Transformers+diffusion技术背景简介
Transformers diffusion背景
近期大火的OpenAI推出的Sora模型,其核心技术点之一,是将视觉数据转化为Patch的统一表示形式,并通过Transformers技术和扩散模型结合,展现了卓越的scale特性。
被Twitter上广泛传播的论文《Scalable diffusion models with transformers》也被认为是Sora技术背后的重要基础。而这项研究的发布遇到了一些坎坷,曾经被CVPR2023拒稿过。然DiT被拒了,我们看到来自清华大学,人民大学等机构共同研究的CVPR2023的论文U-ViT《All are Worth Words: A ViT Backbone for Diffusion Models》,2022年9月发表,这项研究设计了一个简单而通用的基于vit的架构(U-ViT),替换了U-Net中的卷积神经网络(CNN),用于diffusion模型的图像生成任务。
项目已经开源
GitHub链接: https://github.com/baofff/U-ViT
论文链接:https://arxiv.org/abs/2209.12152
模型链接:https://modelscope.cn/models/thu-ml/imagenet256_uvit_huge
但是,正如作者所说的,Sora将基于Transformers的diffusion model scale up成功,不仅需要对底层算法有专家级理解,还要对整个深度学习工程体系有很好的把握,这项工作相比在学术数据集做出一个可行架构更加困难。
什么是ViT
Vision Transformer (ViT) 模型由 Alexey Dosovitskiy等人在 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 中提出。这是第一篇在 ImageNet 上成功训练 Transformer 编码器的论文,与熟悉的卷积架构相比,取得了非常好的结果。论文提出,虽然 Transformer 架构已成为自然语言处理任务事实上的标准,但其在计算机视觉中的应用仍然有限。 在视觉中,attention要么与卷积网络结合应用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。 ViT证明这种对 CNN 的依赖是不必要的,直接应用于图像块序列(patches)的纯 Transformer 可以在图像分类任务上表现良好。 当对大量数据进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,Vision Transformer (ViT) 与SOTA的CNN相比取得了优异的结果,同时需要更少的计算资源来训练,Vision Transformer (ViT) 基本上是 Transformers,但应用于图像。
每个图像被分割成一系列不重叠的块(分辨率如 16x16 或 32x32),并线性embedding,接下来,添加position embedding,并通过编码器层发送。 在开头添加 [CLS] 标记以获得整个图像的表示。 可以在hidden states之上添加MLP head以对图像进行分类。
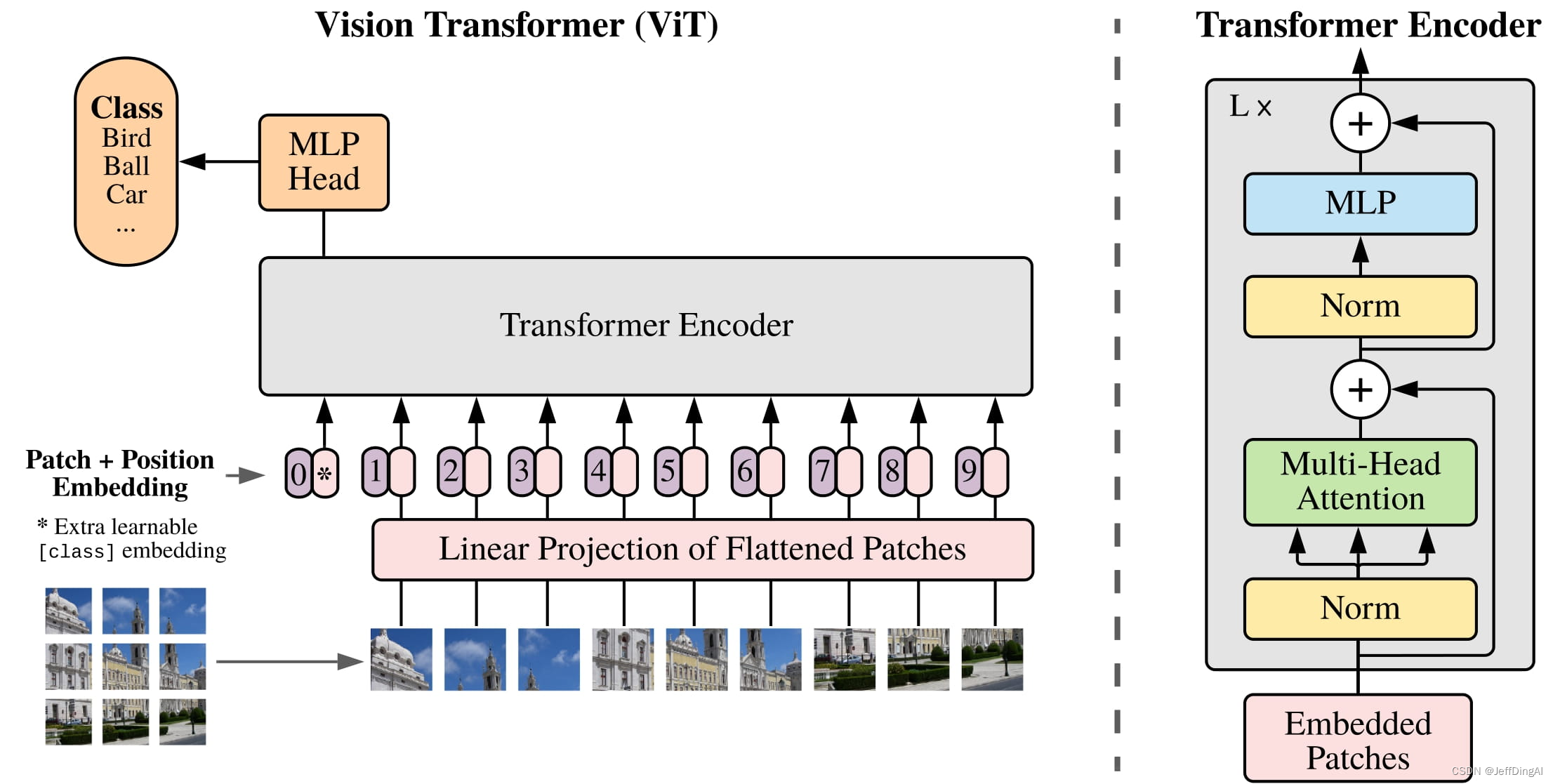
论文:
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Paper: https://arxiv.org/abs/2010.11929
Official repo (in JAX): https://github.com/google-research/vision_transformer
ViT在大语言模型中的使用(Qwen-VL为例)
Qwen-VL: Qwen-VL 以 Qwen-7B 的预训练模型作为语言模型的初始化,并以openclip-ViT-bigG作为视觉编码器的初始化,中间加入单层随机初始化的 cross-attention,经过约1.5B的图文数据训练得到。最终图像输入分辨率为448*448。
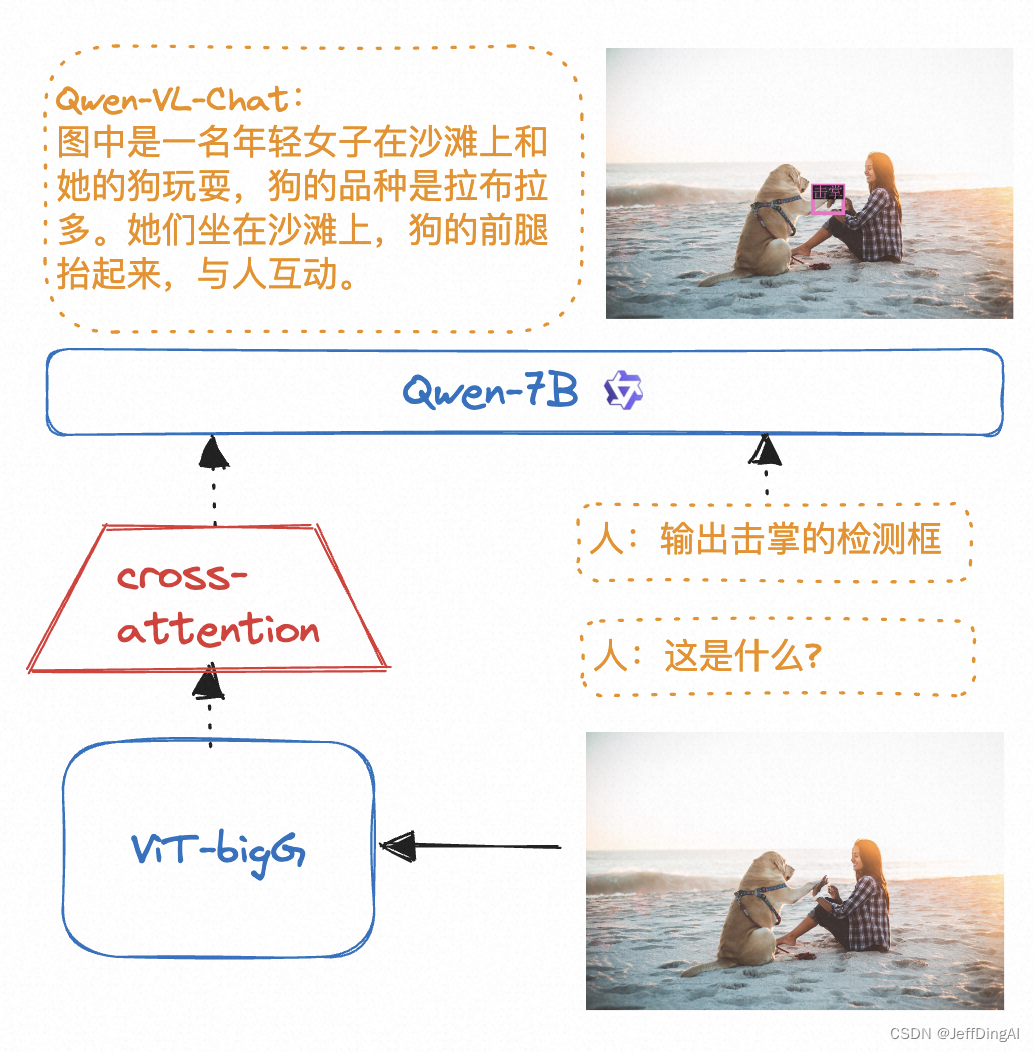
论文链接:
https://arxiv.org/abs/2010.11929
ViViT:视频ViT
ViViT基于纯变压器的视频模型分类,借鉴了ViT图像分类中取得的成功。 ViViT从输入视频中提取时空标记,然后由一系列转换器层进行编码。
源自:Arnab, Anurag, et al. “Vivit: A video vision transformer.” ICCV2021
