目录
- 一、任务概述
- 二、Django微服务开发
- 2.1 创建项目
- 2.1.1 创建Django项目
- 2.1.2 创建主页面
- 2.1.3 编写视图处理函数
- 2.1.4 配置访问路由url
- 2.1.5 启动项目
- 2.2 前端开发
- 2.2.1 集成Bootstrap5
- 2.2.2 初始化各组件
- 2.2.3 自适应展示图像
- 2.2.4 橡皮擦涂抹
- 2.2.5 使用Ajax传输图像
- 2.3 后端开发
- 三、照片修复
- 3.1 算法原理
- 3.1.1 图像修复概述
- 3.1.2 DeepFillV2算法
- 3.2 算法测试
- 3.3 算法集成
- 四、总结
- 参考文献
一、任务概述
在当今时代,人工智能和深度学习已经成为了科技领域的热门话题。随着这些技术的发展,越来越多的行业开始尝试将人工智能和深度学习应用于解决实际问题。在这种背景下,Django技术和人工智能的结合成为了当下一种流行的解决方案。
Django是一个基于Python的Web框架,而深度学习是人工智能的重要分支,将深度学习技术应用于Django框架中,可以快速构建出轻量、智能的Web应用。
使用Django来集成深度学习技术具有两个显著优势:
- 语言迁移成本低:Django框架本身基于Python开发,可以方便地与其他人工智能Python框架进行集成,降低了开发的难度和成本。
- 可扩展性强:Django框架支持丰富的插件和第三方库,可以轻松地扩展功能,满足不断变化的应用需求,方便维护和扩展。
在日常生活中,遇到一些美景会自然的拿起手机进行拍照,但在照片拍摄过程中,往往会混入不协调的干扰物。比如在景区中繁华的人流,导致难以获得背景干净的照片。这时候就希望有一款工具能够将不想要的物体擦除掉,使得修复后的照片看上去就好像没有出现过这个干扰物一样。为此,本文将采用Django框架来开发一款这样的线上AI应用,帮助用户对自己的照片进行局部修复。
具体实现效果如下图所示:

最左边是原图,中间是由用户使用画刷画出的想要擦除掉的区域,最右一张图是通过智能算法自动将涂抹的区域擦除掉。可以看到修复后的照片其涂抹区域已经被AI算法自动填充了,并且填充效果非常自然,几乎看不出明显的修复痕迹。
本文开发环境如下:
- 操作系统:Windows10。
- Python版本:3.11.8
- Django版本:5.0.2
- torch版本:1.8.0 (CPU版)
注意:在进入下面的内容学习前,请读者先按照上述开发环境安装好各版本软件。
二、Django微服务开发
2.1 创建项目
2.1.1 创建Django项目
首先创建一个名为eraser的django项目:
django-admin startproject eraser
然后在eraser项目下创建一个主应用:
cd eraser
python manage.py startapp app
打开eraser子文件夹中的settings.py文件,找到INSTALLED_APPS字段,然后在该字段末尾添加一行代码将app应用包含进来即可:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app', # 新添加应用
]
接下来制作访问页面。首先在创建的app文件夹下创建一个templates文件夹用来存放网站页面。具体的,在app文件夹下新建一个文件夹,命名为templates。然后在templates文件夹下新建一个文件,文件命名为index.html。最终完整的项目目录结构如下图所示:

2.1.2 创建主页面
打开index.html文件,在该文件中输入下面的代码:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8" />
<title>我的第一个页面</title>
</head>
<body>
<h1>欢迎</h1>
</body>
</html>
这是一个最基本的Web页面,在该页面中指定了页面的标题为“我的第一个页面”,页面内容显示“欢迎”字样。
2.1.3 编写视图处理函数
使用django进行web访问的的基本流程如下:
- 用户在浏览器中输入网址(http://127.0.0.1:8000)访问eraser网站;
- 服务器收到浏览器发来的访问请求,解析请求后根据urls.py文件中定义好的路由,在views.py文件中找到对应的访问处理函数;
- 访问处理函数开始处理请求,然后返回用户想要浏览的网页内容。
本小节按照上述流程开始编写视图处理函数。打开app应用下的views.py文件,编辑代码如下:
from django.shortcuts import render
# 创建视图处理函数
def home(request):
return render(request, 'index.html')
上述代码第一行引入了Django提供的渲染页面的函数render,然后定义了一个home函数,该函数有一个参数request,这个参数就是用户的请求参数,该参数封装了用户的所有请求信息,这里暂时对它不作处理。home函数收到请求后返回index.html页面内容。
2.1.4 配置访问路由url
