爬虫
- scrapy
- beautifulsoup
- find_all
- find
- 祖先/父节点
- 兄弟节点
- next
- previous
- CSS选择器
- 属性值 attrs
- select 后 class
- 正则
- 使用字符串来描述、匹配一系列符合某个规则的字符串
- 组成
- 元字符
- 使用grep匹配正则
- 组与捕获
- 断言与标记
- 条件匹配
- 正则表达式的标志
- 特定中文 匹配
scrapy
scrapy内置的选择器包含re、css、xpath选择器,依赖lxml
beautifulsoup
从网页上抓取信息。它位于HTML或XML解析器之上,
为迭代、搜索和修改解析树提供了Pythonic习惯用法。(优雅的、地道的、整洁的)代码
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<p>Some<b>bad<i>HTML")
>>> print(soup.prettify())
<html>
<body>
<p>
Some
<b>
bad
<i>
HTML
</i>
</b>
</p>
</body>
</html>
>>> soup.find(text="bad")
'bad'
>>> soup.i
<i>HTML</i>
#
>>> soup = BeautifulSoup("<tag1>Some<tag2/>bad<tag3>XML", "xml")
#
>>> print(soup.prettify())
<?xml version="1.0" encoding="utf-8"?>
<tag1>
Some
<tag2/>
bad
<tag3>
XML
</tag3>
</tag1>
find_all
# soup.find_all(name=['div','p'])
# find_all( name , attrs/class_ , recursive , string , **kwargs )
# name:标签名搜索
# attrs/class_:属性/类名搜索
# recursive:限定直接子节点
# string:文档字符串搜索
# soup.find(attrs={'data-custom':'custom'})
# soup.find_all("a", "sister") #class_="sister"
# soup.find_all("a", string="Elsie")
# soup.find_all(string=re.compile("Dormouse"))
# soup.find_all(string=["Tillie", "Elsie", "Lacie"])
# soup.find_all("a")
# soup("a")
嵌套查询:
for ul in soup.find_all(name='节点名1'):
print(ul.find_all(name='节点名1内的节点名'))
2:attrs:根据 属性
print(soup.find_all(attrs={'属性': '属性值'}))
得到列表形式,包含的内容就是符合“属性”为“属性值”的所有节点
3:text:(根据)传入的形式可以是字符串,可以是正则表达式对象(pattern)
可用来匹配 节点的文本
print(soup.find_all(text= str / pattern ))
