本文通过原理和示例对随机梯度下降进行了详解,并和梯度下降进行了对比分析,简单易懂。
- 随机梯度下降
- 原理
- 示例
- 动态学习率
- 动态学习率
- 示例
- 总结
随机梯度下降
原理

示例
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
def train_2d(trainer, steps=20, f_grad=None): #@save
"""用定制的训练机优化2D目标函数"""
# s1和s2是稍后将使用的内部状态变量
x1, x2, s1, s2 = -5, -2, 0, 0
results = [(x1, x2)]
for i in range(steps):
if f_grad:
x1, x2, s1, s2 = trainer(x1, x2, s1, s2, f_grad)
else:
x1, x2, s1, s2 = trainer(x1, x2, s1, s2)
results.append((x1, x2))
print(f'epoch {i + 1}, x1: {float(x1):f}, x2: {float(x2):f}')
return results
def show_trace_2d(f, results): #@save
"""显示优化过程中2D变量的轨迹"""
plt.figure(figsize=(6, 3))
plt.plot(*zip(*results), '-o', color='#ff7f0e')
x1, x2 = torch.meshgrid(torch.arange(-5.5, 1.0, 0.1),
torch.arange(-3.0, 1.0, 0.1), indexing='ij')
plt.contour(x1, x2, f(x1, x2), colors='#1f77b4')
plt.xlabel('x1')
plt.ylabel('x2')
def f(x1, x2): # 目标函数
return x1 ** 2 + 2 * x2 ** 2
def f_grad(x1, x2): # 目标函数的梯度
return 2 * x1, 4 * x2
def sgd(x1, x2, s1, s2, f_grad):
g1, g2 = f_grad(x1, x2)
# 模拟有噪声的梯度
g1 += torch.normal(0.0, 1, (1,)).item()
g2 += torch.normal(0.0, 1, (1,)).item()
eta_t = eta * lr()
return (x1 - eta_t * g1, x2 - eta_t * g2, 0, 0)
def constant_lr():
return 1
eta = 0.1
lr = constant_lr # 常数学习速度
show_trace_2d(f, train_2d(sgd, steps=50, f_grad=f_grad))
输出:
epoch 1, x1: -4.021846, x2: -1.076427
epoch 2, x1: -3.268095, x2: -0.605968
epoch 3, x1: -2.635950, x2: -0.365234
epoch 4, x1: -1.919869, x2: -0.238383
epoch 5, x1: -1.398639, x2: -0.098951
epoch 6, x1: -1.121853, x2: -0.104999
epoch 7, x1: -0.872707, x2: -0.064939
epoch 8, x1: -0.867427, x2: -0.210833
epoch 9, x1: -0.693494, x2: -0.037735
epoch 10, x1: -0.439256, x2: -0.120039
epoch 11, x1: -0.271984, x2: -0.087188
epoch 12, x1: -0.114489, x2: 0.089921
epoch 13, x1: -0.030704, x2: 0.034423
