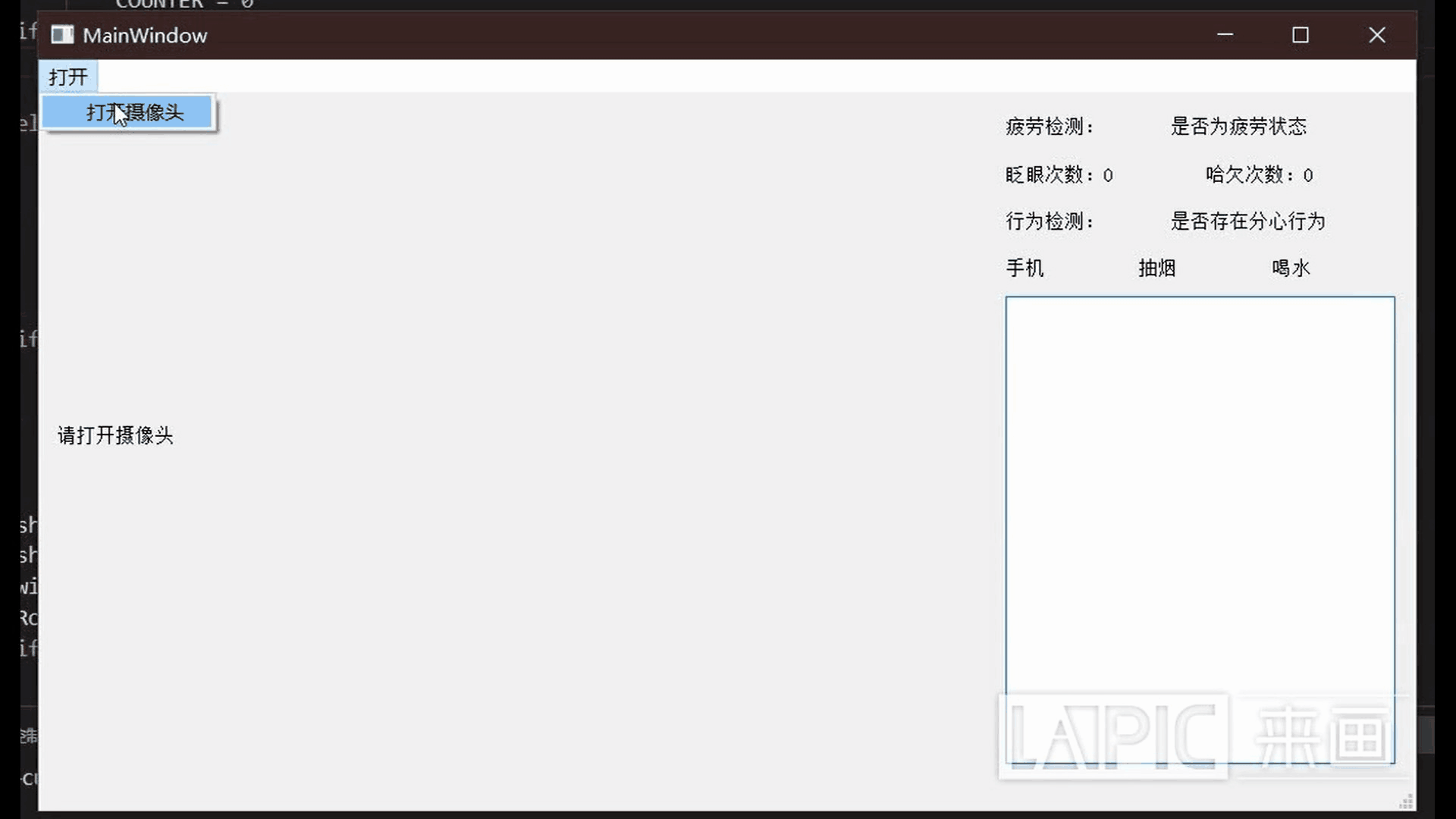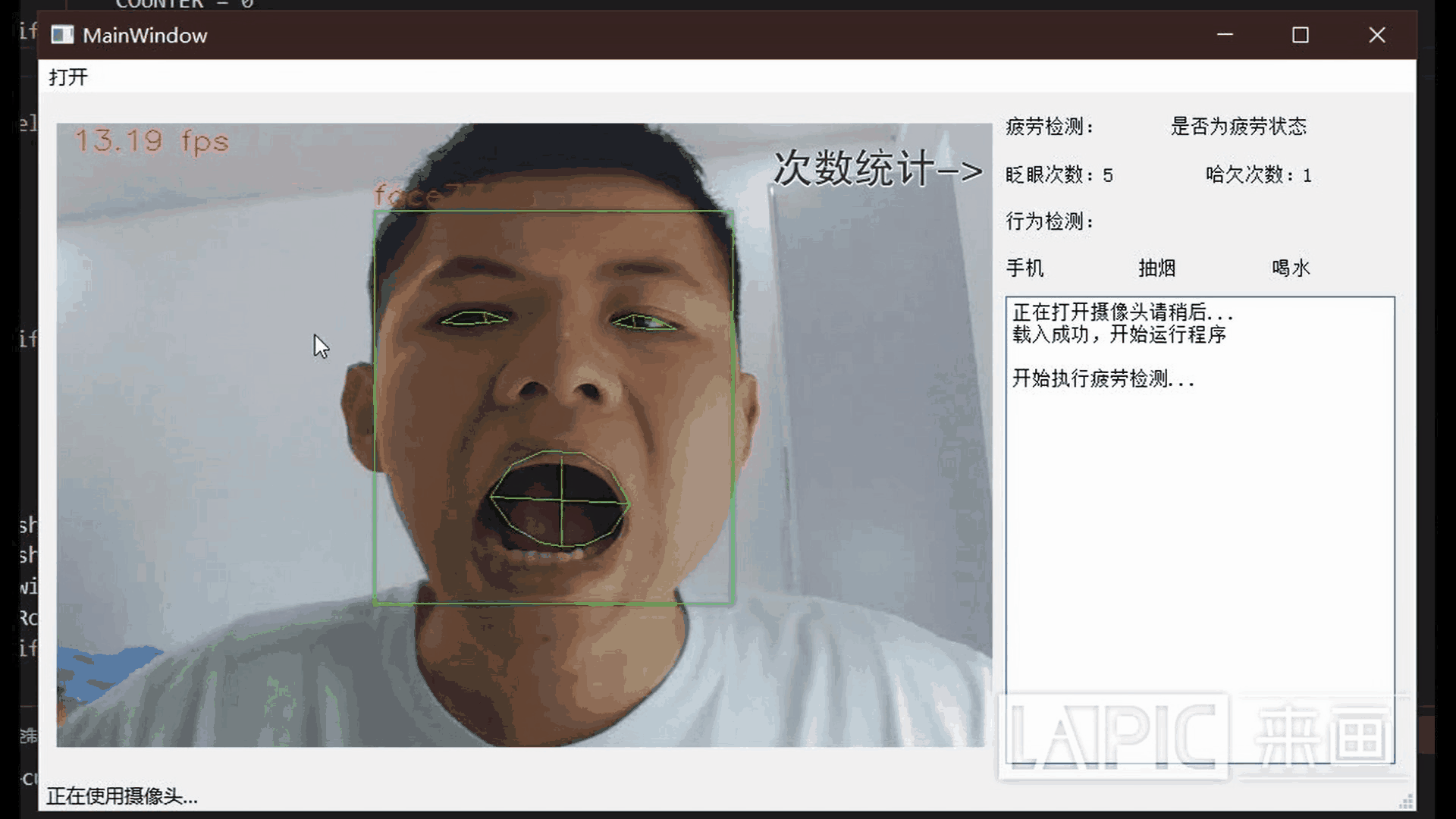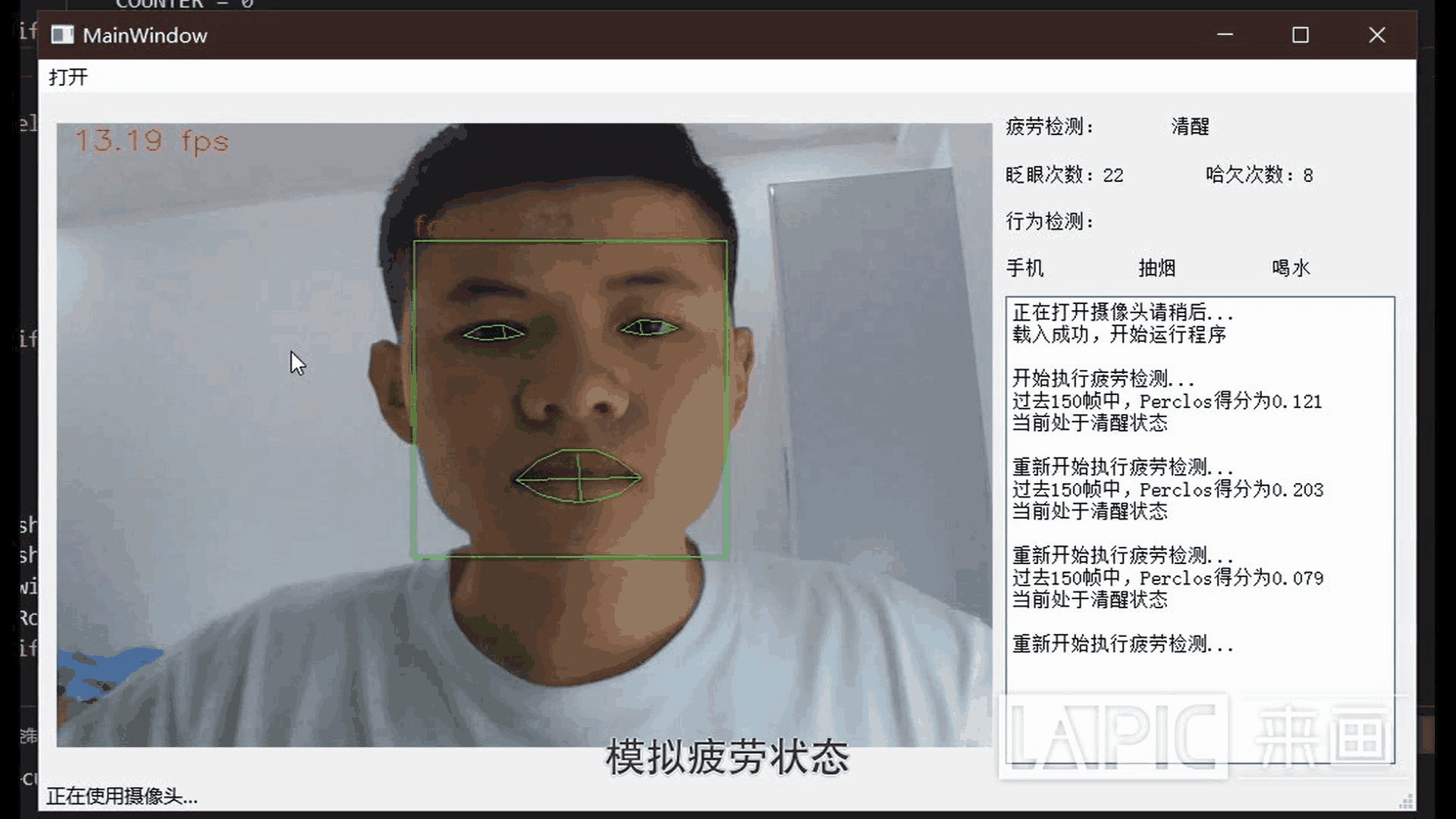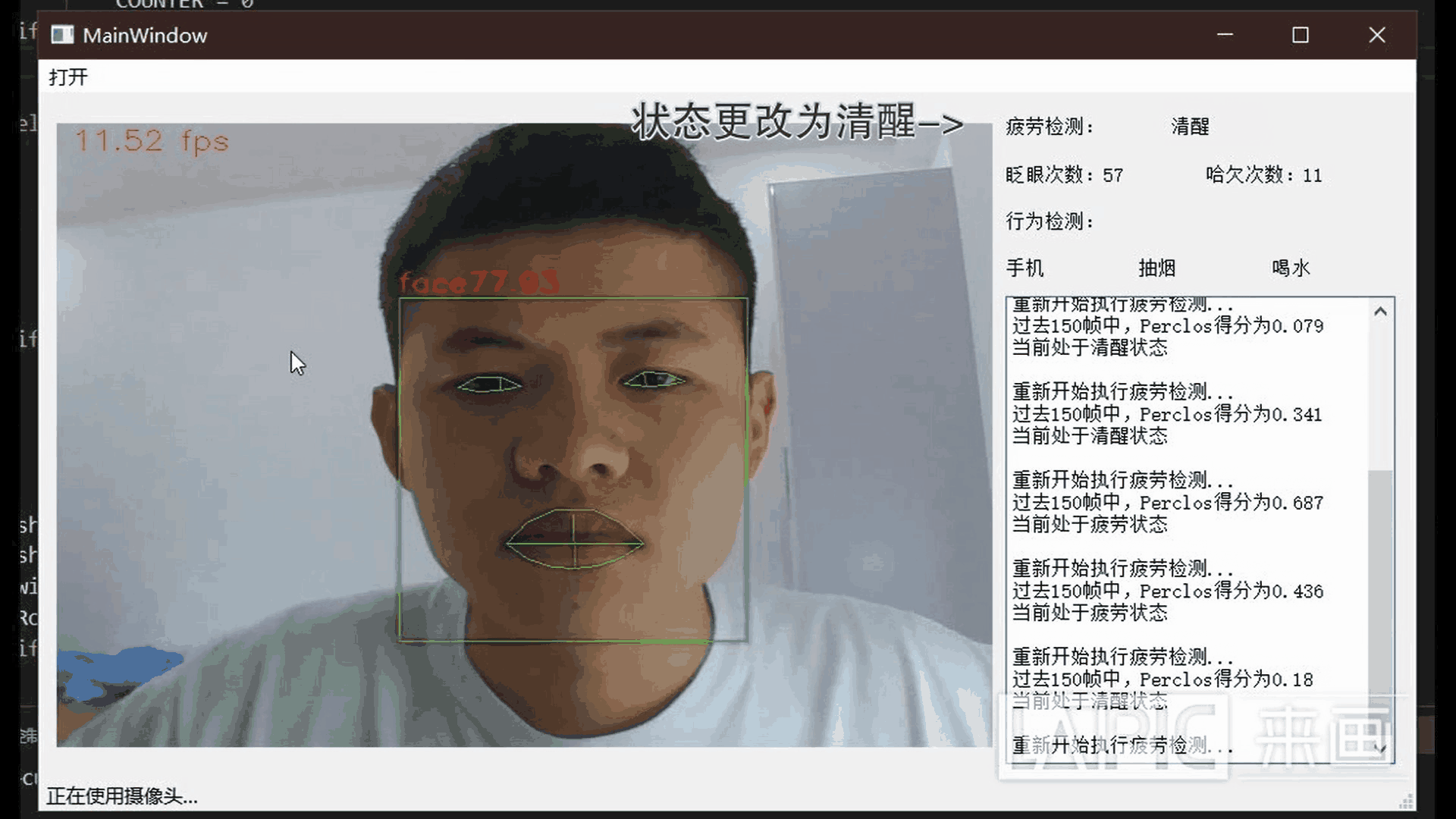
MoE概述

神经网络的学习能力受限于它的参数规模,因此寻找更有效的方法来增加模型的参数已成为深度学习研究的趋势。混合专家系统 (MoE) 可以大幅增加模型参数规模且不会等比例地增加模型计算量,对于单个样本,神经网络只有某些部分被激活。在混合专家系统的稀疏变体(如 Switch Transformer, GLaM, V-MoE)中,会根据 token 或样本来选择专家子集,从而在网络中产生稀疏性。此类模型在多个领域表现出更好的扩展性,并在持续学习的设置下表现出更好的记忆力。然而,糟糕的专家路由策略可能会导致某些专家训练不足,从而导致专家不够专业或过于专业。
在 NeurIPS 2022 的“Mixture-of-Experts with Expert Choice Routing”一文中,谷歌提出了一种称为专家选择 (EC) 的新型 MoE 路由算法。