earser子文件夹下的urls.py文件用来绑定每个访问请求对应的处理函数。其中,urlpatterns即为配置访问路由的字段。接下来对urls.py文件进行编辑,使得访问根网址时即可返回index.html页面。具体编辑代码如下:
from django.contrib import admin
from django.urls import path
from app.views import home # 导入新添加的视图函数
urlpatterns = [
path('admin/', admin.site.urls),
path('', home, name='home'), # 添加新的路由
]
2.1.5 启动项目
在终端中输入下面的命令启动项目:
python manage.py runserver
默认启动页面网址为http://127.0.0.1:8000。启动成功后即可采用浏览器进行访问。效果如下图所示:

到这里,基本的django项目框架已经搭建完毕。
2.2 前端开发
本节内容来设计具体的前端页面,主要通过js来实现图像加载、橡皮擦涂抹等功能。考虑到样式美观,本文使用bootstrap5的相关组件来实现页面元素设计。
2.2.1 集成Bootstrap5
重新编辑index.html页面,代码如下:
<!doctype html>
<html lang="ch">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>照片在线修复</title>
<!-- 导入bootstrap -->
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/js/bootstrap.bundle.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/jquery@1.12.4/dist/jquery.min.js"></script>
</head>
<body>
<div class="container">
<br>
<!-- 照片上传控件 -->
<div class="row">
<div class="offset-md-3 col-md-6 d-flex justify-content-center">
<input class="form-control" type="file" id="photo_file" accept="image/*">
</div>
</div>
<div>
</body>
</html>
上述代码在head部分导入了Bootstrap5的相关引用,这样就可以在页面中使用Bootstrap5的相关组件和样式了。在body部分定义了一个用于照片上传的组件,重新运行项目后样式如下:

2.2.2 初始化各组件
本小节继续完善页面。具体的,包括一个画布组件、一个画刷组件和一个按钮组件,代码如下:
<!-- 画板 -->
<div class="row">
<div class="d-flex justify-content-center">
<!-- 作图画板 -->
<canvas id="photo_canvas"></canvas>
<!-- 掩码图画板(不可见) -->
<canvas id="mask_canvas" style="display:none"></canvas>
<!-- 原始图像画板()不可见 -->
<canvas id="org_canvas" style="display:none"></canvas>
</div>
</div>
<br>
<!-- 工具栏控件 -->
<div class="row">
<div class="offset-md-3 col-md-4">
<label class="form-label">画笔粗细</label>
<input type="range" class="form-range" min="1" max="40" id="paint_range">
</div>
<div class="offset-md-1 col-md-4">
<button type="button" id="btnProcess" class="btn btn-success">修复</button>
</div>
</div>
注意到在定义画板canvas时一共定义了3个,其中1个用来在原图上涂抹,1个用来记录涂抹的痕迹,1个用来保存涂抹前的原图状态。后两个画板并不显示,一直处于隐藏状态。用来记录涂抹痕迹的画板后续将用来生成二值掩码图。所谓二值掩码图,就是将需要涂抹的区域全部设置为纯白色,而没有涂抹的区域设置为纯黑色。如下图所示:

上图中,最左边是原图,中间是由用户使用白色画刷涂抹后的图像,最右边是根据用户的涂抹区域所获取到的二值掩码图。
之所以额外定义一个这样的画板是为了后续“告知”AI算法,白色部分为用户标出来的需要自动填充的区域,而黑色部分是不需要处理的。因此,上述代码中,针对第二个画板mask_canvas,其底色初始时刷新为黑色,后续涂抹时只需要将涂抹区域刷成白色即可。