传入pattern:结果返回 所有匹配正则表达式 的节点文本 组成的列表
response.content utf-8
soup = bs(response.content, 'html.parser')
ResultSet
实际上依赖解析器,它 除了支持Python标准库中的HTML解析器外,还支持一些第三方解析器(比如lxml)
可以把要解析的字符串以标准的缩进格式输出
CSS 路径
节点选择器——根据属性**来选择
直接调用节点的名称就可以选择节点元素,再调用string属性就可以得到节点内的文本了
1:这种选择方式速度非常快:
2:如果单个节点结构层次非常清晰,可以选用这种方式来解析
soup.title.string()
输出HTML中title节点的文本内容
注:soup.title可以选出HTML中的title节点,
再调用string属性就可以得到里面的文本了
——调用string属性来获取文本的值
提取信息
1:获取节点的名称——调用name
print(soup.title.name)
2:获取属性和属性值——调用attrs(获取所有属性,一个节点 有时候不止一个属性)
返回字典{}形式,并且 把选择的节点的所有属性和属性值组合成一个字典
{'class': ['title'], 'name': 'dromouse'}
有的返回结果是字符串,比如,name属性的值是唯一的,返回的结果就是单个字符串。
有的返回结果是字符串组成的列表。对于class,一个节点元素可能有多个class,所以返回的是列表。
∴在实际处理过程中,我们要注意判断类型
如果要获取name属性值,就相当于从字典中获取某个键值,只需要用中括号加属性名就可以了。比如,要获取name属性值,就可以通过attrs[‘name’]来得到
点元素后面加中括号,传入属性名就可以获取属性值了。不写attrs
print(soup.p['name'])#
——输出
dromouse
3:获取 节点元素 包含的文本内容——调用string
print(soup.p.string) 获取的是 第一个 p节点的文本
嵌套选择:
每一个返回结果都是bs4.element.Tag类型,它可以被继续调用 来进行下一步的选择
eg:
获取了head节点元素(Tag类型),我们可以继续调用head 来选取其内部的head节点元素
关联选择:
在做选择的时候,有时候不能做到一步就选到想要的节点元素,需要先选中某一个节点元素,然后以它为基准再选择它的子节点、父节点、兄弟节点等——嵌套选择同理
(1)子节点、子孙节点
选取节点元素之后,如果想要获取它的直接子节点,可以调用contents属性
contents属性 :得到的结果是直接子节点的列表
调用children属性也可以得到相应的结果,返回的是生成器类型,接着用for循环输出相应的内容
如果要得到所有的子孙节点的话,可以调用 descendants属性
(2)父节点、祖先节点
如果要获取某个节点元素的父节点,可以调用 parent属性 ——直接父节点,没有再向外寻找父节点的祖先节点
如果想获取所有的祖先节点,可以调用 parents属性——返回结果:生成器类型
(3)兄弟节点(同级节点)
next_sibling 和 previous_sibling 分别获取节点的下一个和上一个兄弟元素
next_siblings 和 previous_siblings 则分别返回所有前面和后面的兄弟节点 的生成器
关联元素节点的信息 提取:
1:如果返回结果是单个节点,那么可以直接调用string、attrs等属性获得其文本和属性:
2:如果返回结果是多个节点的生成器,则可以转为列表后取出某个元素,然后再调用string、attrs等属性获取其对应节点的文本和属性
print(list(soup.a.parents)[0].attrs['class'])
方法选择器——调用方法选择
find_all :
返回 所有 匹配成功元素 所组成的列表
1:name:根据节点名 查询元素
print(soup.find_all(name='节点名'))
find
祖先/父节点
find()
ps: 返回 第一个匹配的元素 (单个)
用法 和 find_all 相同
find_parents()
前者返回所有祖先节点,
find_parent()
后者返回直接父节点。
兄弟节点
find_next_siblings()
前者返回后面所有的兄弟节点,
find_next_sibling()
后者返回后面第一个兄弟节点。
find_previous_siblings()
前者返回前面所有的兄弟节点,
find_previous_sibling()
后者返回前面第一个兄弟节点。
next
find_all_next()
前者返回节点后所有符合条件的节点,
find_next()
后者返回第一个符合条件的节点。
previous
find_all_previous()
前者返回节点后所有符合条件的节点,
find_previous()
后者返回第一个符合条件的节点。
CSS选择器
只需要调用select()方法,传入相应的CSS选择器
输出——列表形式
1:嵌套选择:
select()方法——先选择所有父节点,再遍历每个父节点,选择其子节点
for ul in soup.select('ul'):
print(ul.select('li'))
2:获取属性
节点类型是Tag类型,所以获取属性还可以用原来的方法(attrs)
3:获取文本
同理,可以调用string属性
另外,get_text()
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for li in soup.select('li'):
print('Get Text:', li.get_text())
print('String:', li.string)
select 的功能跟find和find_all 一样用来选取特定的标签,它的选取规则依赖于css,我们把它叫做css选择器
ul_ = soup.select('html body div.wapper section.in-main div.n.w_index section.main div.contents div.column_cont.fixed div.column_right div.vulbar ul.vul_list li')
bs4.element.Tag
属性值 attrs
soup = BeautifulSoup(html, 'lxml')
print(soup.select("#list-2 li"))
for li in soup.select("#list-2 li"):
print(type(li))
print(li.attrs)
print(li.attrs['class'])
select 后 class
