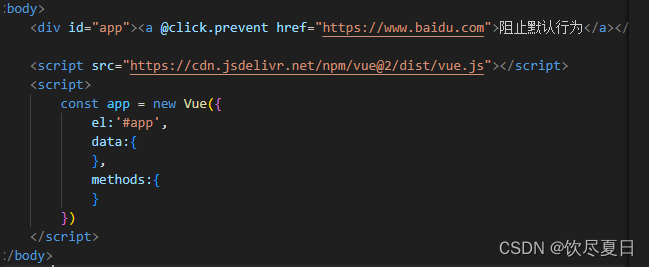
一般这两个东西相互配合使用

pd.Series

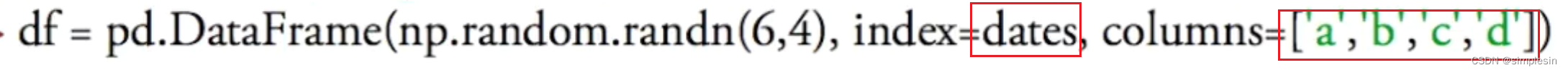

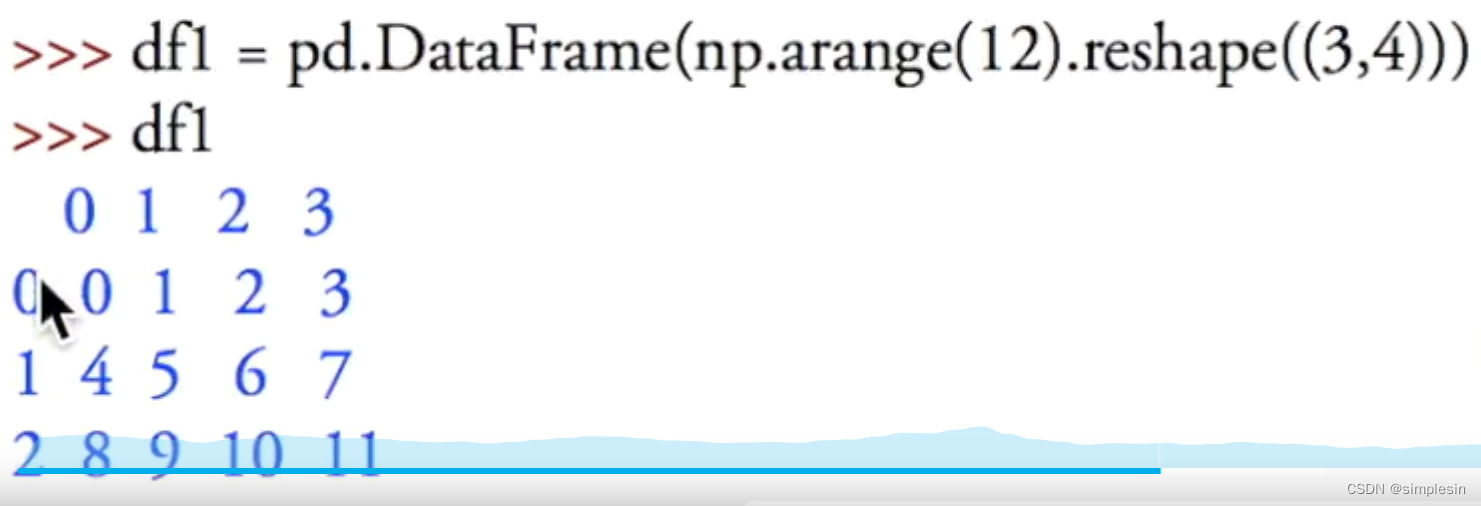