在工具栏部分定义了一个用于控制画笔粗细的滑动组件,同时定义了一个按钮用来将当前图像及涂抹掩码图像发送给后端服务器处理。
接下来,按照上述逻辑在该html文件中写一段组件初始化的javascript代码:
<!-- 全局初始化 -->
<script>
image_size = 512; //全局画布大小
let erasing = false; //是否正在涂抹
//初始化画图面板
var photo_ctx = photo_canvas.getContext("2d");
photo_canvas.width = image_size;
photo_canvas.height = image_size;
photo_ctx.fillStyle = "#bbbbbb";
photo_ctx.fillRect(0, 0, photo_canvas.width, photo_canvas.height);
let savedImage = null; //用于控制不同的涂抹状态显示效果
//初始化掩码图面板
var mask_ctx = mask_canvas.getContext("2d");
mask_canvas.width = photo_canvas.width;
mask_canvas.height = photo_canvas.height;
mask_ctx.fillStyle = "#000000"; //刷新为黑色背景
mask_ctx.fillRect(0, 0, mask_canvas.width, mask_canvas.height);
//初始化原图面板
var org_ctx = org_canvas.getContext("2d");
//初始化画刷大小
let radius = 15;
document.getElementById("paint_range").value = radius;
document.getElementById("paint_range").addEventListener("change", e => {
radius = parseInt(e.target.value);
});
</script>
上述脚本对html中的各个组件进行了初始化,包括画板初始大小、填充颜色等。需要注意的是,对于掩码图面板,初始时
保存所有修改后重新运行项目,效果如下图所示:

2.2.3 自适应展示图像
为了能够比较好的在画板上展示用户上传的照片,本文采用一种自适应宽高比的方法,在展示时保持原图的宽高比。具体实现时,通过计算当前上传的照片的宽高比,动态调整画布的尺寸,长边统一对齐到固定的image_size大小,短边等比缩放。具体的,添加两段javascript代码即可实现:
<!-- 根据新图像刷新面板状态 -->
<script>
function drawFlashImage(image) {
erasing = false;
//更新画图面板
if (image.height > image.width) {
photo_canvas.height = image_size;
photo_canvas.width = image_size / (image.height * 1.0 / image.width);
}
else {
photo_canvas.width = image_size;
photo_canvas.height = image_size / (image.width * 1.0 / image.height);
}
photo_ctx.drawImage(image, 0, 0, photo_canvas.width, photo_canvas.height);
savedImage = photo_ctx.getImageData(0, 0, photo_canvas.width, photo_canvas.height);
//更新掩码图面板
mask_canvas.height = photo_canvas.height;
mask_canvas.width = photo_canvas.width;
mask_ctx.fillStyle = "#000000";
mask_ctx.fillRect(0, 0, mask_canvas.width, mask_canvas.height);
//更新原始图面板
org_canvas.height = photo_canvas.height;
org_canvas.width = photo_canvas.width;
org_ctx.drawImage(image, 0, 0, org_canvas.width, org_canvas.height);
}
</script>
<!-- 照片上传 -->
<script>
$(function () {
$('#photo_file').on('change', function () {
var r = new FileReader();
f = document.getElementById('photo_file').files[0];
r.readAsDataURL(f);
r.onload = function (e) {
var image = new Image();
