我们的生活当中真正有意义或者有价值的部分可以概括为两句话:一句话是:弄清楚某个东西是怎么一回事,另一句话是,弄清楚某个东西是怎么一回事。头一句话,我们弄清楚的那个东西对于我们而言是未知的,但是已经被别人搞明白了,我们要通过学习,来弄清楚它是怎么一回事,增长我们的知识。而第二句话我们去弄清楚的东西是这个世界上没人明白的东西。那么你要把他弄清楚。事实上你如果想要毕业,你在第二个问题上总要做那么一点点。考试只是一种比较被动的为了分配比较紧张的教育资源而不得已采用的非常low的做法。
在聊正则化之前,先来假设问题场景:我们有采样数据,假定是这么一个样子: X : ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) x k ∈ R n , y k ∈ R X:(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\quad x_k\in R^n,y_k\in R X:(x1,y1),(x2,y2),...,(xn,yn)xk∈Rn,yk∈R 我们试图对这一堆数据进行处理,而且我们的目的很单纯,就是试图找到 y k y_k yk和 x k x_k xk之间的关联方式,即, y k = f ( x k ) y_k=f(x_k) yk=f(xk)。现在我们要怎么找到它?
我们要用这些采样数据,他们有一个专门的名:Training Set(训练集)。我们训练的目的是为了要把握规律,我们不仅仅是把训练集里的事全搞清楚,而且我们希望还有推广能力(泛化能力Generalization),即,对于我们没有看见的数据也能做相应处理。
如果我们就以训练集作为目标的话,这个问题其实根本不需要考虑。因为这个问题其实已经解决了,因为有一种技术叫插值(Interpolation)。对于空间中散列的一些点,是可以用插值来找到支配这些点的规律的。并且可以用非常明确的函数形式,比方说多项式Polynomial。但是他的复杂度是取决于训练集的复杂度的,准确地讲,如果训练集有n个数据,他就是一个n阶多项式(n-orders)。n个方程n个未知数,解出来就是了。何况有一种多项式叫拉格朗日,这个多项式形式甚至直接是已知的。

黄色曲线对应插值的结果,绿色曲线对应我们想要的规律。
我们大体一画,大家就会明白,你这样的一个插值结果,尽管说,你在训练集上获得了100%的收益,但是这并不是你想要的东西。因为显而易见他并没有把握住数据的规律。而且这个东西具有严重的不稳定性(Unstable / Non-robust),即,一旦这个插值完成了以后,假如某个点有个些许的变化,你必须要重新进行插值,而你重新插出来的情况和你一开始插出来的情况,两者之间可能存在着巨大的差异。这就使得我们不敢用这样的技术。因为我们谁也说不准,在采样当中究竟有没有噪声(Noise)。换句话讲,采样一定是有噪声的,基于噪声数据的精确插值跟真实规律之间往往存在者较大的差异。
第二个问题:一旦用n阶多项式这么插值以后,多项式的系数往往会过大,产生大系数(Large Coefficient)。这也会产生一种不稳定,跟上一种的区别在于,这会儿多项式已经确定下来了,下一个数据再来的时候,如果新的数据当中也存在一些噪声、畸变,或者一些不好的影响,那么这些不好的影响在我的多项式中就会被充分地放大。
这就是典型的过拟合(Overfit)。
类比学习的过程,我们发现考试也没有这么简单。原因在于,我们考试的题目和平时练习的题目不一样,过拟合就是把做题作死了,缺乏一种推广能力,但是推广能力怎么产生出来呢?在此之前,我们还得补充一条机器学习领域的基本定理。
还是回到图1那幅图,有人说,诶你看那条绿线应该比较好。注意:这个只是一个表象。这有一个前提:基于样本数据!换句话讲我们现在做的所有事情都是基于样本数据进行的。而样本数据和我们真正想研究的那个背后的规律之间是否有很密切的联系没人知道。因此才有了一件非常有趣的事,叫做**"No free Lunch "Theorem。**
"No free Lunch "Theorem
在这里我们假定 L 是Loss Function: L ( f ( x ) , y ) L是 \text{Loss Function}: L(f(x),y) L是Loss Function:L(f(x),y) ,即,用 f f f这样的模型去把 x x x与 y y y联系在一起,将会承受多大的损失( Cost : C ( f ) \text{Cost}: C(f) Cost:C(f))。现在我们把这个损失分成两个角度来看:
①. 基于样本的角度: Empirical: C 1 [ f X ] = 1 n ∑ k = 1 n L ( f X ( x k ) , y k ) \text{Empirical}:C_1[f_X] = \frac{1} {n}\sum_{k=1}^nL(f_X(x_k),y_k) Empirical:C1[fX]=n1k=1∑nL(fX(xk),yk)我们希望基于样本做出来的模型具有某种最优性: f X ( x ) = arg min f C 1 [ f X ] f_X(x)=\underset{f}{\arg \min}\ C_1[f_X] fX(x)=fargmin C1[fX] ,换句话讲, f X ( x ) f_X(x) fX(x)是我们能在样本数据上为了降低损失几乎能做的一切。
②. 从理论的角度: Theoretical: C 2 [ f ] = ∫ x × y L ( f ( x ) , y ) p ( x , y ) d x d y \text{Theoretical}:C_2[f]=\int _{x \times y}L(f(x),y)p(x,y)dxdy Theoretical:C2[f]=∫x×yL(f(x),y)p(x,y)dxdy做积分,但这就存在一个问题:这个分布 p ( x , y ) p(x,y) p(x,y)只能来自上帝视角,没人知道。我们对这个分布的认识,仅仅能够从样本数据来获得,而样本数据所反映的一定只是这个分布的一部分,甚至是一小部分,甚至是很偏的一部分,甚至什么都反应不了。因为你的采样不可能完全没有偏差(Smaple Bias)。就比如你身边没有人出门,但是火车站和机场永远人来人往,你不能基于你身边的采样就说火车和飞机没用。因为对你没用,不等于对别人没用。采样一定是有偏差的。
