目录
一 . 前言
二 . 优化方法
1 . 索引
(1)数据构造
(2)单索引
(3)explain
(4)组合索引
(5)索引总结
2 . 避免使用select *
3 . 用union all代替union
4 . 批量操作
5 . 多用limit
6 . in中值太多
7 . 增量查询
8 . 高效的分页
9 . 用连接查询代替子查询
10 . join的表不宜过多
11 . join时要注意
12 . 控制索引的数量
13 . 选择合理的字段类型
14 . 提升group by的效率
三 . 参考资料
一 . 前言
SQL优化是为了提高数据库查询的性能和效率。在应用程序响应以及数据处理方面,数据库操作通常是性能瓶颈之一,尤其是在处理大量数据或者并发请求的情况下。进行SQL优化可以带来以下几个好处:
-
提高查询速度: 减少查询执行的时间,从而加快响应速度。这对于用户体验至关重要,尤其是在在线交易系统和网站应用中。
-
减少资源消耗: 减少数据库服务器的负载和资源消耗,包括CPU、内存和磁盘IO等,从而提高整个系统的性能和可伸缩性。
-
降低数据库锁定和阻塞: 减少数据库锁定和阻塞的可能性,提高系统的并发处理能力,从而避免因为等待资源而导致的性能下降。
-
节省成本: 通过减少服务器资源的使用和提高系统的吞吐量
二 . 优化方法
1 . 索引
(1)数据构造
我们先创建库以及表,并且在表中插入300万数据量,下列是表语句SQL
-- mtc_base.t_mine definition
CREATE TABLE `t_mine` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`SN` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`DELWHOSN` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`SNINGOVS` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`MINECODE_S` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`MINECODE_C` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`MINECODE_P` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`FULLNAME` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`XVALUE` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`YVALUE` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`ZVALUE` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`NICKNAME` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`PRODUCTIONSTATE` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT '' COMMENT '煤矿生产状态',