image.src = this.result;
image.onload = () => {
drawFlashImage(image);
};
};
});
});
</script>
其中自定义的drawFlashImage()函数会根据传入的Image组件更新各个画板状态。
运行后,上传不同尺寸的照片,效果如下图所示:

可以看到,根据不同的照片尺寸,画板上显示的效果也是不同的。
2.2.4 橡皮擦涂抹
本节内容完成橡皮擦涂抹功能,其本质就是为画板photo_canvas添加一系列鼠标响应事件。
添加javascript代码如下:
<!-- 画图相关事件 -->
<script>
//画板坐标换算
function windowToCanvas(canvas, x, y) {
var bbox = canvas.getBoundingClientRect();
var style = window.getComputedStyle(canvas);
return {
x:
(x -
bbox.left -
parseInt(style.paddingLeft) -
parseInt(style.borderLeft)) *
(canvas.width / parseInt(style.width)),
y:
(y - bbox.top - parseInt(style.paddingTop) - parseInt(style.borderTop)) *
(canvas.height / parseInt(style.height))
};
}
//添加橡皮擦相关事件
photo_canvas.addEventListener("mousedown", e => {
erasing = true;
});
photo_canvas.addEventListener("mousemove", e => {
const { x, y } = windowToCanvas(photo_canvas, e.clientX, e.clientY);
if (erasing) {
erase(x, y);
}
else {
if (savedImage) {
photo_ctx.putImageData(savedImage, 0, 0);
drawEraser(x, y);
}
}
});
photo_canvas.addEventListener("mouseup", e => {
erasing = false;
savedImage = photo_ctx.getImageData(0, 0, photo_canvas.width, photo_canvas.height);
});
photo_canvas.addEventListener("mouseout", e => {
if (!erasing) {
if (savedImage) {
photo_ctx.putImageData(savedImage, 0, 0);
}
}
});
//涂抹操作
function erase(x, y) {
photo_ctx.save();
photo_ctx.beginPath();
photo_ctx.fillStyle = "#ffffff";
photo_ctx.arc(x, y, radius, 0, Math.PI * 2, true);
photo_ctx.fill();
//同时给掩码画板涂抹
mask_ctx.save();
mask_ctx.beginPath();
mask_ctx.fillStyle = "#ffffff";
mask_ctx.arc(x, y, radius, 0, Math.PI * 2, true);
mask_ctx.fill();
}
function drawEraser(x, y) {
photo_ctx.beginPath();
photo_ctx.fillStyle = "#eeeeee";
photo_ctx.arc(x, y, radius, 0, Math.PI * 2, false);
photo_ctx.fill();
}
</script>
重新运行,可以正常的在照片上进行涂抹了,并且可以设置笔刷大小。效果如下:

2.2.5 使用Ajax传输图像
接下来,需要实现最重要的功能:图像修复。当用户涂抹完成后,单击页面上的修复按钮,将原始图像和二值掩码图像一起发送给后端服务器,由后端AI服务对照片进行处理,处理完成后返回给前端,前端收到返回的图像则更新当前各个画板状态。整个操作属于局部刷新,因此本文采用Ajax技术来实现。
继续添加javascript代码如下:
<!-- 图像修复(发送图像给后端并接收修复结果) -->
<script>
//图片转成Buffer
function dataURItoBlob(dataURI) {
var byteString = atob(dataURI.split(',')[1]);
var mimeString = dataURI.split(',')[0].split(':')[1].split(';')[0];
var ab = new ArrayBuffer(byteString.length);