paper:https://arxiv.org/abs/2103.15691
Latte:用于视频生成的潜在扩散变压器
Latte提出了一种新颖的潜在扩散变压器,用于视频生成。Latte 首先从输入视频中提取时空标记,然后采用一系列 Transformer 块对潜在空间中的视频分布进行建模。为了对从视频中提取的大量标记进行建模,从分解输入视频的空间和时间维度的角度引入了四种有效的变体。为了提高生成视频的质量,我们通过严格的实验分析确定了 Latte 的最佳实践,包括视频剪辑补丁嵌入、模型变体、时间步级信息注入、时间位置嵌入和学习策略。我们的综合评估表明,Latte 在四个标准视频生成数据集(即 FaceForensics、SkyTimelapse、UCF101 和 Taichi-HD)上实现了最先进的性能。此外, Latte也 扩展到文本到视频生成 (T2V) 任务,其中 Latte 取得了与最新 T2V 模型相当的结果。我们坚信,Latte 为未来将 Transformer 纳入视频生成扩散模型的研究提供了宝贵的见解。
代码实战
Patch最佳实践
图像预处理:
具体步骤如下:
读取图像: 使用 tf.keras.utils.load_img 函数从给定路径 /mnt/workspace/image_1.png 读取图像。设置参数 grayscale=False 表示读取彩色图像,color_mode=‘rgb’ 指定了图像为 RGB 格式。由于 target_size=None,图像将保持原始尺寸不变。interpolation=‘nearest’ 表示在缩放时采用最近邻插值方法。
转换为数组格式: 使用 tf.keras.preprocessing.image.img_to_array 将读取到的 PIL 图像对象转换为 Numpy 数组(在 TensorFlow 中表示为 tensor)。
图像缩放: 判断条件 if (scale),如果为真,则使用 tf.image.resize 对图像进行缩放到指定大小(即 image_dim)。这里采用了双线性插值方法 (ResizeMethod.BILINEAR) 进行缩放,并且不保留原始宽高比 (preserve_aspect_ratio=False)。
裁剪图像: 使用 tf.image.crop_to_bounding_box 对图像进行裁剪,裁剪区域是从原图的左上角 (0, 0) 开始,裁剪出一个 image_dim x image_dim 大小的正方形图像。
返回处理后的图像: 最终返回经过上述预处理步骤后得到的图像数组(tensor)。
这段代码,能够以统一大小加载并预处理图片,这对于后续将图片输入到深度学习模型中是非常常见的做法。
import tensorflow as tf
# Image preprocessing
def read_image(image_file="/mnt/workspace/image_1.png", scale=True, image_dim=336):
image = tf.keras.utils.load_img(
image_file, grayscale=False, color_mode='rgb', target_size=None,
interpolation='nearest'
)
image_arr_orig = tf.keras.preprocessing.image.img_to_array(image)
if(scale):
image_arr_orig = tf.image.resize(
image_arr_orig, [image_dim, image_dim],
method=tf.image.ResizeMethod.BILINEAR, preserve_aspect_ratio=False
)
image_arr = tf.image.crop_to_bounding_box(
image_arr_orig, 0, 0, image_dim, image_dim
)
return image_arr
创建Patch
这段代码是使用TensorFlow库来从输入图像中提取32x32大小的图像块(即patch)并将其转化为一维向量。以下是详细的步骤解释:
def create_patches(image): 定义了一个名为create_patches的函数,参数为image图像张量。
im = tf.expand_dims(image, axis=0):使用TensorFlow的expand_dims函数在图像数据的第0维(batch维度)增加一个维度,以便能够处理一批图片,即使现在我们只有一张图片。