可以给一个定义: f ∗ ( x ) = arg min f C 2 [ f ] f^*(x)=\underset{f}{\arg \min}\ C_2[f] f∗(x)=fargmin C2[f]
f ∗ ( x ) f^*(x) f∗(x)就是我们最优的那个关系或者说模型。但他只是一个标杆,我们基本是达不到的,而我们能争取的也只有①。
假设我现在做了一个模型,叫 f ( x ) f(x) f(x),那么我可以跟理想的 f ∗ ( x ) f^*(x) f∗(x)和基于样本最优的 f X ( x ) f_X(x) fX(x)模型之间产生如下的关联:
f ( x ) − f ∗ ( x ) = f ( x ) − f X ( x ) ‾ + f X ( x ) − f ∗ ( x ) ‾ f(x)-f^*(x)=\color{red}\underline{f(x)-f_X(x)}+\color{blue}{\underline{f_X(x)-f^*(x)}} f(x)−f∗(x)=f(x)−fX(x)+fX(x)−f∗(x)
红蓝两部分分别叫做:
- 估计误差(Estimate): f ( x ) − f X ( x ) \color{red}{f(x)-f_X(x)} f(x)−fX(x)
- 逼近误差(Approximate): f X ( x ) − f ∗ ( x ) \color{blue}{f_X(x)-f^*(x)} fX(x)−f∗(x)
我们能做的只有红色这一部分,蓝色这部分我们根本动不了:采样数据本身与我们真实情况之间的偏差,是你根本没有办法去触及和改变的,这就叫“no-free-lunch”。在这一点上大家都在瞎子摸象,谁也别笑话谁。任何一种建模方法都不可能是universal最优的。机器学习其实是个低科技,算法其实早就有了。统计学上的算法改个名就都到机器学习里来了,那些东西本来几十年前大家就已经明白了,我们现在缺的是什么,就是数据。对于自动驾驶而言,目前Google 的自动驾驶应该是做的最好的,特斯拉其实不太行,Google 它强在哪,他就是数据多,因为做得早,他有着大量的采样数据,当然人们认为,他那点采样数据对于把机器训练得向人开车开得这么好,也还差得非常非常远。数据才是根本:“no-free-lunch”恰好在说明这一点,后一部分误差是你自身数据造成的,你如果不能在数据上取得突破,你光在算法上想办法,没意义。当然我们这里没有去体现这两部分误差哪部分更加主导,但是实践的经验告诉我们,后面这个更要命。是因为我们目前对算力的掌控迫使我们不可能把数据搞得特别多,这是我们自身的条件约束。而我们基于样本数据,最好的也只能做到 f X ( x ) f_X(x) fX(x)。
Bias-Variance Decomposition
我们下面来计算这个东西:
C 2 [ f ] = ∫ x × y L ( f X ( x ) , y ) p ( x , y ) d x d y C_2[f]=\int _{x \times y}L(f_X(x),y)p(x,y)dxdy C2[f]=∫x×yL(fX(x),y)p(x,y)dxdy
根据我们的定义,他就是把我们从数据产生的那个最优解,代到了我们理想的理论误差上去。这个X自身是随机的。我们这么一代入,这个误差就是有随机性的。因此很自然的,我们希望能够对他进行期望: E X [ C ( 2 [ f X ] ) ] = E X [ ∫ x × y L ( f X ( x ) , y ) p ( x , y ) d x d y ] = E X [ E x , y ( L ( f X ( x ) , y ) ) ] E_X[C(_2[f_X])] = E_X[\int _{x \times y}L(f_X(x),y)p(x,y)dxdy]\\= E_X[E_{x,y}(L(f_X(x),y ))] EX[C(2[fX])]=EX[∫x×yL(fX(x),y)p(x,y)dxdy]=EX[Ex,y(L(fX(x),y))]
这里我们对L,还有x和y之前的那个上帝视角的那个联系做一下假定:
- 假定这里是标准的回归模型:Regression model: y = f 0 ( x ) + ε , E ( ε ) = 0 , V a r ( ε ) = σ 2 y=f_0(x)+\varepsilon,\quad E(\varepsilon)=0, Var(\varepsilon)=\sigma^2 y=f0(x)+ε,E(ε)=0,Var(ε)=σ2
- 我们假定这个L是我们熟悉的二次函数: L ( a , b ) = ( a − b ) 2 L(a,b)=(a-b)^2 L(a,b)=(a−b)2
于是我们就会得到: E X [ E x , y ( ( f X ( x ) − y ) 2 ) ] E_X[E_{x,y}((f_X(x)-y)^2)] EX[Ex,y((fX(x)−y)2)]
这里有三个随机变量,这三个随机变量之间有什么关系我们需要搞清楚:用图来表示:

y是由小x和e共同决定的。采样数据X应当是由小x导出的,
有了这个关系,对接下来的计算会有一定帮助。
下面我们来计算这个期望,我们先条件住谁?这确实是一个问题,注意:我们条件住的是这个小x:
E
x
(
E
X
,
y
(
(
f
X
(
x
)
−
y
)
2
∣
x
)
)
E_x(E_{X,y}((f_X(x)-y)^2|x))
Ex(EX,y((fX(x)−y)2∣x))
接着展开: = E x ( E X , y ( [ f X ( x ) 2 + y 2 − 2 f X ( x ) ⋅ y ] ∣ x ) ) =E_x(E_{X,y}([f_X(x)^2+y^2-2f_X(x)·y]|x)) =Ex(EX,y([fX(x)2+y2−2fX(x)⋅y]∣x))
