介绍:
TensorRT 是 NVIDIA 推出的用于深度学习推理加速的高性能推理引擎。它可以将深度学习模型优化并部署到 NVIDIA GPU 上,实现低延迟、高吞吐量的推理过程。TensorRT 主要用于加速实时推理任务,如物体检测、图像分类、自然语言处理等。
TensorRT是NVIDIA推出的一个深度学习推理优化器,用于在GPU上高效地运行训练好的深度学习模型。它可以将常见的深度学习框架(如TensorFlow、PyTorch等)训练好的模型转换为高性能的推理引擎,从而加速模型的推理过程。
TensorRT的主要作用是提高深度学习模型的推理速度和效率,通过优化模型的计算图和网络结构,减少冗余计算、合并层次、精简精度等方法,从而提高模型的性能。
作用:
- 性能优化:TensorRT 通过层和张量融合、内核自动调整、多流并行以及其他优化技术,提高了推理性能。
- 降低延迟:它可以显著降低推理时的延迟,这对实时应用(如视频分析和自动驾驶)非常重要。
- 减少内存占用:通过优化神经网络的内存使用,降低了对GPU资源的要求。
- 跨平台:支持从框架如 TensorFlow, PyTorch 等导出模型,并通过 ONNX 标准使其与 TensorRT 兼容。
如何使用:
- 模型转换:将训练好的模型转换成 TensorRT 支持的格式,通常是通过 ONNX 中间表示。
- 模型优化:使用 TensorRT 对模型进行优化,包括层融合、精度校准(可选择使用FP16或INT8精度以减少模型大小和提升性能,同时要进行精度损失的校准)。
- 推理:在应用程序中加载优化后的模型,执行推理。
应用领域:
- 自动驾驶和机器人:需要实时处理大量的传感器数据。
- 医疗影像分析:需要快速准确分析医疗影像。
- 云计算服务:提供即时的AI服务,如语音识别和推荐系统。
- 边缘计算:在资源受限的环境中运行深度学习模型,例如物联网(IoT)设备。
安装和配置:
安装 TensorRT 通常包括以下步骤:
- 前提条件:确保有支持的 NVIDIA GPU 和对应的驱动程序。
- 下载:从 NVIDIA 官网下载 TensorRT 的安装包。
- 安装:根据提供的指南安装 TensorRT,通常包括库文件、头文件和工具。
- 环境设置:设置相关的环境变量,例如
LD_LIBRARY_PATH,确保应用程序可以找到 TensorRT 库。 - 验证安装:运行示例应用程序或自己的模型以验证安装是否成功。
安装 TensorRT 还需要注意与 CUDA 的兼容性,因为 TensorRT 依赖 CUDA 进行 GPU 计算。此外,TensorRT 的安装和配置可能会因操作系统和具体版本而异,因此最好参考 NVIDIA 提供的最新官方文档来进行安装和配置。
由于 TensorRT 是专为 NVIDIA GPU 设计的,因此它只能在 NVIDIA 的硬件上使用。在实际部署中,开发者通常会在开发环境中优化模型,然后将优化后的模型部署到生产环境中的服务器或边缘设备上。
TensorRT 的主要作用包括:
- 加速深度学习推理:通过优化模型、减少计算量和内存占用,在保证精度的前提下提高推理速度。
- 支持多种深度学习框架:支持 TensorFlow、PyTorch、ONNX 等主流深度学习框架的模型转换和优化。
- 提供灵活的部署选项:可以部署到各种平台上,包括数据中心服务器、边缘设备、嵌入式系统等。
使用 TensorRT 主要包括以下步骤:
- 准备模型:选择合适的深度学习模型,并将其转换为支持的格式,如 ONNX。
- 优化模型:使用 TensorRT 对模型进行优化,包括融合操作、量化、内存优化等。
- 部署模型:将优化后的模型部署到目标设备上,并集成到应用程序中进行推理。
TensorRT 可以应用在各种场景中,包括但不限于:
- 视觉领域:物体检测、图像分类、人脸识别等。
- 语音处理:语音识别、语音合成等。
- 自然语言处理:文本分类、命名实体识别、机器翻译等。
- 自动驾驶:目标检测、车道线检测、行人识别等。
安装配置 TensorRT 可以参考官方文档和 NVIDIA 官网提供的指南,一般包括以下步骤:
- 下载安装 TensorRT 软件包,根据官方指南进行安装。
- 配置 GPU 驱动和 CUDA 工具包,确保与 TensorRT 版本兼容。
- 设置环境变量,配置 TensorRT 的路径和依赖库。
- 测试安装是否成功,可以使用示例代码或自己的模型进行推理测试。
使用TensorRT可以通过以下步骤进行:
- 导入模型:将训练好的深度学习模型导入到TensorRT中,支持的模型格式包括Caffe、ONNX和TensorFlow等。
- 优化模型:TensorRT会根据输入、输出和网络结构等信息进行模型的优化,以提高推理性能。
- 构建推理引擎:根据优化后的模型,TensorRT会生成一个高性能的推理引擎。
- 运行推理:将输入数据传入推理引擎中进行推理,并获取输出结果。
TensorRT可以应用在许多领域,包括图像识别、人脸识别、机器视觉、自然语言处理等。由于TensorRT的优化能力,它可以在保持模型准确性的同时,大大提高模型的推理速度,适用于对实时性要求较高的场景。
安装TensorRT可以按照以下步骤进行:
- 下载TensorRT:从NVIDIA官网下载适用于自己系统的TensorRT安装包。
- 安装依赖库:安装TensorRT需要依赖一些其他库,如CUDA、cuDNN等,需要根据TensorRT版本和自己系统的兼容性进行配置。
- 安装TensorRT:按照官方文档提供的安装步骤进行安装,可以选择将TensorRT安装在默认位置或自定义安装位置。
- 配置环境变量:将TensorRT的安装路径添加到系统环境变量中,以便在命令行中可以直接使用TensorRT的命令和工具。
在安装完成之后,可以使用TensorRT的Python API或C++ API进行模型导入、优化和推理等操作,具体的使用方法可以参考TensorRT官方文档或示例代码。
总的来说,TensorRT 是一个强大的深度学习推理加速引擎,可以帮助开发者高效地部署深度学习模型并实现高性能的推理任务。通过合理的使用和优化,可以在各种应用场景中发挥重要作用。
训练和推理的区别
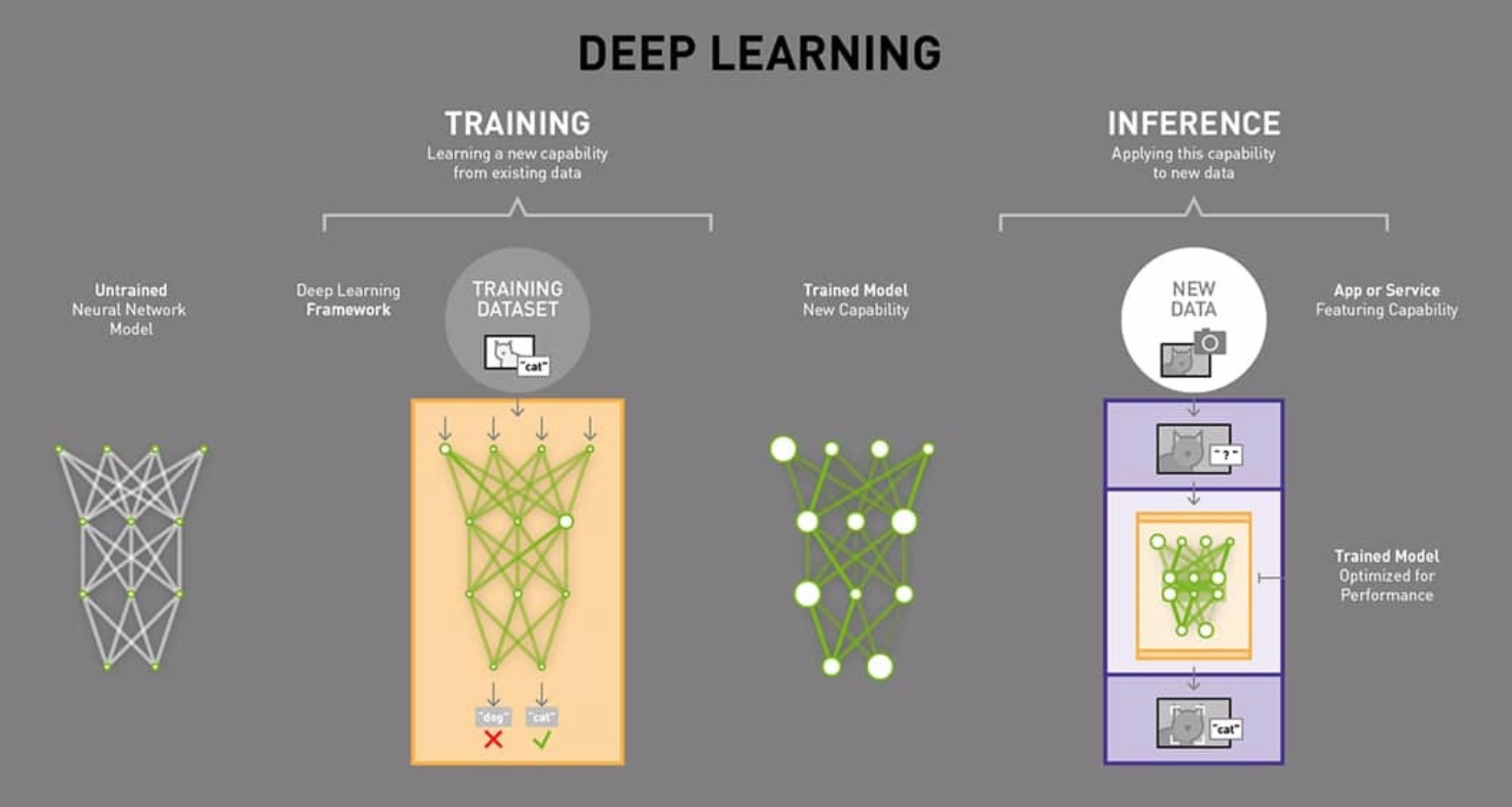
- 训练(Traning)过程是网络不断对训练数据集进行学习的过程。训练包括前向传递和后向传播两个阶段,前向传递用于预测标签,然后再通过预测标签与真实标签之间的误差进行后向传播不断修改网络的权重(weights)。在训练的过程中,网络的权重是不断变化的。
- 推理(Inference)的目的是输出预测标签,仅仅包含前向传递阶段,而且网络的权重是不变的。简言之,推理阶段就是利用训练好的网络进行预测。
TensorRT
TensorRT是nvidia家的一款高性能深度学习推理SDK。此SDK包含深度学习推理优化器和运行环境,可为深度学习推理应用提供低延迟和高吞吐量。在推理过程中,基于TensorRT的应用程序比仅仅使用CPU作为平台的应用程序要快40倍。
TensorRT 优化和性能
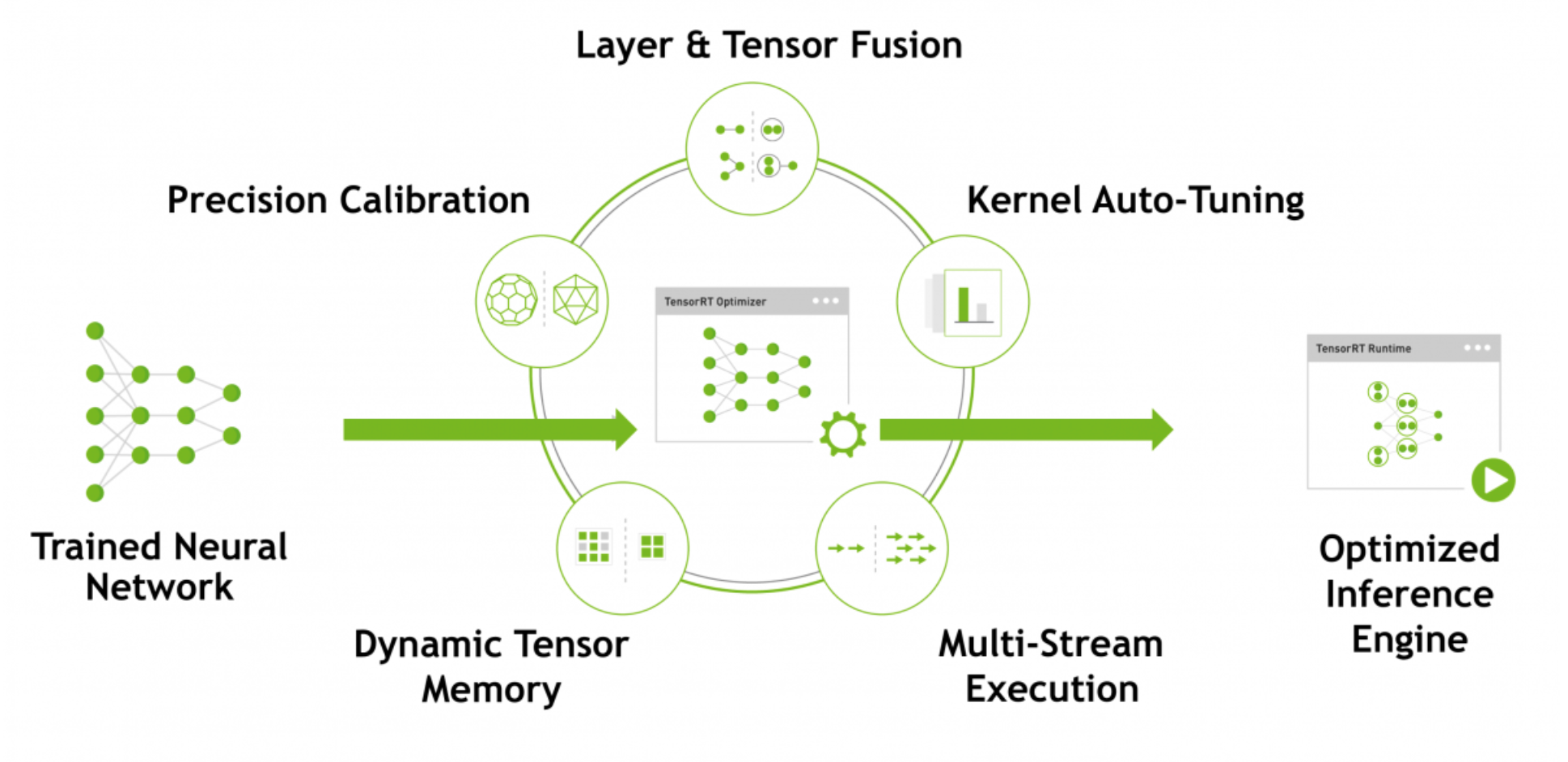
- 权重与激活精度校准:在保证准确率的情况下,通过将模型量化到INT8来更大限度地提高吞吐量
- 层与张量结合:通过结合内核中的节点,优化使用GPU内存和带宽
- 内核自动调整:基于目标GPU平台,选择最优数据层和算法
- 动态张量显存:最小化内存占用并且有效地重新使用张量内存
- 多数据流执行:并行处理多个输入流的扩展设计
TensorRT 工作原理