var ia = new Uint8Array(ab);
for (var i = 0; i < byteString.length; i++) {
ia[i] = byteString.charCodeAt(i);
}
return new Blob([ab], { type: mimeString });
}
//修复按钮响应事件(使用Ajax发送图像给后端)
$('#btnProcess').click(function () {
formdata = new FormData(); //发送数据结构体
//添加原始图像
var src = org_canvas.toDataURL("image/png");
var blob = dataURItoBlob(src);
formdata.append("image", blob);
//添加掩码图像
var mask = mask_canvas.toDataURL("image/png");
var blob_mask = dataURItoBlob(mask);
formdata.append("mask", blob_mask);
//发送数据给后端服务器
$.ajax({
url: '/process/', // 后端API接口
type: 'POST', // 请求类型
data: formdata,
dataType: 'json', // 期望获得的响应类型为json
processData: false,
contentType: false,
success: GetResult // 在请求成功之后调用该回调函数输出结果
})
})
//获取修复后的照片并刷新各面板状态
function GetResult(data) {
var v = data['img64'];
var image = new Image();
image.src = "data:image/jpeg;base64, " + v;
image.onload = () => {
drawFlashImage(image);
};
}
</script>
上述代码通过Ajax发送数据时,后端服务接口定义为了’/process/',这个接口需要在django后端代码中实现。
到这里,前端开发全部完成。
2.3 后端开发
首先在eraser/urls.py文件的urlpatterns 字段中添加新的接口路由:
from app.views import process # 导入新添加的视图函数
urlpatterns = [
path('admin/', admin.site.urls),
path('', home, name='home'),
path('process/', process, name='process'), # 添加图像修复路由
]
然后打开app/views.py文件,添加python代码如下:
import base64
from django.views.decorators.csrf import csrf_exempt
from django.http import JsonResponse
import cv2
import numpy as np
def read_image(stream=None):
"""数据流文件转opencv图像"""
if stream is not None:
data_temp = stream.read()
img = np.asarray(bytearray(data_temp), dtype="uint8")
img = cv2.imdecode(img, cv2.IMREAD_UNCHANGED)
return img
@csrf_exempt
def process(request):
"""图像修复"""
result = {}
if request.method == "POST":
# 接收数据
if (
request.FILES.get("image") is not None
and request.FILES.get("mask") is not None
):
img = read_image(stream=request.FILES["image"])
mask = read_image(stream=request.FILES["mask"])
else:
result["code"] = -1
return JsonResponse(result)
if img is None or mask is None:
result["code"] = -1
return JsonResponse(result)
# 图像处理
imgGray = cv2.flip(img, -1) # 上下、左右都镜像
# 返回结果
_, buffer_img = cv2.imencode(".jpg", imgGray) # 在内存中编码为jpg格式
img64 = base64.b64encode(buffer_img) # base64编码用于网络传输
img64 = str(img64, encoding="utf-8") # bytes转换为str类型
