作者公众号 大数据与AI杂谈 (TalkCheap),转载请标明出处
开始之前,先解释一下为什么深入和通俗这两个看似自相矛盾的词可以并列在这里。因为后续的一些文章可能也是类似的思路,所以先简单做一下文章定位的说明。要看正文的可以直接跳到下一章。
定位
定位上,这篇文章是面向有一定理工科基础,能理解一些基本的工程逻辑或理工常识,但非数学或算法相关专业或职能的同学。他们可能对相关系统,架构感兴趣,想要从基本原理的角度去理解它的核心思想,进而希望做到能有自己的观点和判断,有理有据,不人云亦云。
叫他通俗,是因为文章里我不打算详细阐述任何与公式,算法,代码,数学相关的内容(嗨,其实也是写不出来),而是希望用基本的常识或工程逻辑思维就能理解的的方式去解释相关的内容。
因为对算法工程师来说,不论是为了手撸代码,借鉴paper,还是更科学更有创造性的炼丹,从数学原理上透彻的了解整体计算逻辑,那显然是构建核心竞争力的必要条件。但对大部分非算法科学领域的技术工作者来说,这些往往不是目标而只是可能的手段。
此外,但凡学过一点机器学习算法的同学可能都会有这样的感觉,一件感官直觉上非常简单且合理的事情,一旦要用数学,概率,公式来严谨的推导的时候,可能就云里雾里了。即使花了很大精力去复习相关数学知识,看明白每个公式和推导过程,很可能过了一段时间又忘得一干二净了。
更重要的是,在这个过程中,你可能花了大量的精力去推敲和理解算法的细节,但对整个事情的基本运作原理却依然一头雾水,犹如管中窥豹,抓不到重点,知其然不知其所以然。甚至,在深度学习领域,有很多模型,本身就是细节是严谨的数学,而架构是炼丹式的“玄学”。如果不去理解玄学背后相对“朴素的直觉思想”的话,那就更是捡了芝麻丢了西瓜。
举个不恰当的比喻,就像托勒密时代的地心说,为了解释观察到的现象(比如行星逆行现象),各种本轮,均轮一圈套一圈,计算不可为不精巧,没有高深的数学功底,是不可能完整的理解整个地心说体系的。但事情的原貌,可能根本就不是这样的?

时至今天,任何一个普通人哪怕以日心说的视角来看待太阳系内的行星运动,都比托勒密时代的数学家更接近事情的本质,更有可能合理的解释行星的运行规律。
那么什么叫从原理上通俗的深入呢?
还是举刚才的例子,后来开普勒三大定律从数学上给出了行星运动行为的计算方式,但哪怕你搞定了椭圆积分,知道怎么计算相关公式,你能从根源上解释为什么行星的运动行为是这样的吗?开普勒不能。直到牛顿给出了万有引力定律,才从物理学的角度进一步解释和证明了开普勒定律。
而作为普通人大概只要知道,万有引力的大小与距离的平方成反比和质量的大小成正比这几个字,可能就可以在多数情况下做到原理上的“通俗深入理解”,能够大体揣摩各种物体运动的行为和背后的原因了。
至于如何应用万有引力公式,精确的计算行星的运动轨迹,如何精确计算物体运动的加速度,那都是通俗语义之外的“细节”了,多数情况下,我们把他留给准备考试的学生和天文物理学家就好了 ;)
当然,这个原理有多“深入”,也是有不同层面的理解的,好比引力本身又是什么,放到相对论体系中来解释,可能又已经脱离了“通俗”的层面,广义相对论最终把它归到质量对空间的扭曲,想要更好的理解引力,难免又回到高深的数学领域,至于引力是如何传播的,引力子是啥,它和时空扭曲的关系是啥,至今也只是未经证实的假想理论而已。对于想要有所突破的本职工作者来说,那数学当然还是逃不过去的。
闲话说完,开始正篇。
(另,文中大量图片皆引用自论文或其它相关文章,版权归原文所有。)
SORA是什么
Sora是什么,相信刷屏了这么久,大家应该都不陌生。Sora是一个视频生成模型,能够根据简单的文本或图像提示,输出长达一分钟左右的视频。
咋一看,你可能会觉得,这好像也没啥。毕竟自打一年多前的图像生成领域,MidJourney,DALL-E和Stable Diffussion为代表的产品将图像AIGC能力提高到商用的水平以后,大家对AI在图像创作能力方面的心理预期,也拔高了很多,而视频不外乎就是连续运动的图像嘛,时间长点,不就是计算量大一些呗。
那么Sora为什么一经推出,都还未经大范围推广试用,就能迅速且持续的刷屏,甚至有人称之为AIGC领域的又一次革命性的突破,还有大佬喊出原以为通用人工智能实现需要十年,现在看只要一两年的话语呢?(不过,我个人谨慎的表示不认同这个一惊一乍的看法)
主要还是从OpenAI官网放出的Sora生成的demo视频来看,质量太过惊人了,几乎能够以假乱真。过往的一些视频生成产品,比如pika,runway之类的,大多都只能生成几秒的短视频,生成质量也很一般,比如视频里的图像内容不稳定,不连贯,画面闪烁,无法控制生成结果,随机性过高等等,总之一眼AI视频,因此基本都不太具备实用价值,只能作为玩具玩玩尝尝鲜。而Sora的视频如此逼真,以至于网上甚至有用真视频反向假装是Sora生成的AI视频的。。。
那么要生成真实可信的视频有多难呢?与静止的图像不同,视频对其图像内容的呈现通常是多角度,运动变化的,因此不可避免的会涉及到对客观物理世界的物体的三维透视,旋转,变形,以及多个物体相互交互后产生的各种物理运动行为的呈现。
所以,从视频生成的角度来说,如果需要让生成的视频足够逼真,一种可行的方式,就是能够根据一些基本物理规律,对物理世界的物体呈现和运动行为进行模拟。大多数的三维建模软件,游戏引擎就是这么做的,只不过,具体的呈现形式和物理规律,是由人通过编程和算法来实现的。
而普遍认为真正的通用AGI,就是需要具备自主的对物理世界进行模拟的能力,也就是具备建立“世界模型”认知的能力。而Sora所生成的视频效果如此之好,就让不少人惊呼,这怕就是模拟物理世界的前奏,是世界模型能力“涌现”的表现吧。
你看就连OpenAI自己在官网发布的Sora技术文章所用的标题,都是:Video generation models as world simulators:一种作为世界模拟器的视频生成模型。文章从根源上想要强调和探讨的就不是Sora所生成的美女有多么的逼真,而是在讨论一条建立物理世界通用模拟器的有潜力的路径 (a promising path towards building general purpose simulators of the physical world.)