= E x [ E X ( f X 2 ( x ) ∣ x ) + E y ( y 2 ∣ x ) − 2 E X , y ( f X ( x ) ⋅ y ∣ x ) ] =E_x[E_X(f_X^2(x)|x) + E_y(y^2|x) - 2E_{X,y}(f_X(x)·y|x)] =Ex[EX(fX2(x)∣x)+Ey(y2∣x)−2EX,y(fX(x)⋅y∣x)]
= E x [ V a r X ( f X ( x ) ∣ x ) + ( E X ( f X ( x ) ∣ x ) ) 2 + V a r ( y ∣ x ) + ( E y ( y ∣ x ) ) 2 − 2 E X , y ( f X ( x ) ⋅ y ∣ x ) ] =E_x[Var_X(f_X(x)|x)+(E_X(f_X(x)|x))^2 + Var(y|x) + (E_y(y|x))^2 -2E_{X,y}(f_X(x)·y|x)] =Ex[VarX(fX(x)∣x)+(EX(fX(x)∣x))2+Var(y∣x)+(Ey(y∣x))2−2EX,y(fX(x)⋅y∣x)]
随着我们的展开,他们的意义慢慢明确起来:我们一项一项看:
这个 V a r ( y ∣ x ) Var(y|x) Var(y∣x)是什么?如果这个看不清楚,没关系,我们看这项: E y ( y ∣ x ) E_y(y|x) Ey(y∣x),这个是条件期望,我们讲过,他是均方意义下的最优估计,换句话讲,这个条件期望不是别的,就是我们在上帝视角上能够做的最好的那个 f ∗ ( x ) f^*(x) f∗(x),也就是我们这里的这个 f 0 f_0 f0,那么 V a r ( y ∣ x ) Var(y|x) Var(y∣x)就等于 V a r ( ε ) = σ 2 Var(\varepsilon)=\sigma^2 Var(ε)=σ2,是一个定值,不会随我们的分析而改变。因此这两项,我们就给看明白了。 E y ( y ∣ x ) = f ∗ ( x ) E_y(y|x) = f^*(x) Ey(y∣x)=f∗(x)这个 σ 2 \sigma^2 σ2提醒我们这样一件事情:即便我们有上帝视角,即便我们已经知道了那个背后的分布是什么,我们也不可能做的100%的准确,因为你模型当中本身有不确定性。本身有随机项,如果我们进一步假定为高斯,即便你连这都知道了,你能把误差做到0吗?不可能 。我告诉你有一个随机变量是高斯分布,你猜一下这个随机变量等于几?你哪猜得出来,这里高斯自身的随机性是你不能去克服和穿越的。所以我们要强调误差当中有这一部分是不会被改变的。
那么这个 ( E X ( f X ( x ) ∣ x ) ) 2 (E_X(f_X(x)|x))^2 (EX(fX(x)∣x))2是什么?我们在数据层面上能做到的最好的模型就是 f X ( x ) f_X(x) fX(x),因为这里包含两部分随机性,我把里面那部分给掐住。我专门看数据这一部分,这个时候我里面的x已经被条件住了,相当于已经没有随机性了,不会影响我们对数据的这个看法,我专门看数据,那么我希望在数据上面做一个平均,然后这样平均出来的模型,是不是可以认为是某种意义上你能够做到的最好的估计。因为你能够做到的最好的模型他一定依赖于数据。现在你在所有可能的数据上做平均,那也就是你能做到的最好的模型,这个模型,他的误差我们写在这了: V a r X ( f X ( x ) ∣ x ) Var_X(f_X(x)|x) VarX(fX(x)∣x)
我们再看一看这儿: 2 E X , y ( f X ( x ) ⋅ y ∣ x ) 2E_{X,y}(f_X(x)·y|x) 2EX,y(fX(x)⋅y∣x),在已知x的情况下,大X跟y什么状态啊?看看那个图,如果小x已经知道了,没随机性了那么大X和y之间的连接就被掐断了。

额,大家都学过马尔可夫,马尔可夫有一个基本的小结论,假设A是过去,B是当下,C是未来,那么我在知道当下的情况下,这个未来跟过去就没有联系了: P ( C ∣ B A ) = P ( C ∣ B ) P(C|BA)=P(C|B) P(C∣BA)=P(C∣B)
他有一个等价形式:
P
(
C
A
∣
B
)
=
P
(
C
∣
B
)
P
(
A
∣
B
)
P(CA|B)=P(C|B)P(A|B)
P(CA∣B)=P(C∣B)P(A∣B) 假如,我把当前给条件住,那么未来跟过去一定是独立的。 他为什么能独立呢?因为过去跟未来本来他们就是由当前来单向联系的,你这个单向联系中间一切断,两者就是条件独立的。同样的道理:如果我们把小x给条件住了,我们的大X跟小y条件独立。
因此就有:
E
X
,
y
(
f
X
(
x
)
⋅
y
∣
x
)
=
E
X
,
y
(
f
X
(
x
)
∣
x
)
E
X
,
y
(
y
∣
x
)
E_{X,y}(f_X(x)·y|x) = E_{X,y}(f_X(x)|x)E_{X,y}(y|x)
EX,y(fX(x)⋅y∣x)=EX,y(fX(x)∣x)EX,y(y∣x)和我们在马儿可夫中的感觉非常的类似。
有了这些知识,现在我们就能够把他们总结在一起了:
注意到:
(
E
X
(
f
X
(
x
)
∣
x
)
)
2
+
(
E
y
(
y
∣
x
)
)
2
−
2
E
X
,
y
(
f
X
(
x
)
∣
x
)
E
X
,
y
(
y
∣
x
)
(E_X(f_X(x)|x))^2 + (E_y(y|x))^2 -2 E_{X,y}(f_X(x)|x)E_{X,y}(y|x)
(EX(fX(x)∣x))2+(Ey(y∣x))2−2EX,y(fX(x)∣x)EX,y(y∣x)
= [ E X ( f X ( x ) ∣ x ) ) − f ∗ ( x ) ] 2 =[E_X(f_X(x)|x)) - f^*(x)]^2 =[EX(fX(x)∣x))−f∗(x)]2
是个完全平方。所以最终原式可以写成: E x ( σ 2 + V a r X ( f X ( x ) ∣ x ) + [ E X ( f X ( x ) ∣ x ) ) − f ∗ ( x ) ] 2 ) = σ 2 + V a r X ( f X ( x ) ) + [ E X ( f X ( x ) ) − f ∗ ( x ) ] 2 ) E_x(\sigma^2 + Var_X(f_X(x)|x)+[E_X(f_X(x)|x)) - f^*(x)]^2)\\\ \\=\sigma^2 + Var_X(f_X(x))+[E_X(f_X(x)) - f^*(x)]^2) Ex(σ2+VarX(fX(x)∣x)+[EX(fX(x)∣x))−f∗(x)]2) =σ2+VarX(fX(x))+[EX(fX(x))−f∗(x)]2)