`MINECODE_V` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`OUTLINE` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`DATETIME` datetime DEFAULT NULL,
`MINECODE` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`NICKNAME_OLD` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
PRIMARY KEY (`ID`),
) ENGINE=InnoDB AUTO_INCREMENT=3000001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;插入SQL代码,我需要的数据不同,所以每次我插入100万条之后修改插入数据继续执行
import datetime
from dbutils.pooled_db import PooledDB
import pymysql
import threading
# 创建数据库连接池
pool = PooledDB(pymysql, maxconnections=10, host='192.168.14.93', user='root', password='abc123', database='mtc_base',
charset='utf8')
# 定义插入数据的函数
def insert_data_batch(data_batch):
# 从连接池获取连接
connection = pool.connection()
cursor = connection.cursor()
# 批量插入数据
try:
sql = "INSERT INTO t_mine (SN, DELWHOSN, SNINGOVS, MINECODE, MINECODE_S, MINECODE_C, MINECODE_P, NICKNAME_OLD, FULLNAME, XVALUE, YVALUE, ZVALUE, NICKNAME, PRODUCTIONSTATE, MINECODE_V, OUTLINE, DATETIME) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
cursor.executemany(sql, data_batch)
connection.commit()
except Exception as e:
print("Error:", e)
connection.rollback()
# 关闭游标和连接
cursor.close()
connection.close()
# 定义多线程插入数据的函数
def insert_data_multithread(data, batch_size, num_threads):
data_batches = [data[i:i+batch_size] for i in range(0, len(data), batch_size)]
threads = []
for i in range(num_threads):
thread = threading.Thread(target=insert_data_batch, args=(data_batches[i],))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
if __name__ == "__main__":
# 准备300万条数据,这里使用示例数据代替
data = [('SN003', 'DELWHOSN00-第三次', 'SNINGOVS001-第三次', 'MINECODE001-第三次', 'MINECODE_S001-第三次', 'MINECODE_C001',
'MINECODE_P001', 'NICKNAME_OLD001', 'FULLNAME001', 'XVALUE001', 'YVALUE001', 'ZVALUE001', 'NICKNAME001',
'PRODUCTIONSTATE001', 'MINECODE_V001', 'OUTLINE001', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
for _ in range(2000000)]
# 指定每个批次的大小和线程数量
batch_size = 100000 # 每个批次的大小
num_threads = 10 # 线程数量
# 执行多线程插入数据操作
insert_data_multithread(data, batch_size, num_threads)
(2)单索引
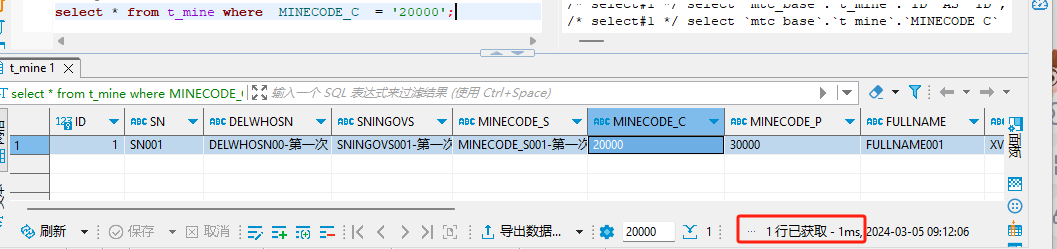
当我们要查询一条数据 (我手动将MINECODE_C一条数据修改为20000)
-
没有索引的时候
使用的全表检索的方式,直接访问文件中的数据,对该列的每一个值进行访问,此时访问文件中数据使用了大量的IO操作,而IO操作是要耗费大量性能
当没有索引的时候300万数据查询时间为 :18秒
这个效率是每个人都接受不来的,因为我们没法等他这么长时间

-
有索引的时候
给 MINECODE_C 字段 创建索引
CREATE INDEX t_mine_MINECODE_C_IDX USING BTREE ON mtc_base.t_mine (MINECODE_C);
索引,其实就相当于书中的目录,它是帮助MySQL系统快速检索数据的一种存储结构。我们可以在索引中按照查询条件,检索索引字段的值,然后快速定位数据记录的位置,这样就不需要遍历整个数据表了。