当然,我认为,这个标题多少是有些商业炒作的味道的,我个人是不认为Sora具备对物理世界的认知能力的。就像我不认为LLM大语言模型具备逻辑推理能力一样。不论其表现得有多么像,其本质还是一个概率层面的模拟呈现。OpenAI的同学们当然也不傻,但作为本职工作,梦想还是要有的,万一是真的呢 ;)

那么Sora的整体技术框架到底是什么样的,它和之前的技术到底有什么区别呢,为什么他能做到如此惊人的“物理世界模拟能力”呢?接下来我们来通俗深入的理解一下。
先理解图像扩散模型
因为Sora的核心是一个用Transformer模型局部改造过的Diffusion图像扩散模型,所以让我们先从什么是Diffusion扩散模型说起。了解了图像扩散模型的基本工作原理,基本上就了解了大半个Sora的工作原理
Diffusion扩散模型就是之前Mid Journey和Stable Diffusion等图像AIGC产品的核心算法模型。
扩散模型生成图像的基本流程可能和大多数人对图像生成流程的直觉想象不同,他并不像普通绘图或3D建模软件,是从空白的画面逐渐添加或者细化绘制像素来生成图像的。实际上,正相反,它是从一张随机生产的填满了噪点的图像开始,逐渐去除噪点来还原(生成)图像的。
这个过程,不严谨的举个例子,就好像你家小朋友拿出一张用蜡笔涂鸦涂满的纸,然后用橡皮擦,擦着擦着就擦出一幅画来了。。
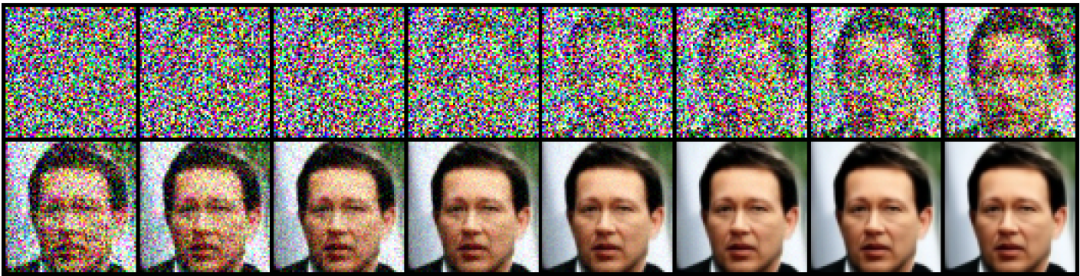
如果这个过程的逻辑合理性不好理解,那可以先把这个流程反过来看,你可以从一张图像开始,逐步添加越来越多的随机噪点(一般是符合高斯分布的噪声,为什么是高斯噪声呢,不用深究,大体上是统计规律上为了满足一些后续数学概率推演和计算的便利性的需要),最终获得一张完全随机的噪点图像。(这也是这个模型为什么叫做扩散模型的原因,当然严谨的说,叫他渐进模型可能更合适)
而图像生成(还原)的过程就是上述流程的逆过程。理论上来说,我们如果知道一张图片是如何一步一步的被添加噪音的,那么我们按照相反的顺序去除这些噪音,也就能还原原始的图像了。
但问题是,你怎么知道添加的噪点数据是什么呢?毕竟,我们的目标是图像生成,在图像生成的应用场景下,原始图像是什么我压根都不知道(我本来就是要靠你来生成呀),我们其实也根本就没有走过这样一个添加噪声的流程,我要怎么知道这子虚乌有的加噪过程添加的噪点数据是啥呢。
答案是,我们可以训练一个深度学习网络模型,根据过往其它图片的加噪过程来“猜”。。。
怎么训练呢,简单来说,训练的过程就是我先拿一张图像数据来,按照一定的步骤添加噪声,然后呢,我把添加完噪声的图像数据作为输入,给到一个我们计划用来去除噪声用的网络模型(比如图中的UNET),让这个模型通过一番的计算,输出他算出来(猜出来)的噪声数据。
然后我们不是知道我们添加的真实噪声是什么吗?那就好办了,我们可以把模型预测出来的噪声数据和我们实际添加的噪声数据做对比,去计算网络预测的偏差值,最后根据这个偏差值再去校正网络模型的参数,如此反复迭代,最后希望这个网络模型能够尽可能准确的从添加了噪点的图像中,预测出噪点数据来。
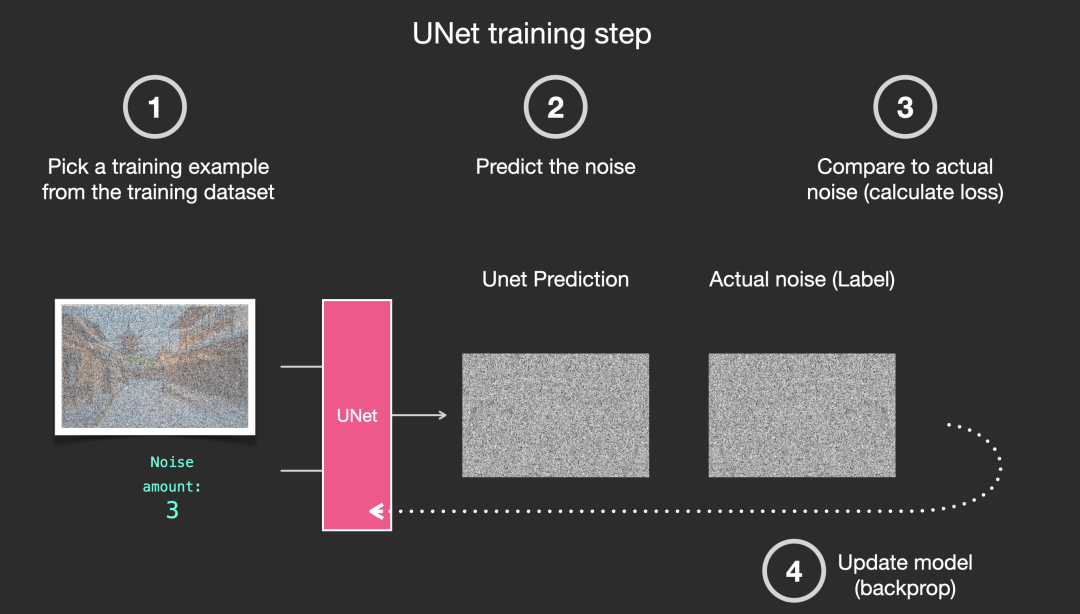
具体网络是怎么训练的,模型的参数是怎么矫正和迭代的,你不想关心细节也没关系,就是常见的神经网络正向传播,反向传播,梯度下降,优化损失函数之类的流程。
总之,当这个网络模型训练好以后,我们就可以把一幅随机生成的噪点图像输入到这个模型中,让他预测噪点是什么,预测出来噪点以后,如上文所说,我们按照相反的顺序从这个随机生成的高斯分布噪点图像中,一步一步去除这些噪点,最后就得到我们想生成的图像了。
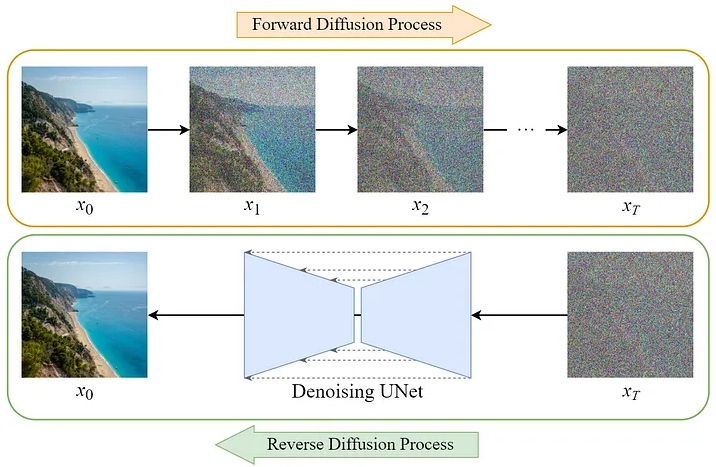
这个流程,看似简明,但如果你仔细看了,你可能会觉得这里面有几个疑问
首先,我干嘛要从添加了噪点的图像中预测噪点呢?我不能直接预测图像吗?说来你可能不信,这是因为噪点更容易预测(我们前面说了,他是一个满足高斯分布的噪点,相比千变万化的图像,噪点其实更有规律,用均方差和均值就能表示了),计算过程会更简单,模型也更容易被训练出来。OK,姑且相信这一点。
