文章目录
- 3.4 一个简化的SSM结构
- 3.5 选择机制的性质
- 3.5.1 和门控机制的联系
- 3.5.2 选择机制的解释
- 3.6 额外的模型细节
- A 讨论:选择机制
- C 选择SSM的机制
Mamba论文
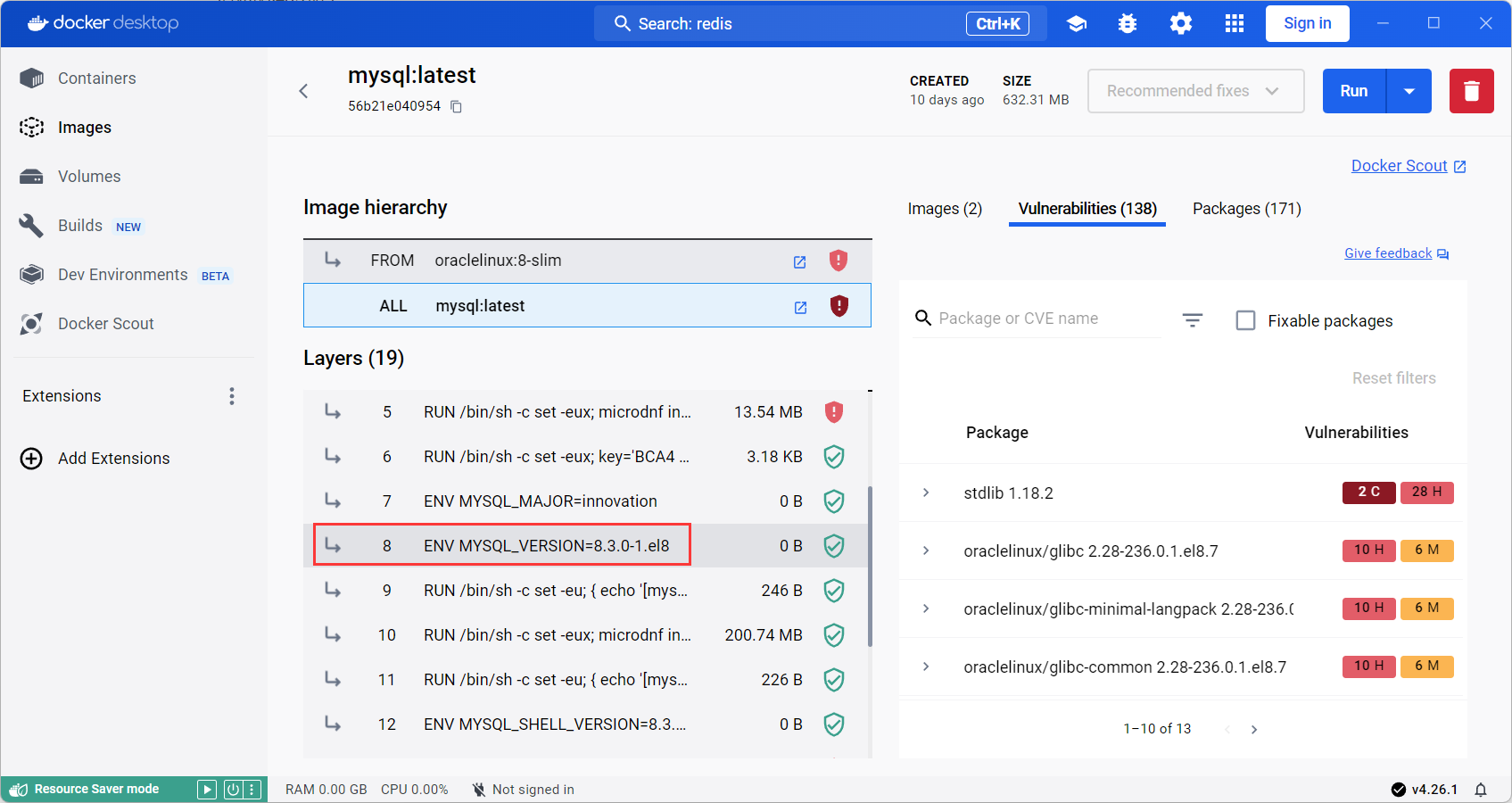
第一部分 Mamba:选择状态空间模型的线性时间序列建模(一)
3.4 一个简化的SSM结构
如同结构SSM,选择SSM是单独序列变换可以灵活地整合进神经网络。H3结构式最知名SSM结构地基础,其通常包括受线性注意力启发的和MLP交替地块。我们通过结合这两个组件到一个来简化这个结构,均匀地堆叠。这受到了门控注意力单元的启发(GAU),和为注意力做的事情相似。
这个结构包括扩展模型维度 D D D通过一个可控的扩展因子 E E E。对于每个块,参数( 3 E D 3ED 3ED)的大部分都在线性映射( 2 E D 2 2ED^2 2ED2对于输入映射, E D 2 ED^2 ED2对于输出映射)而内部的SSM贡献很少。相比起来,SSM参数( Δ , B , C \Delta,\textbf B,\textbf C Δ,B,C和矩阵 A \textbf A A)的参数少很多。我们复制这个块,插入标准的归一化和残差连接,来建立Mamba结构。我们一般固定 E = 2 E = 2 E=2在我们的实验中使用两层块的堆叠,来匹配Transformer插入多头注意力和MLP块的参数量。我们使用SiLU/Swish激活函数,激活以使门控MLP变为流行的"SwiGLU"变体。最后,我们额外使用了一个可选归一化层(我们选择层归一化),受RetNet在相似位置归一化使用的启发。

我们的简化块设计结合了H3块,H3是大多数SSM结构的基础,有现代神经网络中无处不在的MLP块。我们简单重复这两个块而不是两个块交错。和H3相比,Mamba用激活函数替代了第一个乘法门。相比于MLP块,Mamba在主干添加了一个SSM。对于 σ \sigma σ我们使用SiLU/Swish激活。
3.5 选择机制的性质
选择机制是一个广泛的概念,可以以不同的方式应用,例如在更传统的RNN和CNN,在不同的参数(例如算法2中的 A \textbf A A),或者使用不同的变换 s ( x ) s(x) s(x)
3.5.1 和门控机制的联系
我们着重指出最重要的联系,RNN的经典门控机制是我们SSM选择机制的一个实例。我们注意到RNN门控和连续时间系统的离散化间的关系被很好的建立。事实上,Theorem 1是对ZOH离散化和输入相关门的推广的改进(证明见附录C)。更广泛的,SSM中的 Δ \Delta Δ可以被看作在RNN门控机制中扮演了一个普遍的角色。和之前工作保持一致,我们采取SSM的离散化是启发式门控机制的原则基础。
Theorem 1 当 N = 1 , A = − 1 , B = 1 , S Δ = L i n e a r ( x ) N = 1, \textbf A = -1, \textbf B = 1, S_\Delta = Linear(x) N=1,A=−1,B=1,SΔ=Linear(x)和 τ Δ = s o f t p l u s \tau_\Delta = softplus τΔ=softplus