其中,第一个 σ 2 \sigma^2 σ2是上帝来了也没办法克服的一部分误差,刚才解释过了,我们关键看后头两个,第二个是一个方差,第三个是一个偏差。一个是这个模型的方差,一个是这个模型与我们上帝视角模型最优解之间的偏差。所以我们在这里谈到的是Bias-Variance Tradeoff。
Bias-Variance Tradeoff
我们以前遇到过的形式是这样子的: E ( θ − θ ^ ) 2 = E ( θ ^ − E ( θ ^ ) ) 2 + ( E ( θ ^ ) − θ ) 2 E(\theta - \hat \theta)^2 = E(\hat \theta - E(\hat \theta))^2 + (E(\hat \theta)- \theta)^2 E(θ−θ^)2=E(θ^−E(θ^))2+(E(θ^)−θ)2 前面这一项是随机误差,后面这一项是系统误差,有时候我们更希望让随机误差更小,宁可牺牲掉一点系统误差,所以我们未必要追求无偏性,因为无偏性代表后头这一项是0,所有的压力都压到前面这一项来了。我们这里如果能够进行tradeoff,我们宁可把后面牺牲掉一点,因为后面是可以整体性地纠偏的,而前面往往更加难以对付 。
那么参照之前的之前的经验,我们应该牺牲掉后面。牺牲后面是什么意思?意思是我这个模型可以搞得稍微简单一点,意味着我们在模型复杂度上做了一些牺牲,使得我们在偏差这里做了点放松,而我们想换来的是前头一项可以降得更低。其背后的原理是,模型简单了,我们控制起方差来更容易。这和我们刚才所做的描述就对应起来了:我们为什么不愿意用多项式插值,因为多项式插值模型太过复杂,你是可以通过多项式插值让这个偏差变得很小,但是你把前面这一项方差(随机误差)放得非常大,得不偿失。而我们为什么喜欢用线性的,是因为线性它往往前面控制起来非常容易,没有比线性更简单的了。
因此,在之前版本的bias-variance tradeoff里面我们希望去牺牲的是无偏性,我们希望换来的是整体MSE的可控,在今天这个版本的bias-variance tradeoff里面,我们希望牺牲掉的是模型自身的复杂程度,我们换来的是对这个模型估计的方差的可控。两者道理几乎是一致的。
如果大家能够对这件事情有一定的认识,我们再开始说我们今天要说的第三件事情,那就进入到我们的主题了,那就是正则化。
正则化(Regularization)
我现在,想对我的模型做一些简化:,那这个简化怎么做,就变得很有意思了,原始情况下,我都是极小化我的损失的,没有任何的约束: arg min f X 1 n ∑ k = 1 n L ( f X ( x k ) , y k ) \underset{f_X}{\arg \min} \frac{1}{n}\sum_{k=1}^nL(f_X(x_k),y_k) fXargminn1k=1∑nL(fX(xk),yk)那么现在我要简化的话,很显然,我是要加约束的,我要约束我的模型必须落在某一类模型当中: s . t . f X ( x ) ∈ F s.t.f_X(x)\in F s.t.fX(x)∈F
这个事情,他可以进一步明确为: arg min θ 1 n ∑ k = 1 n L ( f X ( x k , θ ) , y k ) \underset{\theta}{\arg \min} \frac{1}{n}\sum_{k=1}^nL(f_X(x_k,\theta),y_k) θargminn1k=1∑nL(fX(xk,θ),yk)这里我们做了参数化。是因为 F F F是一个泛函概念,函数集合或者函数空间,我们不习惯。我们比较习惯普通的欧式空间,怎么把函数空间转换为欧式空间呢?很简单,我们只要把函数参数化就可以了:通过参数化,我们把寻找最优的那个函数,变成寻找最优的参数,那么相应的,我们函数出现在某个函数空间这样的数学表达,也就可以转变为参数属于某个可行域: s . t . θ ∈ Ω s.t.\theta \in \Omega s.t.θ∈Ω
我们继续,我们要选择一个合适的损失:均方损失。当然这个损失还可以有别的选择方式,根据你的问题,根据你的背景而设定。
arg
min
θ
1
n
∑
k
=
1
n
E
(
f
X
(
x
k
,
θ
)
−
y
k
)
2
.
s
.
t
.
θ
∈
Ω
\underset{\theta}{\arg \min} \frac{1}{n}\sum_{k=1}^nE(f_X(x_k,\theta)-y_k)^2. \quad s.t.\theta \in \Omega
θargminn1k=1∑nE(fX(xk,θ)−yk)2.s.t.θ∈Ω更进一步地,来把我们的模型给落地,给出参数化模型的具体样式,这里我们考虑简单情况:线性的。
arg
min
θ
1
n
∑
k
=
1
n
E
(
θ
k
T
x
k
−
y
k
)
2
.
s
.
t
.
θ
∈
Ω
\underset{\theta}{\arg \min} \frac{1}{n}\sum_{k=1}^nE(\theta_k^T x_k-y_k)^2. \quad s.t.\theta \in \Omega
θargminn1k=1∑nE(θkTxk−yk)2.s.t.θ∈Ω再来一步,我们现在终于要触摸到正则化的核心了,可行域怎么定?我们刚才谈到过多项式插值两个问题:第一个是不稳定,是因为它没有考虑到数据当中有可能存在着噪声;第二个是大系数,这数一大,这事儿就不太对。因此我们想要做正则化,我们想要把我们的这个模型参数限制在一定范围之内,能够对他有所控制,我们可以限制这个参数的大小,限制大小的方式其实有很多,我们这提一种最自然容易想到的方式,它的二次模有界:
arg
min
θ
1
n
∑
k
=
1
n
E
(
θ
k
T
x
k
−
y
k
)
2
.
s
.
t
.