result["code"] = 1
result["img64"] = img64
return JsonResponse(result)
上述代码引入了opencv库用来处理图像,如果没有安装opencv库则可以使用下述命令安装:
pip install opencv-python
接下来自定义了一个read_image()函数用来接收从前端网页发过来的图像数据流,并将其转成opencv类型的图像。
最后定义了一个用于图像修复的视图处理函数process(),在该函数中,首先接收从前端发过来的原始图image和二值掩码图mask,然后进行图像处理,最后返回处理后的图像img64。注意到,此处的图像处理仅对图像做了上下颠倒操作,旨在完成前后端串联逻辑,并没有实现真正意义上的AI修复。后续在本文第三节,将详细阐述具体的AI算法及其集成方法。
到这里,后端的逻辑实现就完成了。
保存所有修改后重新运行项目,修复前后效果如下图所示:
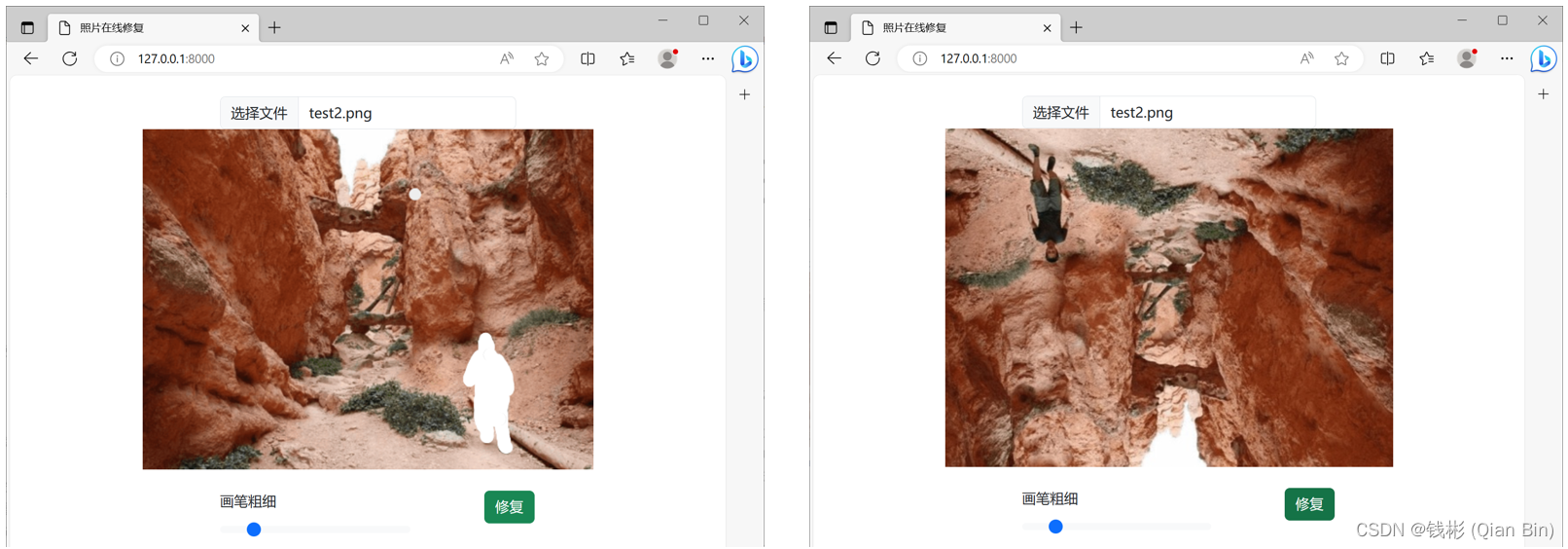
到这里,前后端逻辑已全部实现,接下来进入AI算法集成环节。
三、照片修复
3.1 算法原理
3.1.1 图像修复概述
图像修复是指利用图像中已知的信息,对损坏或缺失的部分进行修复,以恢复原始图像的过程。这个领域的研究具有重要的实际意义,因为在实际生活中,经常会遇到需要修复损坏或老化的图像的情况。
早期的研究主要基于传统的图像处理技术,如滤波、插值等。然而,随着深度学习的发展,研究者们开始尝试将深度学习应用于图像修复。与传统方法相比,深度学习方法能够更好地学习和理解图像的内容和结构,从而更好地进行修复。
在众多深度学习方法中,基于卷积神经网络(CNN)的方法是最为常见和有效的。这些方法通常采用编解码架构,首先通过编码网络对图像进行编码,提取图像的特征,然后通过解码网络对特征进行解码,生成修复后的图像。同时,为了提高修复效果,研究者们还提出了多种损失函数,如重建损失、对抗损失等。除了CNN方法外,生成对抗网络(GAN)也是一种非常有效的图像修复方法。GAN由生成器和判别器两部分组成,通过两者之间的对抗训练,使得生成器能够学习到真实图像的分布,从而生成更加真实的图像。GAN在图像修复中的应用,不仅可以提高修复效果,还可以创造出更加逼真的细节。
目前,深度学习图像修复技术已经取得了显著的应用效果。例如,在文物修复、老照片复原、图像去噪等领域都得到了广泛的应用。同时,随着技术的不断发展,越来越多的应用场景也在不断出现。然而,深度学习图像修复技术仍然存在一些挑战和问题。例如,深度学习方法通常需要大量算力资源进行训练和推理,这也限制了其在某些场景下的应用。因此,研究学者们在改进算法、提高效率、降低成本等方面一直在不断努力尝试着。
3.1.2 DeepFillV2算法
本文将使用DeepFillV2算法来实现照片智能修复功能。DeepFillV2算法来源于ICCV2019会议的一篇论文《Free-Form Image Inpainting With Gated Convolution》,该算法基于GAN模型进行修复,并且创新性的引入了门控卷积来代替传统的CNN卷积,
以更好的解决图像空洞修补问题。门控卷积可以看作是部分卷积的可学习版本,其蒙版参数是可以根据训练数据动态学习的,如下图所示:

通过门控卷积的引入,DeepFillV2将一般的矩形蒙版扩展到可以接受任意形状的蒙版,并且可以形成一种自监督学习模式,通过自动生成任意形状的蒙版区域并覆盖在原图上,从而形成修复前、修复后的大量成对训练图像,整个过程无需额外的人工标记工作,这极大的提升了模型的实际使用性能。
具体 的,DeepFillv2遵循由粗到细的两阶段网络结构。第一生成器网络负责粗重建,而第二生成器网络负责对粗填充的图像进行细化,如下图所示:

对于鉴别器,DeepFillv2采用了著名的PatchGAN结构,并且对鉴别器的每个标准卷积层使用了谱归一化,以提高训练的稳定性。
DeepFillv2的损失函数包含L1损失和GAN损失。L1损失用来衡量原图和重建图像之间的像素差异,GAN损失用来衡量重建图像的整体视觉感受。
DeepFillv2的部分修复实验效果如下:

由于篇幅限制,本文不再深入阐述DeepFillV2算法的实现细节,感兴趣的读者可以自行阅读论文或其他相关资料进行学习。
3.2 算法测试
原始DeepFillV2算法需要读者自行下载和转换权重,为了方便读者,本文将DeepFillV2算法的相关代码和权重进行了整理,并且放在了AI Studio上,读者可以直接下载使用。
在使用DeepFillV2算法前,先确保已安装好pytorch。需要注意的是,由于DeepFillV2算法性能较好,即使不使用GPU,推理速度也基本可以满足本文要求。因此本文安装的是CPU版本的pytorch2.2.1,安装命令如下:
pip install torch torchvision torchaudio
然后运行test.py脚本,其完整代码如下:
import torch
import torchvision.transforms as T
from model.networks import Generator
import cv2
