程序访问的局部性原理
程序访问的局部性原理包括时间局部性和空间局部性。
- 时间局部性:指在最近的未来要用到的信息,很可能是现在正在使用的信息,因为程序中存在循环。
- 空间局部性:指在最近的未来要用到的信息,很可能与现在正在使用的信息在存储空间上是邻近的,因为指令通常是顺序存放、顺序执行的,数据一般也是以向量、数组等形式簇聚地存储在一起的。
高速缓冲技术就是利用局部性原理,把程序中正在使用的部分数据存放在一个高速的、容量较小的 Cache 中,使 CPU 的访存操作大多数针对 Cache 进行,从而提高程序的执行速度。

Cache的基本工作原理
Cache 位于存储器层次结构的顶层,通常由 SRAM 构成,其基本结构如图3.17所示。为便于 Cache 和主存间交换信息,Cache和主存都被划分为相等的块,Cache 块又称 Cache 行,每块由若干字节组成,块的长度称为块长(Cache 行长)。由于Cache的容量远小于主存的容量,所以 Cache 中的块数要远少于主存中的块数,它仅保存主存中最活跃的若干块的副本。因此 Cache 按照某种策略,预测 CPU 在未来一段时间内欲访存的数据,将其装入 Cache。
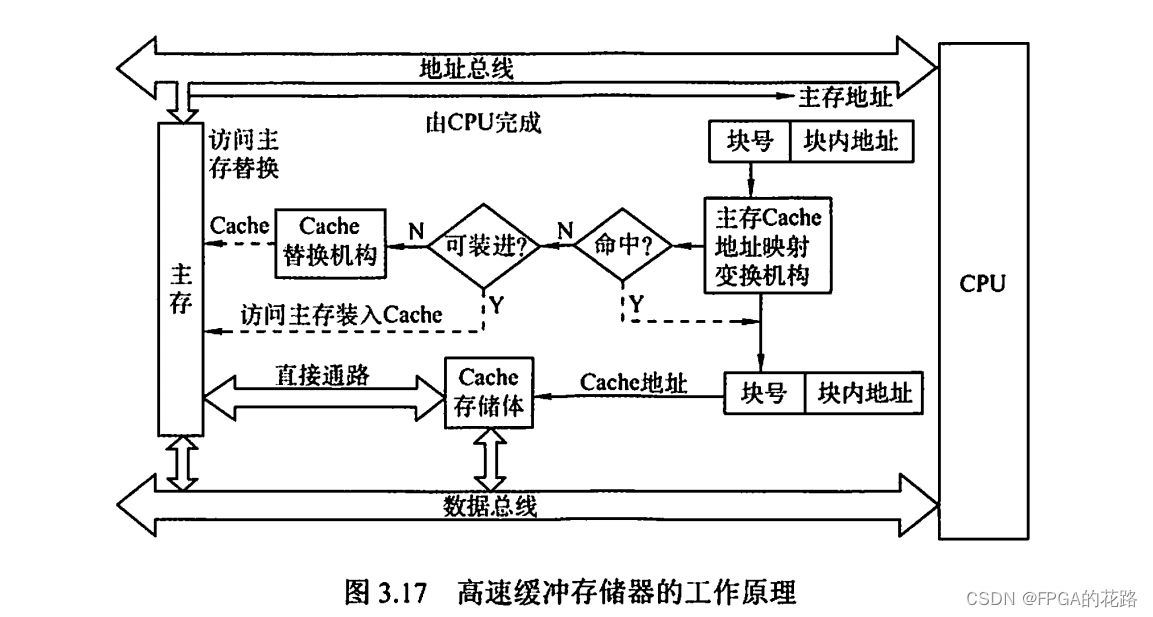
当 CPU 发出读请求时,若访存地址在 Cache 中命中,就将此地址转换成 Cache 地址,直接对 Cache 进行读操作,与主存无关;若 Cache 不命中,则仍需访问主存,并把此字所在的块一次性地从主存调入 Cache。若此时 Cache 已满,则需根据某种替换算法,用这个块替换 Cache 中原来的某块信息。整个过程全部由硬件实现。值得注意的是,CPU 与 Cache 之间的数据交换以字为单位,而 Cache 与主存之间的数据交换则以 Cache 块为单位。
注意:某些计算机中也采用同时访问 Cache 和主存的方式,若 Cache 命中,则主存访问终止;否则访问主存并替换 Cache。
