清华大学驭风计划课程链接
学堂在线 - 精品在线课程学习平台 (xuetangx.com)
代码和报告均为本人自己实现(实验满分),此次代码开源大家可以自行参考学习
有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~
一、案例简介¶
随着电商平台的兴起,以及疫情的持续影响,线上购物在我们的日常生活中扮演着越来越重要的角色。在进行线上商品挑选时,评论往往是我们十分关注的一个方面。然而目前电商网站的评论质量参差不齐,甚至有水军刷好评或者恶意差评的情况出现,严重影响了顾客的购物体验。因此,对于评论质量的预测成为电商平台越来越关注的话题,如果能自动对评论质量进行评估,就能根据预测结果避免展现低质量的评论。本案例中我们将基于集成学习的方法对 Amazon 现实场景中的评论质量进行预测。
二、作业说明
本案例中需要大家完成两种集成学习算法的实现(Bagging、AdaBoost.M1),其中基分类器要求使用 SVM 和决策树两种,因此,一共需要对比四组结果(AUC 作为评价指标):
-
Bagging + SVM
-
Bagging + 决策树
-
AdaBoost.M1 + SVM
-
AdaBoost.M1 + 决策树
注意集成学习的核心算法需要手动进行实现,基分类器可以调库。
基本要求
-
根据数据格式设计特征的表示
-
汇报不同组合下得到的 AUC
-
结合不同集成学习算法的特点分析结果之间的差异
-
(使用 sklearn 等第三方库的集成学习算法会酌情扣分)
扩展要求
-
尝试其他基分类器(如 k-NN、朴素贝叶斯)
-
分析不同特征的影响
-
分析集成学习算法参数的影响
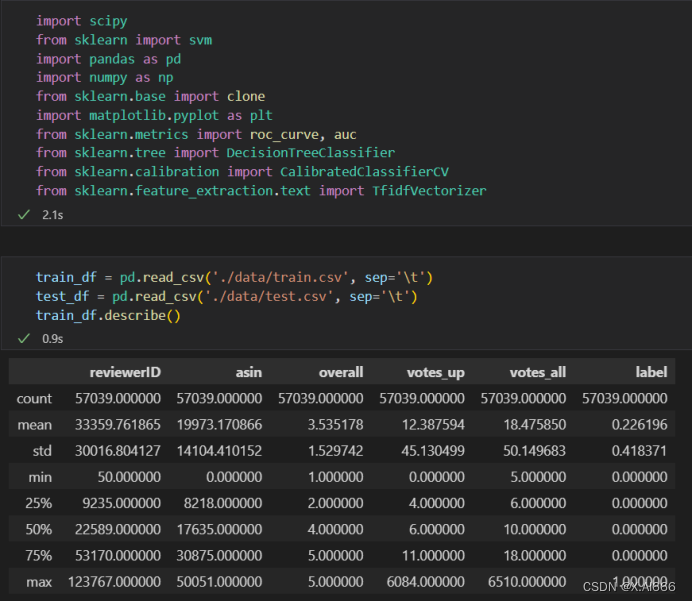
本次数据来源于 Amazon 电商平台,包含超过 50,000 条用户在购买商品后留下的评论,各列的含义如下:
* reviewerID:用户 ID
* asin:商品 ID
* reviewText:英文评论文本
* overall:用户对商品的打分(1-5)
* votes_up:认为评论有用的点赞数(只在训练集出现)
* votes_all:该评论得到的总评价数(只在训练集出现)
* label:评论质量的 label,1 表示高质量,0 表示低质量(只在训练集出现)
评论质量的 label 来自于其他用户对评论的 votes,votes_up/votes_all ≥ 0.9 的作为高质量评论。此外测试集包含一个额外的列 ID,标识了每一个测试的样例。
三, 实验结果
在处理文本特征时候我也有尝试引入其他特征,比如评论长度,情感浓度,但是发现训练的效果反而更差,所以最终没有引入新的特征,在这里也尝试过Countvectorizer方法,最终会使得预测效果变差不少,最终使用TfidfVectorizer发现效果好很多。在这里也使用了稀疏数组的拼接方法,很适合大规模文本数据。
# 处理文本特征
vectorize_model = TfidfVectorizer(stop_words='english')
train_X = vectorize_model.fit_transform(train_df['reviewText'])
test_X = vectorize_model.transform(test_df['reviewText'])
# 合并上总评分特征
train_X = scipy.sparse.hstack([train_X, train_df['overall'].values.reshape((-1, 1)) / 5])
test_X = scipy.sparse.hstack([test_X, test_df['overall'].values.reshape((-1, 1)) / 5])