# 参数设置
img_path = "examples/test.png" # 原始图像路径
mask_path = "examples/mask.png" # 掩码图路径
out_path = "examples/result.png" # 保存图像路径
checkpoint = "./pretrained/states_pt_places.pth" # 模型路径
# 设置设备环境
device = torch.device('cpu')
# 加载模型
generator = Generator(cnum_in=5, cnum=48, return_flow=False).to(device)
generator_state_dict = torch.load(checkpoint, map_location=device)['G']
generator.load_state_dict(generator_state_dict, strict=True)
# 加载图像和掩码图
img = cv2.imread(img_path)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
mask = cv2.imread(mask_path)
# 准备输入数据
img = T.ToTensor()(img)
mask = T.ToTensor()(mask)
_, h, w = img.shape
grid = 8
img = img[:3, :h//grid*grid, :w//grid*grid].unsqueeze(0)
mask = mask[0:1, :h//grid*grid, :w//grid*grid].unsqueeze(0)
img = (img*2 - 1.).to(device) # 映射图像数据至[-1, 1]
mask = (mask > 0.5).to(dtype=torch.float32,
device=device) # 1.: masked 0.: unmasked
img_masked = img * (1.-mask)
ones_x = torch.ones_like(img_masked)[:, 0:1, :, :]
x = torch.cat([img_masked, ones_x, ones_x*mask], dim=1)
with torch.inference_mode():
_, x_stage2 = generator(x, mask)
# 后处理
img_inpainted = img * (1.-mask) + x_stage2 * mask
img_out = ((img_inpainted[0].permute(1, 2, 0) + 1)*127.5)
img_out = img_out.to(device='cpu', dtype=torch.uint8)
img_out = img_out.numpy()
img_out = cv2.cvtColor(img_out,cv2.COLOR_RGB2BGR)
cv2.imwrite(out_path,img_out)
运行结果存放在examples文件夹中,运行效果如下:

可以看到,算法根据用户标出的二值掩码图,自动对掩码区域进行了填充,“完美”的擦除了人像。
需要注意的是,DeepFillV2一共提供了两个训练好的模型(存放在pretained文件夹中):
- states_pt_places.pth:用于一般性图像修复;
- states_pt_celebahq.pth:专门用于肖像照片修复;
读者可以根据需要自行选择需要使用的模型。
3.3 算法集成
上一小结完成了算法的测试,本节内容需要将算法集成到前面搭建好的django项目中。
首先将前面算法部分的代码文件夹model和权重文件夹pretrained整个拷贝到django项目eraser文件夹下面,然后修改eraser/app/views.py文件,代码如下:
from django.shortcuts import render
import base64
from django.views.decorators.csrf import csrf_exempt
from django.http import JsonResponse
import cv2
import numpy as np
import torch
import torchvision.transforms as T
from model.networks import Generator
# 创建视图处理函数
def home(request):
return render(request, "index.html")
def read_image(stream=None):
"""数据流文件转opencv图像"""
if stream is not None:
data_temp = stream.read()
img = np.asarray(bytearray(data_temp), dtype="uint8")
img = cv2.imdecode(img, cv2.IMREAD_UNCHANGED)