epoch 14, x1: 0.025138, x2: 0.039062
epoch 15, x1: 0.079952, x2: 0.154875
epoch 16, x1: -0.031280, x2: 0.187696
epoch 17, x1: 0.015347, x2: 0.018523
epoch 18, x1: -0.117373, x2: 0.125311
epoch 19, x1: -0.115787, x2: 0.256176
epoch 20, x1: 0.061688, x2: -0.018338
随机梯度下降迭代过程:
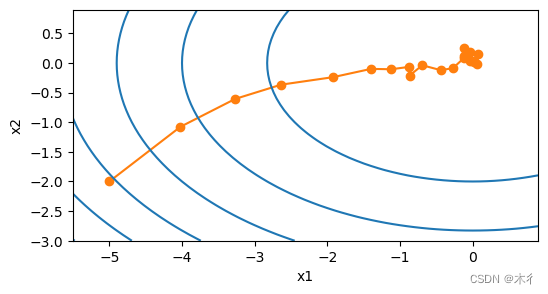
梯度下降迭代过程:
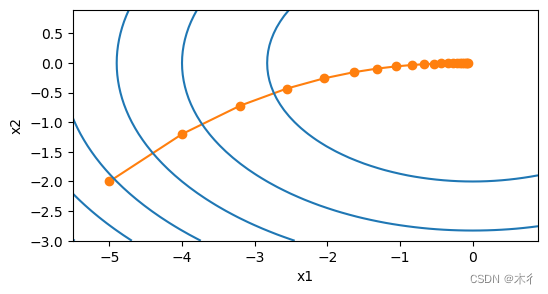
从上面的两个图对比可以看出,随机梯度下降中变量的轨迹比梯度下降中的轨迹更混乱一些。这是由于梯度的随机性质。也就是说,即使我们接近最小值,我们仍然受到通过的瞬间梯度所注入的不确定性的影响。即使经过20次迭代,质量仍然不那么好。更糟糕的是,经过额外的步骤,它不会得到改善。这给我们留下了唯一的选择:改变学习率。但是,如果我们选择的学习率太小,我们一开始就不会取得任何有意义的进展。另一方面,如果我们选择的学习率太大,我们将无法获得一个好的解决方案,如上所示。解决这些相互冲突的目标的唯一方法是在优化过程中动态降低学习率。
动态学习率
动态学习率
用与时间相关的学习率n(t)取代n增加了控制优化算法收敛的复杂性。特别是,我们需要弄清n的衰减速度。如果太快,我们将过早停止优化。如果减少的太慢,我们会在优化上浪费太多时间。以下是随着时间推移调整n时使用的一些基本策略(稍后我们将讨论更高级的策略):
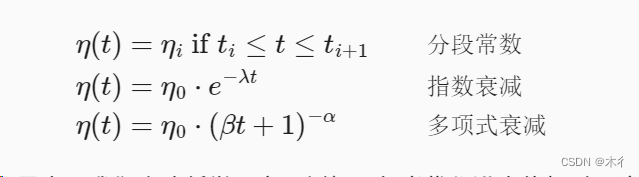
在第一个分段常数(piecewise constant)场景中,我们会降低学习率,例如,每当优化进度停顿时。这是训练深度网络的常见策略。或者,我们可以通过指数衰减(exponential decay)来更积极地减低它。
示例
import math
def exponential_lr():
# 在函数外部定义,而在内部更新的全局变量
global t
t += 1
return math.exp(-0.1 * t)
t = 1
lr = exponential_lr
show_trace_2d(f, train_2d(sgd, steps=1000, f_grad=f_grad))
epoch 1, x1: -4.210943, x2: -1.249196
epoch 2, x1: -3.593916, x2: -0.855586
epoch 3, x1: -3.100004, x2: -0.743650
epoch 4, x1: -2.810694, x2: -0.598492
epoch 5, x1: -2.505691, x2: -0.404280
''''
''''
''''
epoch 993, x1: -0.832819, x2: 0.002843
epoch 994, x1: -0.832819, x2: 0.002843
epoch 995, x1: -0.832819, x2: 0.002843
epoch 996, x1: -0.832819, x2: 0.002843
epoch 997, x1: -0.832819, x2: 0.002843
epoch 998, x1: -0.832819, x2: 0.002843
epoch 999, x1: -0.832819, x2: 0.002843
epoch 1000, x1: -0.832819, x2: 0.002843
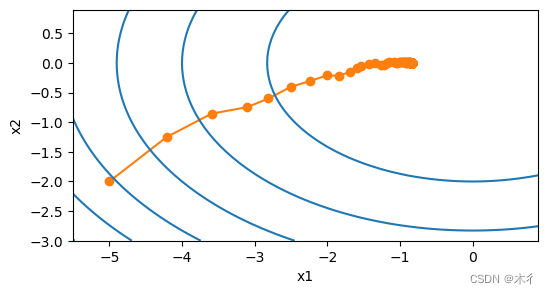
与上图的进行对比可知,效果已经有了较大提升,但距离真实解还有一定差距。
这也是现在为什么模型训练时,要添加学习率衰减或者余弦等策略,让学习率动态变化,需要快的地方学习率大一些,需要慢的地方,学习率小一些。
总结
- 随机梯度下降相较于梯度下降,计算量会小很多。
- 合理的调整学习率,将有助于收敛和避免陷入局部最优解。