那为什么要分好几步来预测噪点数据呢?那是因为这样预测的难度小一些。你想,如果直接从一个完全随机的噪点中直接一步还原出最终清晰的图像,直觉上是不是就会觉得这有点强人所难呢?相比比如分一千步(是的,基础模型的理论假设基础是一千步,当然,后面有各种算法改进),循序渐进的添加噪点(训练),和去除噪点,每一步图像之间的差异小很多,训练和预测的难度显然就小多了。
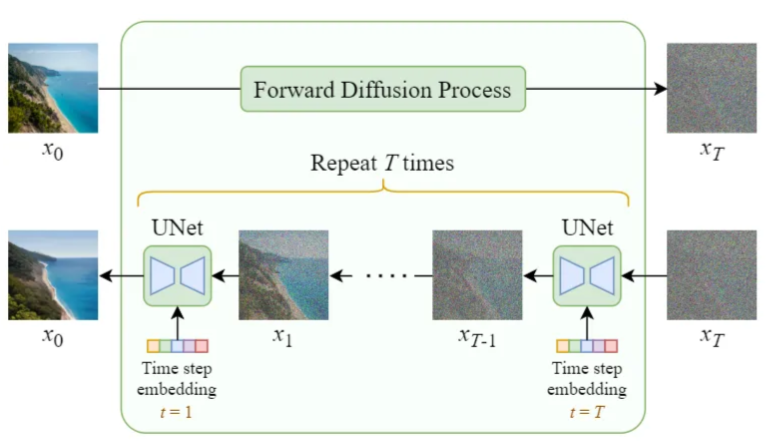
细心的同学可能还会接着问,那去噪用的网络模型是怎么知道当前给定的带噪点的图像,对应的是第几步的噪点数据呢?我不可能直接看噪点图像就知道我应该算第几步吧?还是说,对每一步的噪点数据,都要训练不同的网络模型来分别处理呢?
答案是不用训练不同网络模型,用的是同一个网络模型(即网络参数),但在训练和推理的过程中,需要从迭代流程上控制一下,输入一些迭代步骤相关的信息。
具体来说,就是在训练的过程中,输入给模型的噪点图像数据,都会叠加上一个代表时间步骤(Time Step)的数据(没有固定的做法,但通常是将迭代T的数值带入一组特定的sin cos函数算出来的向量,以满足各种数学便利性特性),所以模型在训练过程中,是同时结合了图像噪声数据和时间步骤数据进行学习的。在后续图像生成步骤中,同样使用相同的算法叠加时间迭代步骤的数据进行噪点预测就好了。
你可能会问,这图像数据为什么就能和你随便就定义出来的一个时间步骤向量数据叠加呢?这两者完全就是风马牛不相关的内容啊,叠加完的内容,其物理涵义是什么呢?
怎么说呢,个人认为这就是科学炼丹中偏玄学的部分,非要类比的话,可以类比一下各种数字信号的调制解调编码,你不用关心原始的信息信号和编码用的载波信号是否相关,说到底,这都是数据的载体,只要他们能组合出有区分度的信号,事后能够再还原出来被编码的型号就可以了。是的,要不怎么说这是数学呢 ;)
实际工程训练中,并不需要一步一步叠加噪声,因为有了时间信息的嵌入,对于任何一个时间步骤的噪点图像,模型都是平等看待的,所以训练的实际过程是随机选取一个时间步骤T,然后预测这个步骤下的噪声是什么,这样做的好处是引入更多的随机性,从而让模型具备更好的泛化效果。当然,图像生成的过程还是需要完整的走完整个逐步去噪的过程的。
看到这,你可能还会嘀咕,我需要的是从文本生成图像,你这前面说的都是图像去除噪声,那这文本信息体现在哪呢?它和去除噪声又有什么关系呢?
遇事不决加数据。没错,和处理时间Step信息类似,只要在训练的时候把对图像进行描述的文本信息一起塞给模型,然后指望模型能学到这些文本信息和噪声之间的关系就好了。
和添加时长信息不一样的是,这里的文本信息,通常和图像信息是一个并集关系,而不是加法叠加关系。也就是说文本信息的数据并没有直接和图像信息混合到一起去,而是作为并集,拓宽了数据的维度(宽度),这听起来就合理多了不是。
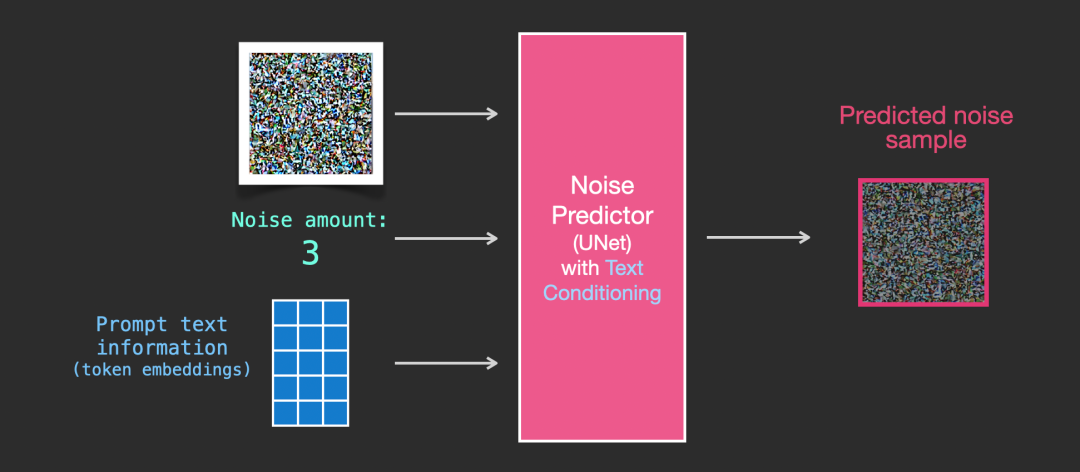
需要注意的是,这些文本信息是经过向量化嵌入处理的信息,而非原始文本信息,毕竟,矩阵计算需要确定长度的向量数据,而图像的文本描述信息可能长度不一(当然,这并不是Embeding的唯一甚至主要原因),向量化Embedding处理以后能够统一数据格式,也便于后续运算。
图生图的流程与此类似,只不过附加的信息不是提示文本的向量,而是参考图像经过特定编码以后输出的向量。这些附加的文本或参考图像向量数据,在图像扩散模型结构中,一般被叫做condition,也就是附加的条件信息。
这里用来对文本和图像编码生成embedding向量,用作condition条件输入的,通常是一个叫做CLIP的模型,这个模型的具体原理,我们后面再说。
到此为止,就是图像扩散模型粗略的框架流程和原理了。
简单来说,我们就是定个宏观的,大的思路和方向,把脚手架搭好,然后把各种周边信息都编码到数据中去,接下来就交给深度学习网络自己去“深度学习”,填充具体的内容就好了。大力出奇迹,怎么出的我不管,大力是关键。
实际应用过程中,上面的流程有一个比较大的问题,就是计算量太大了。因为这个模型中,不管是模型训练还是图像生成,都需要一个循环迭代的去噪过程。而大力出奇迹的重点在于,要训练过足够多的图像数据。这时候如果单张图片需要的计算量太大就不好弄了。