train_X.shape,train_df['label'].shape((57039, 153748), (57039,))
def selection_clf(base_name):
clf = None
if base_name == 'SVM':
base_clf = svm.LinearSVC()
clf = CalibratedClassifierCV(base_clf, cv=2, method='sigmoid')
elif base_name == 'DTree':
clf = DecisionTreeClassifier(max_depth=10, class_weight='balanced')
return clf
class Bagging:
def __init__(self, base_estimator, num_estimators):
self.base_estimator = base_estimator # 基分类器对象
self.num_estimators = num_estimators # Bagging 的分类器个数
def fit_predict(self, X_train, y_train, X_test):
num_samples = X_train.shape[0]
num_features = X_train.shape[1]
result = np.zeros(X_test.shape[0]) # 记录测试集的预测结果
for i in range(self.num_estimators):
sample_indices = np.random.choice(num_samples, size=num_samples, replace=True) # Bootstrap
sample_X = X_train[sample_indices]
sample_y = y_train[sample_indices]
estimator = clone(self.base_estimator) # 克隆基分类器
estimator.fit(sample_X, sample_y)
print(f"模型 {i+1:2d} 完成!")
predict_proba = estimator.predict_proba(X_test)[:, 1]
result += predict_proba # 累加不同分类器的预测概率
result /= self.num_estimators # 取平均(投票)
return result
class AdaBoostM1(object):
def __init__(self, base_estimator, num_iter):
self.base_estimator = base_estimator # 基础分类器对象
self.num_iter = num_iter # 迭代次数
def fit_predict(self, X_train, y_train, X_test):
result_lst, beta_lst = [], [] # 记录每次迭代的预测结果和投票权重
num_samples = len(y_train)
weights = np.ones(num_samples) # 样本权重,注意总和应为 num_samples
for i in range(self.num_iter):
self.base_estimator.fit(X_train, y_train, sample_weight=weights) # 带权重的训练
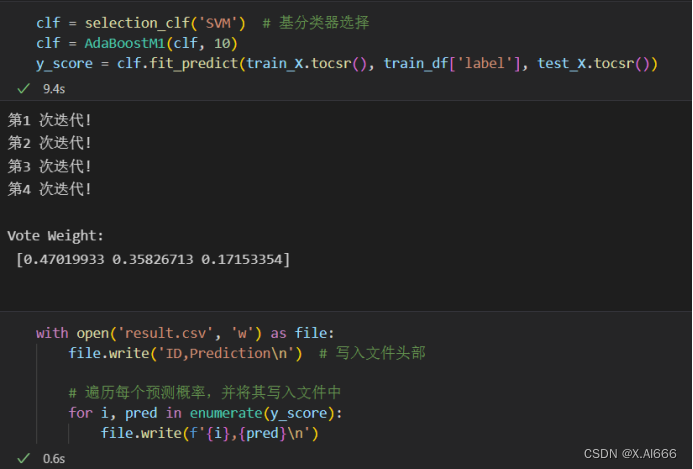
print('第{:<2d}次迭代!'.format(i+1))