beautifulsoup是一个用于解析和提取HTML和XML文档的Python库,它提供了一些方法和属性来操作文档树。其中一个方法是select,它可以接受一个CSS选择器作为参数,返回一个匹配的标签列表。如果想要对select的结果进行class查询,可以使用列表推导式或循环遍历结果列表,然后使用get或has_attr方法来获取或判断标签的class属性。以下是一些使用select方法和class查询的示例代码:
# 导入beautifulsoup模块
from bs4 import BeautifulSoup
# 定义一个HTML文档字符串
html = """
<div class="A B C">
<p class="D E">Hello</p>
<p class="F G">World</p>
</div>
<div class="A B">
<p class="D H">Foo</p>
<p class="F I">Bar</p>
</div>
"""
# 创建一个BeautifulSoup对象,解析HTML文档
soup = BeautifulSoup(html, "html.parser")
# 使用select方法,根据CSS选择器查找所有的div标签
divs = soup.select("div")
# 使用列表推导式,从结果列表中筛选出有C类的div标签
divs_with_C = [div for div in divs if div.get("class") and "C" in div.get("class")]
# 打印筛选后的结果
print(divs_with_C)
# 使用select方法,根据CSS选择器查找所有的p标签
ps = soup.select("p")
# 使用循环遍历结果列表,判断每个p标签是否有E类,并打印相应信息
for p in ps:
if p.has_attr("class") and "E" in p["class"]:
print(p, "has E class")
else:
print(p, "does not have E class")
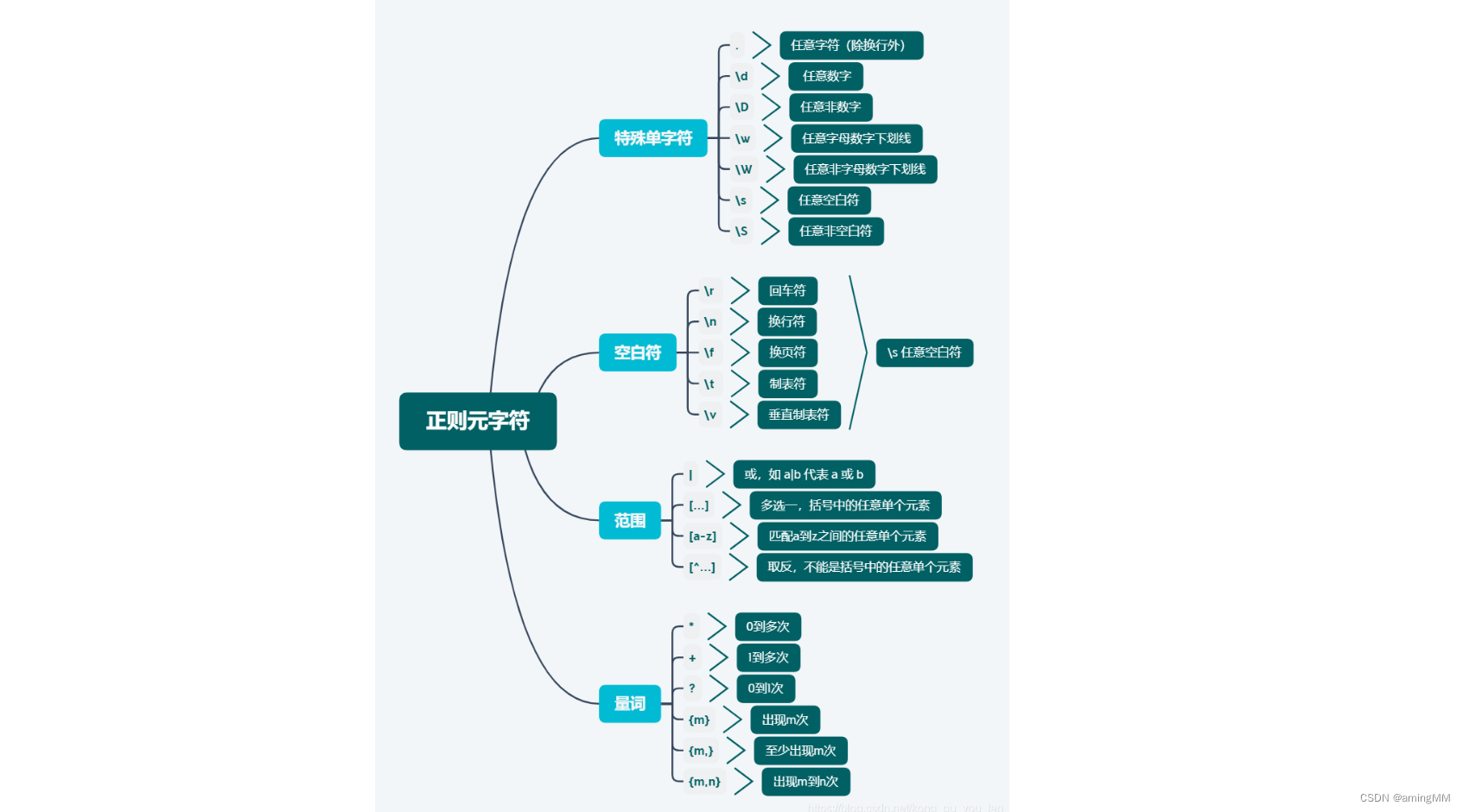
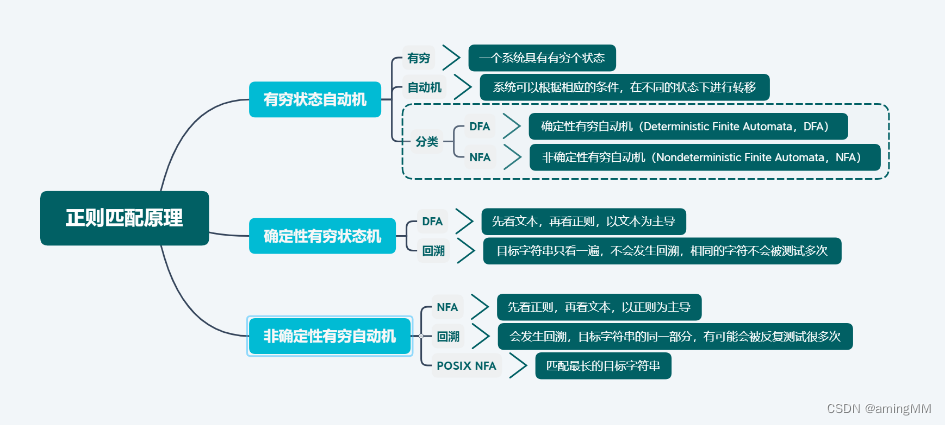
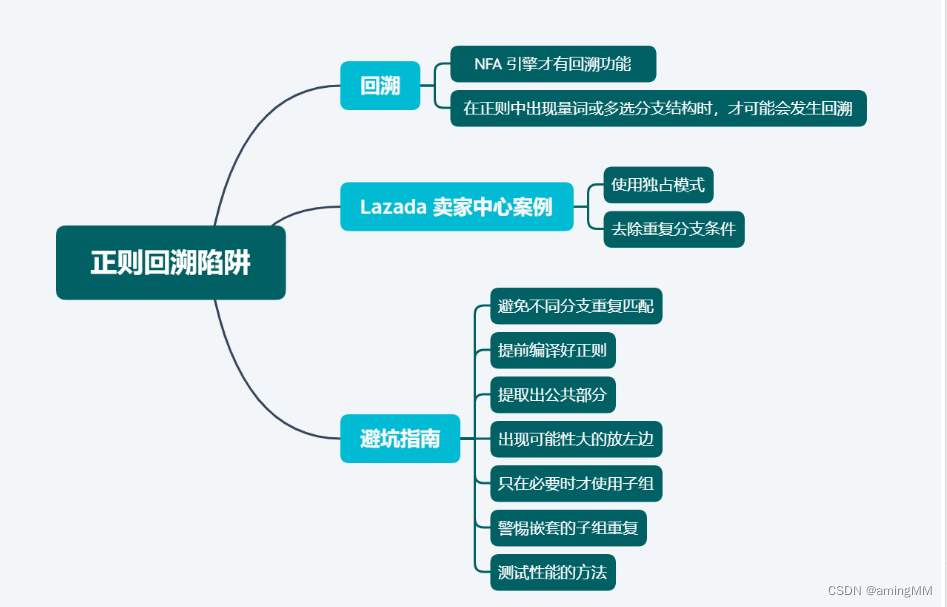
正则
使用字符串来描述、匹配一系列符合某个规则的字符串
搜索匹配特定模式的语句,
而这种模式及具体的 ASCII 序列或 Unicode 字符。从解析/替代字符串
组成
普通字符:
大小写字母、数字、标点符号及一些其他符号
元字符:
在正则表达式中具有特殊意义的专用字符
元字符
\
用来转义字符,\!、\n等 特殊字符:\.^$?+*{}[]()|
*************************************以上特殊字符要想使用字面值,必须使用\进行转义
^ 锚点
匹配字符串开始 表示^本身的行位置
$ 锚点
匹配字符串结束的行位置
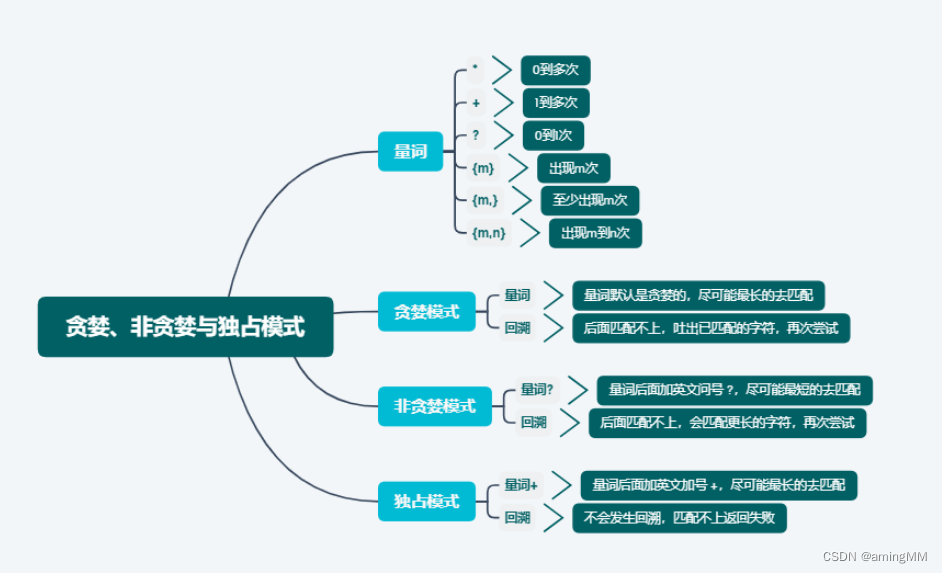
*
匹配前面 子表达式0次或者多次
abc* 匹配在“ab”后面跟着零个或多个“c”的字符串
a(bc)* 匹配在“a”后面跟着零个或更多“bc”序列的字符串
+
匹配前面 子表达式1次以上
abc+ 匹配在“ab”后面跟着一个或多个“c”的字符串abc
?