当有索引的时候300万数据查询时间为 :1 ms
与没有索引查询时间可谓是天差地别
(3)explain
要想知道MySQL中索引是怎么起作用的,我们需要借助explain关键字。
explain关键字能够查看SQL语句的执行细节,包括表的加载顺序,表示如何建立连接的,以及索引的使用情况等。
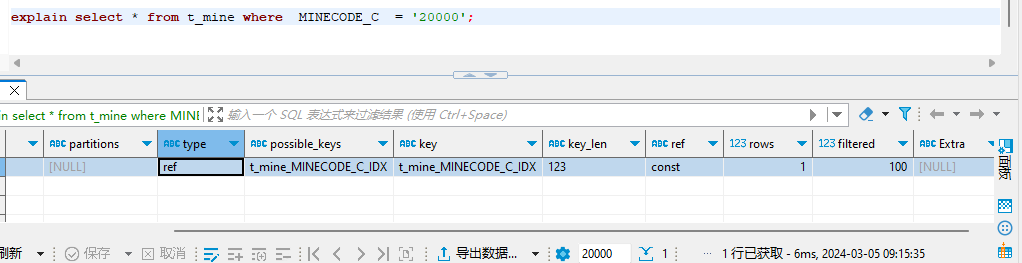
解释一下代码里的关键内容:
- rows=1:表示需要读取的记录数
- possible_keys=index_trans:表示可以选择的索引是 index_trans
- key=index_trans:表示实际选择的索引是 index_trans
我们发现,有了索引之后,MySQL在执行SQL语句的时候多了一种优化的手段。也就是说,在查询的时候,可以先通过查询索引快速定位,然后再找到对应的数据进行读取,这样就大大提高了查询的速度。
组合索引类似同理
(4)组合索引
CREATE INDEX t_mine_MINECODE USING BTREE ON mtc_base.t_mine (MINECODE_C,MINECODE_S,MINECODE_P);
如果有多个索引,而这些索引的字段同时作为筛选字段出现在查询中的时候,MySQL 会选择使用最优的索引来执行查询操作。
组合索引的多个字段是有序的,遵循左对齐的原则。比如我们创建的组合索引,排序的方式是 MINECODE_C、MINECODE_S 和 MINECODE_P。因此,筛选的条件也要遵循从左向右的原则,如果中断,那么,断点后面的条件就没有办法利用索引了。
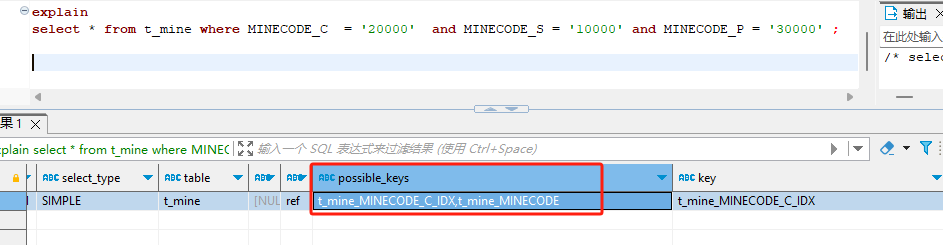
MySQL没有选择组合索引,选择了创建的普通索引。因为如果只使用组合索引的一部分,效果没有单字段索引那么好。
(5)索引总结
索引能够提升查询的效率,但是创建索引是有成本的,主要有2个方面,一个存储空间的开销,还有一个是数据操作上的开销。
- 存储空间的开销,是指索引需要单独占用存储空间;
- 数据操作上的开销,是指一旦数据表有变动,无论是插入一条新数据,还是删除一条旧数据,甚至是修改数据,如果涉及索引字段,都需要对索引本身进行修改,以确保索引能够指向正确的记录。
(6)索引失效场景
联合索引不满足最左匹配原则。模糊查询最前面的为不确定匹配字符。索引列参与了运算。索引列使用了函数。索引列存在类型转换。索引列使用 is not null 查询。
索引失效情况1:非最左匹配
最左匹配原则指的是,以最左边的为起点字段查询可以使用联合索引,否则将不能使用联合索引。 我们本文的联合索引的字段顺序是 sn + name + age,我们假设它们的顺序是 A + B + C,以下联合索引的使用情况如下:
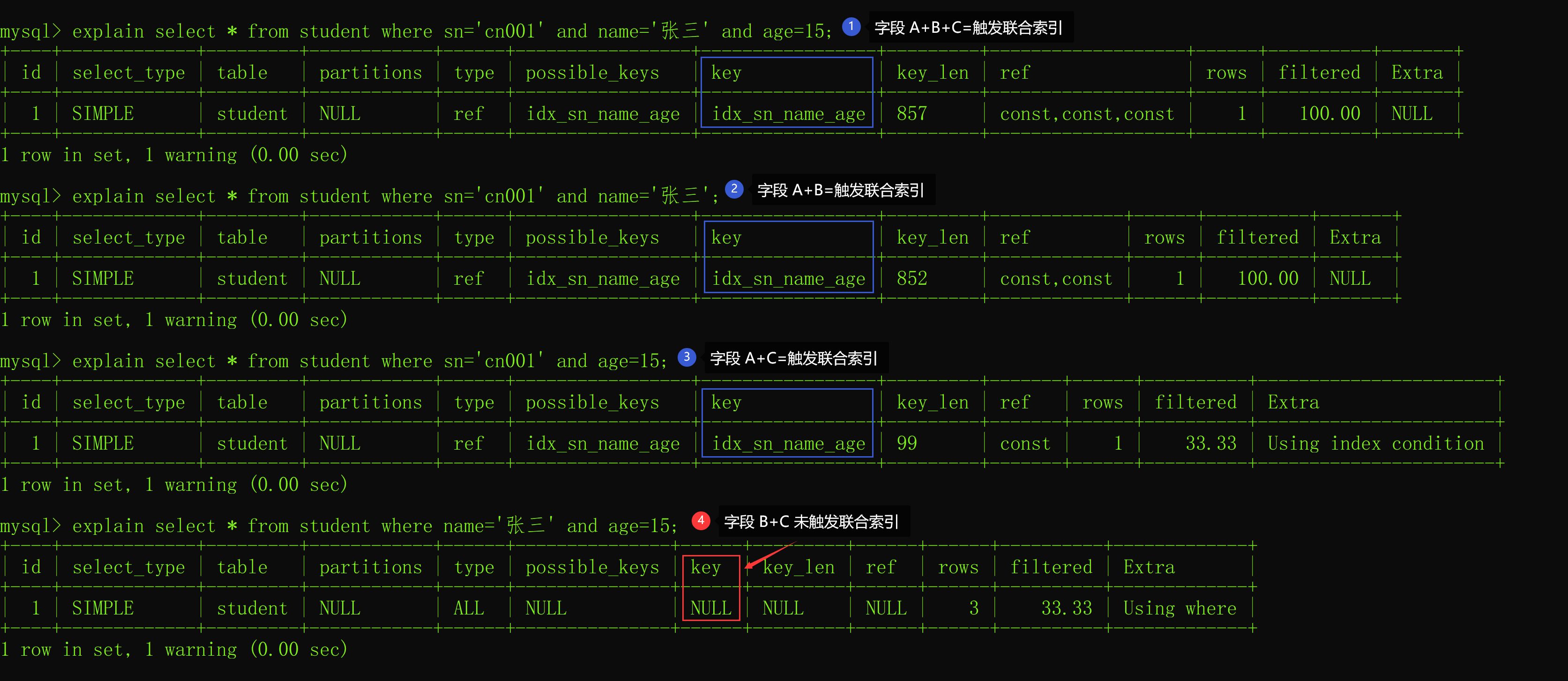
从上述结果可以看出,如果是以最左边开始匹配的字段都可以使用上联合索引,比如:
A+B+C
A+B
A+C 其中:A 等于字段 sn,B 等于字段 name,C 等于字段 age。
而 B+C 却不能使用到联合索引,这就是最左匹配原则。
