当CV遇上transformer(一)ViT模型
-
我们知道计算机视觉(Computer Vision),主要包括图像分类、目标检测、图像分割等子任务。
- 自AlexNet被提出以来,CNN成为了计算机视觉领域的主流架构。
- CNN网络结构主要由卷积层、池化层以及全连接层3部分组成,其工作原理是通过不断堆叠的卷积层慢慢扩大感受野直至覆盖整个图像,来进一步实现对图像从局部到全局的特征提取。
- 然而,由于感受野的大小受限,CNN在浅层网络提取到的局部信息有限,在捕获全局上下文信息方面缺乏效率,缺少对图像的整体感知和宏观理解。
- 受自注意(self-attention)机制在NLP领域成功应用的启发,一些基于CNN的模型尝试通过
引入注意力层(如:CCNet、SENet、Non local neural networks等)或直接用注意力模块替代卷积层(如:注意力增强卷积网络Attention augmented convolutional networks等)来打破卷积带来的局限性,但建模全局关系的能力仍然有限。
-
Transformer是一种基于注意力的编码器解码器架构,其凭借
长距离建模能力与并行计算能力在NLP领域取得了重大突破,并逐步拓展应用至CV领域。- 2020年5月,Carion创新性地将Transformer应用于目标检测领域(DETR),设计了一种新的目标检测框架。
- 2020年10月,Dosovitskiy首次将纯Transformer的网络结构应用于图像分类任务中(ViT),并取得了当时最优的分类效果,其研究成果是Transformer完全替代标准卷积的首次尝试。
- 此后,涌现了许多基于Transformer的视觉模型。

-
今天我们了解一下首次将纯Transformer的网络结构应用于图像分类任务中的ViT模型。ViT模型最大的创新点就是将transformer应用于图像分类的cv任务,证明在cv领域使用Transformer依然可以获得很好的性能,启发了后面基于transformer的目标检测和语义分割等网络。
-
原文连接:ViT模型 (arxiv.org)
1 ViT模型的结构
1.1 ViT的整体框架
Dosovitskiy等人首次使用Transformer结构(Encoder)来完成图像分类任务,提出了一种完全基于注意力机制的ViT模型。
我们先来看看ViT的整体框架,如下图所示:

-
将Transformer结构应用到CV领域,那么首先要解决的就是
如何将一张图像转变为一个序列。-
从变量的维度来看,NLP中的输入往往是二维的tensor,而CV中往往是一个三维的RGB图像。【都忽略了Batch维度】。
-
这种维度的不统一会导致我们不能直接将图片数据喂入到Transformer结构中去,而是需要进行一定的维度转换,即将三维的tensor转换成二维的tensor,这个过程被称为patch_embedding。
-
-
ViT模型中处理流程如下图所示:
- 一张3×8×8的图片,每个块(patch)的尺寸为3×4×4,将图片分为4个块。
- 实现过程是:通过一个卷积核大小为4×4、步长为4、输出通道为48的卷积,得到48×2×2的输出。
- 得到48×2×2的输出,然后将其按照宽高进行Flatten,其shape变成48×4,然后转换下维度,变成4×48,表示为4个序列,每个序列长度为48。
- 这步使用卷积很巧妙,我们得到的4×48的二维向量,其实每一行即1×48都包含了原图中3×4×4大小的patch,这就是卷积的提取特征的功能。即先用一些CNN模型来对图片提取特征,只要使CNN最后的输出维度为4×48,最后在送入Transformer模型中。

-
为了保留位置信息,ViT采用绝对位置编码,并将其与嵌入序列相加。另外,ViT参考Bert,在一系列输入序列中插入一个专门用于分类的标志位(Class Token),再输入多层Transformer结构中。
-
最后将cls token取出来通过一个MLP(多层感知机)用于分类。
1.2 ViT模型的详细结构
ViT模型的详细结构如下,可以将其分为预处理、Transformer模块和分类模块。