若没有给定行和列的话,就会自动给0,1,2,3,4



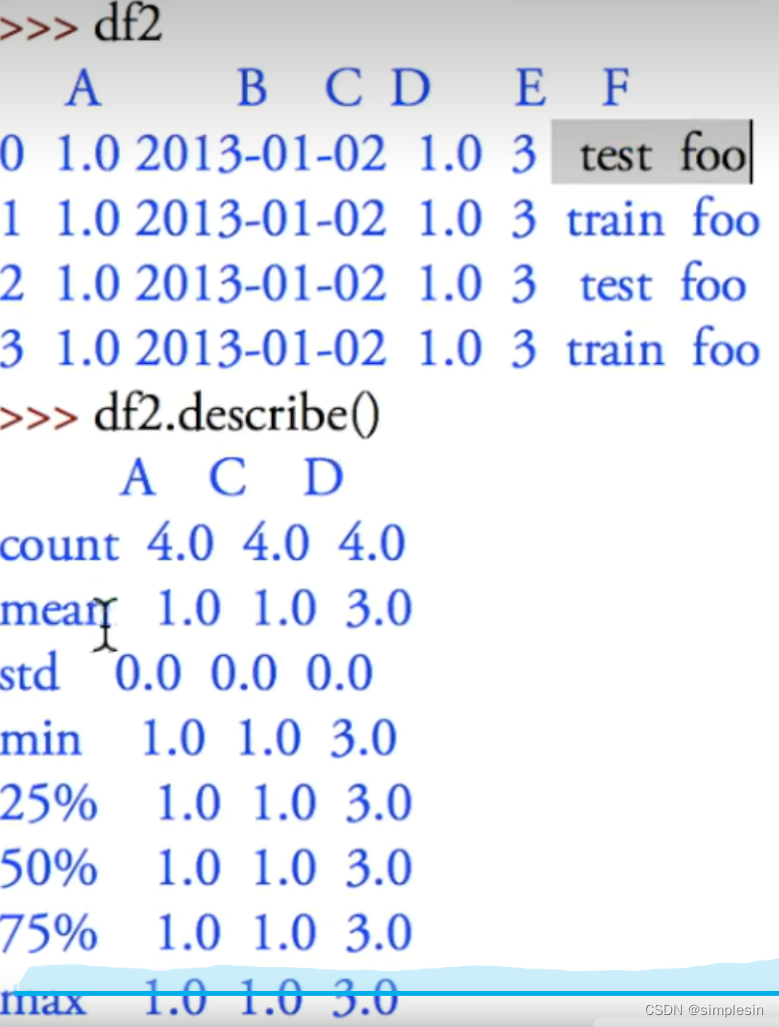
describe= 只能描述数字,不可以描述字符串
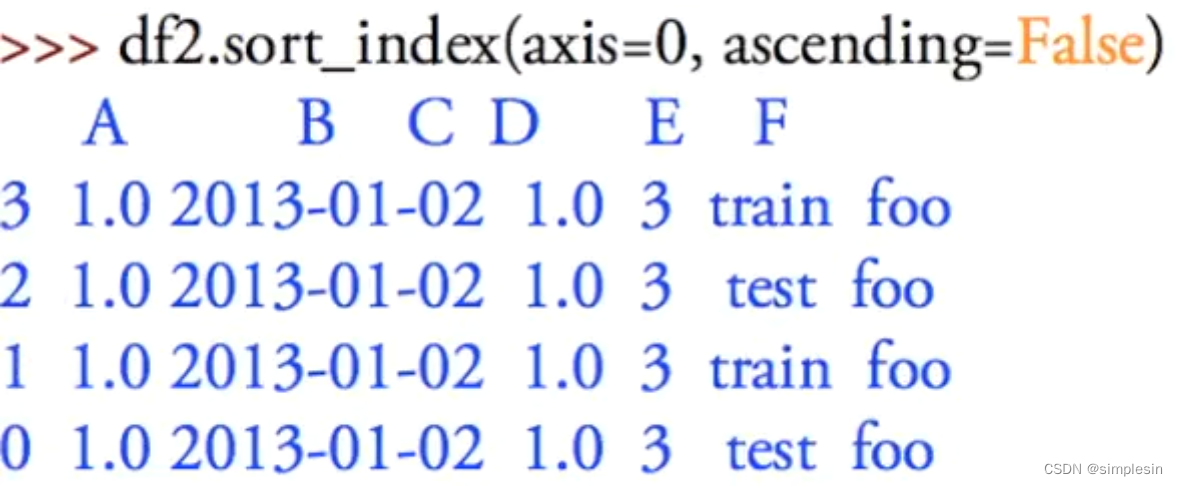