当 CPU 发出写请求时,若 Cache 命中,有可能会遇到 Cache 与主存中的内容不一致的问题。例如,由于 CPU 写 Cache,把 Cache 某单元中的内容从 X 修改成了 X’,而主存对应单元中的内容仍然是 X,没有改变。所以若 Cache 命中,需要按照一定的写策略处理,常见的处理方法有全写法和回写法,详见 Cache 写策略部分。
CPU欲访问的信息已在 Cache 中的比率称为 Cache 的命中率。设一个程序执行期间,Cache 的总命中次数为 Nc,访问主存的总次数为 Nm,则命中率 H 为 H = Nc/(Nc+Nm)
可见为提高访问效率,命中率 H 越接近1越好。设 tc 为命中时的Cache访问时间,tm 为未命中时的访问时间,1-H 表示未命中率,则 Cache-主存系统的平均访问时间 Ta 为 Ta = H*tc+(1-H)*tm

根据 Cache 的读、写流程,实现 Cache 时需解决以下关键问题:
-
数据查找。如何快速判断数据是否在 Cache 中。
-
地址映射。主存块如何存放在 Cache 中,如何将主存地址转换为 Cache 地址。
-
替换策略。Cache 满后,使用何种策略对 Cache 块进行替换或淘汰。
-
写入策略。如何既保证主存块和 Cache 块的数据一致性,又尽量提升效率。
Cache和主存的映射方式
Cache 行中的信息是主存中某个块的副本,地址映射是指把主存地址空间映射到 Cache 地址空间,即把存放在主存中的信息按照某种规则装入 Cache。
由于 Cache 行数比主存块数少得多,因此主存中只有一部分块的信息可放在 Cache 中,因此在 Cache 中要为每块加一个标记,指明它是主存中哪一块的副本。该标记的内容相当于主存中块的编号。为了说明 Cache 行中的信息是否有效,每个 Cache 行需要一个有效位。
地址映射的方法有以下 3 种:
- 直接映射
- 全相联映射
- 组相联映射
直接映射