则选择SSM递归有这样的形式
g
t
=
σ
(
L
i
n
e
a
r
(
x
t
)
)
h
t
=
(
1
−
g
t
)
h
t
−
1
+
g
t
x
t
g_t = \sigma(Linear(x_t)) \\ h_t = (1-g_t)h_{t-1}+g_tx_t
gt=σ(Linear(xt))ht=(1−gt)ht−1+gtxt
如在部分3.2提到的,我们特别选择这样的
S
Δ
,
τ
Δ
S_\Delta,\tau_\Delta
SΔ,τΔ就处于这个联系。特别是,注意如果一个给定输入
x
t
x_t
xt应该被完全忽略(如在合成任务中需要),所有
D
D
D个通道应该忽略它,因此在用
Δ
\Delta
Δ重复/广播之前,我们把输入之前映射到1维。
3.5.2 选择机制的解释
我们详细阐述了选择的两种特殊机制效应。
可变间距 选择性允许过滤掉可能发生在感兴趣的输入间的不相关的噪声标记。在选择性复制任务中得到验证,但是普遍存在于常见数据模态中,特别是离散数据。例如语言中的填词"um"。这个属性提升因为模型可以机械地过滤掉任何特定的输入 x t x_t xt
例如在门控RNN中当 g t → 0 g_t\rightarrow0 gt→0。
过滤内容 在很多序列模型中经常被观察到,更长的内容并没有提升。尽管有更多的内容应该让表现更好这一原理。一个解释是很多序列模型不能在必要时有效地忽略不相关的内容。一个直觉的例子是全局卷积(和其他通常的LTI模型)。另一方面,选择模型可以简单在任何时刻重置它们的状态来移除无关的历史,因此,它们的性能原则上随着上下文长度的增加而单调性提高
边界重设置 在多条不相关序列缝在一起的时候,Transformer可以保持它们分开通过实例化不同的注意力掩膜,而LTI模型将会混合这些序列之间的信息。选择性SSM可以在边界重置他们的状态(例如 Δ t → ∞ \Delta_t\rightarrow \infin Δt→∞或者 g t → 1 g_t\rightarrow 1 gt→1)这些情况将会人为的(打包文件以硬件利用率)或者自然地(强化学习中episode边界)发生。
Δ \Delta Δ的解释 通常, Δ \Delta Δ控制关注遗忘或者关注多少在当前的输入 x t x_t xt的平衡。它推广了RNN门(例如Theorem1中的 g t g_t gt),理论上,一个大的 Δ \Delta Δ重置状态 h h h并关注在当前的输入 x x x,而小的 Δ \Delta Δ保持状态并且忽略当前输入。SSM可以被解释为一个连续西永被时间步长 Δ \Delta Δ离散化,在这个背景下,一个直觉是大 Δ → ∞ \Delta\rightarrow\infin Δ→∞表示了系统关注于当前输入更长时间(因此“选择”它并忘掉它的当前状态)当一个小 Δ → 0 \Delta\rightarrow 0 Δ→0代表一个被遗忘的瞬态输入。