这种方法在 MoE 系统中实现了最佳负载平衡,同时允许 token 到专家映射的异构性。与传统 MoE 网络中基于 token 的路由或其他路由方法相比,EC 表现出了非常强的训练效率,在下游任务取得了很好的成绩。
MoE 路由概述
混合专家系统包含多个专家,每个专家是一个子网络,当输入一个符号 (token) 时,一个或一些专家子网络会被激活。混合专家系统中有一个门控网络 (Gating Network),它的目标是将每个符号路由给最合适的专家网络。根据符号被映射到专家的方式,混合专家系统可以是稀疏的,也可以是密集的。稀疏混合专家系统在路由每个符号时只选择专家集合的一个子集,与密集混合专家系统相比减少了计算成本。稀疏混合专家系统有很多实现方式,例如 k-means 聚类,哈希等。谷歌提出了 GLaM 和 V-MoE,它们都通过稀疏门控混合专家系统推进了自然语言处理和计算机视觉领域的技术进步,证明了稀疏激活的混合专家网络有更好的扩展性能。许多先前的工作都使用的是一种符号选择 (token choice) 的路由策略,这种路由算法为每个输入符号选择最合适的一到两个专家。
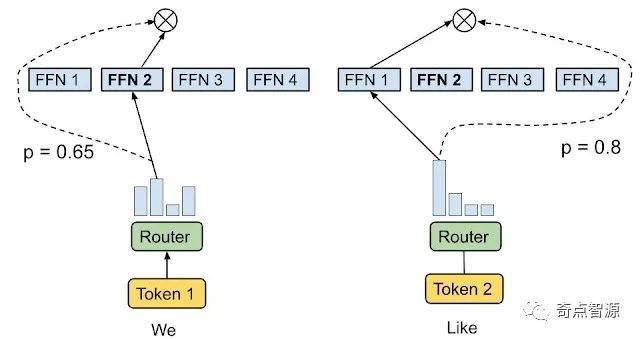
符号选择路由示例。路由选择为每个输入符号依据匹配度 (affinity scores) 选择 top-1 或 top-2 的专家。匹配度与模型的其它参数一起参与训练。
但是为每个符号独立地选择专家往往会导致专家负载不均衡或者利用率不足。为了缓解这种情况,之前的稀疏门控网络会引入额外的辅助损失函数作为正则项,来防止太多符号被路由到相同的专家,但这种方法效果有限。因此,符号选择路由需要大幅增加专家容量(计算容量的2倍到8倍)来避免在缓冲区溢出时丢弃输入符号。
除了负载不均衡这个问题,先前的大多数工作会为每个输入符号通过 top-k 函数分配固定数量的专家,而不考虑不同输入符号的相对重要性。谷歌的研究人员认为,不同的符号应该基于符号的重要性或者难度被不同数量的专家处理。
专家选择路由
为了解决上述问题,谷歌研究人员提出了一种异构混合专家系统,它采用如下所示的专家选择 (Expert Choice) 路由方法。它没有让输入符号选择 top-k 的专家,而是将预定缓冲容量的专家分配给了 top-k 的输入符号。这种方式保证了负载均衡,允许每个输入符号被不同数量的专家处理,并在训练效率和下游性能方面取得了显著的进步。