文章汇总
总体问题
通过对整体分类的训练(文章结构图中ClassifierBaseline),即在整个标签集上进行分类,它可以得到与许多元学习算法相当甚至更好的嵌入。这两种工作之间的界限尚未得到充分的探索,元学习在少样本学习中的有效性仍然不清楚。
动机
我们观察到元学习和整体分类目标之间的权衡,这可能解释了元基线的成功,并重新思考了这两个目标在少样本学习中的有效性。
解决办法
为了了解与全分类相比元学习是否仍然有效,一个自然的实验是看看如果我们在收敛分类器基线的评估指标(即余弦最近质心)上执行进一步的元学习会发生什么。
实现方法
用质心的概念来代表一个类别的高度,
为去掉最后一个FC层的编码器

通过质心算概率
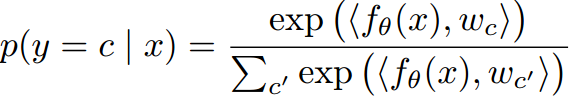
流程图如下

摘要
元学习是近年来最常见的少样本学习框架。它从少量分类任务的集合中学习模型,这被认为具有使训练目标与测试目标一致的关键优势。然而,最近的一些研究报道,通过对整体分类的训练,即在整个标签集上进行分类,它可以得到与许多元学习算法相当甚至更好的嵌入。这两种工作之间的界限尚未得到充分的探索,元学习在少样本学习中的有效性仍然不清楚。在本文中,我们探索了一个简单的过程:对其评估指标的整体分类预训练模型进行元学习。
我们观察到,这种简单的方法在标准基准测试中取得了与最先进的方法相比具有竞争力的性能。我们进一步的分析有助于理解元学习目标和全分类目标之间的取舍。
1. 介绍
虽然人类已经表现出了令人难以置信的能力,可以从很少的例子中学习,并推广到许多不同的新例子,但目前的深度学习方法仍然依赖于大规模的训练数据。为了模仿这种人类的泛化能力,提出了few-shot学习[4,29],用于训练网络基于几个标记示例来理解新概念。虽然用很少的样本直接学习大量的参数是非常具有挑战性的,而且很可能导致过拟合,但一个实用的设置是应用迁移学习:用足够的样本在常见类(也称为基类)上训练网络,然后用少量的样本转移模型来学习新的类。
少样本学习的元学习框架遵循了“学会学习”的关键思想。具体来说,它从属于基类的训练样本中采样少量分类任务,并优化模型以在这些任务上表现良好。
一个任务通常采用N-way和K-shot的形式,其中包含N个类,每个类中有K个支持样本和Q个查询样本。目标是根据N × K个支持样本将这N × Q个查询样本分类为N个类。在此框架下,模型直接针对少量分类任务进行优化。训练目标和测试目标之间的一致性被认为是元学习的关键优势。在这一思想的推动下,最近的许多研究[26,6,25,30,5,22,11,33]关注于改进元学习结构,而few-shot学习本身已经成为评估元学习算法的通用测试平台。
然而,最近的一些研究发现,整体分类的训练,即在整个训练标签集(基类)上的分类,提供了与许多最近的元学习算法相当甚至更好的嵌入。整体分类模型的有效性在之前的研究[6,1]和一些并行研究[31,27]中都有报道。元学习使训练目标的形式与测试一致,但为什么它跟简单的整体分类学习比有更糟糕的嵌入呢?虽然有几个可能的原因,如优化困难或过拟合,但答案尚未得到明确的研究。元学习是否仍然比全分类在少样本学习中有效还不清楚。
在这项工作中,我们旨在通过解耦差异来探索整体分类和元学习之间的优势。我们从分类器-基线(Classifier-Baseline)开始:这是一种整体分类方法,在并行工作中也被类似地提出[31,27]。在分类器-基线中,我们首先在基类上训练分类器,然后去除最后一个完全连接(FC)层,该层是类相关的。在测试期间,计算每个新类的支持样本均值嵌入作为其质心,并将查询样本分类到距离最近的余弦距离质心。我们观察到这种基线方法优于许多最近的元学习算法。
为了了解与全分类相比元学习是否仍然有效,一个自然的实验是看看如果我们在收敛分类器基线的评估指标(即余弦最近质心)上执行进一步的元学习会发生什么。作为一种结果方法,它类似于MatchingNet[29]或ProtoNet[24],但增加了分类预训练阶段。我们观察到元学习仍然可以提高ClassifierBaseline,并且它在标准基准上达到了与最先进的方法竞争的性能。我们称这个简单的方法为Meta-Baseline。我们强调,作为一种方法,Meta-Baseline的所有单独组成部分都已在先前的工作中提出,但据我们所知,它被忽视了,先前的工作都没有将它们作为一个整体进行研究。我们通过对两种类型的泛化进行评估来进一步解耦差异:
基类泛化表示在基类中未见数据的少量分类任务上的性能,它遵循泛化的常见定义(即在训练分布中进行评估);
新类泛化是指在新类数据的少数样本分类任务上的性能,这是少数样本学习问题的目标。
研究发现:
(1)元学习过程中,基类泛化程度的提高会导致新类泛化程度的降低;
(2)当从头开始训练Meta-Baseline(即不进行整个分类训练)时,它的基类泛化率更高,但新类泛化率要低得多。
我们的观察表明,在元学习和整体分类的目标之间可能存在权衡。可能元学习学习的是对N-way K-shot任务效果更好的嵌入,而全分类学习的是类可转移性更强的嵌入。我们发现,在元学习之前进行整体分类训练的主要优势有可能提高类的可转移性(性能)。我们进一步的实验为Meta-Baseline成为强基线的原因提供了一个潜在的解释:通过继承整个分类模型中最有效的评估指标之一,它最大限度地重用了具有强类可转移性的嵌入。从另一个角度来看,我们的研究结果也从数据集的角度重新思考了元学习和整体分类的比较。
当收集基类以覆盖新类的分布时,新类泛化会收敛于基类泛化,元学习的强度可能会超过整体分类的强度。
总之,我们的贡献如下:
我们提出了一个简单的元基线,这在以前的工作中被忽视了。它在标准基准上实现了具有竞争力的性能,并且易于遵循。
我们观察到元学习和整体分类目标之间的权衡,这可能解释了元基线的成功,并重新思考了这两个目标在少样本学习中的有效性。
3. 方法
3.1. 问题定义
在标准的few-shot分类中,给定一个带有大量图像的基类的标记数据集,目标是使用少量样本学习新颖类
中的概念。在N向K次少射分类任务中,支持集包含N个类,每个类有K个样本,查询集包含来自相同N个类的样本,每个类有Q个样本,目标是将N × Q个查询图像分类为N个类。
3.2. Classifier-Baseline
Classifier-Baseline是一个整体分类模型,即为整个标签集训练的分类模型。它是指训练一个在所有基类上都有分类损失的分类器,并使用余弦最近邻质心方法执行少射任务。具体来说,我们在所有基类上训练一个具有标准交叉熵损失的分类器,然后去除它的最后一个FC层并得到编码器,它将输入映射到嵌入。给定几个镜头的任务设支持集
,
为c类的少次样本,计算平均嵌入
作为c类的质心(公式1)
然后对于少样本任务中的查询样本x,根据样本x的嵌入与c类质心的余弦相似度预测样本x属于c类的概率:
表示两个向量的余弦相似度。
在并行研究中也提出了与Classifier-Baseline类似的方法[31,27]。与Baseline++[1]相比,classifier-Baseline不使用余弦分类器进行训练或在测试期间进行微调,而它在标准基准测试中表现更好。在这项工作中,我们选择Classifier-Baseline作为全分类模型的代表进行少镜头学习。为了简单明了,我们不为这个全分类训练引入额外的复杂技术。
3.3. Meta-Baseline

图1显示了元基线。
第一阶段是分类训练阶段,它训练一个ClassifierBaseline,即在所有基类上训练一个分类器,并去除它的最后一层FC得到。
第二阶段是元学习阶段,在分类器-基线评价指标上对模型进行优化。具体来说,给定分类训练的特征编码器,它从基类的训练样本中采样N次k次任务(带有N × Q个查询样本me:也就是第二阶段的训练数据是从查询集里面抽出来的)。为了计算每个任务的损失,在support-set中计算公式1中定义的N个类的质心,然后使用这些质心计算公式2中定义的queryset中每个样本的预测概率分布。损失是由p和查询集中样本的标签计算得出的交叉熵损失。在训练过程中,每个训练批可以包含多个任务,并计算平均损失。
由于余弦相似度的取值范围为[−1;1],当它用于计算对数时,在训练过程中,在应用Softmax函数之前它可以帮助对值进行缩放(最近的工作中常见的做法[6,17,16])。我们将余弦相似度乘以一个可学习的标量,则训练中的概率预测变为:

在这项工作中,Meta-Baseline的主要目的是研究元学习目标在整体分类模型上是否仍然有效。作为一种方法,虽然Meta-Baseline中的每个组件都在之前的工作中提出过,但我们发现之前的工作都没有将它们作为一个整体进行研究。因此,元基线也应该是一个被忽视的重要基线。
4. 标准基准测试结果
4.1. 数据集
miniImageNet数据集[29]是一个常用的少镜头学习基准。它包含从ILSVRC-2012中采样的100个类[21],然后将其随机分成64、16、20个类分别作为训练集、验证集和测试集。每个类包含600张大小为84 × 84的图像。
tieredImageNet数据集[20]是最近提出的另一个规模更大的常见基准。它是ILSVRC-2012的一个子集,包含来自34个超类别的608个类,然后将这些超类别分成20个、6个、8个超类别,分别得到351个、97个、160个类作为训练集、验证集、测试集。图像大小为84 × 84。
这种设置更具挑战性,因为基类和新类来自不同的超类别。
除了上述数据集之外,我们还在ImageNet-800上评估了我们的模型,ImageNet-800是从ILSVRC-2012 1K类中衍生出来的,随机划分了800个类作为基类,200个类作为新类。基类包含来自原始训练集的图像,新类包含来自原始验证集的图像。这个更大的数据集旨在将训练设置标准作为ImageNet 1K分类任务[8]。
4.2. 实现细节
我们在miniImageNet和tieredImageNet上使用ResNet-12,它遵循了最近的大部分作品[16,25,11,33],在ImageNet800上使用ResNet-18, ResNet-50[8]。对于分类训练阶段,我们使用动量为0.9的SGD优化器,学习率从0.1开始,衰减因子为0.1。在miniImageNet上,我们在4个gpu上训练100个epoch,批处理大小为128,学习率在epoch 90时下降。在tieredImageNet上,我们在4个gpu上训练了120个epoch,批处理大小为512,学习率在第40和第80时期下降。在ImageNet-800上,我们在8个gpu上训练90个epoch,批大小为256,学习率在epoch 30和60时下降。ResNet-12的权重衰减为0.0005,ResNet-18或ResNet-50的权重衰减为0.0001。应用标准数据增强,包括随机调整大小的裁剪和水平翻转。对于元学习阶段,我们使用动量为0.9的SGD优化器。学习率固定为0.001。batch大小为4,即每个training batch包含4个few-shot task来计算平均损失。
余弦缩放参数τ初始化为10。
我们还应用一致抽样来评估性能。对于数据集中的新类拆分,采样少量测试任务遵循确定的顺序。一致采样使我们能够得到更好的模型比较使用相同数量的采样任务。在下面部分中,如果在表中省略置信区间,则表示对固定的800个测试任务进行采样以估计性能。
4.3. 结果



7. 总结与讨论
在这项工作中,我们提出了一个简单的元基线,它被忽视的少样本学习。没有任何额外的参数或复杂的设计选择,它是竞争的最先进的方法在标准基准。
我们的实验表明,对于少样本学习,元学习框架可能存在客观差异,即一个元学习模型在基类的未见任务上泛化得更好,而在新类的任务上泛化得更差。这可能解释了为什么一些复杂的元学习方法不能获得比简单的整体分类明显更好的性能。虽然最近的研究集中在改进元学习结构上,但其中许多并没有明确地解决班级可转移性的问题。我们的观察表明,客观差异可能是一个需要解决的潜在关键挑战。
虽然人们提出了许多新的元学习算法,并且最近的一些研究报告表明,简单的整体分类训练足以用于少量学习,但我们表明,元学习在整体分类模型上仍然有效。我们观察到元学习和整体分类目标之间的潜在权衡。从数据集的角度,我们展示了元学习和整体分类之间的偏好是如何随着类相似度等因素的变化而变化的,这表明这些因素在未来的模型比较中可能需要更多的关注。
参考资料
文章下载(ICCV 2021)
https://arxiv.org/abs/2003.04390
📎Meta-Baseline Exploring Simple Meta-Learning for Few-Shot Learning.pdf

代码地址
GitHub - yinboc/few-shot-meta-baseline: Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning, in ICCV 2021










![Linux基础命令[11]-find](https://img-blog.csdnimg.cn/direct/77fe8b0071724e5486b80920388136f0.png)