TensorRT包含两个阶段:编译build和部署deploy。
-
编译阶段对网络配置进行优化,并生成一个plan文件,用于通过深度神经网络计算前向传递。plan文件是一个优化的目标代码,可以序列化并且可存储在内存和硬盘中。
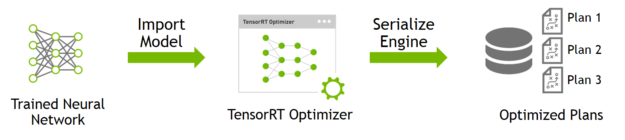
-
部署阶段通常采用长时间运行的服务或者用户应用程序的形式。它们接收批量输入数据,通过执行plan文件在输入数据上进行推理,并且返回批量的输出数据(分类、目标检测等)

为了优化你的推理模型,TensorRT将接受你的网络定义,执行优化,包括特定平台优化,并且生成一个推理引擎(inference engine)。这个过程被视作编译阶段(build phase)。编译计算可能耗费相当多的时间,尤其是在嵌入式平台中运行时。因此,一个典型的应用将会构建一个引擎,然后将其序列化为一个plan 文件,以供后续使用。(生成的plan文件并不能够跨平台/TensorRT版本移植)
编译阶段在图层中执行如下优化:
- 消除输出未被使用的层
- 消除等价于no-op的运算
- 卷积层,偏差和ReLu操作的融合
- 聚合具有足够相似参数和相同目标张量的操作(例如,Googlenet v5 inception 模型的1*1卷积)
- 通过直接将层输出定向到正确最终目的来合并concatenation 层
Python API
C++ API和Python API在支持开发者的需求方面非常接近。在任何性能是关键的场景中,和在安全性非常重要的情况下,C++应该被使用。Python API 的主要优点是可以使用Python的各种库文件对数据预处理和后处理。
将一个训练好的模型部署到TensorRT上的流程为:
- 从模型创建一个TensorRT网络定义
- 调用TensorRT生成器从网络创建一个优化的运行引擎
- 序列化和反序列化引,以便于运行时快速重新创建
- 向引擎提供数据以执行推断
Importing TensorRT Into Python
# 导入TensorRT
import tensorrt as trt
# 日志接口,TensorRT通过该接口报告错误、警告和信息性消息
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
Creating A Network Definition In Python
使用解析器(parser)导入一个模型,需要执行以下步骤:
- 创建TensorRT builder 和 network
- 为特定的格式创建TensorRT 解析器
- 使用解析器解析导入的模型并填充模型
import tensorrt as trt
# 以CaffeParse为例
datatype = trt.float32 # 定义数据类型
# 定义配置文件和参数模型路径
deploy_file = 'data/mnist/mnist.prototxt'
model_file = 'data/mnist/mnist.caffemodel'
# 创建builder, network 和 parser
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.CaffeParser() as parser:
model_tensors = parser.parse(deploy=deploy_file, model=model_file, network=network, dtype=datatype)
注: builder必须在network之前创建。不同的解析器有不同的机制标记网络输出。
Building An Engine In Python
builde的功能之一是通过搜索CUDA内核目录以获得可用的最快实现,因此有必要使用相同的GPU进行构建,就像优化引擎将在其上运行一样。