在论文中给出了三个模型(Base Large Huge)的参数,如下:
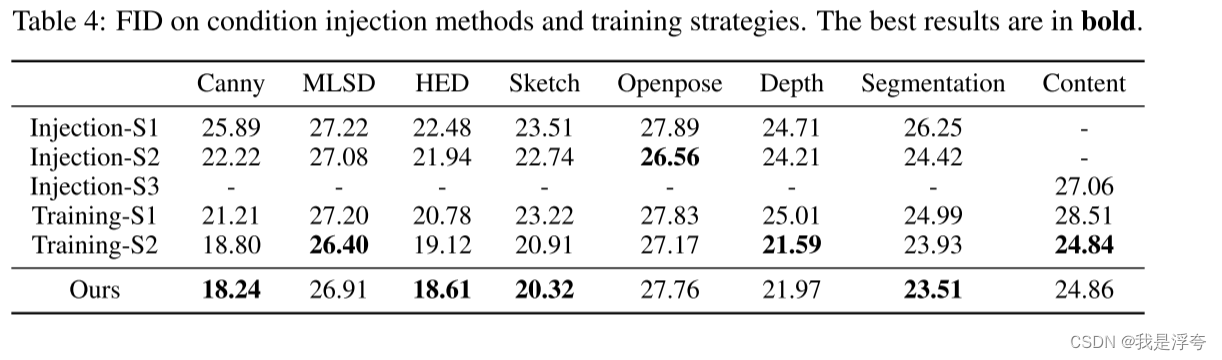
| Model | Patch size | Layers | Hidden Size | MLP size | Heads | Params |
|---|---|---|---|---|---|---|
| VIT-Base | 16*16 | 12 | 768 | 3072 | 12 | 86M |
| VIT-Large | 16*16 | 24 | 1024 | 4096 | 16 | 307M |
| VIT-Huge | 14*14 | 32 | 1280 | 5120 | 16 | 632M |
-
Patch size为将一张图片分成小块每小块的尺寸,在代码中其实就是卷积核的尺寸。
-
Layers表示encoder结构重复的次数。
-
Hidden Size为通过输入encoder前每个token的维度,其实就是卷积核的个数。
-
MLP size是在encoder结构中的MLP Block中第一个全连接层的节点个数。
-
Heads表示Multi-Head Attention的Heads数目。
-
params表示模型所用参数大小。
1.2.1 预处理模块
预处理模块的结构如下图所示。处理流程和1.1中讲的一样,如下:
- 一张224×224×3的图片,通过一个卷积核大小为16×16、步长为16、输出通道为768的卷积,得到14×14×768的输出。
- 得到14×14×768的输出,然后将其按照宽高进行Flatten,其shape变成196×768,表示为196个序列,每个序列长度为768。
- 在196×768的数据上,concat一个1×768的分类token在最前面。则shape变成197×768。我们设这个197×768的矩阵为 A 。
- 设置一个1×197×768的Position Embedding,对应值相加至 A 。

1.2.2 多层Transformer模块
-
多层Transformer模块,顾名思义就是多次叠加Transformer Encoder模块。
-
Transformer Encoder模块主要有两个部分,一个是Muti-head Attention,另一个是MLP。
-
由Self-attention和MLP可以组合成Transformer Encoder的基本模块。Transformer Encoder的基本模块还使用了残差连接结构。
-
不了解Transformer的,可以先看看NLP领域的Transformer相关资料。
-
pytorch中已经实现了TransformerEncoder(如下代码),先构造TransformerEncoderLayer,然后堆叠num_layers即可。
# 将token_embedding送入到transformer的encoder中
encoder_layer = nn.TransformerEncoderLayer(d_model=model_dim, nhead=8)
transformer_encoder = nn.TransformerEncoder(encoder_layer=encoder_layer, num_layers=12)
encoder_output = transformer_encoder(token_embedding) # 忽略mask
1.2.3 分类模块
-
分类很简单,就是取特征层如197×768的第一个向量,即1×768。
-
然后,再对此进行线性全连接层进行多分类即可。