patches = tf.image.extract_patches(…):调用TensorFlow的extract_patches函数从图像中提取 patches。这里的设置表明:
images=im 表示要提取 patches 的图像。
sizes=[1, 32, 32, 1] 表示每个 patch 的大小为 32x32 像素,并且深度(通道数)与原图相同。
strides=[1, 32, 32, 1] 表示在宽度和高度方向上以32像素为步长移动来提取相邻的 patch。
rates=[1, 1, 1, 1] 表示采样率,在此处等于 strides,意味着没有进行亚像素采样。
padding=“VALID” 表示不进行额外的填充,只对完全包含在原始图像内的 patch 进行提取。
patch_dims = patches.shape[-1]:获取提取出的 patches 在最后一个维度(在这里指的是每个 patch 的元素数量,即3232C,C为通道数)的大小。
patches = tf.reshape(patches, [1, -1, patch_dims]):将提取到的一系列 patches 进行reshape,将其展平为一个一维数组,其中第一个维度表示 batch 大小(这里为1),第二个维度是所有 patches 的总数量(-1表示自动计算这一维度的大小),第三个维度是每个 patch 的元素数量。
函数最后返回经过处理得到的 patches 张量。
image_arr = read_image():假设这是一个读取图像并转换为张量的函数,用于获取待处理的图像。
patches = create_patches(image_arr):调用create_patches函数,传入读取到的图像数据,得到该图像分割后的 patches。
# Patching
def create_patches(image):
im = tf.expand_dims(image, axis=0)
patches = tf.image.extract_patches(
images=im,
sizes=[1, 32, 32, 1],
strides=[1, 32, 32, 1],
rates=[1, 1, 1, 1],
padding="VALID"
)
patch_dims = patches.shape[-1]
patches = tf.reshape(patches, [1, -1, patch_dims])
return patches
image_arr = read_image()
patches = create_patches(image_arr)
绘制patches
这段代码是使用matplotlib库在Python中绘制图像及其分块patches的函数定义,并在最后调用了这两个函数来显示结果。它假定您正在处理一个TensorFlow环境,其中image_arr是一个图像数组(可能已经被转换为浮点数),而patches是一个形状如(batch_size, num_patches, patch_height, patch_width, channels)的张量,其中包含了从image_arr图像中提取出的多个小图像块(patches)。
函数解释:
-
render_image_and_patches(image, patches)- 这个函数首先创建一个新的图形窗口,并设置其大小为16x16英寸。
- 使用
suptitle添加标题"Cropped Image",并设置字体大小为48。 - 使用
plt.imshow显示原始image_arr图像,将其转换回uint8类型以便正确显示,并关闭坐标轴显示。 - 计算patches矩阵的行数和列数(假设patch的数量是平方数)。
- 创建第二个图形窗口同样大小为16x16英寸,添加标题"Image Patches"。
- 遍历
patches的第一个样本的所有patch,对每个patch进行以下操作:- 在网格布局中创建一个新的子图(subplot)。
- 将该patch reshape为(32, 32, 3),即尺寸为32x32像素且有3个颜色通道的小图像。
- 使用
imshow展示这个patch,并关闭坐标轴显示。
-
render_flat(patches)- 这个函数创建一个图形窗口,其宽度为32英寸,高度为2英寸。
- 添加标题"Flattened Image Patches",并设置字体大小为24。
- 同样遍历
patches的第一个样本的所有patch,但这次是在一个水平方向上连续排列的子图中显示它们。- 只显示前100个patch(通过if条件判断
i == 100时跳出循环)。 - 对每个patch重复与上述相同的reshaping和显示过程。
- 只显示前100个patch(通过if条件判断
当调用这两个函数时,将会显示两个图表:
- 第一个图表包含原始整幅图像以及从该图像分割出来的patches。
- 第二个图表则展示了patches在一行内水平排列的扁平化视图,最多显示前100个patch。
原图:

# Drawing
import numpy as np
import matplotlib.pyplot as plt
def render_image_and_patches(image, patches):
plt.figure(figsize=(16, 16))
plt.suptitle(f"Cropped Image", size=48)
plt.imshow(tf.cast(image, tf.uint8))
plt.axis("off")
n = int(np.sqrt(patches.shape[1]))
plt.figure(figsize=(16, 16))
plt.suptitle(f"Image Patches", size=24)
for i, patch in enumerate(patches[0]):
ax = plt.subplot(n, n, i+1)
patch_img = tf.reshape(patch, (32, 32, 3))
ax.imshow(patch_img.numpy().astype("uint8"))
ax.axis("off")
def render_flat(patches):
plt.figure(figsize=(32, 2))
plt.suptitle(f"Flattened Image Patches", size=24)
n = int(np.sqrt(patches.shape[1]))
for i, patch in enumerate(patches[0]):
ax = plt.subplot(1, 101, i+1)
patch_img = tf.reshape(patch, (32, 32, 3))
ax.imshow(patch_img.numpy().astype("uint8"))
ax.axis("off")
if(i == 100):
break
render_image_and_patches(image_arr, patches)
render_flat(patches)
运行结果


ViT最佳实践

from transformers import ViTForImageClassification
import torch
from modelscope import snapshot_download
from PIL import Image
import requests
from transformers import ViTImageProcessor
model_dir = snapshot_download('AI-ModelScope/vit-base-patch16-224')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ViTForImageClassification.from_pretrained(model_dir)
model.to(device)
url = './000000039769.jpg'
image = Image.open(url)
processor = ViTImageProcessor.from_pretrained(model_dir)
inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_values
print(pixel_values.shape)
with torch.no_grad():
outputs = model(pixel_values)
logits = outputs.logits
print(logits.shape)
prediction = logits.argmax(-1)
print("Predicted class:", model.config.id2label[prediction.item()])
运行结果
torch.Size([1, 3, 224, 224])
torch.Size([1, 1000])
Predicted class: Egyptian cat
UViT最佳实践
下载代码仓
git clone https://github.com/baofff/U-ViT
pip install einops
创建代码并且放到U-ViT目录下
import os
import torch
from dpm_solver_pp import NoiseScheduleVP, DPM_Solver