主存中的每一块只能装入 Cache 中的唯一位置。若这个位置已有内容,则产生块冲突,原来的块将无条件地被替换出去(无须使用替换算法)。直接映射实现简单,但不够灵活,即使 Cache 的其他许多地址空着也不能占用,这使得直接映射的块冲突概率最高,空间利用率最低。
直接映射的关系可定义为 :Cache 行号 = 主存块号 mod Cache 总行数
假设 Cache 共有 2c 行,主存有 2m块,在直接映射方式中,主存的第 0 块、第 2c 块、第 2c+1 块 …… 只能映射到 Cache 的第 0 行;而主存的第 1 块、第 2c+1块、第 2c+1+1块 …… 只能映射到Cache的第 1 行,以此类推。由映射函数可看出,主存块号的低 c 位正好是它要装入的 Cache 行号。给每个 Cache 行设置一个长为 t = m - c 的标记(tag),当主存某块调入 Cache 后,就将其块号的高 t 位设置在对应 Cache 行的标记中,如图3.18(a)所示。
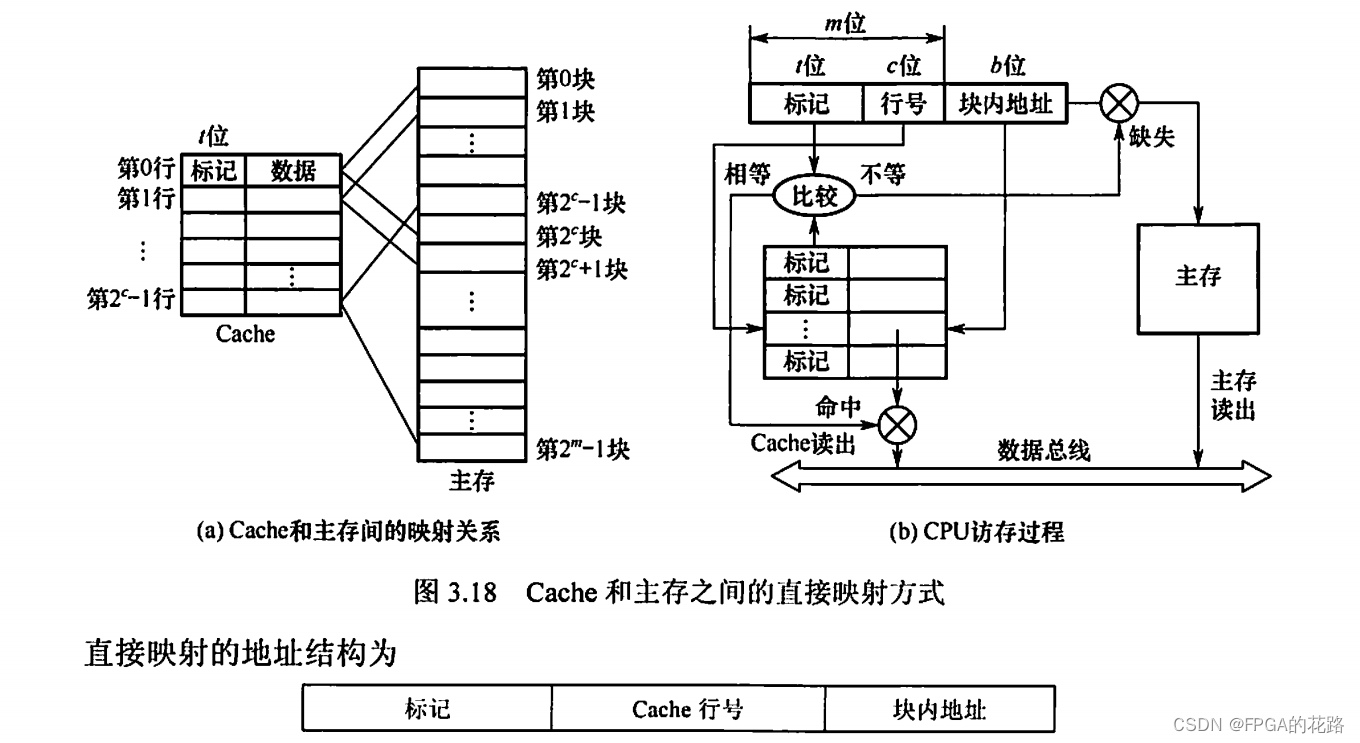
CPU 访存过程如图3.18(b)所示。首先根据访存地址中间的 c 位,找到对应的 Cache 行,将对应 Cache 行中的标记和主存地址的高 t 位标记进行比较,若相等且有效位为 1,则访问 Cache “命中”,此时根据主存地址中低位的块内地址,在对应的Cache行中存取信息;若不相等或有效位为 0,则 “不命中”,此时 CPU 从主存中读出该地址所在的一块信息送到对应的 Cache 行中,将有效位置 1,并将标记设置为地址中的高 t 位,同时将该地址中的内容送 CPU。
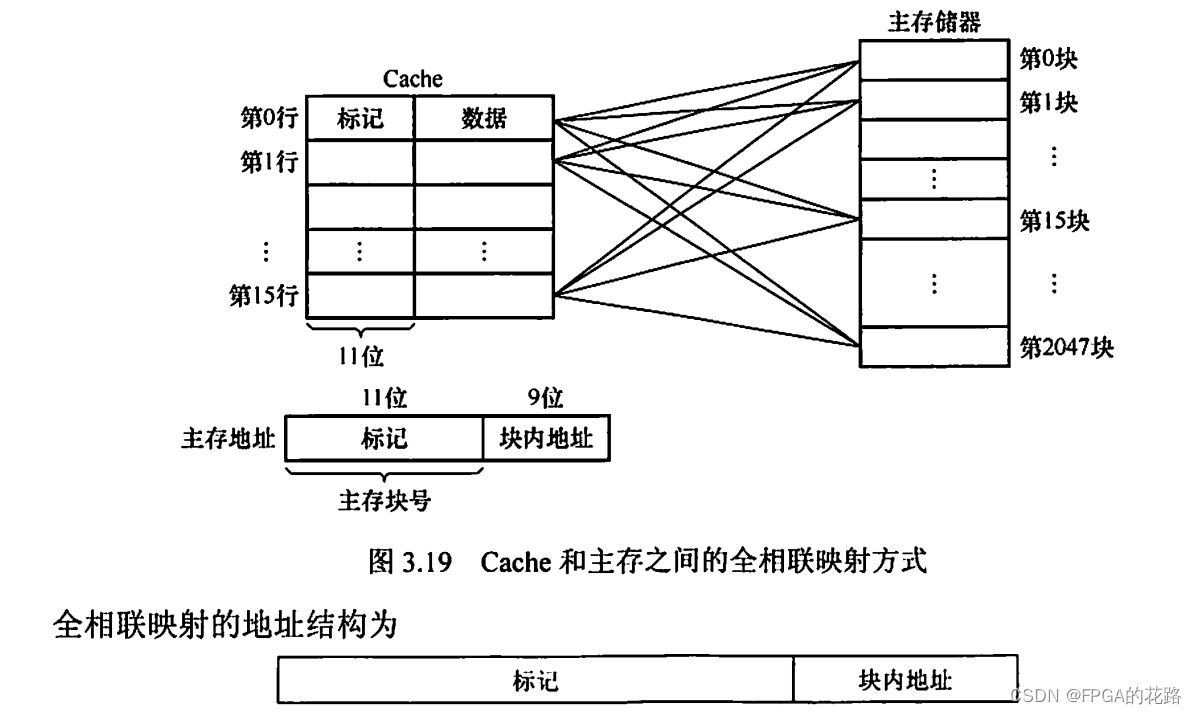
全相联映射
主存中的每一块可以装入 Cache 中的任何位置,每行的标记用于指出该行取自主存的哪一块,所以 CPU 访存时需要与所有 Cache 行的标记进行比较。全相联映射方式的优点是比较灵活,Cache 块的冲突概率低,空间利用率高,命中率也高;缺点是标记的比较速度较慢,实现成本较高,通常需采用昂贵的按内容寻址的相联存储器进行地址映射,如图3.19所示。