1.3 利用pytorch简单实现ViT模型
我们这里简单实现下ViT模型,后续会找开源代码进行分析:
import torch
import torch.nn as nn
def image2emb_conv(image, patch_size):
# 二维卷积得到embedding
# 1、对图像做2维卷积
# 2、输出的特征图拉直
conv = nn.Conv2d(in_channels=image.shape[1], out_channels=patch_size*patch_size*image.shape[1], kernel_size=patch_size, stride=patch_size)
conv_output = conv(image)
bs, channel, oh, ow = conv_output.shape
# oh * ow为序列长度(seq_len),需要放到中间
# channel是emb_dim
patch_embedding= conv_output.reshape((bs, channel, oh * ow)).transpose(-1, -2)
return patch_embedding
if __name__ == '__main__':
# step 1 将图片转换为embedding
bs, channel, image_h, image_w = 3, 3, 224, 224
image = torch.randn((bs, channel, image_h, image_w))
patch_size = 16
patch_embedding_conv = image2emb_conv(image, patch_size)
model_dim = patch_embedding_conv.shape[2]
print('图片转换为embedding后,shape = ', patch_embedding_conv.shape)
# step 2 增加分类的token embedding
cls_token_embedding = torch.randn((bs, 1, model_dim), requires_grad=True)
# 在序列维度(seq_len)进行拼接
token_embedding = torch.cat([cls_token_embedding, patch_embedding_conv], dim=1)
print('增加分类的token embedding后,shape = ', token_embedding.shape)
# step 3 增加位置编码
max_num_token = 1000
position_embedding_table = torch.randn((max_num_token, model_dim), requires_grad=True)
seq_len = token_embedding.shape[1]
# 位置编码复制,复制bs份
position_embedding = torch.tile(position_embedding_table[:seq_len], [token_embedding.shape[0], 1, 1])
token_embedding += position_embedding
# step 4 将token_embedding送入到transformer的encoder中
encoder_layer = nn.TransformerEncoderLayer(d_model=model_dim, nhead=8)
transformer_encoder = nn.TransformerEncoder(encoder_layer=encoder_layer, num_layers=12)
encoder_output = transformer_encoder(token_embedding) # 忽略mask
print('经过transformer的encoder后,shape = ', encoder_output.shape)
# step 5 做分类
cls_token_output = encoder_output[:, 0, :]
print('取出cls token输出后,shape = ', cls_token_output.shape)
num_classses = 10
label = torch.randint(num_classses, (bs,))
linear_layer = nn.Linear(model_dim, num_classses)
logits = linear_layer(cls_token_output)
print('logits shape = ', cls_token_output.shape)
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(logits, label)
print(loss)
图片转换为embedding后, shape = torch.Size([3, 196, 768])
增加分类的token embedding后,shape = torch.Size([3, 197, 768])
经过transformer的encoder后,shape = torch.Size([3, 197, 768])
取出cls token输出后, shape = torch.Size([3, 768])
logits shape = torch.Size([3, 768])
tensor(2.8507, grad_fn=<NllLossBackward0>)
2 ViT相关结论
2.1 论文中相关结论
2.1.1 ViT更需要预训练
-
ViT的模型整体参数量是较大的,一个ViT-base的预训练权重就高达400M,相较于MobileNet-v2的13M和ResNet34的85M,超出较多。所以,ViT模型相较于CNN网络更加需要大数据集的预训练。
-
文中做了一个实验,使用不同规模的ImageNet和JFT数据集,进行预训练,比较其与CNN模型的性能(如下图)。
- 在数据量较小时,无论是在ImageNet还是JFT数据集,BiT(以ResNet为骨干的CNN模型)准确率相对更高。(注:这三个数据集数据量越来越大)
- 但是当数据集量增大到一定程度时,ViT模型略优于CNN模型。
- 所以,ViT模型更需要大数据集进行预训练,以提高模型的表征。

2.1.2 ViT模型更容易泛化到下游任务
-
对于CNN网络,即使有预训练权重,当使用这个网络泛化到其他下游任务时,也需要训练较长时间才能达到较好的结果。
-
但是,对于ViT模型来说,当拥有ViT的预训练权重时,只需要训练几个epoch既可以拥有很好的性能。
2.1.3 ViT模型存在的问题
ViT首次将Transformer应用于图像分类任务,打破了传统卷积网络的框架限制,为视觉特征学习提供了一种新的
范式,但其主要存在以下问题:
-
1、数据需求大。
- 自注意力归纳偏置能力较CNN弱,需要基于更多的数据去自动学习假设。
-
2、局部信息缺失。
- Transformer通过计算每对图像块之间的注意力权重来聚合全局信息,使得每一个图像块都具备任何其他图像块的信息,可以有效地建模图像块之间的长距离依赖关系。
- 但Transformer直接将单个图像块通过线性变换进行序列化,使ViT无法对图像的局部结构(如边缘、线条)进行建模,忽略了对单个图像块局部特征的提取。
-
3、计算复杂度高。
- 自注意力机制计算复杂度与
token数量呈平方关系,且在ViT结构中token数以及通道数始终保持不变,算法效率低下,运算时间长。
- 自注意力机制计算复杂度与
-
4、堆叠层数受限。
- 随着模型层数的加深,注意力图会逐渐相似,甚至趋于相同。换言之,模型无法有效地提取丰富的
特征,导致模型性能迅速饱和。
- 5、位置编码方式缺乏灵活性。
- ViT使用的绝对位置编码方式无法处理不同分辨率大小的图片,模型的灵活性进一步受限。
针对上述问题,研究人员提出了很多的改进模型,主要包括下面的方向:
- 结合CNN的Transformer,如CoAtNet。
- 全局与局部信息交互的Transformer,如Swin Transformer。
- 多尺度序列交互的Transformer,如PVT模型。
- 深层Transformer
- 针对位置编码改进的Transformer,如PEG模型。