∣
∣
θ
∣
∣
2
2
≤
r
\underset{\theta}{\arg \min} \frac{1}{n}\sum_{k=1}^nE(\theta_k^T x_k-y_k)^2. \quad s.t.||\theta||_2^2 \leq r
θargminn1k=1∑nE(θkTxk−yk)2.s.t.∣∣θ∣∣22≤r这个结果来源于Tikhnov,所以学术界统称为:Tikhnov Regularization
现在我们来算这个正则化,这里暂时丢开期望,我们假定:
X
=
(
x
1
T
x
2
T
⋮
x
n
T
)
y
=
(
y
1
T
y
2
T
⋮
y
n
T
)
⇒
∑
k
=
1
n
(
x
k
T
θ
k
−
y
k
)
2
=
(
X
θ
−
y
)
T
(
X
θ
−
y
)
X = \begin{pmatrix} x_{1}^T \\ x_{2}^T \\ \vdots\\ x_{n}^T \end{pmatrix} \quad y = \begin{pmatrix} y_{1}^T \\ y_{2}^T \\ \vdots\\ y_{n}^T \end{pmatrix} \\ \Rightarrow \sum_{k=1}^n(x_k^T\theta_k-y_k)^2=(X\theta-y)^T(X\theta-y)
X=
x1Tx2T⋮xnT
y=
y1Ty2T⋮ynT
⇒k=1∑n(xkTθk−yk)2=(Xθ−y)T(Xθ−y)
优化问题变为:
arg
min
θ
(
X
θ
−
y
)
T
(
X
θ
−
y
)
.
s
.
t
.
∣
∣
θ
∣
∣
2
2
=
θ
T
θ
≤
r
\underset{\theta}{\arg \min}(X\theta-y)^T(X\theta-y). \quad s.t.||\theta||_2^2 =\theta^T\theta\leq r
θargmin(Xθ−y)T(Xθ−y).s.t.∣∣θ∣∣22=θTθ≤r我们的求解策略是熟悉的拉格朗日乘子:
L
(
θ
,
λ
)
=
(
X
θ
−
y
)
T
(
X
θ
−
y
)
+
λ
(
θ
T
θ
−
r
)
.
L(\theta, \lambda) = (X\theta-y)^T(X\theta-y) + \lambda(\theta^T\theta-r).
L(θ,λ)=(Xθ−y)T(Xθ−y)+λ(θTθ−r). 计算偏导:
∇
θ
L
(
θ
,
λ
)
=
∇
θ
(
θ
T
X
T
X
θ
−
y
T
X
θ
−
θ
T
X
T
y
+
y
T
y
+
λ
θ
T
θ
−
λ
r
)
\nabla_{\theta}L(\theta,\lambda)=\nabla_{\theta}(\theta^TX^TX\theta-y^TX\theta-\theta^T X^T y+y^Ty+ \lambda \theta^T\theta-\lambda r)
∇θL(θ,λ)=∇θ(θTXTXθ−yTXθ−θTXTy+yTy+λθTθ−λr)
=
2
X
T
X
θ
−
x
T
y
−
X
T
y
+
2
λ
θ
=
0
=2X^TX\theta-x^Ty-X^Ty+2\lambda \theta=0
=2XTXθ−xTy−XTy+2λθ=0
⇒
θ
=
(
X
T
X
+
λ
I
)
−
1
X
T
y
\Rightarrow\theta=(X^TX+\lambda I)^{-1}X^Ty
⇒θ=(XTX+λI)−1XTy
矩阵向量求导补充知识:
- ∇ θ ( θ T A θ ) = ( A + A T ) θ \nabla_{\theta}(\theta^T A\theta) = (A+A^T)\theta ∇θ(θTAθ)=(A+AT)θ
- ∇ θ ( A θ ) = A T \nabla_{\theta}(A\theta) = A^T ∇θ(Aθ)=AT
- ∇ θ ( θ T A ) = A \nabla_{\theta}(\theta^TA) = A ∇θ(θTA)=A
相比于我们熟悉的最小二乘解: θ OLS = ( X T X ) − 1 X T y \theta_{\text{OLS}}=(X^TX)^{-1}X^Ty θOLS=(XTX)−1XTy,差距在哪?加上的 λ I \lambda I λI这一部分,在信号处理里面叫做对角加载技术(Diagonal Loading),主要是为了解决这个 X X X缺秩的问题,正常 X T X X^TX XTX想要求逆的话, X X X必须得是列满秩,否则你的数值稳定性大打折扣,你这个逆可能逆出很大的数,在信号处理里头,你一看到很大的数,你心里就要紧张,因为那多半是算的有问题,即便不是算错,也是处在数值稳定性相当糟糕的这么一个区域内,因此我们希望把他平移下来。我们不希望看到很大的数,和我们的正则化有着异曲同工的地方:我们选择直接在对角线上进行扰动,你这一扰动,矩阵的条件数马上就好了。只不过对角加载的基本想法是从数值稳定性出发的,并不是从我们的正则化出发的。我们这里正则化主要是为了想让模型更简单,从而让整体具有比较好的泛化特性。两个角度,得到的结果是一致的。一个是数值稳定性,一个是推广能力;一个涉及到的是怎么让我们的计算的结果不产生巨大的波动,一个涉及到的是我们怎么样让我们估计的结果方差能够变小。但是两者最终汇聚到的是同一个点。都是做这么一个工作,非常有意思,并且这一个点,还会被另外的方向汇聚到,我们待会就知道了。
强烈建议大家去学矩阵论,如果你想做和信号处理相关的研究工作的话,你上三门课就够了:矩阵论、随机过程还有现代信号处理,有必要的话,再去听一门优化课,特别是凸优化。就齐活了。
现在我们要仔细地看一眼,我们这一加一定牺牲掉什么了,最小二乘解是无偏的,可是你加上这一项一定有偏,恰如我们tradeoff说的一样,我们把偏差牺牲掉了 ,我们要的是方差变小。我们要习惯偏差的损失,因为方差的损失你承受起来更重。