匹配前面 子表达式0次或者1次
匹配在“ab”后面跟着零个或一个“c”的字符串
{m} 匹配前面表达式m次
abc{2} 匹配在“ab”后面跟着两个“c”的字符串
{m,} 匹配前面表达式至少m次
abc{2,} 匹配在“ab”后面跟着两个或更多“c”的字符串
{,n} 匹配前面的正则表达式最多n次
{m,n} 匹配前面的正则表达式至少m次,最多n次
abc{2,5} 匹配在“ab”后面跟着2到5个“c”的字符串
a(bc){2,5} 匹配在“a”后面跟着2到5个“bc”序列的字符串
以上量词都是贪婪模式,会尽可能多的匹配,
如果要改为非贪婪模式,通过在量词后面跟随一个?来实现
()
将括号中的字符串作为一个整体
|
以或的方式匹配字条串
a(b|c) 匹配在“a”后面跟着“b”或“c”的字符串
a[bc] 匹配在“a”后面跟着“b”或“c”的字符串
[list]
匹配list列表中的一个字符
包含在[]中的一个或者多个字符被称为字符类
在匹配时如果没有指定量词则只会匹配其中的一个
内部可以使用速记法,比如\d \s \w
[^list]
匹配任意不在list列表中的一个字符
字符类内可以指定范围
例: [^a-z]、[^0-9]、[^A-Z0-9] 否定一个字符类
[abc] 匹配带有一个“a”、“ab”或“ac”的字符串
与 a|b|c 一样
[a-c] 匹配带有一个“a”、“ab”或“ac”的字符串与 a|b|c 一样
[a-fA-F0-9] 匹配一个代表16进制数字的字符串,不区分大小写
[0-9]% 匹配在%符号前面带有0到9这几个字符的字符串
[^a-zA-Z] 匹配不带a到z或A到Z的字符串,其中^为否定表达式
记住在方括弧内,所有特殊字符(包括反斜杠\)都会失去它们应有的意义。
.
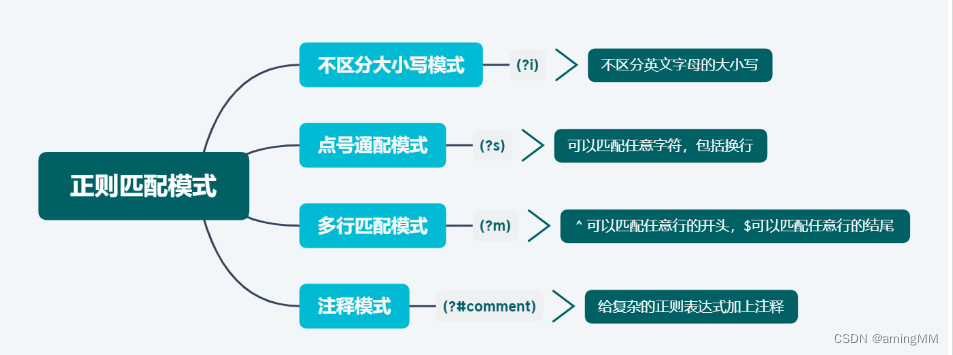
匹配除\n之外的任意的一个字符
如果有re.DOTALL标志,则匹配任意字符包括换行
`\d
匹配一个Unicode数字, 数字型的单个字符 如果带re.ASCII,则匹配0-9
\$\d 匹配在单个数字前有符号“$”的字符串
`\D`
匹配Unicode非数字
匹配单个非数字型的字符
`\s`
匹配Unicode空白,如果带有re.ASCII,则匹配`\t\n\r\f\v`中的一个
匹配单个空格字符(包括制表符和换行符)
`\S`
匹配Unicode非空白
`\w`
匹配Unicode单词字符,如果带有re.ascii,则匹配`[a-zA-Z0-9_]`中的一个
匹配单个词字(字母加下划线)
`\W`
匹配Unicode非单子字符
non-printable 字符
Tab 符「\t」、换行符「\n」和回车符「\r」
前向匹配和后向匹配:(?=) 和 (?<=)
d(?=r) 只有在后面跟着“r”的时候才匹配“d”
(?<=data-original-title=)\S+ 匹配 data-original-title= 后的 非空字符串
[\\s\\S]+ 所有空字符+所有非空字符
使用grep匹配正则
Grep 【选项】 查找条件 目标文件
-w:表示精确匹配
-E :开启扩展(Extend)的正则表达式
-c : 计算找到'搜寻字符串'的次数
-i :忽略大小写的不同,所以大小写视为相同
-o :只显示被模式匹配到的宁符串
-v:反向选择,亦即显示出没有'搜寻字符串′内容的那一行!