train_predictions = self.base_estimator.predict(X_train) # 训练集预测结果
misclassified = train_predictions != y_train
error = np.sum(weights[misclassified]) / num_samples
if error > 0.5:
break
beta = error / (1 - error)
weights = weights * (1 - misclassified) * beta + weights * misclassified
weights /= np.sum(weights) / num_samples # 归一化,使权重和等于 num_samples
beta_lst.append(beta)
test_predictions = self.base_estimator.predict_proba(X_test)[:, 1] # 测试集预测概率
result_lst.append(test_predictions)
beta_lst = np.log(1 / np.array(beta_lst))
beta_lst /= np.sum(beta_lst) # 归一化投票权重
print('\nVote Weight:\n', beta_lst)
result = np.sum(np.array(result_lst) * beta_lst[:, None], axis=0)
return resultfrom sklearn.model_selection import train_test_split
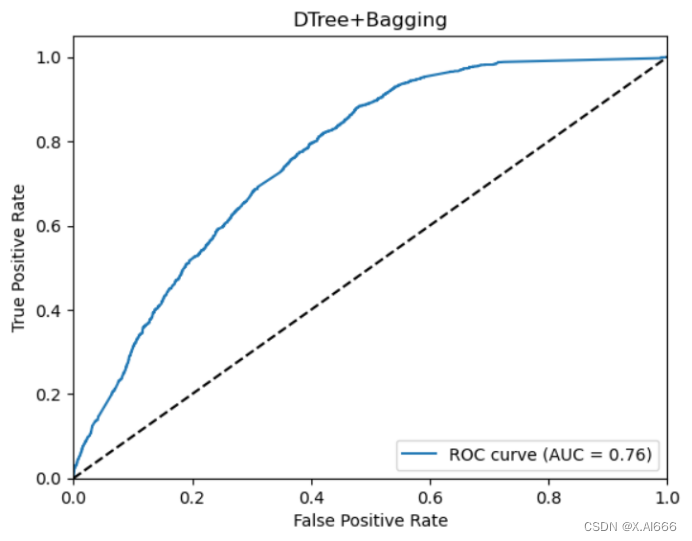
X_train, x_test, y_train, y_test = train_test_split(train_X, train_df['label'], test_size=0.14, random_state=42, shuffle=True)在训练的时候也发现bagging算法要是使用直接划分的数据集会出错,所以我用了直接切片的方法就运行成功了。通过4种组合看出,svm+adaboostm1的组合auc成绩最高,在bagging算法在此次运行中不如adaboostm1的效果好。
clf = selection_clf('SVM') # 基分类器选择
clf = Bagging(clf, 10)
y_score = clf.fit_predict(train_X.tocsr()[:50000], train_df['label'][:50000], train_X.tocsr()[50000:57039])
# 计算ROC曲线和AUC
fpr, tpr, thresholds = roc_curve(train_df['label'][50000:57039], y_score)
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.plot(fpr, tpr, label='ROC curve (AUC = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--') # 绘制对角线
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('SVM+Bagging')
plt.legend(loc="lower right")
plt.show()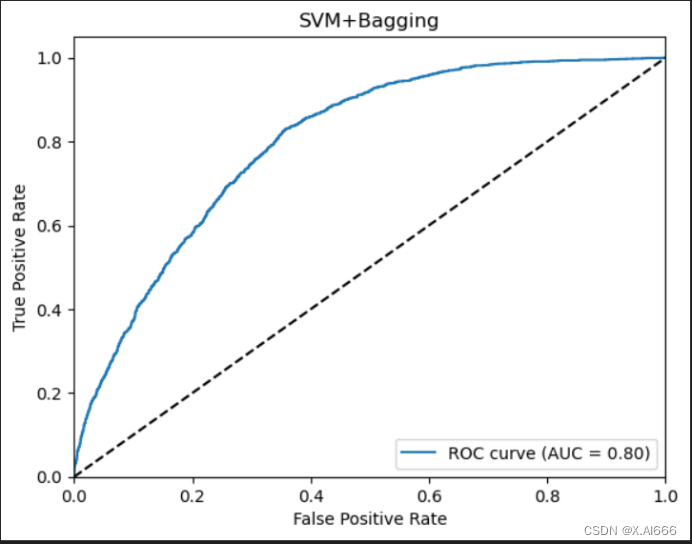

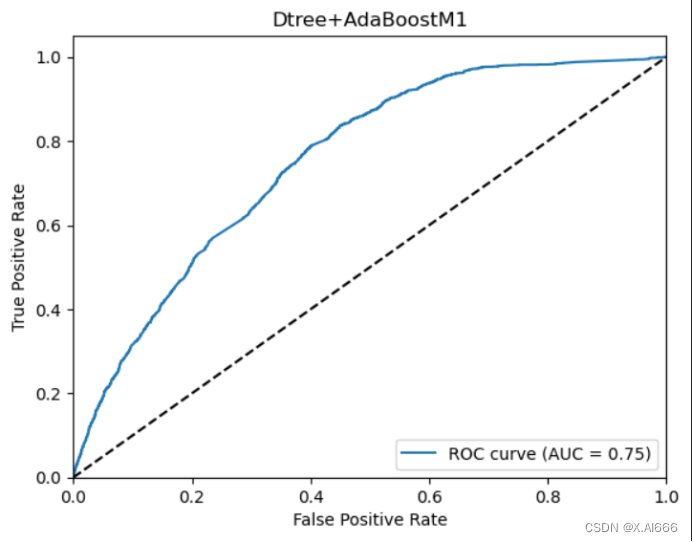
最终选择选择效果最好的svm+adaboostm1进行预测,最终写入文件。