ascending=false:倒序




一般的截取方式
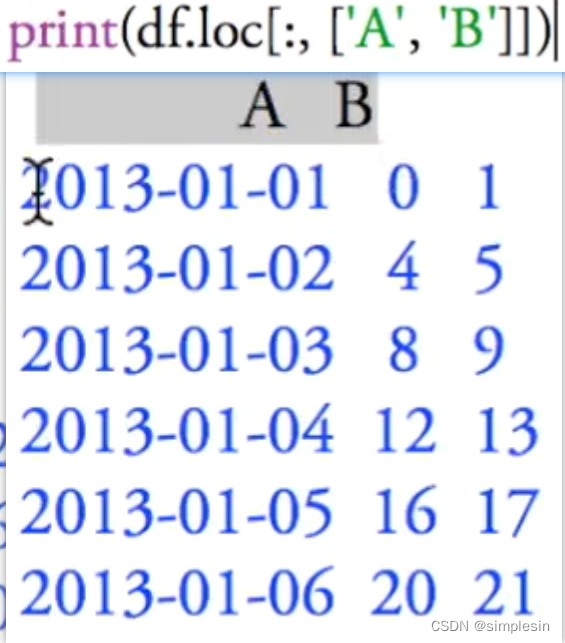

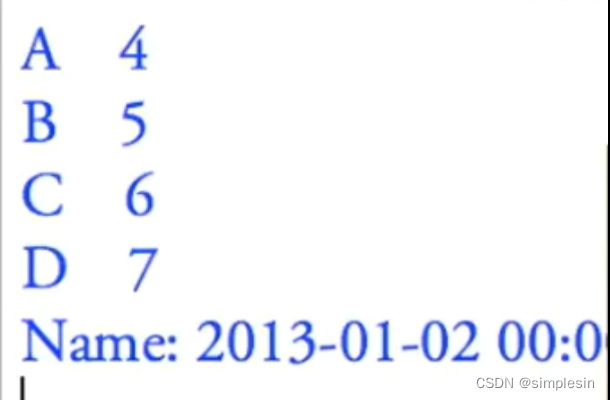
特定的选取方式


有这三种挑选方式


一些改变某些值的方法
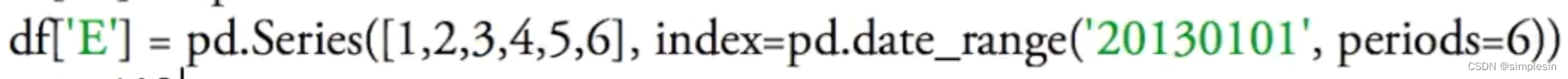
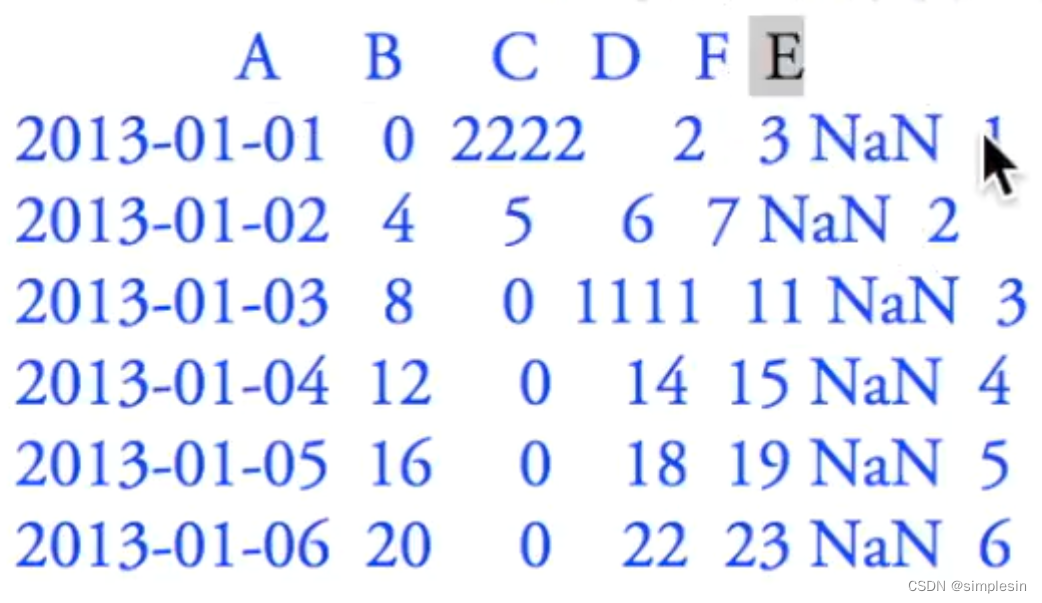
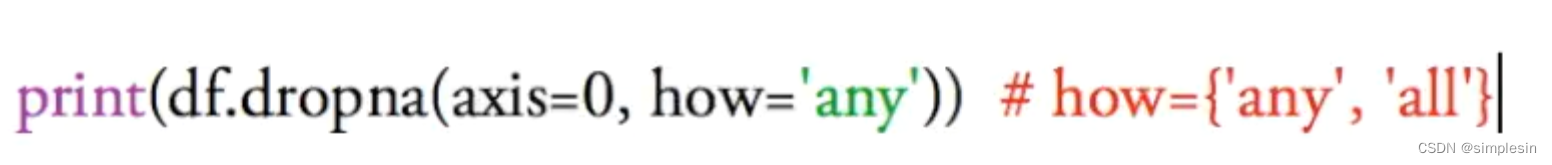 df.dropna=丢掉有nan的东西
df.dropna=丢掉有nan的东西
axis = 指定是丢掉行还是丢掉列
若how = ‘any’,就说明只要这一行/列有nan,就丢掉
若how = ‘all’,就说明只有这一行/列都有nan,才丢掉

df.fillna = 填充nan值,把nan改为value的值,这里的意思就是把值为nan变成值为0
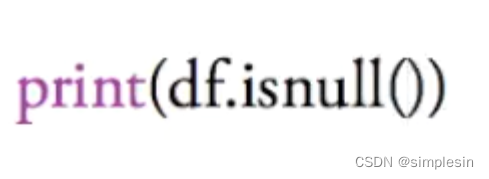