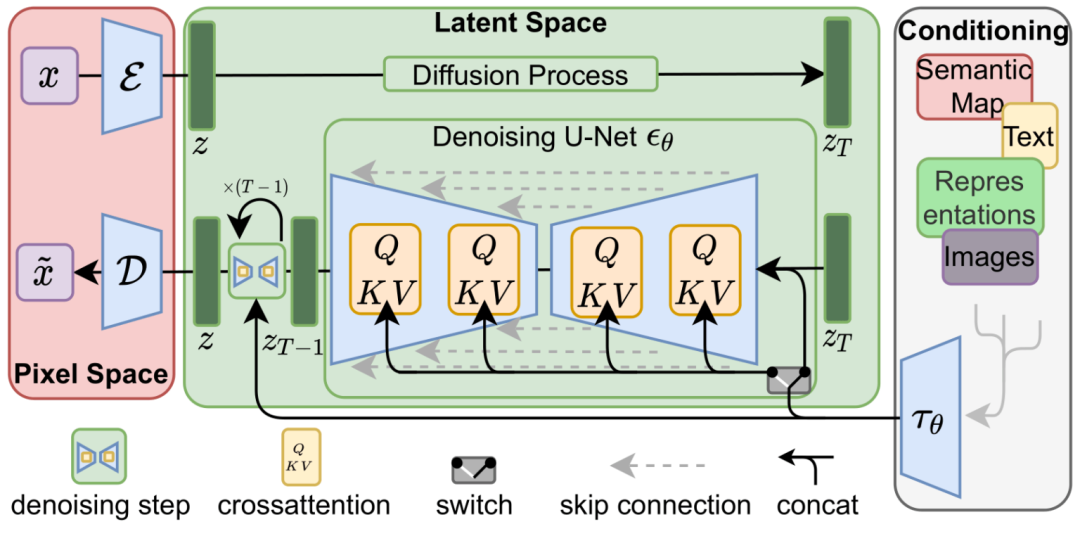
所以,如果拿Stable Diffusion的流程架构图看一下,就会发现,实际上前面所说的对噪音图像的训练和预测的过程,都不是直接在原始的图像像素的语义上操作的,而是经过了一次编码映射,在所谓的Latent Space潜空间里操作的。最后的图像还要从去完噪点的潜空间数据中再次解码反向映射出来。
为什么要经过编码转到潜空间呢?其实也没有什么玄妙的原因,主要就是为了压缩图像待处理的数据量,比如,将图像数据的表达形式,从256x256的维度,压缩成32x32的维度(这里是简化的说法,实际上因为不同的RGB颜色通道和后续卷积通道的设置,可能是从256x256x3的数据压缩成32x32x4的数据),压缩完数据量小了64倍,那算起来自然就快多了,也就能用相同的时间和金钱成本去学习和训练更多的图像,从而获得更好的训练效果。(当然,什么去除高频信息啊,保留关键特性啊,也是一种解释,但我理解都不是关键)
看到这,你可能会想,好嘛,前面告诉我说,根据图像像素我能猜测噪点,根据文本信息,我能关联文本可能的图像,这都好理解,我不管你是怎么训练出来的,至少听起来符合逻辑。结果,你现在操作的压根就不是图像像素了,而是某种编码映射转换后的数据,那前面所说的噪点,文本信息和图像本身还有什么物理意义上的关联关系吗?
没错,一番操作以后,物理可解释性是越来越牵强了,但不影响这么做的效果,这就是数学嘛 ;)如前所述,你就理解处理得当的话,这些各种形式的编码,可以不破坏数据之间(像素之间,图像和文本之间)的内在分布特征关系。无论这个分布和关联关系是用原始像素数据表达的,还是用编码过的潜空间向量表达的。我们只要能高效准确的建立起对应的模型就好了,可解释性向来不是深度学习网络的强项。
那么从像素空间到潜空间的编解码过程,具体怎么编解码呢?要做到不破坏数据之间的内在分布特征关系,应该不是随便就能搞定的吧,是不是也需要个训练个什么模型呢?你说对了,这里一般采用一个叫VAE的模型来做编解码映射工作,这个VAE模型的原理,我们也放在后面再说。
SORA的架构原理
好了,前面说完图像扩散模型为代表的图像生成技术的基本流程和袁立思想了,那么Sora作为一个视频生成产品,是不是就用同样的方式连续生成几张图片然后串联成视频就完事了呢?
是,也不是。
一方面,的确有很多基于SD的图像生成模型来处理视频的产品,但另一方面此前的这类产品往往效果都不是太好。
其中一种思路,是把视频的每一帧拿出来作为参考图像,按照输入文本的描述,生成新的图像,然后把新的图像串联起来,变成一个新的视频。这种方式大体常见用在一些图像风格转换,换衣服,换脸之类的场景。需要依靠原视频来作为参考,大体是因为从文本到图像的输出,既然是一个概率去噪的过程,那图像内容和效果就很难精确控制,所以视频的连续性大体是靠原视频的内容来保证的,但即便如此,这类转换视频通常也往往是大体轮廓和原视频相同,视频本身的图像细节的连续性还是很难保证。
当然也有不是视频转换,而是直接生成视频的,但此前如pika,runway等的产品,大体都只能生成较短的视频,视频里的内容很多情况下主体(比如人)也不会做大幅度的运动,通常是通过比如镜头缩放,视角轻微横移,旋转之类的方式来呈现视频的运动效果。
说到底,这是因为对运动的物体,需要保持图像内容在多帧图像之间的一致性以及运动过程中视角变化后内容的合理性。这就不是通过学习独立静止的图像就能训练出来的了。
所以,如果要做视频生成,在模型的训练过程中,就不单单要学习单帧图像中像素之间的空间关系,还需要学习不同图像帧之间的内容在时间轴上的变化关系。
这么粗浅的道理当然谁都知道,只不过要训练视频,按照过往的模型,一方面其训练的难度和计算量相比静止图像是呈数量级的规模增长的,另一方面原有的模型结构能否从视频内容中很好的承载或学习到长距离的上下文一致性相关知识也不好说。
Sora的基本框架思路
那么Sora是如何做到的呢,还是先来看看它的整体框架。Sora的核心架构,简单来说就是:一个能高效灵活的处理不同视频分辨率尺寸的Diffusion Transformer预训练模型。