import libs.autoencoder
from libs.uvit import UViT
import einops
from torchvision.utils import save_image
from PIL import Image
import os
from modelscope.hub.file_download import model_file_download
image_size = "256" #@param [256, 512]
image_size = int(image_size)
if image_size == 256:
model_file_download(model_id='thu-ml/imagenet256_uvit_huge',file_path='imagenet256_uvit_huge.pth', cache_dir='/root/temp/workspace')
os.system("mv /root/temp/workspace/thu-ml/imagenet256_uvit_huge/imagenet256_uvit_huge.pth /root/temp/workspace/U-ViT/imagenet256_uvit_huge.pth")
else:
model_file_download(model_id='thu-ml/imagenet512_uvit_huge',file_path='imagenet512_uvit_huge.pth', cache_dir='/root/temp/workspace')
os.system("mv /root/temp/workspace/thu-ml/imagenet512_uvit_huge/imagenet512_uvit_huge.pth /root/temp/workspace/U-ViT/imagenet512_uvit_huge.pth")
z_size = image_size // 8
patch_size = 2 if image_size == 256 else 4
device = 'cuda' if torch.cuda.is_available() else 'cpu'
nnet = UViT(img_size=z_size,
patch_size=patch_size,
in_chans=4,
embed_dim=1152,
depth=28,
num_heads=16,
num_classes=1001,
conv=False)
nnet.to(device)
nnet.load_state_dict(torch.load(f'/root/temp/workspace/U-ViT/imagenet{image_size}_uvit_huge.pth', map_location='cpu'))
nnet.eval()
model_file_download(model_id='AI-ModelScope/autoencoder_kl_ema',file_path='autoencoder_kl_ema.pth', cache_dir='/root/temp/workspace')
os.system("mv /root/temp/workspace/AI-ModelScope/autoencoder_kl_ema/autoencoder_kl_ema.pth /root/temp/workspace/U-ViT/autoencoder_kl_ema.pth")
autoencoder = libs.autoencoder.get_model('/root/temp/workspace/U-ViT/autoencoder_kl_ema.pth')
autoencoder.to(device)
seed = 4321 #@param {type:"number"}
steps = 25 #@param {type:"slider", min:0, max:1000, step:1}
cfg_scale = 3 #@param {type:"slider", min:0, max:10, step:0.1}
class_labels = 207, 360, 387, 974, 88, 979, 417, 279 #@param {type:"raw"}
samples_per_row = 4 #@param {type:"number"}
torch.manual_seed(seed)
def stable_diffusion_beta_schedule(linear_start=0.00085, linear_end=0.0120, n_timestep=1000):
_betas = (
