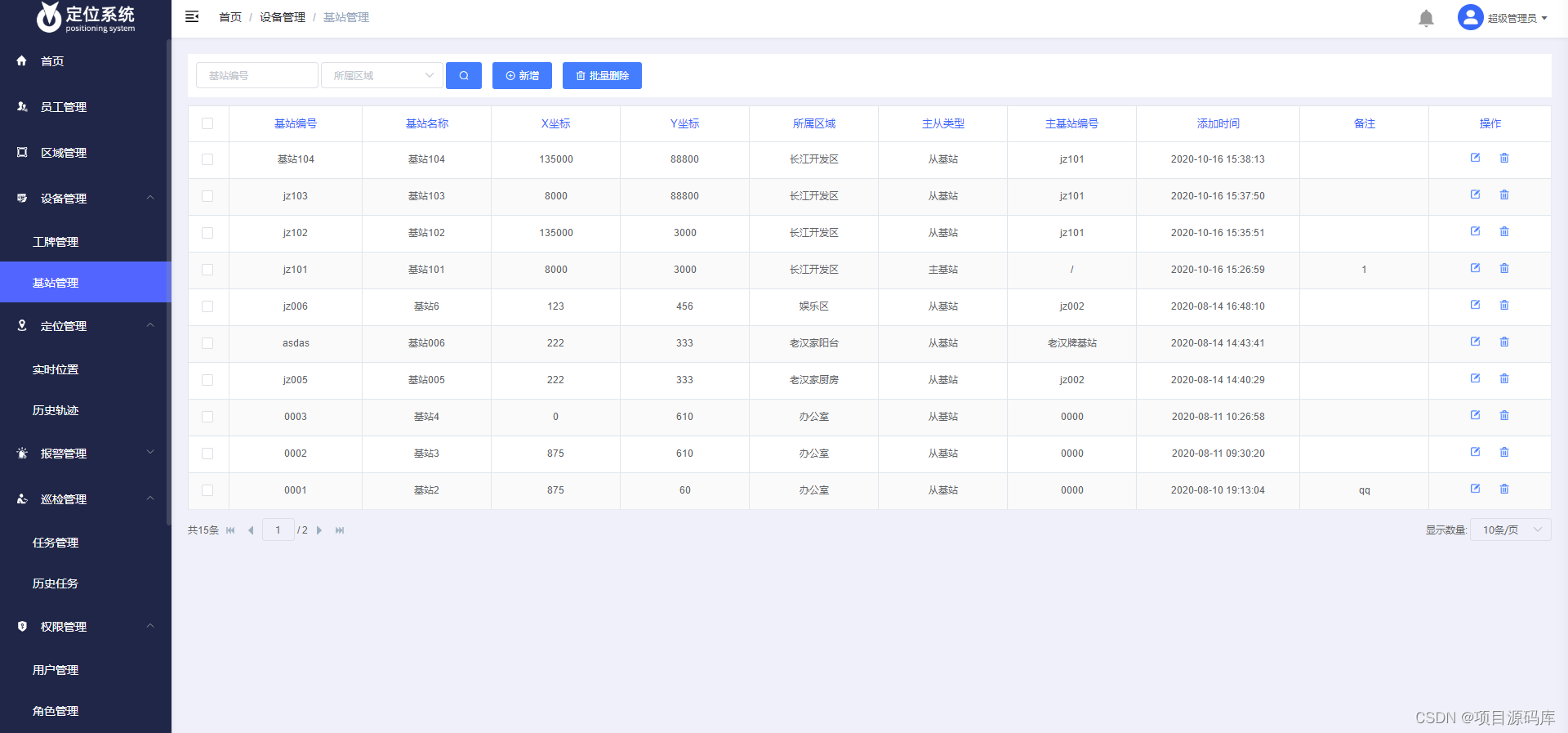
基于梯度提升树实现波士顿房价预测
将波士顿房价数据集拆分成训练集和测试集,搭建gbdt_1、gbdt_2和gbdt_3三个梯度提升树模型,分布设置超参数n_estimators为50、100、150。各自对训练集进行训练,然后分别对训练集和测试集进行预测。输出以下结果:
(1)gbdt_1(50)在训练集上的准确率,在测试集上的准确率。
(2)gbdt_2(100)在训练集上的准确率,在测试集上的准确率。
(2)gbdt_3(150)在训练集上的准确率,在测试集上的准确率。
源码
from sklearn.datasets import load_boston
from sklearn.ensemble import GradientBoostingRegressor as GBDT
from sklearn.model_selection import train_test_split, validation_curve
def train():
boston = load_boston()
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target)
model = GBDT(n_estimators=50)
model.fit(x_train, y_train)
train_score = model.score(x_train, y_train)
test_score = model.score(x_test, y_test)
print("李思强 20201107148")
print("50")
print("train_score",train_score)
print("test_score",test_score)
mode2 = GBDT(n_estimators=100)
mode2.fit(x_train, y_train)
train_score2 = mode2.score(x_train, y_train)
test_score2 = mode2.score(x_test, y_test)
print("100")
print("train_score",train_score2)
print("test_score",test_score2)
mode3 = GBDT(n_estimators=150)
mode3.fit(x_train, y_train)
train_score3 = mode3.score(x_train, y_train)
test_score3 = mode3.score(x_test, y_test)
print("150")
print("train_score",train_score3)
print("test_score",test_score3)
if __name__ == '__main__':
train()
运行结果





![Linux基础命令[11]-find](https://img-blog.csdnimg.cn/direct/77fe8b0071724e5486b80920388136f0.png)