组相联映射
将 Cache 分成 Q 个大小相等的组,每个主存块可以装入固定组中的任意一行,即组间采用直接映射、而组内采用全相联映射的方式,如图 3.20 所示。它是对直接映射和全相联映射的一种折中,当 Q = 1 时变为全相联映射,当Q = Cache 行数时变为直接映射。假设每组有 r 个 Cache 行,则称之为 r 路组相联,图 3.20 中每组有 2 个 Cache 行,因此称为二路组相联。
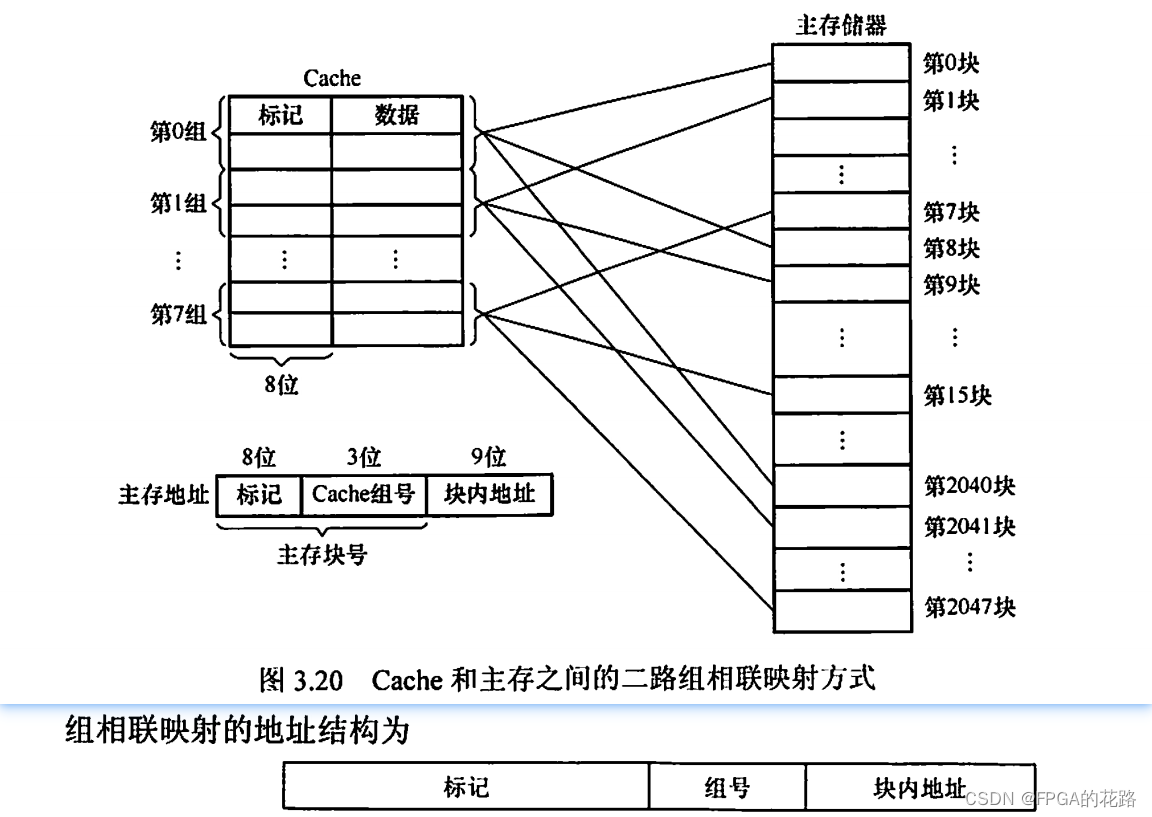
组相联映射的关系可以定义为:Cache 组号 = 主存块号 mod Cache 组数(Q)
路数越大,即每组 Cache 行的数量越大,发生块冲突的概率越低,但相联比较电路也越复杂。选定适当的数量,可使组相联映射的成本接近直接映射,而性能上仍接近全相联映射。
CPU 访存过程如下:首先根据访存地址中间的组号找到对应的 Cache 组;将对应 Cache 组中每个行的标记与主存地址的高位标记进行比较;若有一个相等且有效位为1,则访问 Cache 命中,此时根据主存地址中的块内地址,在对应 Cache 行中存取信息;若都不相等或虽相等但有效位为0,则不命中,此时 CPU 从主存中读出该地址所在的一块信息送到对应 Cache 组的任意一个空闲行中,将有效位置1,并设置标记,同时将该地址中的内容送 CPU。

三种映射方式中,直接映射的每个主存块只能映射到 Cache 中的某一固定行;全相联映射可以映射到所有 Cache 行;N 路组相联映射可以映射到 N 行。当 Cache 大小、主存块大小一定时:
- 直接映射的命中率最低,全相联映射的命中率最高。
- 直接映射的判断开销最小、所需时间最短,全相联映射的判断开销最大、所需时间最长。
- 直接映射标记所占的额外空间开销最少,全相联映射标记所占的额外空间开销最大。