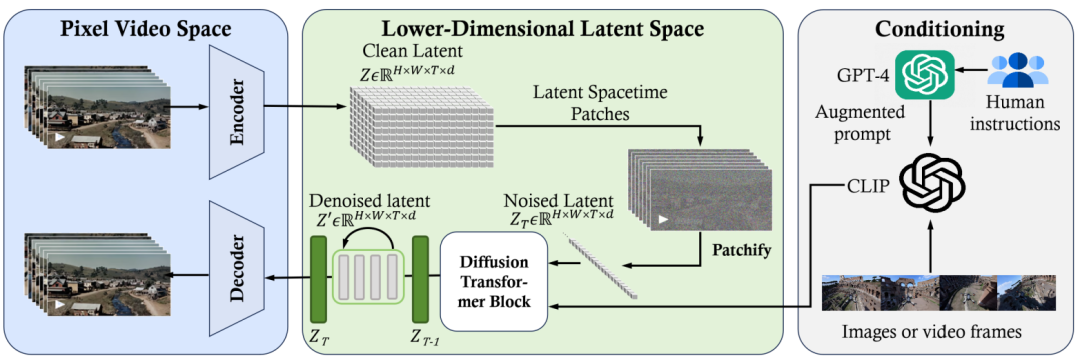
这个框图和前面Stable Diffusion的架构框图非常像,其中对模型结构最大的改动,就是用大语言模型中常用的Transformer网络结构,替换了原来的UNET网络结构。整体的生成逻辑,仍然保留了扩散模型从随机噪点图像数据逐步去噪得到清新图像的过程,只不过,这里的图像不是单幅图像,而是连续的多幅图像帧。

为什么要替换UNET网络呢?大体是因为Transformer的网络结构,相比于UNET来说,由于其Attention的机制的原因,通常认为更加擅长识别和学习长距离的内容之间的相关性,这一点在大语言模型的文本输出方面已经有很好的表现。那么,用在视频领域,就很有可能能更好的保证视频内容在较长时间轴范围内的一致性和连贯性。
那为什么Transformer的网络结构会被认为更加擅长长距离的内容相关性的学习呢,我们可以简单来看一下两者的架构和原理。
UNET
图像扩散模型中经典的UNET网络,大体是如下图这样一个网络结构(这是论文里的,实际SD应用中的网络结构要更复杂一些)
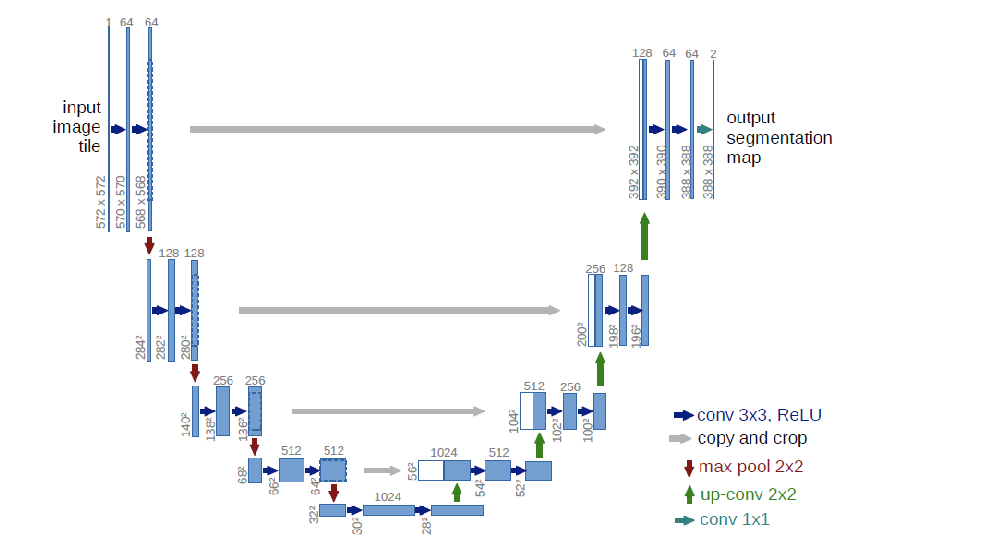
简单来说呢,从计算逻辑上来讲,UNET就是构造了一系列的卷积网络层,左边(U的前半部分),是一个不断把图像进行卷积计算然后降维(压缩)的操作,右边(U的后半部分)则是一个结合前面的输出,进行反向卷积升维(解压)的过程。
那么什么是卷积呢?说白了,就是拿一个权重模版(比如3x3)在图像上不断平移去计算模版下面的图像像素数值的加权汇总值。
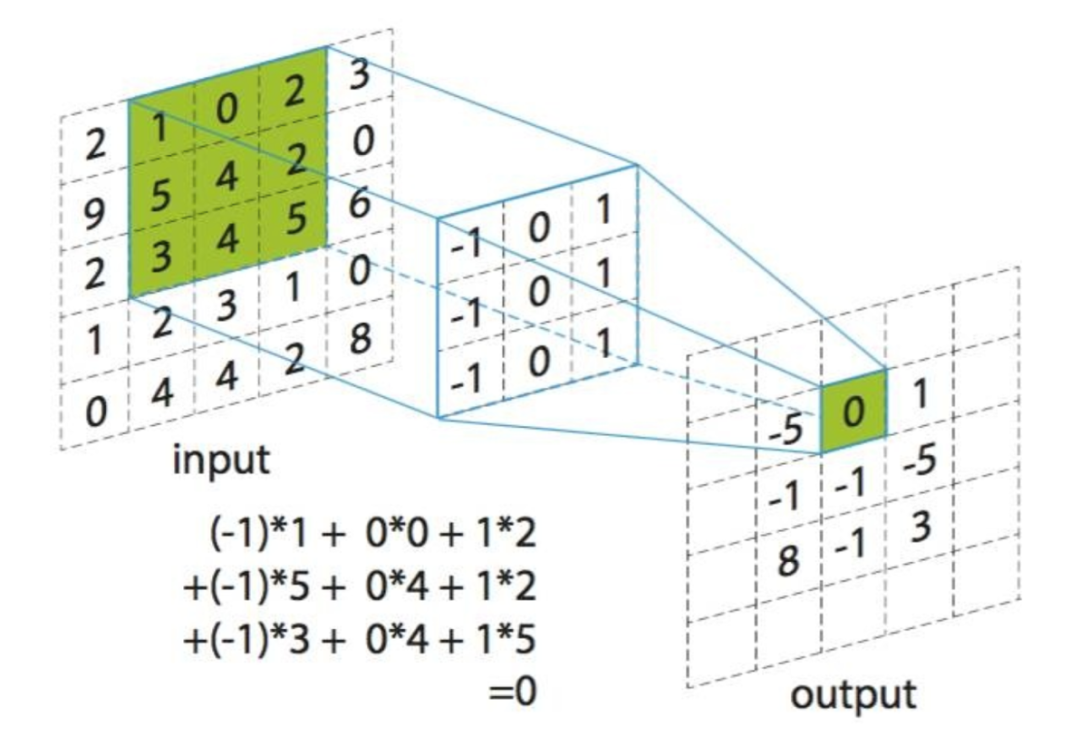
很久以前,学过一点传统的图像处理或信号处理课程的同学,对下面这个妹子应该都不陌生,反正就是上各种矩阵运算去加工原始数据来试图提取一些特征信息

UNET的基本实现思路,就是构建好多层的卷积网络,来不断提取特征和重建特征,通常的说法是
左半部分是特征提取网络(编码器),输入图像通过卷积和下采样,获得不同层级的特征。
右半部分是特征融合网络(解码器),各层级特征经过反卷积进行特征融合。
从物理含义上来说,因为卷积运算的模版权值的不同,可能有不同的作用,比如均值模糊,差值提取边沿等等。但一幅图像卷积好几次以后,每一层的操作,还能和具体的什么物理含义对应上吗?别问,问就是深层特征,至于这个深层特征到底是啥,这又回到玄学了。既然是玄学,那这个卷积模版权值通常也不是人为设定的就很好理解了,反正就是设置一个随机值,然后各种迭代传播梯度下降让模型自己“训练”出来呗。
其实,深度学习体系中的各种网络结构设计,说白了,不少都是直觉常识(或者说洞察),数学原理(概率)和网络结构玄学(物理含义?)几者之间的各种组合试错,否则也不可能有这么多的paper不是 ;)
UNET在各种图像处理算法和模型中之所以能得到广泛的应用,主要还是在于整体的思路非常简单直白,实现也相对容易,计算量同样可控,在很多场景下,效果也还不错(比如最早应用在医学图像分割的场景中)。
但说到底,整个UNET网络模型的基本思想就是不断的对周边临近数值做加权运算(当然,还有一些激活层做非线性化处理,一些全连接层做长距离关联等,这些我们在这里就不深究了)。结构并不复杂,所以能力上限在哪里,大家总是会打个问号的。
Transformer模型
再来看看Transformer,它的网络结构如图,这张图对不是搞算法的同学来说,估计看了也没啥用,放这张图的目的,就是你主要知道一下,里面的核心网络结构,有一个叫Multi-Head Attention的模块就好了。
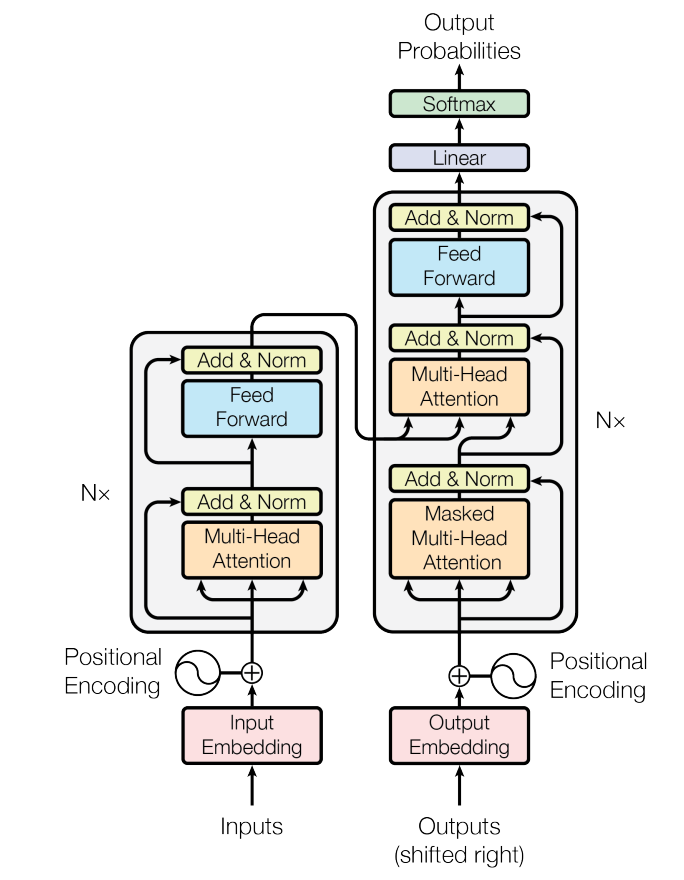
这个模块也是一个矩阵运算的模块,但它的算法与卷积网络的算法的区别在于,他不是一个简单的相邻数值的模版加权计算过程。他是一个索引和位置关联的权重计算过程。按照论文的说法,就是对每个数值(token)构建了Q(query),K(key),V(Value)三个向量参数,用这三个向量来计算每个token和其它token的关联度和影响值。当然,实际计算过程是把所有token的这三个向量构建成矩阵来做批量并行计算的。