我们下面引入一种工具:奇异值分解(SVD:Singular Value Decomposition)它是一个十分重要的矩阵计算技术,其重要性在信号处理里头特别得到彰显。因为矩阵分解这一直是我们学习线性代数的理想,我们为什么希望能够做矩阵分解,是因为矩阵这个元素,我们操作起来感觉很不方便,我们之所以感觉很不方便的原因很简单,是因为矩阵多数情况下不是对角阵。如果是对角阵,那我们操作起来是不是方便多了:矩阵相乘就是对角元之间相乘就行了,矩阵乘矢量就是对角线元跟矢量直接乘就行了。你操作起来方便多了。我们想尽各种办法,来让我们的矩阵可以通过某种分解得到对角阵,人们为了能够做到这一点,事实上认识是在不断依次逼近的
-
如果矩阵是对称的,一定可以做分解:
A = A T ⇒ A = U Λ U T = ∑ k = 1 n λ U k U k T U U T = U T U = I , Λ = d i a g ( λ 1 , λ 2 , . . . , λ n ) A=A^T\Rightarrow A=U\Lambda U^T=\sum_{k=1}^n \lambda U_kU_k^T \\UU^T=U^TU=I,\quad \Lambda=diag(\lambda_1,\lambda_2,...,\lambda_n) A=AT⇒A=UΛUT=k=1∑nλUkUkTUUT=UTU=I,Λ=diag(λ1,λ2,...,λn) -
如果矩阵是正规阵(Normal): A A T = A T A ⇒ A = U − 1 Λ U AA^T=A^TA \Rightarrow A = U^{-1}\Lambda U AAT=ATA⇒A=U−1ΛU 注意: Λ \Lambda Λ依然是对角阵,但是U的正交性没了取而代之的是求逆,这里比对称阵更加的一般
-
对于通常意义上的方阵,只能是分块对角: A = U − 1 Λ U , Λ = ( J 1 ⋱ J k ) A=U^{-1}\Lambda U ,\quad \Lambda =\begin{pmatrix} J_1 & \\ & \ddots &\\ & & J_k \end{pmatrix} A=U−1ΛU,Λ= J1⋱Jk 每一个块都有: J k = ( J 1 1 ⋱ ⋱ 1 J k ) J_k=\begin{pmatrix} J_1 & \\ 1& \ddots &\\ & \ddots 1&J_k \\ \end{pmatrix} Jk= J11⋱⋱1Jk 这个叫若当型标准型(Jordan Canonical Form) J k 称为Jordan Block J_k称为\text{Jordan Block} Jk称为Jordan Block(若当采用的是法语音,是个法国人)。
我们可以看到随着我们不断地往回退,矩阵的要求不断地放松,我们对角化的成果也就不断地模糊起来了,从最开始的合同变换,到相似变换,到没法再做真正意义上的对角化。
这时候我们的奇异值分解终于要登场了,奇异值分解是对上述结果的一个本质性的推进,因为他可以应用于非方阵: A ∈ R m × n ⇒ A = U Σ V T A\in R^{m \times n}\Rightarrow A=U\Sigma V^T A∈Rm×n⇒A=UΣVT 由于此时我的U和V彻底地脱离了关系(前面的分解里头,U和后面的“V”他们的关系是极端密切的,要么互为转置,要么互为逆,现在我把两者的关系彻底割裂开,一下子自由度就重新回来了)所以我的U和V性质都可以非常好:他们都是正交的: U T U = U U T = I , V V T = V T V = I U^TU=UU^T=I , VV^T=V^TV=I UTU=UUT=I,VVT=VTV=I。 Σ = ( Λ 0 0 0 ) Λ is diagonal \Sigma=\begin{pmatrix} \Lambda &0 \\ 0 & 0 \\ \end{pmatrix} \Lambda \text{ is diagonal} Σ=(Λ000)Λ is diagonal
我们对于矩阵分解的追求来源于我们希望处理对角阵的一种原始的期望,那么我们在追求矩阵分解的过程当中,我们对矩阵的要求是在不断放松的,因此我们能够拿到的矩阵分解的结果事实上也是在不断恶化的,但是到了奇异值分解这突然有了一个反转,就是因为我们把整体的要求放松了,即,前后两个矩阵不做关联。尽管前后两个矩阵没有关联,但是奇异值分解仍然是相当好用。
我们从θ的这个解开始说起: θ R i d g e = ( X T X + λ I ) − 1 X T y ,Ridge(岭) Regression \theta_{Ridge}=(X^TX+\lambda I)^{-1}X^Ty ,\text{Ridge(岭) Regression} θRidge=(XTX+λI)−1XTy,Ridge(岭) Regression直观地理解,就好像把对角的山脊给抬起来了一样。假定X是列满秩的: Σ = ( Λ 0 ) ⇒ Σ T Σ = Λ 2 \Sigma=\binom{\Lambda}{0} \Rightarrow \Sigma^T\Sigma = \Lambda^2 Σ=(0Λ)⇒ΣTΣ=Λ2奇异值分解: X = U Σ V T X=U\Sigma V^T X=UΣVT ⇒ X T X = V Σ T U T U Σ V T = V Σ T Σ V T = V Λ 2 V T \Rightarrow X^TX=V\Sigma^T U^TU\Sigma V^T = V\Sigma^T\Sigma V^T = V\Lambda^2V^T ⇒XTX=VΣTUTUΣVT=VΣTΣVT=VΛ2VT ⇒ ( X T X + λ I ) − 1 = V ( Λ 2 + λ I ) − 1 V T \Rightarrow(X^TX +\lambda I)^{-1} = V(\Lambda^2+\lambda I)^{-1}V^T ⇒(XTX+λI)−1=V(Λ2+λI)−1VT ⇒ ( X T X + λ I ) − 1 X T y = V ( Λ 2 + λ I ) − 1 V T V Σ T U T y \Rightarrow(X^TX +\lambda I)^{-1}X^Ty = V(\Lambda^2+\lambda I)^{-1}V^TV\Sigma^T U^Ty ⇒(XTX+λI)−1XTy=V(Λ2+λI)−1VTVΣTUTy = V ( Λ 2 + λ I ) − 1 Σ T U T y = V(\Lambda^2+\lambda I)^{-1}\Sigma^T U^Ty =V(Λ2+λI)−1ΣTUTy
