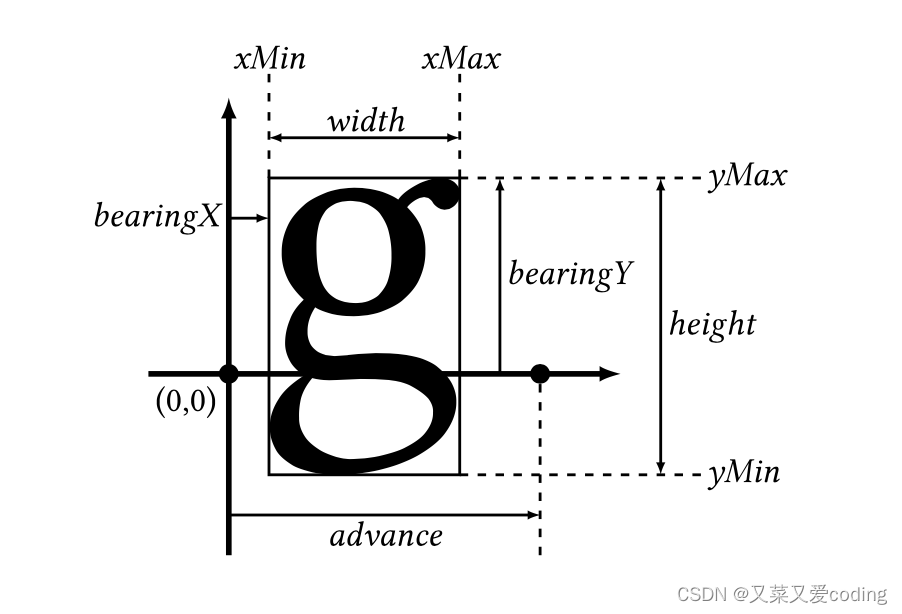
在大语言模型领域,闭源模型正在赢得比赛,无论是 OpenAI 还是刚刚发布新模型的 Anthropic,都是闭源模型的代表。
但在文生图领域,开源模型却表现出了足够强的竞争力。
2 周前,开源模型的代表企业 Stability AI 发布了最新的文生图模型 Stable Diffusion 3,采用了与 Sora 相同的底层架构(DiT,Diffusion Transformer),但是没有公布细节。
昨天,Stability AI 发布研究论文《Scaling Rectified Flow Transformers for High-Resolution Image Synthesis》,详细地介绍了 Stable Diffusion 3 的底层技术。
在该论文里,Stability AI 发布了一种新的多模态 DiT(MMDiT,Multimodal Diffusion Transformer)模型架构,对图像与语言表示使用单独的权重集。与之前的 SD3 版本相比,新版本提高了文本理解和拼写能力。
Stable Diffusion 3 可能是目前世界上最好的文生图模型。Stability AI 表示,基于人类偏好评估,Stable Diffusion 3 在排版和提示词遵守方面,优于 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α 在内的各种开源模型,追平或超越了 DALL·E 3、Midjourney v6 和 Ideogram v1 等最先进的闭源模型。
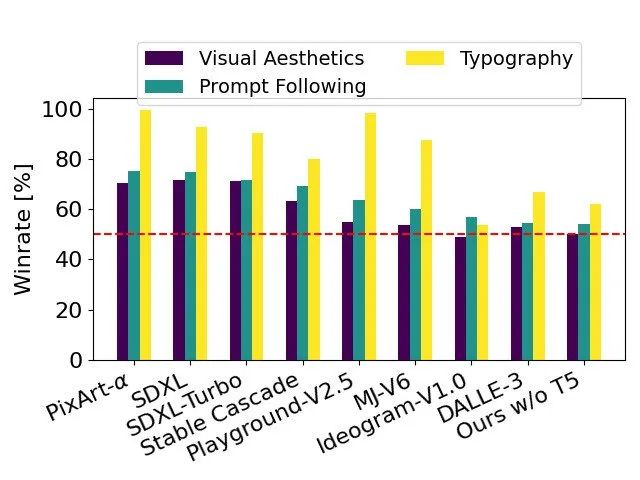
以 SD3 作为基线,该图表根据人类对视觉美学、提示跟随和版式的评估,概述了它在与竞争模型中获胜的领域。
在早期发布期间,Stability AI 将会提供 800M 到 8B 不同参数版本的模型,来降低用户使用门槛。其中,8B 参数的 Stable Diffusion 3 适合 RTX 4090 的 24 GB VRAM,在使用 50 个采样步骤时,生成 1024x1024 分辨率的图像需要 34 秒。
不过,目前要想体验 Stable Diffusion 3 ,仍要加入候补名单。
跟当红的闭源模型 DALL-E 3、Midjourney 不同,Stability AI 始终把开源作为武器。