df.isnull = 看是否有nan,若有nan,则那个位置是True,若没有缺失数据,则不为nan,则返回False
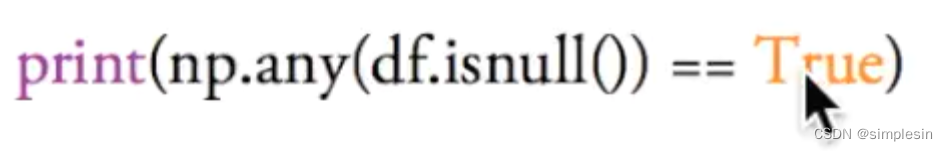
np.any(df.isnull()) == true :若有一个及以上的True,则返回True,就说明起码有一个nan在表格当中,用于大规模数据的排查。



 ignore_index = True = 忽略原来的序号排列,重新排列
ignore_index = True = 忽略原来的序号排列,重新排列
![]()

outer:补齐,如果a有,b没有,合并的时候,补齐,用nan补齐 ,如果b有,a没有,合并的时候,补齐,用nan补齐
![]()

inner:最后只保留两者共有的部分,其他的都不要
![]()
join_axes = 只考虑df1.index 的序号排列,以df1为准
若df1有的,df2没有,则合并的时候,用nan补充,
若df1没有的,df2有,则合并的时候,舍去
听说这个方法新版本已经舍弃了?