索引失效情况2:错误模糊查询
模糊查询 like 的常见用法有 3 种:
模糊匹配后面任意字符:like ‘张%’
模糊匹配前面任意字符:like ‘%张’
模糊匹配前后任意字符:like ‘%张%’而这 3 种模糊查询中只有第 1 种查询方式可以使用到索引,具体执行结果如下:

索引失效情况3:列运算
如果索引列使用了运算,那么索引也会失效,如下图所示:

索引失效情况4:使用函数
查询列如果使用任意 MySQL 提供的函数就会导致索引失效,比如以下列使用了 ifnull 函数之后的执行计划如下:

索引失效情况5:类型转换
如果索引列存在类型转换,那么也不会走索引,比如 address 为字符串类型,而查询的时候设置了 int 类型的值就会导致索引失效,如下图所示:

索引失效情况6:使用 is not null
当在查询中使用了 is not null 也会导致索引失效,而 is null 则会正常触发索引的,如下图所示: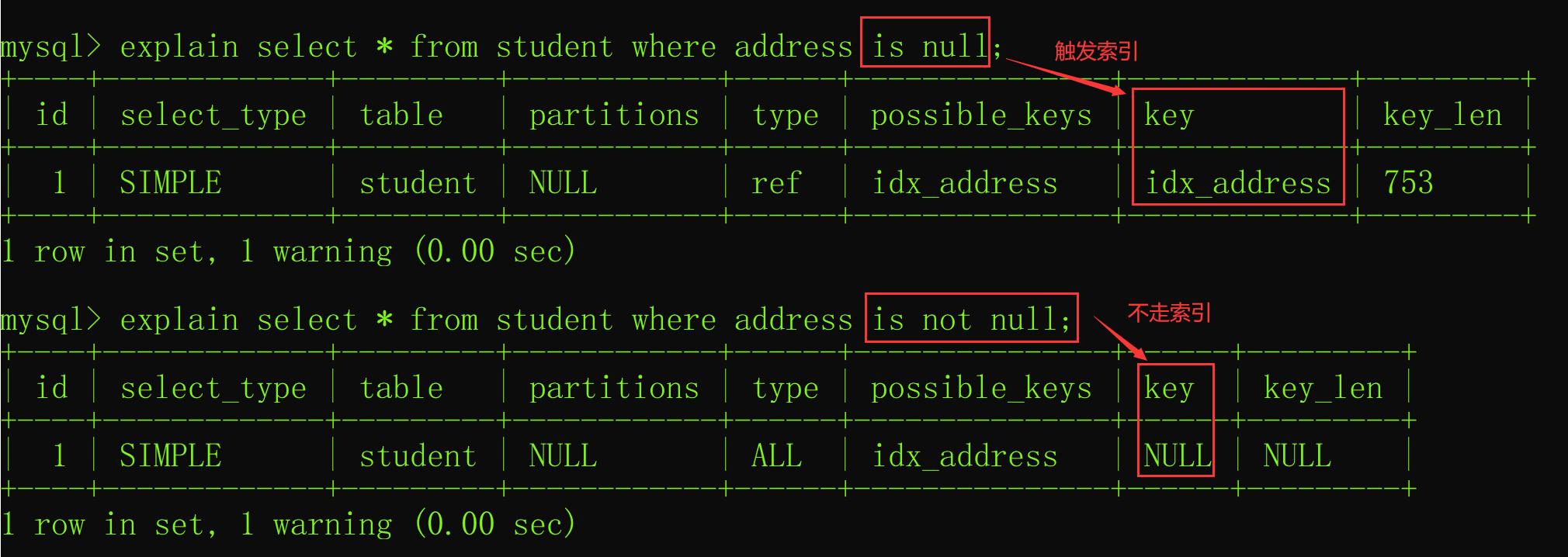
2 . 避免使用select *
反例:
select * from user where id=1;
在实际业务场景中,可能我们真正需要使用的只有其中一两列。查了很多数据,但是不用,白白浪费了数据库资源,比如:内存或者cpu。
此外,多查出来的数据,通过网络IO传输的过程中,也会增加数据传输的时间。
还有一个最重要的问题是:select *不会走覆盖索引,会出现大量的回表操作,而从导致查询sql的性能很低。
正例:
select name,age from user where id=1;
sql语句查询时,只查需要用到的列,多余的列根本无需查出来。
3 . 用union all代替union
我们都知道sql语句使用union关键字后,可以获取排重后的数据。
而如果使用union all关键字,可以获取所有数据,包含重复的数据。
反例:
(select * from user where id=1) union (select * from user where id=2);排重的过程需要遍历、排序和比较,它更耗时,更消耗cpu资源。
所以如果能用union all的时候,尽量不用union。
正例:
(select * from user where id=1) union (select * from user where id=2);除非是有些特殊的场景,比如union all之后,结果集中出现了重复数据,而业务场景中是不允许产生重复数据的,这时可以使用union。
4 . 批量操作
如果你有一批数据经过业务处理之后,需要插入数据,该怎么办?
反例:
在循环中逐条插入数据。
insert into order(id,code,user_id) values(123,'001',100);该操作需要多次请求数据库,才能完成这批数据的插入。
但众所周知,我们在代码中,每次远程请求数据库,是会消耗一定性能的。而如果我们的代码需要请求多次数据库,才能完成本次业务功能,势必会消耗更多的性能。
那么如何优化呢?