torch.linspace(linear_start ** 0.5, linear_end ** 0.5, n_timestep, dtype=torch.float64) ** 2
)
return _betas.numpy()
_betas = stable_diffusion_beta_schedule() # set the noise schedule
noise_schedule = NoiseScheduleVP(schedule='discrete', betas=torch.tensor(_betas, device=device).float())
y = torch.tensor(class_labels, device=device)
y = einops.repeat(y, 'B -> (B N)', N=samples_per_row)
def model_fn(x, t_continuous):
t = t_continuous * len(_betas)
_cond = nnet(x, t, y=y)
_uncond = nnet(x, t, y=torch.tensor([1000] * x.size(0), device=device))
return _cond + cfg_scale * (_cond - _uncond) # classifier free guidance
z_init = torch.randn(len(y), 4, z_size, z_size, device=device)
dpm_solver = DPM_Solver(model_fn, noise_schedule, predict_x0=True, thresholding=False)
with torch.no_grad():
with torch.cuda.amp.autocast(): # inference with mixed precision
z = dpm_solver.sample(z_init, steps=steps, eps=1. / len(_betas), T=1.)
samples = autoencoder.decode(z)
samples = 0.5 * (samples + 1.)
samples.clamp_(0., 1.)
save_image(samples, "sample.png", nrow=samples_per_row * 2, padding=0)
运行结果

ViViT最佳实践
安装依赖
pip install ipywidgets medmnist
下载数据集到/root/temp/workspace
wget https://modelscope.oss-cn-beijing.aliyuncs.com/resource/organmnist3d.npz -O /root/temp/workspace/organmnist3d.npz
代码
import os
import io
import imageio
import medmnist
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# setting seed for reproducibility
SEED = 42
os.environ["TF_CUDNN_DETERMINISTIC"] = "1"
keras.utils.set_random_seed(SEED)
# DATA
DATASET_NAME = "organmnist3d"
BATCH_SIZE = 32
AUTO = tf.data.AUTOTUNE
INPUT_SHAPE = (28, 28, 28, 1)
NUM_CLASSES = 11
# OPTIMIZER
LEARNING_RATE = 1e-4
WEIGHT_DECAY = 1e-5
# TRAINING
EPOCHS = 60
# TUBELET EMBEDDING
PATCH_SIZE = (8, 8, 8)
NUM_PATCHES = (INPUT_SHAPE[0] // PATCH_SIZE[0]) ** 2
# ViViT ARCHITECTURE
LAYER_NORM_EPS = 1e-6
PROJECTION_DIM = 128
NUM_HEADS = 8
NUM_LAYERS = 8
def download_and_prepare_dataset(data_info: dict):
"""
Utility function to download the dataset and return train/valid/test
videos and labels.