Stability AI 创始人兼CEO Emad Mostaque 此前曾表示,与视频、语言、代码、3D、音频等一样,Stable Diffusion 3 也将会开源。
Stable Diffusion 3发布后,一位用户在 X 上评论道:“当开源赢得比赛时,你不喜欢它吗?”
随后,Emad Mostaque 转发了这条帖子。
关注公众号「甲子光年」,后台回复“SD3”,获取《Scaling Rectified Flow Transformers for High-Resolution Image Synthesis》论文原文。
1.超越 DiT 的新架构
![]()
先看一下 Stable Diffusion 3 的架构细节。
MMDiT 是一个多模态架构,旨在处理文本和图像两种模态的数据。这是因为在文本到图像的生成过程中,模型需要理解和转换文本信息,并将其转化为相应的图像内容。
为了获取合适的文本和图像表示,Stability AI 使用了预训练模型。具体来说,他们使用了两个 CLIP 模型和一个 T5 模型来编码文本表示,以及一个改进的自编码器模型来编码图像标记。
MMDiT 架构基于 DiT,它由 Sora 核心成员之一Peebles,与谢赛宁在 2023 年合作发布。MMDiT 为文本和图像模态分别使用了两套独立的权重,这相当于为每种模态创建了独立的变换器,但在注意力操作中将两种模态的序列结合起来,使得两种表示可以在各自的空间中工作,同时考虑到对方。
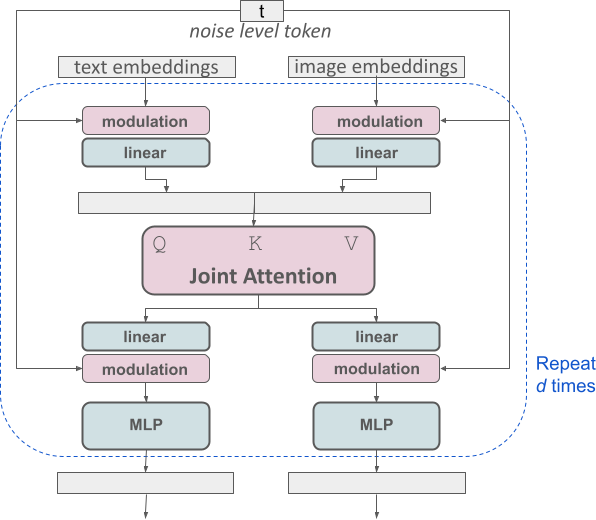
改进的多模态扩散变压器块的概念可视化:MMDiT。
这种设计允许信息在图像和文本标记之间流动,从而提高了模型对文本的理解和生成图像的排版质量。这种双向信息流对于生成与文本描述紧密对应的图像至关重要。
Stability AI 将 MMDiT 架构与现有的文本到图像生成骨干网络(如 UViT 和 DiT )进行了比较。在训练过程中,MMDiT 在视觉保真度和文本对齐方面表现出色,超越了这些已建立的架构。
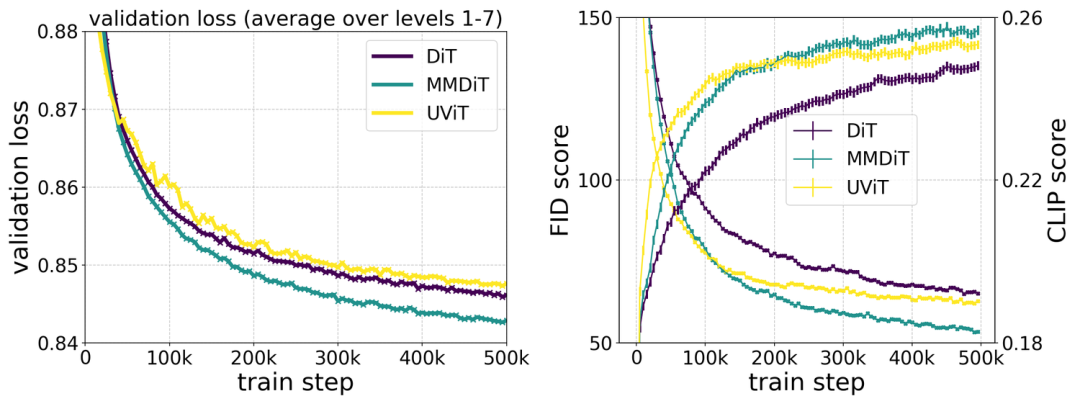
MMDiT 架构不仅适用于图像生成,还可以轻松扩展到其他模态,如视频。这为未来的多模态生成任务提供了灵活性。
得益于 Stable Diffusion 3 改进的提示跟随功能,模型能够创建专注于各种不同主题和质量的图像,同时对图像本身的风格保持高度灵活性。

除了底层的新架构,Stable Diffusion 3 还用到了三种新的训练方法。