A A A的解释我们指出尽管参数 A A A也可以是选择性的,它根本上通过它和 Δ \Delta Δ的交互影响模型,通过 A ‾ = e x p ( Δ A ) \overline {\textbf A} = exp(\Delta \textbf A) A=exp(ΔA)。因此 Δ \Delta Δ的选择性对于确保 ( A ‾ , B ‾ ) (\overline{\textbf A},\overline{\textbf{B}}) (A,B)已经足够而且是提升的主要来源。我们假设使 A \textbf A A选择性替代 Δ \Delta Δ或者附加会有相似的效果,我们出于简便省略。
B B B和 C C C的解释 如在部分3.1讨论的一样,选择性最重要的属性是过滤掉我们不相关的信息以使一个序列模型的内容可以被压缩到哟个有效的状态。在一个SSM中,微调 B \textbf B B和 C \textbf C C成为选择性的允许细粒度控制什么时候一个输入 x t x_t xt到状态 h t h_t ht或者状态到输出 y t y_t yt。这可以被解释为允许模型分别基于内容(输入)和上下文(隐藏状态)来调节循环动态。
3.6 额外的模型细节
实数 vs 复数 很多前面的SSM在他们的状态 h h h中使用复数,对于很多任务中需要的高表现力来说是必要的。然而,在经验上观察到完全的实数SSM运作得也不错,可能更好在某些情形下。我们使用实数值作为默认,除了一个任务意外表现得很好,我们假设复数-实数权衡与数据模态中连续-离散谱有关,对于连续模态(如语音,视频)来说复数有用,对于离散(例如文本,DNA)则无用。
初始化 大多数前面的SSM也要求特别的初始化,特别是对于复数值情况,在一些情况如低数据状态有帮助。我们对于复数情况的默认初始化时S4D-Lin对于实数来说时S4D-Real,基于HIPPO理论。相应定义 A \textbf A A中第 n n n个元素为 − 1 / 2 + n i -1/2+ni −1/2+ni和 − ( n + 1 ) -(n+1) −(n+1)。然而,我们认为很多初始化可以工作良好,特别是在大数据和实数SSM情况。
Δ \Delta Δ的参数化 我们定义 Δ \Delta Δ的选择调整为 s Δ = B r o a d c a s t D ( L i n e a r 1 ( x ) ) s_\Delta = Broadcast_D(Linear_1(x)) sΔ=BroadcastD(Linear1(x)),受3.5部分 Δ \Delta Δ的部分启发。我们观察到可以从维度1推广到更大的维度 R R R。我们将其设置为 D D D的小分数,与块中的主要线性投影相比,其使用可忽略数量的参数。我们还注意到,广播操作可以被视为另一个线性投影,初始化为特殊的模式’1’和‘0’。如果这个映射是可学习的,将导致一个替代的 s Δ ( x ) = L i n e a r D ( L i n e a r R ( x ) ) s_\Delta(x) = Linear_D(Linear_R(x)) sΔ(x)=LinearD(LinearR(x)),可以看作一个低秩映射。