(反向查找,输出与查找条件不相符的行)--color=auto : 可以将找到的关键词部分加上颜色的显示喔!
-n :顺便输出行号
flags。
正则表达式通常以/abc/这种形式出现,
其中搜索模式由两个反斜杠[/]分离。而在模式的结尾,我们通常可以指定以下flag配置或它们的组合:
g(global)在第一次完成匹配后并不会返回结果,它会继续搜索剩下的文本。
m(multi line)允许使用^和$匹配一行的开始和结尾,而不是整个序列。
i(insensitive)令整个表达式不区分大小写(例如/aBc/i将匹配 AbC)。
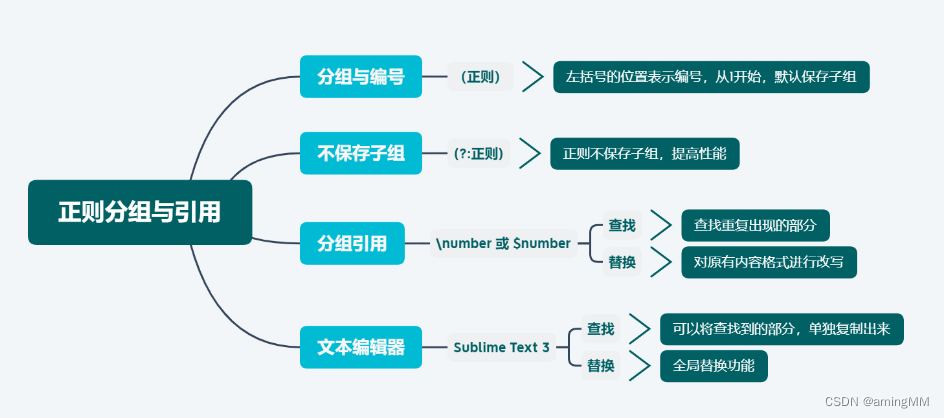
组与捕获
a(bc) 圆括弧会创建一个捕获性分组
它会捕获匹配项“bc”
a(?:bc)* 使用 “?:” 会使捕获分组失效,只需要匹配前面的“a”
a(?bc) 使用 “?” 会为分组配置一个名称
捕获性圆括号 ()和非捕获性圆括弧 (?:)对于从字符串或数据中抽取信息非常重要,
我们可以使用 Python 等不同的编程语言实现这一功能。
从多个分组中捕获的多个匹配项将以经典的数组形式展示:我们可以使用匹配结果的索引访问它们的值。
如果需要为分组添加名称(使用 (?...)),
我们就能如字典那样使用匹配结果检索分组的值,其中字典的键为分组的名称。
()的作用:
捕获`()`中正则表达式的内容以备进一步利用处理,
可以通过在左括号后面跟随`?:`来关闭这个括号的捕获功能 非捕获性圆括弧 (?:)
将正则表达式的一部分内容进行组合,以便使用量词或者|
反向引用前面`()`内捕获的内容:
- 通过组号反向引用
每一个没有使用`?:`的小括号都会分配一个组好,
从1开始,从左到右递增,可以通过`\i`引用前面`()`内表达式捕获的内容
- 通过组名反向引用前面小括号内捕获的内容
可以通过在左括号后面跟随`?P<name>`,尖括号中放入组名来为一个组起一个别名,
后面通过`(?P=name)`来引用 前面捕获的内容。如`(? P<word>\w+)\s+(?P=word)`来匹配重复的单词。
注意点:
反向引用不能放在字符类`[]`中使用。
Greedy 和 Lazy
匹配数量符(* + {})是一种贪心运算符,所以它们会遍历给定的文本,并尽可能匹配。
例如,<.>可以匹配文本「This is asimple divtest」 中的 「simple div」 。
为了仅捕获 div 标签,我们需要使用 「?」 令贪心搜索变得 Lazy 一点:
<.>
一次或多次匹配 “” 里面的任何字符,可按需扩展
]+>
一次或多次匹配 “” 里面的任何字符,除去 “” 字符
更好的解决方案应该需要避免使用「.」,这有利于实现更严格的正则表达式:
断言与标记
断言不会匹配任何文本,只是对断言所在的文本施加某些约束:
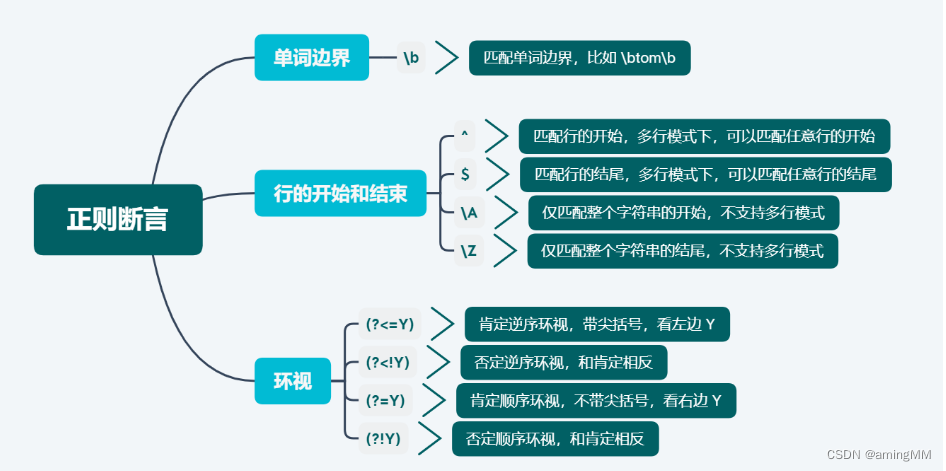
边界符:\b 和 \B
\b 匹配单词的边界,放在字符类[]中则表示backspace
\babc\b
执行整词匹配搜索
\b 如插入符号那样表示一个锚点(它与$和^相同)来匹配位置,
其中一边是一个单词符号(如\w),另一边不是单词符号(例如它可能是字符串的起始点或空格符号)。
\Babc\B 只要是被单词字符环绕的模式就会匹配
它同样能表达相反的非单词边界「\B」,它会匹配「\b」不会匹配的位置,如果我们希望找到被单词字符环绕的搜索模式,就可以使用它。
- `\B`匹配非单词边界,受ASCII标记影响
- `\A` 在起始处匹配
- `^` 在起始处匹配,如果有MULTILINE标志,则在每个换行符后匹配