一是通过重新加权改善修正流(Rectified Flows)。
修正流是一种新兴的生成模型公式,在训练过程中需要模拟从数据到噪声的直线路径。尽管这种方法在理论上具有优势,但在实际应用中,尤其是在多步采样过程中,性能可能会下降。
为了解决这个问题, Stability AI 提出了一种新的训练策略,即在训练过程中对轨迹的中间部分赋予更多的权重。这种策略基于假设:轨迹的中间部分对于模型来说更具挑战性,因为在这个区域,噪声和数据的分布差异较大,预测任务更为困难。
Stability AI 进行了广泛的实验,将他们的重新加权修正流模型与其他 60 种不同的扩散轨迹进行了比较。这些扩散轨迹包括 LDM、EDM 和ADM 等,实验使用了多个数据集、评估指标和采样器设置。
实验结果显示,传统的修正流模型在少步采样制度中表现良好,但随着采样步骤的增加,其性能相对下降。相比之下,Stability AI 提出的重新加权修正流模型在所有测试中都显示出一致的性能提升。
二是 Scale——扩大修正流的 Transformer 模型的规模。
Model Scaling 几乎已经成为大模型研究的必杀技,Stability AI 也不例外,目标是通过增加模型的深度(即注意力块的数量)和参数数量来提高模型的性能。
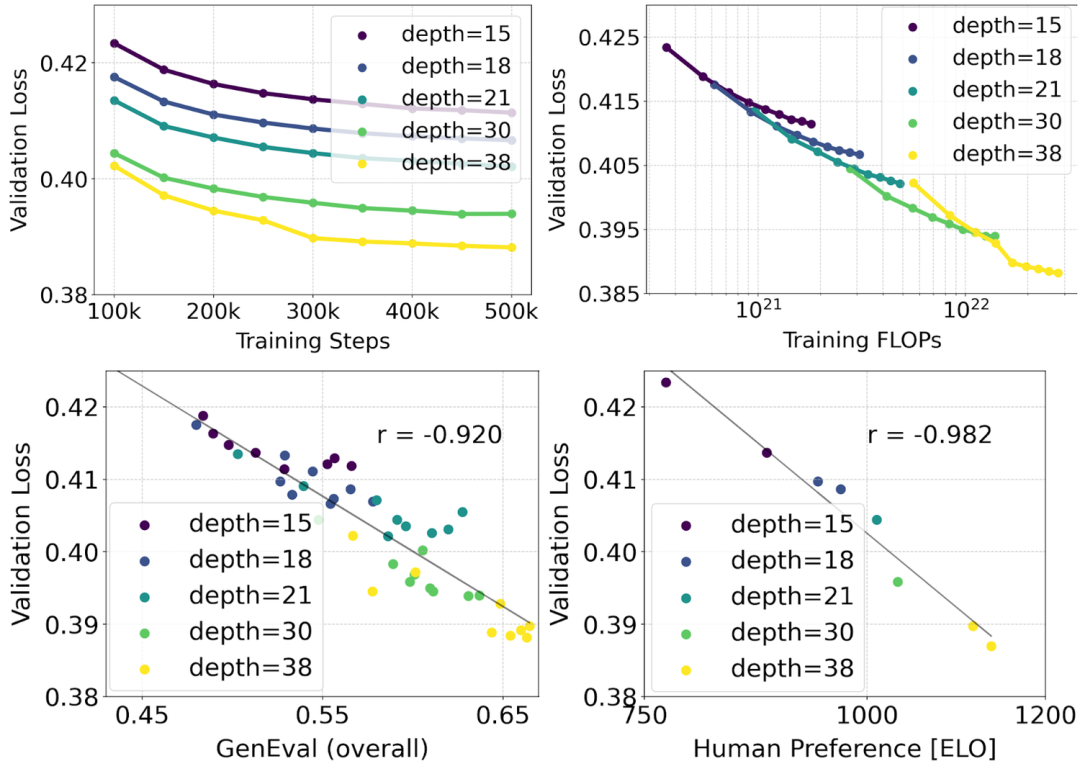
Stability AI 训练的模型范围从 15 个具有 450M 个参数的块到 38 个具有 8B 个参数的块,并观察到随着模型规模的增加和训练步骤的进行,验证损失(validation loss)呈现平滑下降的趋势。验证损失是衡量模型在未见过的测试数据上性能的指标,其下降通常意味着模型性能的提升。
为了测试模型输出的质量,Stability AI 还评估自动图像对齐指标(GenEval)以及人类偏好分数(ELO)。实验结果表明,验证损失的降低与自动图像对齐度量和人类偏好评分的提高有很强的相关性。这意味着验证损失可以作为模型整体性能的一个有效预测指标。
此外,scale 的趋势没有显示出饱和的迹象,可以乐观地认为,未来可以继续提高模型的性能。
三是灵活的文本编码器。
文本编码器在文本到图像生成模型中起着关键作用,它们负责将文本输入转换为模型可以理解和处理的表示形式。这些编码器通常是基于预训练的语言模型,如 CLIP 和 T5。
SD3 模型使用了三种不同的文本嵌入器来处理文本输入:两个 CLIP 模型和一个 T5 模型。这些编码器分别处理文本信息,并生成相应的文本表示。