return img
# 参数设置
checkpoint = "./pretrained/states_pt_places.pth" # 模型路径
# 设置设备环境
device = torch.device('cpu')
# 加载模型
generator = Generator(cnum_in=5, cnum=48, return_flow=False).to(device)
generator_state_dict = torch.load(checkpoint, map_location=device)['G']
generator.load_state_dict(generator_state_dict, strict=True)
@csrf_exempt
def process(request):
"""图像修复接口"""
result = {}
if request.method == "POST":
# 接收数据
if (
request.FILES.get("image") is not None
and request.FILES.get("mask") is not None
):
img = read_image(stream=request.FILES["image"])
mask = read_image(stream=request.FILES["mask"])
else:
result["code"] = -1
return JsonResponse(result)
if img is None or mask is None:
result["code"] = -1
return JsonResponse(result)
# 图像处理
img = cv2.cvtColor(img,cv2.COLOR_BGRA2RGB)
# 准备输入数据
img = T.ToTensor()(img)
mask = T.ToTensor()(mask)
_, h, w = img.shape
grid = 8
img = img[:3, :h//grid*grid, :w//grid*grid].unsqueeze(0)
mask = mask[0:1, :h//grid*grid, :w//grid*grid].unsqueeze(0)
img = (img*2 - 1.).to(device) # 映射图像数据至[-1, 1]
mask = (mask > 0.5).to(dtype=torch.float32,
device=device) # 1.: masked 0.: unmasked
img_masked = img * (1.-mask)
ones_x = torch.ones_like(img_masked)[:, 0:1, :, :]
x = torch.cat([img_masked, ones_x, ones_x*mask], dim=1)
with torch.inference_mode():
_, x_stage2 = generator(x, mask)
# 后处理
img_inpainted = img * (1.-mask) + x_stage2 * mask
img_out = ((img_inpainted[0].permute(1, 2, 0) + 1)*127.5)
img_out = img_out.to(device='cpu', dtype=torch.uint8)
img_out = img_out.numpy()
img_out = cv2.cvtColor(img_out,cv2.COLOR_RGB2BGR)
# 返回结果
_, buffer_img = cv2.imencode(".jpg", img_out) # 在内存中编码为jpg格式
img64 = base64.b64encode(buffer_img) # base64编码用于网络传输
img64 = str(img64, encoding="utf-8") # bytes转换为str类型
result["code"] = 1
result["img64"] = img64
return JsonResponse(result)
重新运行项目,效果如下图所示:

本项目完整下载链接。
四、总结
本文详细讲解了如何构造一个基于django和pytorch的AI应用,旨在通过django打通前后端处理流程,并且集成一种用于照片修复的AI算法。在此基础上,帮助读者更好的掌握django的使用方法。由于水平有限,文中有不当或错误的地方请各位读者批评指正。想要系统学习深度学习与图像处理的读者可以关注本人最新教程,另外想要系统学习django的读者也可以关注我的实体书。
参考文献
【1】J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu and T. Huang, “Free-Form Image Inpainting With Gated Convolution,” IEEE International Conference on Computer Vision (ICCV), 2019, pp. 4470-4479.