IBuilderConfig有很多属性,你可以设置这些属性来控制网络运行的精度,以及自动调整参数等等。其中一个特别重要的属性是
maximum workspace size
# 使用build对象建造engine
with trt.Builder(TRT_LOGGER) as builder, builder.create_builder_config() as config:
# 当构建一个优化引擎时,这决定了builder可用的内存量,通常应当设置为尽可能高
config.max_workspace_size = 1 << 20
with builder.build_engine(network, config) as engine:
Serializing A Model In Python
序列化,意味着将engine转化为一种可以存储的格式并且在以后可以进行推理。用于推理使用时,只需要简单地反序列化engine。序列化和反序列化都是可选的。由于从网络定义中创建一个engine是非常耗时的,通常序列化一次并且在推理时反序列化即可。因此,在构建engine之后,用户通常希望序列化它以供以后使用。
# 序列化模型到modelstream
serialized_engine = engine.serialize()
# 反序列化modelstream用于推理。反序列化需要创建runtime对象。
with trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(serialized_engine)
# 序列化engine并且写入一个file中
with open(“sample.engine”, “wb”) as f:
f.write(engine.serialize())
# 从文件中读取engine并且反序列化
with open(“sample.engine”, “rb”) as f, trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
Performing Inference In Python
# engine有一个输入binding_index=0和一个输出binding_index=1
h_input = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(0)), dtype=np.float32)
h_output = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(1)), dtype=np.float32)
# 为输入和输出分配内存
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
# 创建一个流在其中复制输入/输出并且运行推理
stream = cuda.Stream()
#创建一些空间来存储中间激活值。由于引擎包含网络定义和训练参数,因此需要额外的空间。它们被保存在执行上下文中。
with engine.create_execution_context() as context:
# 将输入数据转换到GPU上
cuda.memcpy_htod_async(d_input, h_input, stream)
# 运行推理
context.execute_async_v2(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)
# 从GPU上传输预测值
cuda.memcpy_dtoh_async(h_output, d_output, stream)
# 同步流
stream.synchronize()