- `\Z` 在结尾处匹配
- `$` 在结尾处匹配,如果有MULTILINE标志,则在每个换行符前匹配
- `(?=e)` 正前瞻
- `(?!e)` 负前瞻
- `(?<=e)` 正回顾
- `(?<!e)` 负回顾
前瞻回顾的解释
前瞻: exp1(?=exp2) exp1后面的内容要匹配exp2
负前瞻: exp1(?!exp2) exp1后面的内容不能匹配exp2
后顾: (?<=exp2)exp1 exp1前面的内容要匹配exp2
负后顾: (?<!exp2)exp1 exp1前面的内容不能匹配exp2
例如:我们要查找hello,但是hello后面必须是world,正则表达式可以这样写:"(hello)\s+(?=world)",用来匹配"hello wangxing"和"hello world"只能匹配到后者的hello
条件匹配
`(?(id)yes_exp|no_exp)`:对应id的子表达式如果匹配到内容,则这里匹配yes_exp,否则匹配no_exp
正则表达式的标志
- 正则表达式的标志有两种使用方法
- 通过给compile方法传入标志参数,多个标志使用|分割的方法
如`re.compile(r"#[\da-f]{6}\b", re.IGNORECASE|re.MULTILINE)`
- 通过在正则表达式前面添加(?标志)的方法给正则表达式添加标志,如`(?ms)#[\da-z]{6}\b`
- 常用的标志
re.A或者re.ASCII, 使\b \B \s \S \w \W \d \D都假定字符串为假定字符串为ASCII
re.I或者re.IGNORECASE 使正则表达式忽略大小写
re.M或者re.MULTILINE 多行匹配,使每个^在每个回车后,每个$在每个回车前匹配
re.S或者re.DOTALL 使.能匹配任意字符,包括回车
re.X或者re.VERBOSE 这样可以在正则表达式跨越多行,也可以添加注释,但是空白需要使用\s或者[ ]来表示,因为默认的空白不再解释。如:re.compile(r"""
<img\s +) #标签的开始
[^>]*? #不是src的属性
src= #src属性的开始
(?:
(?P<quote>["']) #左引号
(?P<image_name>[^\1>]+?) #图片名字
(?P=quote) #右括号
""",re.VERBOSE|re.IGNORECASE)
match = re.compile('<tr>.*?target="_blank">(.*?)</a></td>
.*?<td>(.*?)</td>
.*?<button.*?>.*?title="(.*?)">(.*?)</button>
.*?nowrap="nowrap">(.*?)</td>'
+
'.*?<button.*?>(.*?)</button>.*?</tr>', re.S)
contents = re.findall(match, page_html)
属性值正则匹配选择器
[attr^="val"]
[attr$="val"]
[attr*="val"]
字符匹配,而非单词匹配
尖角符号^、美元符号$以及星号*都是正则表达式中的特殊标识符,
分别表示前匹配、后匹配和任意匹配
[\u4e00-\u9fa5]
匹配中文字符
[^\x00-\xff]
匹配双字节字符(包括汉字在内)
\n\s*\r
匹配空白行
[\w!#$%&'*+/=?^_`{|}~-]+(?:\.[\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\w](?:[\w-]*[\w])?\.)+[\w](?:[\w-]*[\w])?