在我们的实验中,参照之前SSM的工作 Δ \Delta Δ参数(可以被看作一个偏差项)初始化为 τ Δ − 1 ( U n i f o r m [ 0.001 , 0.1 ] ) \tau_\Delta^{-1}(Uniform[0.001,0.1]) τΔ−1(Uniform[0.001,0.1])
A 讨论:选择机制
我们的选择机制受到门控、超网络和数据依赖等概念的启发,并与之相关。它也可以被视为与“快速权重”有关,后者将经典RNN与线性注意力机制联系起来。然而,我们认为,这是一个值得澄清的独特概念。
门控 门控起源于参考RNN例如LSTM和GRU的门控机制,或者Theorem 1的门控等式。这可以被解释为控制是否让一个输入进入一个RNN隐藏状态的特别机制。特别是,这会影响信号沿着时间的传输和输入沿着序列长度方向交互。
然而,此后门控的概念在流行使用中被放款,简单地表示任何乘法相互作用(通常带有激活函数)。例如,神经网络结构中元素间的乘法部分现在通常被称为门控结构,尽管与原始RNN有非常不同的意义。因此我们认为RNN门控的原始概念相比流行的乘法门控实际上有很大的语义不同
超网络 超网络用来指那些自身参数由更小网络产生的神经网络。原始的想法是狭义的用法定义一个大的RNN,其参数由一个小的 R N N RNN RNN生成。
数据依赖 和超网络相似,数据依赖可以指任何概念-一些模型参数依赖于数据
例子:GLU 激活 为了解释这些概念,考虑一个简单的对角线性层 y = D x y = Dx y=Dx,其中 D D D是一个对角权重参数。现在设定 D D D是由自身通过一个 x x x的线性变换而来,由一个可选的非线性: D = σ ( W x ) D = \sigma(Wx) D=σ(Wx),因为它是对角的,乘法变成元素积: y = σ ( W x ) ∘ x y = \sigma(Wx)\circ x y=σ(Wx)∘x这是一个相当琐碎的转换,但它在技术上满足了门控的常见含义(因为它有“乘法”分支),超网络(因为参数 D D D是由另一个层产生的),和数据依赖(因为 D D D取决于数据 x x x)然而,这实际上简单定义了一个GLU函数,简单到通常仅仅被看作一个激活函数而不是一个有意义的层。
选择 因此,虽然选择机制可以被视为架构门控、超网络或数据依赖性等思想的特例,但大量其他结构也可以——基本上是任何具有乘法运算的结构,也包括标准注意力机制,但我们认为这样没有信息量。
相反,我们认为它与传统RNN的门控机制最为密切相关,这是一种特殊情况,也有通过变量(依赖输入)离散化参数 Δ \Delta Δ与SSM连接的。我们还避开了“选通”一词,而倾向于选择,以澄清前者的过度使用。更狭义地说,我们使用选择来指代模型的机制作用,以选择或忽略输入,并促进沿序列长度的数据交互。除了选择性SSM和门控RNN之外,其他例子可能包括依赖于输入的卷积,甚至注意力
C 选择SSM的机制
Theorem 1的证明,考虑一个 N = 1 , A = − 1 , B = 1 , s Δ = L i n e a r ( x ) , τ Δ = s o f t p l u s N = 1, A = -1, B = 1, s_\Delta = Linear(x), \tau_\Delta = softplus N=1,A=−1,B=1,sΔ=Linear(x),τΔ=softplus的选择SSM