Cache中主存块的替换算法
在采用全相联映射或组相联映射方式时,从主存向 Cache 传送一个新块,当 Cache 或 Cache 组中的空间已被占满时,就需要使用替换算法置换 Cache 行。而采用直接映射时,一个给定的主存块只能放到唯一的固定 Cache 行中,所以在对应 Cache 行已有一个主存块的情况下,新的主存块毫无选择地把原先已有的那个主存块替换掉,因而无须考虑替换算法。
常用的替换算法有随机(RAND)算法、先进先出(FIFO)算法、近期最少使用(LRU)算法和最不经常使用(LFU)算法。
-
随机算法:随机地确定替换的 Cache 块。它的实现比较简单,但未依据程序访问的局部性原理,因此可能命中率较低。
-
先进先出算法:选择最早调入的行进行替换。它比较容易实现,但也未依据程序访问的局部性原理,因为最早进入的主存块也可能是目前经常要用的。
-
近期最少使用算法(LRU):依据程序访问的局部性原理,选择近期内长久未访问过的 Cache 行作为替换的行,平均命中率要比 FIFO 的高,是堆栈类算法。
-
最不经常使用算法:将一段时间内被访问次数最少的存储行换出。每行也设置一个计数器,新行建立后从 0 开始计数,每访问一次,被访问的行计数器加1,需要替换时比较各特定行的计数值,将计数值最小的行换出。这种算法与 LRU 类似,但不完全相同。
LRU 算法对每个 Cache 行设置一个计数器,用计数值来记录主存块的使用情况,并根据计数值选择淘汰某个块,计数值的位数与 Cache 组大小有关,2路时有一位 LRU 位,4 路时有两位 LRU 位。假定采用四路组相联,有 5 个主存块 {1,2,3,4,5} 映射到 Cache 的同一组,对于主存访问序列 {1,2,3,4,1,2,5,1,2,3,4,5},采用 LRU 算法的替换过程如图 3.23 所示。图中左边阴影的数字是对应 Cache 行的计数值,右边的数字是存放在该行中的主存块号。
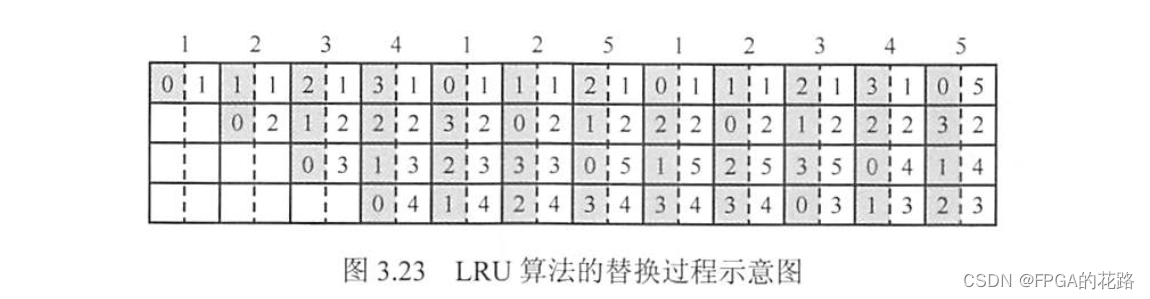