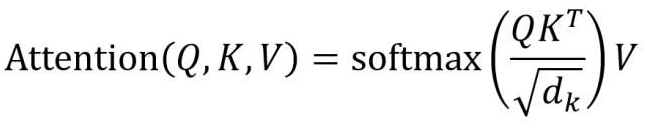
看不懂没关系,简单来说,就是这种计算方式,是对每个token构建了它与其它所有token之间的关联关系和权重,而不是像卷积计算那样,构建的是与周边相邻少数几个数值之间的关系,所以,直觉上,这对与实现文本理解和生成场景中,长距离的语义关联,上下文语义context,逻辑的一致性,连贯性等就很有效了。
既然前面也说了,处理视频的时序图像,长距离的逻辑一致性和连贯性是关键难点,那么,采用Transformer网络模型替换UNET这种简单的网络模型听起来就顺理成章了,感觉应该能更好的提取视频的时空信息,非常合理不是。
既然如此,那么之前为啥不早这么做呢?其实也不是没有,只是还没有人大规模跑成功,没有成为潮流而已。
那么,用Transformer网络模型替代UNET网络模型的难点在哪呢?难点主要还是在计算量上,卷积模块只处理周边的少量数据,而Attention模块是要处理所有数据(Token)之间的两两关系的。这就导致计算复杂度和Token总数的平方成正比了,而视频作为一个三维数据,其数据的总量又是和分辨率的平方以及时长的乘积成正比关系的。那总体计算量相对于视频的大小就是一个六次方的比例关系了。
Sora做的事情,就是在工程上结合了过往的一些论文和技术方案来解决计算量的问题,使得处理海量的视频数据成为可能,在解决了工程计算量的问题以后,经过海量视频数据的暴力学习,达到了现在的视频生成效果。
那具体是哪些技术方案呢?简单来说,大体就是对视频进行一些名为“Patch”的切割和一些动态Token采样编排编码相关技术,虽然没有非常创新的思想,但做了各种技术方案的大规模工程化实现和融合。
Patch这个词,不少自媒体把它YY成一个智能的包含了特定图像元素的多边形时空系列块什么的,宣称有了这个Patch,视频图像的元素就能随意自由用不同的patch组合编辑云云。
其实根本就没有那么玄乎,从根源上来说,Patch只是为了解决计算量的问题的。什么是Patch呢,简单说就是把图像切割成小的图块(通常是正方形的),把每个图块编码成一个Patch(对应的放到Transformer模块中,这个patch实际就是当作Token来对待使用),然后用Transformer模型来训练和学习Patch之间的关系,推导下一个patch。
为什么要这么做呢,并不是这个Patch有多么神奇的图像元素表征的作用,只是这么做,相比于把每个像素都作为一个Token来输入到Transformer模型中进行训练的方案,Token的数量大大的降低了,从而计算量也就大大的减少了。(其实和卷积模版只需要计算周边少量数据有异曲同工的地方)
比如,如果一个二维图像的Patch的尺寸是16x16,那么相比直接用像素做Token,用Patch作Token的数量就少了256倍,由于Transformer Attention模块的计算量和Token数量的平方成正比,相应的,计算量就降低了256x256=65536倍。
当然,这里的Patch也不是在像素空间里切割的,同样是在经过类似VAE的编码压缩转换后的潜空间的数据中进行切割的,其切割的尺寸可能也不是16x16,可能小到2x2(原始论文中,这样的效果是最好的),很显然,这么小的尺寸,根本就表达不了什么完整的图形元素语义。
所以Patch在物理含义上和所谓图像语义元素的抽取,基本上没有一毛钱的关系,纯粹是一个数据工程化压缩降维处理的手段。
具体落到工程实现层面,如何把视频数据切割成patch,如何排列,如何用Transformer模型来处理这些patch还是有各种方案需要考量设计的

比如可以简单的把每一帧的图像数据切割成二维的图像后,顺序排列。
或者把几帧图像数据在时间和空间轴上同时切割,输出一个三维的数据块,把每一个三维的数据块转换成一个patch。而这三维的数据块怎么打平成一个二维数据呢,比如取均值,简单叠加,或者上个卷积模版做加权计算,又甚至像论文中一样,简单粗暴的扔掉其它帧,只保留中间那一帧的数据就好了
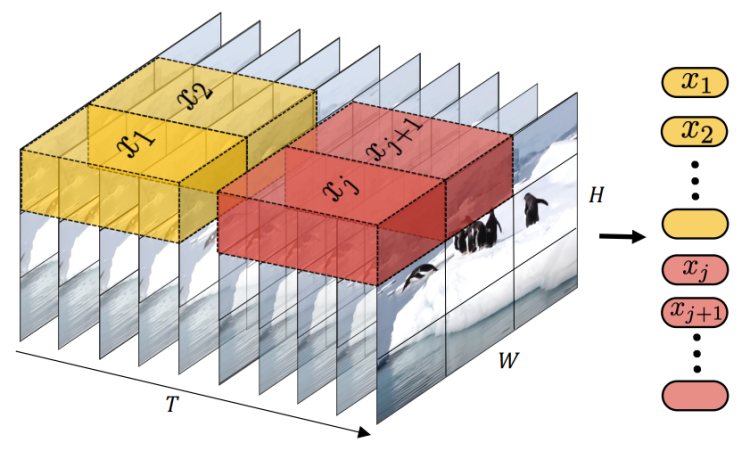