我们令 θ ∼ R i d g e = V T θ R i d g e , y ∼ = U T y 于是 θ ∼ R i d g e = ( Λ 2 + λ I ) − 1 ( Λ 0 ) y ∼ 我们令\stackrel{\sim}{\theta}_{Ridge} = V^T\theta_{Ridge},\quad \stackrel{\sim}{y}=U^Ty \\ 于是\stackrel{\sim}{\theta}_{Ridge} = (\Lambda^2+\lambda I)^{-1}(\Lambda \quad0) \stackrel{\sim}{y} 我们令θ∼Ridge=VTθRidge,y∼=UTy于是θ∼Ridge=(Λ2+λI)−1(Λ0)y∼我们对于参数的每一维,来仔细看一下这件事情: ⇒ θ ∼ R i d g e ( i ) = λ i λ i 2 + λ ⋅ y ∼ , ( i = 1 , . . . , m , m < n ) \Rightarrow \stackrel{\sim}{\theta}_{Ridge}(i) = \frac{\lambda_i}{\lambda_i^2+\lambda}·\stackrel{\sim}{y} ,\ (i = 1,...,m,m<n) ⇒θ∼Ridge(i)=λi2+λλi⋅y∼, (i=1,...,m,m<n)
我们重点看 λ i λ i 2 + λ \frac{\lambda_i}{\lambda_i^2+\lambda} λi2+λλi,这个 λ \lambda λ作为我们正则化的参数它所起的作用:如果 λ = 0 ,就变成 λ i y λ i 2 \lambda=0,就变成\frac{\lambda_i y}{\lambda_i^2} λ=0,就变成λi2λiy,这不就是分母是个归一化,分子在相关的标准的最小二乘吗?那么这说明标准的最小二乘在经过了坐标变换的前提下(我们引入了SVD,SVD其实就是再做坐标变换)它本质上就是我们熟悉的这个结果。其实 ( X T X ) − 1 X T y (X^TX)^{-1}X^Ty (XTX)−1XTy形式上跟它一模一样。另外有一个小细节,为什么这里分子分母的 λ i \lambda_i λi没被消掉?回到一开始因为我们这里假设先抛开期望计算不谈,但原本他是要求期望的: E ( λ i y ) E ( λ i 2 ) \frac{E(\lambda_i y)}{E(\lambda_i^2)} E(λi2)E(λiy)
现在分母加入了 λ \lambda λ,看极端情况,如果 λ \lambda λ特别大的时候,θ值与这些 λ i 、 y i ∼ \lambda_i、\stackrel{\sim}{y_i} λi、yi∼们关系就不大了:是因为我们的拉格朗日里面 λ \lambda λ相当于一个权重: ( X θ − y ) T ( X θ − y ) + λ ( θ T θ − r ) . (X\theta-y)^T(X\theta-y) + \lambda(\theta^T\theta-r). (Xθ−y)T(Xθ−y)+λ(θTθ−r).在目标函数里面,如果 λ \lambda λ巨大无比,那么前面一项基本上是无关紧要的。当 λ \lambda λ越来越大的时候,θ的每一个权值就慢慢趋同了。
如果 λ i \lambda_i λi比较大, λ \lambda λ的作用还不明显,如果 λ i \lambda_i λi比较小,意味着这些个分量在X当中并不反映X的主导信息,也不反应X的显著特征,他们就不是特别重要,很有可能就是一些噪声。而如果 λ i \lambda_i λi很小, λ i 2 \lambda_i^2 λi2更小,然后平方是放在分母上。他就会导致这个 θ i \theta_i θi值特别大,由于均方意义下的线性估计自身的特点,导致了我的模型反而对你很重视!而原本我们希望应当忽略它才对!这时候 λ \lambda λ就起到了正则化的明显作用!
换句话说,当我们在研究均方意义下的线性估计的时候,发现我们真正求的这个线性系数,它比较大。那么按照你的想象,他应该比较重要,反应的是比较重要的特征才对。错了,真未必!他的值很大,只能说明你计算的这个结果很大,而且很有可能是因为这个 λ i \lambda_i λi比较小造成的。我们必须要通过调参来把这种事消除掉。正则化就是一种很聪明的调参:通过 λ \lambda λ的合理确定是可以有效的克服数据当中存在的这种问题所导致的我们系数计算出现的偏差。为了让大家看到这一点,我们才引入了奇异值分解。因为只有你看到了这一点,你才能真正把正则化理解到位,至少把Tikhonov这个正则化理解到位。
LASSO
好,现在我们来说,Tikhonov正则化并不是唯一的正则化。你要想把参数变小,二范数只是选择之一。我们可以选择一范数:就是把绝对值加起来: ∣ ∣ θ ∣ ∣ 1 = ∑ k = 1 n ∣ θ k ∣ ≤ r ( LASSO ) ||\theta||_1 = \sum_{k=1}^n|\theta_k|\leq r \quad (\text{LASSO}) ∣∣θ∣∣1=k=1∑n∣θk∣≤r(LASSO) Least Absolute Shrinkage Selection Operation。发明人是:Tibshrani 1996年。想理解清楚LASSO,我们需要引入凸分析。这个放到之后再讲。但是今天我们可以从一个非常有趣的角度来对LASSO算法产生一点初步的认识:
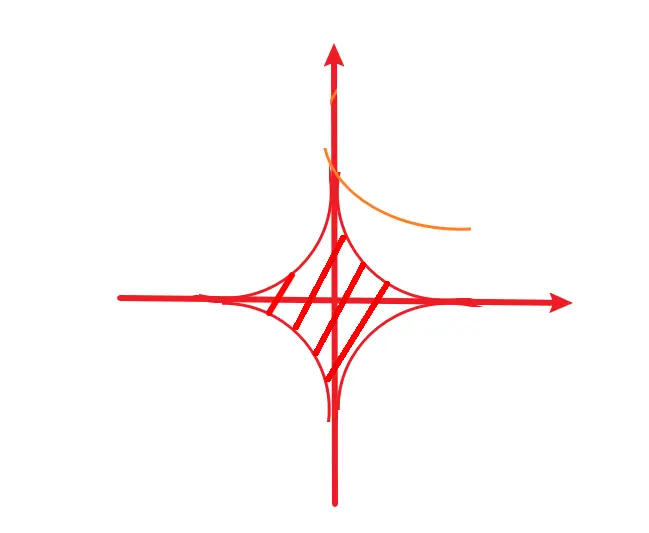
假设θ是两维的: θ = ( θ 1 , θ 2 ) \theta=(\theta_1, \theta_2) θ=(θ1,θ2),与此同时,我们的目标函数关于θ是一个二次曲线。一般情况下,可行域是个圆(二范数)所以优化过程中,二次曲线平移的时候,跟我可行域碰到的位置,肯定是比较随意的。并没有什么特殊。这是Tikonov所设想的场景:

我们再来看看LASSO(一范数)面临的可行域:可以发现,二次曲线很容易碰到坐标轴上的点,而坐标轴上的点,对应着什么含义?它对应的就是稀疏。因此LASSO是会导致稀疏解的。所以LASSO的优化结果可以从另一个角度看:它是对我们这个模型各个分量进行了一个选择(Selection)。

我们没有刻意的谈到过变量选择问题,是因为我们并没有对变量的重要性做过认真的评估,你做线性的模型,你相当于是用θ这样的系数去组合了一堆元素,做线性组合,那么这些元素哪些是重要的,那些是次要的,如何进行评估?如果你能够对这件事有所评估的话,肯定大大有利于你的模型构建,因为可以略去次要的。但是你这样的评估单独做肯定又是一番负担。而LASSO就非常好,他直接替你做了。因为优化出来的结果就已经选择过了,他是稀疏的。因此,LASSO在机器学习里头受到充分重视不是没有理由的。他是自动地完成了选择(Automatic)。
还有人把LASSO和Tikonov正则化放到一起搞: α ∣ ∣ θ ∣ ∣ 2 + β ∣ ∣ θ ∣ ∣ 1 \alpha||\theta||_2+\beta||\theta||_1 α∣∣θ∣∣2+β∣∣θ∣∣1。还有个特别好听的名:弹性网格(Elastic Net)
甚至还有这样的正则化,更加强化稀疏性,选择特征更加明朗。相当于
∣
∣
θ
∣
∣
q
,
q
≤
1
||\theta||_q,\quad q\leq 1
∣∣θ∣∣q,q≤1。但是这玩意不凸。1次模是凸的底线,而它是非凸的,优化起来很难搞。现实的意义价值并不大,个人认为。
其实正则化除了控制系数大小这个作用以外,还有别的的用途(这类正则化有一个统一的名字叫Weight Decay)。正则化是一种思想,通过对某些因素进行控制来达成我们的目的。这里的正则化是为了减小我们模型的方差。微分方程里头其实也有正则化这一说法,它的正则化是为了让我们的解变得更加锁死,更加的光滑,他也把这个叫做正则化。所以正则化的思想是一种非常宽泛的思想,千万不要把他看得太过狭窄。这里再说两种正则化思想:
Dropout
CNN的训练里面有一种叫Dropout。你在训练的时候不是老收敛不了吗?或者说你很快就收敛了(不要觉得收敛了是好事,那一般是局部极小值或者是overfit了),所以你为了能够保持一种弹性,随机地选取一部分节点跟weight,把他们从网络里扔掉。练一会就扔一些,练一会就扔一些,别舍不得,扔掉更有助于健康。Dropout这篇2015年的文章到现在被引用一万多次了,尽管显得有一些没理论,甚至显得有一些没道理,但是真的是好用,每一个像Tensorflow,Pytorch这样的深度学习框架里面都有Dropout。那他到底是在干什么?他是在随机地做Selection。为什么他在形式上不能表现得Formal一点呢?原因很简单,神经网络他是一个复杂的非线性体系。比如说他有这个activation function,然后还有Pooling…所以它里面的非线性操作非常多。在那么多非线性的操作下,你完全没有办法能写一个正儿八经的看得清楚的目标函数和正则化约束,完全做不到。所以它能有效果就不错了。
噪声注入
还有一种是做活体检测:这在刷脸支付里非常重要(要不然照片就能骗过它的话,那还得了啊)。如何识别熊猫图案和印着熊猫的布:有人在熊猫图案上弄了点噪声(胡椒面噪声)立马就识别成布了,这意味着你在刷脸的时候光线得要特别好,如果光线不好,信噪比就下降,在暗处胡椒面噪声的特性是非常强的,那么你就有可能识别成照片。如果真的识别成照片,那就说明它根本没有活体检测能力。那如果我们想避免熊猫的这个错误,我们可以怎么办?有一个很常见的技术,叫噪声注入(Noise Injection)。我有意给其中的一部分熊猫的照片加上噪声。我要让那个机器知道,加上噪声的这些图片仍然是熊猫,让他刻意的去注意到加进去的这个噪声和那个布所呈现的纹理是有差异的。可以把这种差异给强化出来。大家注意:噪声注入和我们今天说的Tikhnov 正则化: ( X T X + λ I ) − 1 X T y (X^TX+\lambda I)^{-1}X^Ty (XTX+λI)−1XTy之间有着奇妙的联系:Tikhnov本身就是噪声注入!你的 λ I \lambda I λI就是白噪声的相关阵。所以,你本质上是在用 X ∼ = X + ε 来取代 X 进行训练 \stackrel{\sim}{X} = X+\varepsilon来取代X进行训练 X∼=X+ε来取代X进行训练 ⇒ X ∼ T X ∼ = X T X + ε T ε \Rightarrow \stackrel{\sim}{X }^T\stackrel{\sim}{X} = X^TX + \varepsilon^T \varepsilon ⇒X∼TX∼=XTX+εTε
我们之前说过了,我们还可以从另外一个角度理解Tikhnov 正则化。我们不但认为他是个正则化,或者对角加载,我们还可以认为他就是噪声注入。因此反过来说,噪声注入我们是可以通过今天所建立起来的理论进行理解跟认识的。相比于Dropout。噪声注入的理论基础还更加的坚实一点,因为他可以认为是我们Tikhnov正则化的一个非常自然的延伸。
好了,总结一下,正则化对于我们做好一个估计是非常关键的。大家无论是在信号处理还是机器学习的各个领域都能看到正则化的影子。希望大家能够很好地领会正则化的思想并且在今后的学习工作中加以应用。