计数器的变化规则:①命中时,所命中的行的计数器清零,比其低的计数器加1,其余不变;②未命中且还有空闲行时,新装入的行的计数器置 0,其余全加 1;③未命中且无空闲行时,计数值为 3 的行的信息块被淘汰,新装行的块的计数器置 0,其余全加 1。
当集中访问的存储区超过 Cache 组的大小时,命中率可能变得很低,如上例的访问序列变为 1,2,3,4,5,1,2,3,4,5,…,而 Cache 每组只有 4 行,那么命中率为 0,这种现象称为抖动。
Cache写策略
因为 Cache 中的内容是主存块副本,当对 Cache 中的内容进行更新时,就需选用写操作策略使 Cache 内容和主存内容保持一致。此时分两种情况。
**对于 Cache 写命中(write hit),有两种处理方法。**全写法和回写法都对应于Cache写命中(要被修改的单元在Cache中)时的情况。
-
全写法(写直通法、write-through)
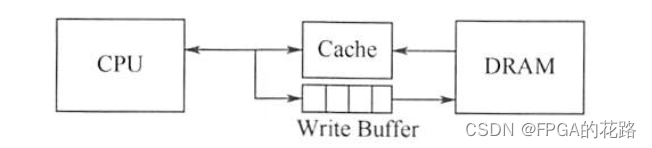
当 CPU 对 Cache 写命中时,必须把数据同时写入 Cache 和主存。当某一块需要替换时,不必把这一块写回主存,用新调入的块直接覆盖即可。这种方法实现简单,能随时保持主存数据的正确性。缺点是增加了访存次数,降低了 Cache 的效率。写缓冲:为减少全写法直接写入主存的时间损耗,在 Cache 和主存之间加一个写缓冲(Write Buffer),如下图所示。CPU 同时写数据到 Cache 和写缓冲中,写缓冲再控制将内容写入主存。写缓冲是一个 FIFO 队列,写缓冲可以解决速度不匹配的问题。但若出现频繁写时,会使写缓冲饱和溢出。
-
回写法(write-back)
当 CPU 对 Cache 写命中时,只把数据写入 Cache,而不立即写入主存,只有当此块被换出时才写回主存。这种方法减少了访存次数,但存在不一致的隐患。为了减少写回主存的开销,每个 Cache 行设置一个修改位(脏位)。若修改位为1,则说明对应 Cache 行中的块被修改过,替换时需要写回主存;若修改位为0,则说明对应 Cache 行中的块未被修改过,替换时无须写回主存。