# 返回主机输出
return h_output
examples
import pycuda.driver as cuda
import pycuda.autoinit
import tensorrt as trt
import common
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
# 分配主机和设备缓冲区,创建流
def allocate_buffers(engine):
h_input = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(0)), dtype=np.float32)
h_output = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(1)), dtype=np.float32)
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
stream = cuda.Stream()
return h_input, h_output, d_input, d_output, stream
def do_inference(context, h_input, h_output, d_input, d_output, stream):
cuda.memcpy_htod_async(d_input, h_input, stream)
context.execute_async_v2(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)
cuda.memcpy_dtoh_async(h_output, d_output, stream)
stream.synchronize()
def build_engine_caffe(model_file, deploy_file):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.CaffeParser() as parser:
builder.max_workspace_size = common.GiB(1)
model_tensors = parser.parse(deploy=deploy_file, model=model_file, network=network, dtype=trt.float32)
network.mark_output(model_tensors.find(ModelData.OUPUT_NAME))
return builder.build_cuda_engine(network)
def Load_normalized_test_case(test_image, pakelocked_buffer):
# 将输入图像转化为一个CHW numpy数组
def main():
caffe_model_file, caffe_deploy_file
with build_engine_caffe(caffe_model_file, caffe_deploy_file) as engine:
h_input, h_output, d_input, d_output, stream = allocate_buffers(engine)
with engine.create_execution_context() as context:
test_image
Load_normalized_test_case(test_image, h_input)
do_inference(context, h_input, h_output, d_input, d_output, stream)