与 Switch Transformer、GShard 和 GLaM 中的 top-1 及 top-2 门控模型相比,专家选择路由在 8B/64E(80 亿激活参数,64 位专家)模型中将训练收敛速度提高了 2 倍以上。
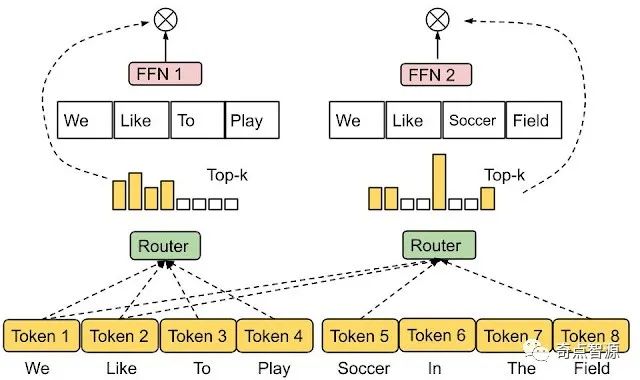
专家选择路由。预定缓冲容量的专家被分配给了 top-k 的输入符号。每个输入符号被不同数量的专家处理。
在专家选择路由中,容量 k 被设置成了每个专家在一批输入序列中处理的平均符号数乘以一个容量因子,这决定了每个符号可被接收的平均专家数量。为了学习符号到专家的匹配度,该方法生成了一个符号到专家的得分矩阵,用于做出路由决策。该得分矩阵表示一批输入序列中的给定符号被路由到指定专家的概率。
与 Switch Transformer 和 GShard 类似,MoE 和门函数使用了全连接前馈神经网络 (Dense Feedforward Layer),这是基于 Transformer 的网络中计算成本最高的部分。在生成符号到专家的得分矩阵后,每个专家使用 top-k 函数来选择与它最相关的输入符号。