在推理(生成图像)阶段,为了减少内存需求,可以选择性地移除某些文本编码器。例如,移除 T5 模型,这是一个拥有 4.7 亿参数的大型模型,可以显著降低内存占用,但同时可能会对模型性能产生一定影响。
移除 T5 模型后,SD3 模型在视觉美学(图像质量)方面的表现几乎没有变化(胜率保持在 50%),在文本遵循方面的表现略有下降(胜率降至 46%)。 然而,对于生成文本排版方面,性能下降更为明显(胜率降至 38%),这表明 T5 模型在处理复杂文本提示时尤为重要。

Stability AI 强调,尽管移除 T5 模型会牺牲一些性能,但这种灵活性使得 SD3 模型能够适应不同的硬件条件。在资源受限的环境中,用户可以根据需要选择是否使用 T5 模型,以在性能和资源消耗之间做出权衡。
2.逆行中的 Stability AI
![]()
Stability AI 成立于 2019 年,是全球领先的开源生成式 AI 公司。
成立至今,Stability AI 获得过三轮融资。2022 年 10 月,Stability AI 宣布获得 1.01 亿美元融资,由 Coatue、光速创投领投,O'Shaughnessy Ventures 参投,估值达到 10 亿美元。2023 年 5月 1日,Sound Ventures 宣布投资 Stability AI ;11 月,Stability AI 获得英特尔投资的 5000 万美元。
Stability AI 创始人兼 CEO Emad Mostaque 是一位在英国长大的印度裔,毕业于牛津大学,获得数学和计算机科学硕士学位,创业之前他曾在多家对冲基金担任分析师。
Emad Mostaque 的创业的动机是个人对 AI 的迷恋,以及他认为开源 AI 社区缺乏“组织”。Mostaque 曾在采访中表示,“计划使用我们的计算来加速开源基础人工智能。”
让 Stability AI 声名鹊起的是在 2022 年 9 月开源的文生图模型 Stable Diffusion,此后 AI 绘画很快成为生成式 AI 最热门的领域,而 Emad Mostaque 也顺理成章地成为“有史以来最受欢迎的开源软件”的首席布道者。
然而,2023 年 Stability AI 被曝出一系列“丑闻”,其中一条便是 Stable Diffusion 的知识产权归属问题。