Working With Mixed Precision Using The Python API
import tensorrt as trt
# 使用python设置层精度 Layer Precision
# 用precision指定层精度
layer.precision = trt.int8
# 设置输出张量数据类型与层实现一致
layer.set_output_type(out_tensor_index, trt.int8)
# builder强制准寻设置的精度
builder.strict_type_constraints = true
# 使用Python使得推理以FP16精度运行
builder.fp16_mode = True
# 通过设置builder标志强制16-bit精度
builder.strict_type_constraints = True
# 通过设置builder标志运行INT8精度模式
builder.int8_mode = True
# 使用Python设置每一层的动态范围
# 为了能够以INT8精度执行推理,必须为每一网络张量设置动态范围。可以使用各种方法导出动态范围值,包括量化感知训练或者仅仅简单地记录上一个训练epoch期间每个张量的最小和最大值
layer = network[layer_index]
tensor = layer.get_output(output_index)
tensor.dynamic_range = (min_float, max_float)
# 同样需要为网络输入设置动态范围
input_tensor = network.get_input(input_index)
input_tensor.dynamic_range = (min_float, max_float)
# INT8校准
# 和测试/验证文件相似,使用输入文件集合作为一个矫正文件数据集。确保校准文件能够代表整个推断数据文件。为了使得TensorRT能够使用校准文件,需要创建batchstream对象。一个bacthstream对象通常被用来配置校准器。
NUM_IMAGES_PER_BATCH = 5
batchstream = ImageBatchStream(NUM_IMAGES_PER_BATCH, calibration_files)
# 用输入节点名称和batch stream创建一个Int8_calibrator对象
Int8_calibrator = EntropyCalibrator(["input_node_name"], batchstream)
# 设置INT8模式和INT校准
config.set_flag(trt.BuilderFlag.INT8)
config.int8_calibrator = Int8_calibrator
# 使用Python API创建一个明确的精度网络,需要将EXPLICIT_PRECISION标志传送给builder
network_creation_flag = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_PRECISION)
self.network = self.builder.create_network(network_creation_flag)
其他
TensorRT 允许开发者可以import、calibrate、generate和deploy优化网络。网络可以直接从Caffe框架中imported,或者通过UFF/ONNX格式从其他框架中imported;网络也可以通过直接设置参数和权重实例化各层以编程地方式创建。
TensorRT为所有支持平台提供了C++实现,以及在x86、aarch64和ppc64le平台上提供Python支持。