Arguments:
data_info (dict): Dataset metadata
"""
data_path = "/root/temp/workspace/organmnist3d.npz"
with np.load(data_path) as data:
# Get videos
train_videos = data["train_images"]
valid_videos = data["val_images"]
test_videos = data["test_images"]
# Get labels
train_labels = data["train_labels"].flatten()
valid_labels = data["val_labels"].flatten()
test_labels = data["test_labels"].flatten()
return (
(train_videos, train_labels),
(valid_videos, valid_labels),
(test_videos, test_labels),
)
# Get the metadata of the dataset
info = medmnist.INFO[DATASET_NAME]
# Get the dataset
prepared_dataset = download_and_prepare_dataset(info)
(train_videos, train_labels) = prepared_dataset[0]
(valid_videos, valid_labels) = prepared_dataset[1]
(test_videos, test_labels) = prepared_dataset[2]
@tf.function
def preprocess(frames: tf.Tensor, label: tf.Tensor):
"""Preprocess the frames tensors and parse the labels"""
# Preprocess images
frames = tf.image.convert_image_dtype(
frames[
..., tf.newaxis
], # The new axis is to help for further processing with Conv3D layers
tf.float32,
)
# Parse label
label = tf.cast(label, tf.float32)
return frames, label
def prepare_dataloader(
videos: np.ndarray,
labels: np.ndarray,
loader_type: str = "train",
batch_size: int = BATCH_SIZE,
):
"""Utility function to prepare dataloader"""
dataset = tf.data.Dataset.from_tensor_slices((videos, labels))
if loader_type == "train":
dataset = dataset.shuffle(BATCH_SIZE * 2)
dataloader = (
dataset.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE)
.batch(batch_size)
.prefetch(tf.data.AUTOTUNE)
)
return dataloader
trainloader = prepare_dataloader(train_videos, train_labels, "train")
validloader = prepare_dataloader(valid_videos, valid_labels, "valid")
testloader = prepare_dataloader(test_videos, test_labels, "test")
class TubeletEmbedding(layers.Layer):
def __init__(self, embed_dim, patch_size, **kwargs):
super().__init__(**kwargs)
self.projection = layers.Conv3D(
filters=embed_dim,
kernel_size=patch_size,
strides=patch_size,
padding="VALID",
)
self.flatten = layers.Reshape(target_shape=(-1, embed_dim))
def call(self, videos):
projected_patches = self.projection(videos)
flattened_patches = self.flatten(projected_patches)
return flattened_patches
class PositionalEncoder(layers.Layer):
def __init__(self, embed_dim, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
def build(self, input_shape):
_, num_tokens, _ = input_shape
self.position_embedding = layers.Embedding(
input_dim=num_tokens, output_dim=self.embed_dim
)
self.positions = tf.range(start=0, limit=num_tokens, delta=1)
def call(self, encoded_tokens):
# Encode the positions and add it to the encoded tokens
encoded_positions = self.position_embedding(self.positions)
encoded_tokens = encoded_tokens + encoded_positions
return encoded_tokens
def create_vivit_classifier(
tubelet_embedder,
positional_encoder,
input_shape=INPUT_SHAPE,
transformer_layers=NUM_LAYERS,
num_heads=NUM_HEADS,
embed_dim=PROJECTION_DIM,
layer_norm_eps=LAYER_NORM_EPS,
num_classes=NUM_CLASSES,
):
# Get the input layer
inputs = layers.Input(shape=input_shape)
# Create patches.
patches = tubelet_embedder(inputs)
# Encode patches.
encoded_patches = positional_encoder(patches)
# Create multiple layers of the Transformer block.
for _ in range(transformer_layers):
# Layer normalization and MHSA
x1 = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
attention_output = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim // num_heads, dropout=0.1
)(x1, x1)
# Skip connection
x2 = layers.Add()([attention_output, encoded_patches])
# Layer Normalization and MLP
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
x3 = keras.Sequential(
[
layers.Dense(units=embed_dim * 4, activation=tf.nn.gelu),
layers.Dense(units=embed_dim, activation=tf.nn.gelu),
]
)(x3)
# Skip connection
encoded_patches = layers.Add()([x3, x2])
# Layer normalization and Global average pooling.
representation = layers.LayerNormalization(epsilon=layer_norm_eps)(encoded_patches)
representation = layers.GlobalAvgPool1D()(representation)
# Classify outputs.
outputs = layers.Dense(units=num_classes, activation="softmax")(representation)
# Create the Keras model.
model = keras.Model(inputs=inputs, outputs=outputs)
return model
def run_experiment():
# Initialize model
model = create_vivit_classifier(
tubelet_embedder=TubeletEmbedding(
embed_dim=PROJECTION_DIM, patch_size=PATCH_SIZE
),
positional_encoder=PositionalEncoder(embed_dim=PROJECTION_DIM),
)
# Compile the model with the optimizer, loss function
# and the metrics.
optimizer = keras.optimizers.Adam(learning_rate=LEARNING_RATE)
model.compile(
optimizer=optimizer,
loss="sparse_categorical_crossentropy",
metrics=[
keras.metrics.SparseCategoricalAccuracy(name="accuracy"),
keras.metrics.SparseTopKCategoricalAccuracy(5, name="top-5-accuracy"),
],
)