数据被分配给了多个专家,这样所有的专家可以在输入符号的子集上并行计算。由于专家的容量是固定的,因此不会因负载不平衡而过度配置专家容量,从而与 GLaM 相比,显著减少了约 20% 的训练和推理步骤时间。
结果评估
为了说明专家选择路由的有效性,首先看训练效率和收敛性。使用容量因子为 2 (EC-CF2) 的专家选择路由,与 GShard top-2 门控相比较,并运行固定数量的步骤。EC-CF2 在不到一半的步骤内达到了与 GShard top-2 相同的 perplexity,此外,研究人员发现 GShard top-2 的每一步都比 EC-CF2 慢 20%。
研究人员还测试了不同的专家数量,这个过程将 EC 和 GShard top-2 的专家大小固定为 100M 参数。 结果发现,两者在预训练的 perplexity 的指标上表现得都很好——拥有更多的专家可以持续改善 perplexity。
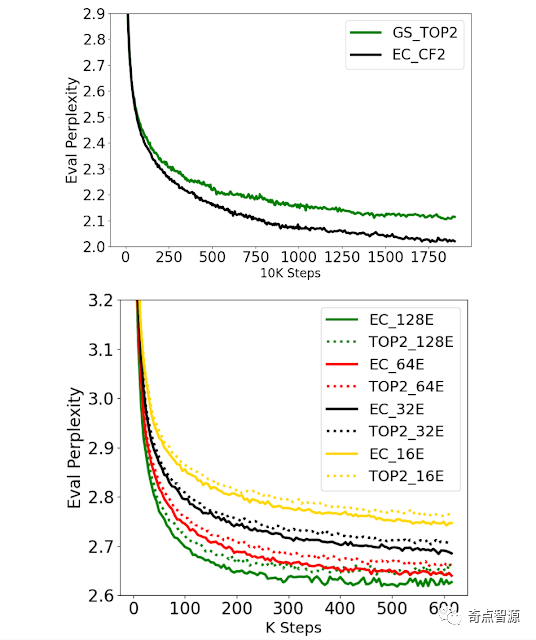
为了验证更好的 perplexity 是否可以为下游任务带来收益,研究人员对 GLUE 和 SuperGLUE 中的 11 个任务进行了微调。在比较了 Switch Transformer top-1 gating (ST Top-1),GShard top-2 gating (GS Top-2) 以及 EC-CF2 后发现,EC-CF2 始终比其他两种方法效果更好,在 8B/64E 的设置下准确率提升了2%以上。此外,与 EC-CF2 对应的密集模型相比,EC-CF2 将平均分数提高了 3.4 分。
实验结果还表明,限制输入符号的专家数量会使微调后的分数平均降低 1 分。这项研究证实,允许每个符号有不同数量的专家确实是有帮助的。另一方面,研究人员发现大多数符号被路由到一到两名专家,而 23% 的符号被路由到三到四名专家,只有约 3% 的符号被路由到四名以上的专家,从而验证了假设,即专家选择路由学会了将可变数量的专家分配给输入符号。
总结思考
专家选择 (EC) 路由为稀疏激活的混合专家系统提出了一种新的路由方法,该方法解决了传统 MoE 方法中的负载不平衡和专家利用率不足的问题,并能够为每个输入符号选择不同数量的专家。与 GShard 和 Switch Transformer 模型相比,该方法将训练效率提升了两倍以上,并且在 GLUE 和 SuperGLUE 基准测试中对 11 个数据集进行微调时取得了可观的收益。