相应的连续时间SSM是
h
(
t
)
=
−
h
(
t
)
+
x
(
t
)
h(t) = -h(t) +x(t)
h(t)=−h(t)+x(t)
也被称为一个漏积分器。离散步长是
Δ
t
=
τ
Δ
(
P
a
r
a
m
e
t
e
r
+
s
Δ
(
x
t
)
)
=
s
o
f
t
p
l
u
s
(
P
a
r
a
m
e
t
e
r
+
L
i
n
e
a
r
(
x
t
)
)
=
s
o
f
t
p
l
u
s
(
L
i
n
e
a
r
(
x
t
)
)
\Delta_t = \tau_\Delta(Parameter + s_\Delta(x_t)) \\=softplus(Parameter+Linear(x_t)) \\=softplus(Linear(x_t))
Δt=τΔ(Parameter+sΔ(xt))=softplus(Parameter+Linear(xt))=softplus(Linear(xt))
我们观察到这个参数也可以被看作一个可学习的偏差变成一个线性映射。
现在应用零阶保持离散形式:
A
‾
t
=
e
x
p
(
Δ
A
)
=
1
1
+
e
x
p
(
L
i
n
e
a
r
(
x
t
)
)
=
σ
(
−
L
i
n
e
a
r
(
x
t
)
)
=
1
−
σ
(
L
i
n
e
a
r
(
x
t
)
)
\overline{A}_t = exp(\Delta A) = \frac{1}{1+exp(Linear(x_t))} = \sigma(-Linear(x_t))\\ =1-\sigma(Linear(x_t))
At=exp(ΔA)=1+exp(Linear(xt))1=σ(−Linear(xt))=1−σ(Linear(xt))
B ‾ t = ( Δ A ) − 1 ( e x p ( Δ A ) − I ) ⋅ Δ B = − ( e x p ( Δ A ) − I ) = I − A ‾ = σ ( L i n e a r ( x t ) ) \overline{B}_t = (\Delta A)^{-1}(exp(\Delta A) - I)\cdot\Delta B=-(exp(\Delta A) - I) = I - \overline A \\=\sigma(Linear(x_t)) Bt=(ΔA)−1(exp(ΔA)−I)⋅ΔB=−(exp(ΔA)−I)=I−A=σ(Linear(xt))
因此最后的离散递归是
g
t
=
σ
(
L
i
n
e
a
r
(
x
t
)
)
h
t
(
a
−
g
t
)
h
t
−
1
+
g
t
x
t
g_t = \sigma(Linear(x_t)) \\ h_t(a-g_t)h_{t-1}+g_tx_t
gt=σ(Linear(xt))ht(a−gt)ht−1+gtxt







![[最佳实践] Windows上构建一个和Linux类似的Terminal](https://img-blog.csdnimg.cn/img_convert/b60e8e4962f8f791a5e571c867b06a95.png)