正例:
提供一个批量插入数据的方法。
insert into order(id,code,user_id) values (123,'001',100),(124,'002',100),(125,'003',101);这样只需要远程请求一次数据库,sql性能会得到提升,数据量越多,提升越大。
但需要注意的是,不建议一次批量操作太多的数据,如果数据太多数据库响应也会很慢。批量操作需要把握一个度,建议每批数据尽量控制在500以内。如果数据多于500,则分多批次处理。
5 . 多用limit
select id, create_date from order where user_id=123 order by create_date asc limit 1;使用limit 1,只返回该用户下单时间最小的那一条数据即可。增加数据响应效率
6 . in中值太多
对于批量查询接口,我们通常会使用in关键字过滤出数据。比如:想通过指定的一些id,批量查询出用户信息。
sql语句如下:
select id,name from category where id in (1,2,3...100000000);如果我们不做任何限制,该查询语句一次性可能会查询出非常多的数据
7 . 增量查询
有时候,我们需要通过远程接口查询数据,然后同步到另外一个数据库。
反例:
select * from user;
如果直接获取所有的数据,然后同步过去。这样虽说非常方便,但是带来了一个非常大的问题,就是如果数据很多的话,查询性能会非常差。
这时该怎么办呢?
正例:
select * from user where id>#{lastId} and create_time >= #{lastCreateTime} limit 100;按id和时间升序,每次只同步一批数据,这一批数据只有100条记录。每次同步完成之后,保存这100条数据中最大的id和时间,给同步下一批数据的时候用。
通过这种增量查询的方式,能够提升单次查询的效率。
8 . 高效的分页
有时候,列表页在查询数据时,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理。
在mysql中分页一般用的limit关键字:
select id,name,age from user limit 10,20;9 . 用连接查询代替子查询
mysql中如果需要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询。
子查询的例子如下:
select * from order where user_id in (select id from user where status=1)子查询语句可以通过in关键字实现,一个查询语句的条件落在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。
子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。
但缺点是mysql执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。
这时可以改成连接查询。具体例子如下:
select * from order o inner join user u on o.user_id = u.id where u.status=110 . join的表不宜过多
根据阿里巴巴开发者手册的规定,join表的数量不应该超过3个。
如果join太多,mysql在选择索引的时候会非常复杂,很容易选错索引。
所以我们应该尽量控制join表的数量。
11 . join时要注意
我们在涉及到多张表联合查询的时候,一般会使用join关键字。
而join使用最多的是left join和inner join。
-
left join:求两个表的交集外加左表剩下的数据。 -
inner join:求两个表交集的数据。
使用inner join的示例如下:
如果两张表使用inner join关联,mysql会自动选择两张表中的小表,去驱动大表,所以性能上不会有太大的问题。
如果两张表使用left join关联,mysql会默认用left join关键字左边的表,去驱动它右边的表。如果左边的表数据很多时,就会出现性能问题。
要特别注意的是在用left join关联查询时,左边要用小表,右边可以用大表。如果能用inner join的地方,尽量少用left join。
12 . 控制索引的数量
众所周知,索引能够显著的提升查询sql的性能,但索引数量并非越多越好。
因为表中新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。
阿里巴巴的开发者手册中规定,单表的索引数量应该尽量控制在5个以内,并且单个索引中的字段数不超过5个。
mysql使用的B+树的结构来保存索引的,在insert、update和delete操作时,需要更新B+树索引。如果索引过多,会消耗很多额外的性能。
13 . 选择合理的字段类型
14 . 提升group by的效率
我们有很多业务场景需要使用group by关键字,它主要的功能是去重和分组。
通常它会跟having一起配合使用,表示分组后再根据一定的条件过滤数据。
反例:
select user_id,user_name from order group by user_id having user_id <= 200;这种写法性能不好,它先把所有的订单根据用户id分组之后,再去过滤用户id大于等于200的用户。
分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?
正例:
select user_id,user_name from order where user_id <= 200 group by user_id使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。
其实这是一种思路,不仅限于group by的优化。我们的sql语句在做一些耗时的操作之前,应尽可能缩小数据范围,这样能提升sql整体的性能。
三 . 参考资料
MySQL第九讲·索引怎么提高查询的速度?_mysql range索引速度-CSDN博客
sql优化的15个小技巧(必知五颗星),面试说出七八个就有了_sql优化常用的15种方法-CSDN博客