最后,在训练过程中,还可以随机或者按照特定的方式(比如近似数据去重之类)再丢掉一些Patch数据块,名义上是增加模型抗干扰能力,避免过拟合,增强泛化能力,但实际上很重要的目的之一,也是为了为了进一步减少数据量,降低训练代价,这么说起来,一举两得不是。
当然,能够丢弃一些patch,包括Sora能处理不同分辨率的图像的原因,大体还是因为Attention的计算逻辑机制,不是固定的卷积运算,而是一个两两相关检索计算的过程,所以对数据的完整性和顺序性不那么敏感,缺失的数据只要不计算就完事了(当然,实现上算法是需要做一些特定的改造的)
简单总结一下,上述Patchify的过程和各种工程优化手段,降低了在Diffusion扩散模型中使用Transformer模块替换UNET模块带来的计算量增长问题,使得大规模训练视频数据成为可能。从而使得视频生成模型能够延续语言模型大力出奇迹的路线,经过海量视频数据训练学习后,“涌现”出一些“理解”物理世界的能力特性。
以上就是Sora的大体原理和思路。
一些补充讨论
前面的内容中,为了简单起见,不节外生枝,所以还有一些部分没有“深入”讨论,这里做一些补充。当然这种补充“深入”一定程度上来说是没有尽头的,所以仅挑几个重点阐述一下。
图像和视频编辑
前面说到,我个人理解,Patch没有什么特别的图像语义内涵,就是一种工程优化手段。你可能会问,那明明Demo视频中,Sora可以替换视频中的对象,甚至融合不同视频的内容啊,这不是通过操纵Patch得到的吗?官方自己都说了,可以通过在指定画幅图像空间中 Arrange Patch来生成视频内容啊。
你说得对,Sora是可以通过操纵patch来控制图像内容,这也是有些自媒体说Sora能够抽取各种图像语义,然后自由组合视频内容的原因来源。
但这本身并不代表切割的patch具备什么特定的语义内涵,事实上,不止Sora,在SD图像扩散模型中早就就有很多方式能够以某种方式操纵图像的内容生成,比如各种SDEdit技术。
实际上,SDEdit之类的思路,大体上还是利用了扩散模型中,训练完的模型对噪点数据的预测的概率特性。模型参数确定了,只要输入数据相同,计算的过程不管正向加噪声还是逆向去除噪声,计算结果相对来说是确定的,可逆的。
所以一般的图像操控的实现方式,大体都是在一幅随机噪点图像中,按一定的比例加权混合入一个用作参考的指定图像(或局部图像)经过正向添加噪声步骤以后产生的数据。用这种噪点数据混合的方式,来影响反向去噪的过程中最后生成的图像结果。
举个例子,如果我把一个苹果的图像正向叠加噪声的数据给到模型去做反向去噪,那自然就会还原出一个苹果来。那么现在在一个给定了草地作为提示词输入的图像生成的过程中,我们原本是从一个完全随机的噪声图像中开始去噪,现在我在图像去噪的过程中,不再使用完全随机的噪声图像,而是把其中一部分数据替换成前面苹果的噪声数据,那么经过去噪流程以后,是不是就在草地的图像中加上了这个苹果的图像呢?
当然,这是从原理上简单这么说。实际的计算过程,要实现最终输出效果的自然和合理,除了模型的可采样连续性是前提以外(这也是各种模型结构,激活函数,泛化等流程想要保证的),在什么时候添加指定元素的噪声,如何获取这些指定元素的噪声,添加多少,什么时候开始添加,什么时候结束添加,如何混合噪点数据,如何保证混合的元素和周边元素的内容连续性,都是需要考虑的工程问题。同样,也因此衍生出各种奇妙的上层应用呈现方式。
但总体来说,图像或视频的编辑过程,基本就是一个正反向噪点数据混合的过程,单个patch本身作为少量数据的载体,并不具备任何图像语义。就像你可以把一篇文章中的一段话搬到另一篇文章中去,但你并不能因此就说这里面每个单个的字母(或者中文的笔画)就包含了什么特殊的语义。只有这些个体按一定方式组合起来成为一个整体,才有意义。
CLIP
在完整的SD模型中,我们说到用作文生图或图生图的embedding向量,一般是通过一个叫做CLIP的模型生成的,那这个Clip模型为啥能够编码图像和文本呢?编码出来的图像和文本数据,他们的相关性是怎么建立的呢?凭什么这段文本的编码和另一幅图像的编码都能指代比如苹果这个语义,最后还能够引导生成出苹果的画面呢?