# Train the model.
_ = model.fit(trainloader, epochs=EPOCHS, validation_data=validloader)
_, accuracy, top_5_accuracy = model.evaluate(testloader)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
print(f"Test top 5 accuracy: {round(top_5_accuracy * 100, 2)}%")
return model
model = run_experiment()
import ipywidgets
NUM_SAMPLES_VIZ = 25
testsamples, labels = next(iter(testloader))
testsamples, labels = testsamples[:NUM_SAMPLES_VIZ], labels[:NUM_SAMPLES_VIZ]
ground_truths = []
preds = []
videos = []
for i, (testsample, label) in enumerate(zip(testsamples, labels)):
# Generate gif
with io.BytesIO() as gif:
imageio.mimsave(gif, (testsample.numpy() * 255).astype("uint8")[..., 0], "GIF", fps=5)
videos.append(gif.getvalue())
# Get model prediction
output = model.predict(tf.expand_dims(testsample, axis=0))[0]
pred = np.argmax(output, axis=0)
ground_truths.append(label.numpy().astype("int"))
preds.append(pred)
def make_box_for_grid(image_widget, fit):
"""
Make a VBox to hold caption/image for demonstrating
option_fit values.
Source: https://ipywidgets.readthedocs.io/en/latest/examples/Widget%20Styling.html
"""
# Make the caption
if fit is not None:
fit_str = "'{}'".format(fit)
else:
fit_str = str(fit)
h = ipywidgets.HTML(value="" + str(fit_str) + "")
# Make the green box with the image widget inside it
boxb = ipywidgets.widgets.Box()
boxb.children = [image_widget]
# Compose into a vertical box
vb = ipywidgets.widgets.VBox()
vb.layout.align_items = "center"
vb.children = [h, boxb]
return vb
boxes = []
for i in range(NUM_SAMPLES_VIZ):
ib = ipywidgets.widgets.Image(value=videos[i], width=100, height=100)
true_class = info["label"][str(ground_truths[i])]
pred_class = info["label"][str(preds[i])]
caption = f"T: {true_class} | P: {pred_class}"
boxes.append(make_box_for_grid(ib, caption))
ipywidgets.widgets.GridBox(
boxes, layout=ipywidgets.widgets.Layout(grid_template_columns="repeat(5, 200px)")
)
Latte最佳实践
下载代码仓
git clone https://github.com/maxin-cn/latte.git
安装依赖
pip install timm
pip install einops
pip install omegaconf
pip install modelscope
pip install diffusers==0.24.0
pip install sentencepiece beautifulsoup4 ftfy
pip install imageio[ffmpeg] imageio[pyav]
pip install transformers
pip install accelerate
pip install tensorboard
下载模型到Latte/models目录下
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('AI-ModelScope/Latte', cache_dir='/root/temp/Latte/models/', revision='master')
修改配置文件configs/t2v/t2v_sample.yaml
path:
ckpt: ./models/Latte/t2v.pt
save_img_path: "./sample_videos/t2v"
pretrained_model_path: "./models/Latte/t2v_required_models"
执行命令
export CUDA_VISIBLE_DEVICES=0
export PYTHONPATH=../
python sample/sample_t2v.py --config configs/t2v/t2v_sample.yaml
扩展学习:LaVie
安装依赖
pip install accelerate==0.19.0
pip install av==10.0.0
pip install decord==0.6.0
pip install diffusers[torch]==0.16.0
pip install einops==0.6.1
pip install ffmpeg==1.4
pip install imageio==2.31.1
pip install imageio-ffmpeg==0.4.9
pip install pandas==2.0.1
pip install timm==0.6.13
pip install tqdm==4.65.0
pip install transformers==4.28.1
pip install xformers==0.0.20
pip install omegaconf==2.3.0
pip install natsort==8.4.0
pip install rotary_embedding_torch
下载代码仓
git clone https://github.com/Vchitect/LaVie
设置hf-mirror
export HF_ENDPOINT="https://hf-mirror.com"
下载模型到代码仓models目录下
huggingface-cli download --resume-download --local-dir-use-symlinks False YaohuiW/LaVie --local-dir /root/temp/LaVie/pretrained_models
huggingface-cli download --resume-download --local-dir-use-symlinks False CompVis/stable-diffusion-v1-4 --local-dir /root/temp/LaVie/pretrained_models/stable-diffusion-v1-4
huggingface-cli download --resume-download --local-dir-use-symlinks False stabilityai/stable-diffusion-x4-upscaler --local-dir /root/temp/LaVie/pretrained_models/stable-diffusion-x4-upscaler
参考资料
学习视频:https://www.bilibili.com/video/BV1px421y7qU

![[HackMyVM]靶场 Wild](https://img-blog.csdnimg.cn/direct/b4c47be59eff48bd8e18ff09c60609e3.png)






![【二分查找】【map]436. 寻找右区间](https://img-blog.csdnimg.cn/f95ddae62a4e43a68295601c723f92fb.gif#pic_center)