原来,Stable Diffusion 并非由 Stability AI 研发,而是由其所赞助。Stable Diffusion 由慕尼黑大学、海德堡大学和 Runway 合作开发,Stability AI 只是作为“金主”,通过 AWS 为其提供了大约 4000 张 A100 芯片。
只不过,Stability AI 在宣传的时候,故意模糊了这一点。
除了 Stable Diffusion 的归属权争议,Stability AI 在 2023 年过得并不顺利,至少有 15 位核心高管先后离职。2023 年 6 月,福布斯发布的一则长新闻在网上发酵,30 多位 Stability AI 的前员工和投资人现身说法,细数 Emad Mostaque 的 9 大罪证,包括窃取 Stable Diffusion 成果,隐瞒融资困难,夸大公司收入,拖欠员工工资,学历和工作经历造假等等。
一系列负面舆论也让 Stability AI 的发展前景蒙上了一层阴影。
不过,Stability AI 并没有停下脚步。现在,Stability AI 不再是一家单独的文生图模型公司,其模型矩阵涵盖了视频、音频、3D 和语言模型等多个领域——
-
2023 年 9 月,推出首个音乐和声音生成模型 Stable Audio;
-
2023 年 11月,推出首个视频模型 Stable Video Diffusion;
-
2023年 12 月,推出首个图生3D模型 Zero123;
-
2024年 1 月,先后推出其第一个代码模型 Stable Code 3B 与第一个语言模型Stable LM 2 1.6B。
Stability AI 始终把开源开放作为核心战略。在 X 的主页置顶消息上,Emad Mostaque 写道:“我们致力于开放模型,已提供超过 2000 万小时的 A100 资助,用于跨社区开展人工智能研究和项目。Stable Diffusion 3 将公开发布,视频、语言、代码、3D、音频等也是如此。开放合作才是出路。”

近期,Stability AI 还先后与两家 AI 公司达成合作。在 AI 视频领域,Morph AI 成为 Stability AI 首位视频产品领域的合作伙伴;在AI 3D 领域,Stability AI 与 Tripo AI 合作开发了TripoSR,从单个图像快速生成 3D 图像。
Stability AI 正在试图通过一系列产品矩阵与开源开放赢得用户。在激烈的 AI 竞赛中,Stability AI 会走多远?
(封面图来自 Stability AI)