我们做一下简单的原理说明
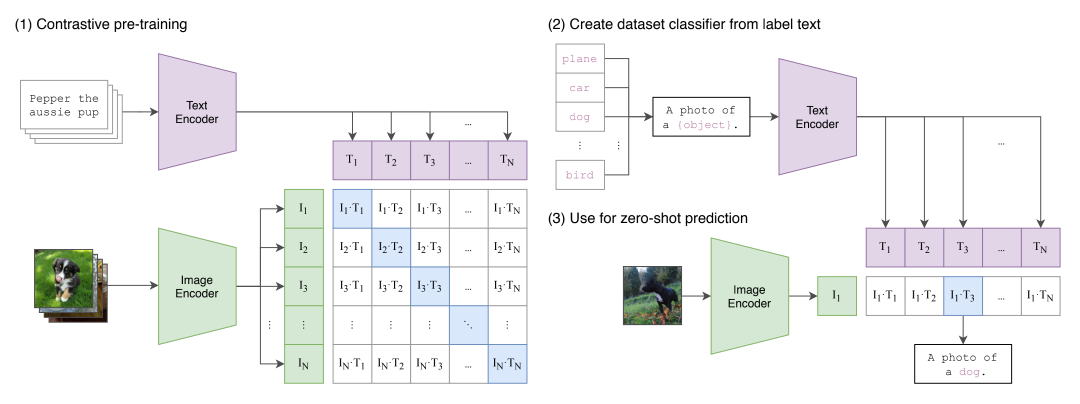
CLIP模型,原本是用作图像分类的。主要由一个文本编码模块(类Bert)和一个图像编码模块(类Transformer)构成。
他的基本思想,不是作问答题,比如给定文本生成图像,或者反过来给定图像生成文本(否则不就变成鸡生蛋蛋生鸡的问题了吗)。而是从概率匹配的角度做选择题。也就是只回答指定文本和指定图像的相似性有多大,有没有匹配关系。选择题相比问答题,那当然就简单许多了。
具体的流程,就是把文本编码模块生成的向量,和图像编码模块生成的向量去做一个相似性计算,相似性最大的就认为相互匹配。
所以训练的过程,就是把大量(比如4亿对)已知配对的图像和文本描述对作为样本给到模型去进行迭代训练,直到模型计算出来的文本和图像对的匹配关系和实际已知的配对关系的误差尽可能小为止。
那么,这样生成的文本向量或图像向量本身代表了什么物理含义呢?不知道,可能并没有什么含义,但这不重要,只要这些编码后的向量,相互之间建立了正确的空间相似性分布关系,并具备足够的泛化能力就好了。
接下来,在SD模型训练的过程引入的这些向量作为控制变量以后,在生成过程中,因为向量的空间相关性和可采样的泛化能力,你就能指望你输入的文本或图像也能作为控制变量,引导SD生成出语义相关的图像了。甚至,因为这个过程具备连续可采样的能力,让你能够生成一些不在原训练数据集中的组合语义的图像。而这,就是艺术所追求的天马行空的创新啊 ;)
VAE
接下来再介绍一下VAE,也就是前面提到的,把图像在像素空间和潜空间之间进行编解码转换的模块。
前面我们说,别管什么潜空间之类的玄乎的词汇,在图像扩散模型中,这个模块的本质就是进行压缩编解码,降低模型训练和推理过程所涉及到的数据量。
说VAE之前得先说一下AE(Auto-Encoder)自编码器。
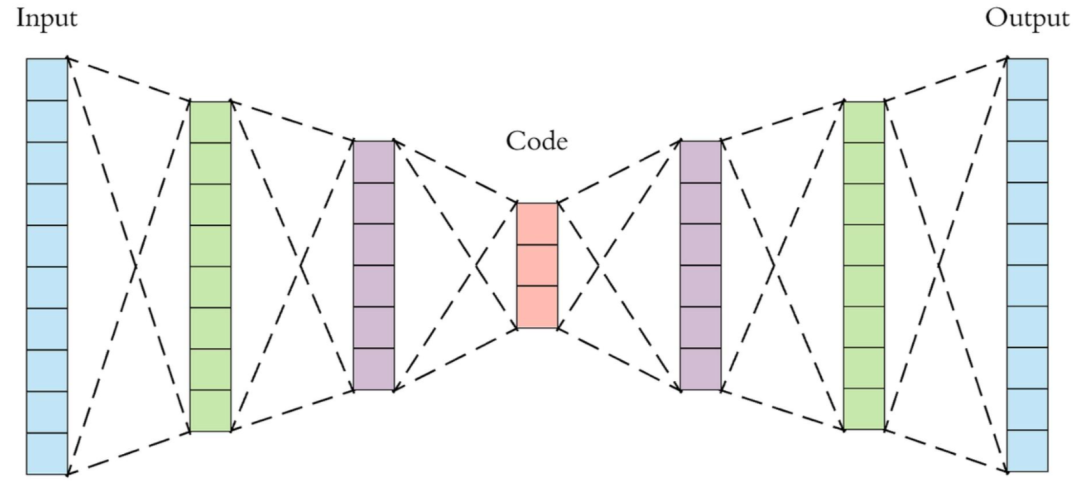
AE的基本思想很简单,大体就是构建了一个普通的神经网络结构,这个网络结构是一个对称的结构,而且越中间的网络层,参数越少,向量的尺寸越小,因此中间层的数据一定程度上就相当于对输入层数据的压缩表达。
实际使用时,训练完成的网络左边的部分,可以作为压缩编码器使用,网络右边的部分可以作为解压缩的解码器使用。中间那层的输出结果就是我们在扩散模型中需要的潜空间向量。
叫他自编码器的原因,是AE网络的训练过程,其训练目标是让网络输出侧的数据尽可能还原网络输入侧的数据(所以整个完整的网络正向传播计算的过程,也就类似于压缩然后再解压了),由于输入数据是已知的,那么目标输出也就是已知的了,所以AE网络的训练过程就不需要人为提供额外的对结果数据的标注了。
至于最后这个网络是怎么实现正确的数据压缩的,代表了啥算法,有啥物理含义,我们其实通通不在乎,你只要保证压缩和解压的流程走一遍以后,数据尽可能还原就好了。这样把中间层的数据拿出来,不就是对原始数据的一个基本无损的的压缩表达形式了嘛。咱神经网络的精髓,不就是不求甚解的实用主义精神嘛,不管白猫黑猫,能抓到老鼠就是好猫。
至于VAE呢,全名是 Variational Auto Encoder,就是AE编码器的一个增强变种。具体实现的原理是在AE网络模型基础上,添加了一些高斯分布的噪音来对网络的参数数值进行抖动处理,已实现更好的泛化效果,避免过拟合。否则在训练过程中见过的数据能较好的压缩和解压,但如果凭空采样生成一个中间层的压缩数据,能否解压成合理的数据就不一定了(举个例子,就好比你随机填一些数据,然后让winzip去解压缩,大概率他会告诉你压缩包损坏,当然,在AE这里,解压还是照样解的,毕竟就是个矩阵运算而已,只是结果可能不如人意),在潜空间很相似的数据经过解码以后,还原到像素空间的图像可能就完全没有关系。
比如,我把球和红色这两个图像分别独立编码以后,在潜空间里进行叠加计算,然后能否解压得到一张与红色的球尽可能相似的图像呢?如果模型不具备一定的线性(或者说低频连续性?)和泛化的能力,很有可能解码的结果就是一匹马,或者完全没有意义的噪声图像。这种情况下,前面我们说到的,各种为了减少计算量,而在潜空间里的去噪,图像元素叠加等操作就没有了实现的理论基础了,因为你在潜空间的操作没办法对等到图像的原始像素空间去。VAE相对于AE的改进,就是为了保证这个基础的前提。至于为什么VAE能做到,从数学的角度进行推导就不在本文的讨论范围之内了。
结语
纵观Sora背后的原理逻辑,我个人依然保持过往的观点:当前的框架从根源上来说,它并没有脱离概率计算和相关性推导的本质,所以并不具备任何真正的逻辑推理能力。仅靠大量的观察和概率统计计算,而没有任何逻辑推理过程,要理解客观世界,建立世界模型,我个人认为,是不太可能的。(尽管人类的逻辑推理能力本质是什么,我们至今也没有什么头绪,也不排除没准万一也就是一个海量神经元单元电化学反应的概率过程,但我个人目前主观上不这么认为)
但也请不要误解我的态度,我并不是要否定Sora的价值,是不是真的具备通用人工智能的能力,并不影响Sora和所有其他AIGC产品在我们的实际工作生活中可能发挥的越来越重要的作用。
此外,个人的认知有限,上文难免有各种不科学不严谨甚至错误的观点,也请各位读者自行思考甄别,毕竟,不要人云亦云,这本身就是笔者写本文的意图出发点所在 ;)