对于Cache写不命中,也有两种处理方法。
-
写分配法(write-allocate)
加载主存中的块到 Cache 中,然后更新这个 Cache 块。它试图利用程序的空间局部性,但缺点是每次不命中都需要从主存中读取一块。
-
非写分配法(not-write-allocate)
只写入主存,不进行调块。
非写分配法通常与全写法合用,写分配法通常和回写法合用。
随着新技术的发展(如指令预取),需要将指令 Cache 和数据 Cache 分开设计,这就有了分离的 Cache 结构。统一 Cache 的优点是设计和实现相对简单,但由于执行部件存取数据时,指令预取部件要从同一 Cache 读指令,会引发冲突。采用分离 Cache 结构可以解决这个问题,而且分离的指令和数据 Cache 还可以充分利用指令和数据的不同局部性来优化性能。
现代计算机的 Cache 通常设立多级 Cache,假定设 3 级 Cache,按离 CPU 的远近可各自命名为 L1 Cache、L2 Cache、L3 Cache,离 CPU 越远,访问速度越慢,容量越大。指令 Cache 与数据 Cache 分离一般在L1级,此时通常为写分配法与回写法合用。下图是一个含有两级 Cache 的系统,L1 Cache对 L2 Cache 使用全写法,L2 Cache 对主存使用回写法,由于 L2 Cache 的存在,其访问速度大于主存,因此避免了因频繁写时造成的写缓冲饱和溢出。

参考资料:
- 2023王道计算机组成原理考研复习指导(3.5节)
- 带你彻底搞懂cache-哔哩哔哩_









![[PTA] 分解质因子](https://img-blog.csdnimg.cn/direct/703cbe5c7bd74448a861542e13fb0208.png)