匹配Email地址
[a-zA-z]+://[^\s]*
匹配网址URL
\d{3}-\d{8}|\d{4}-\{7,8}
匹配国内电话号码
[1-9][0-9]{4,}
匹配腾讯QQ号
[1-9]\d{5}(?!\d)
校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*或([1−9][0−9]∗)1,3或([1−9][0−9]∗)1,3 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9"*或−[1−9]\d∗或−[1−9]\d∗
非负整数:^\d+或[1−9]\d∗|0或[1−9]\d∗|0
非正整数:^-[1-9]\d*|0或((−\d+)|(0+))或((−\d+)|(0+))
非负浮点数:^\d+(\.\d+)?或[1−9]\d∗\.\d∗|0\.\d∗[1−9]\d∗|0?\.0+|0或[1−9]\d∗\.\d∗|0\.\d∗[1−9]\d∗|0?\.0+|0
非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))或(−([1−9]\d∗\.\d∗|0\.\d∗[1−9]\d∗))|0?\.0+|0或(−([1−9]\d∗\.\d∗|0\.\d∗[1−9]\d∗))|0?\.0+|0
正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*或(([0−9]+\.[0−9]∗[1−9][0−9]∗)|([0−9]∗[1−9][0−9]∗\.[0−9]+)|([0−9]∗[1−9][0−9]∗))或(([0−9]+\.[0−9]∗[1−9][0−9]∗)|([0−9]∗[1−9][0−9]∗\.[0−9]+)|([0−9]∗[1−9][0−9]∗))
负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)或(−(([0−9]+\.[0−9]∗[1−9][0−9]∗)|([0−9]∗[1−9][0−9]∗\.[0−9]+)|([0−9]∗[1−9][0−9]∗)))或(−(([0−9]+\.[0−9]∗[1−9][0−9]∗)|([0−9]∗[1−9][0−9]∗\.[0−9]+)|([0−9]∗[1−9][0−9]∗)))
浮点数:^(-?\d+)(\.\d+)?或−?([1−9]\d∗\.\d∗|0\.\d∗[1−9]\d∗|0?\.0+|0)或−?([1−9]\d∗\.\d∗|0\.\d∗[1−9]\d∗|0?\.0+|0)
校验字符的表达式
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+或[A−Za−z0−9]4,40或[A−Za−z0−9]4,40
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^\w+或\w3,20或\w3,20
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+或[\u4E00−\u9FA5A−Za−z0−9]2,20或[\u4E00−\u9FA5A−Za−z0−9]2,20
可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
禁止输入含有~的字符:[^~\x22]+
三、特殊需求表达式
Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15})|(\d18)|(\d18)|(^\d{17}(\d|X|x)$)
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
钱的输入格式:
有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
中文字符的正则表达式:[\u4e00-\u9fa5]
双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:\n\s*\r (可以用来删除空白行)
HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*或(\s∗)|(\s∗或(\s∗)|(\s∗) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
非负整数:^\d+$ 或 ^[1-9]\d*|0$
非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
校验字符的表达式
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
禁止输入含有~的字符:[^~]+
三、特殊需求表达式
Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$
电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
钱的输入格式:
有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
中文字符的正则表达式:[\u4e00-\u9fa5]
双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:\n\s*\r (可以用来删除空白行)
HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IPv4地址:((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
'''
re.sub(pattern, repl, string, count=0, flags=0)
re.sub的参数:5个参数
参数1:pattern
表示正则中的模式字符串。
参数2:repl
就是replacement,表示被替换的字符串,可以是字符串也可以是函数。
参数3:string
表示要被处理和替换的原始字符串
参数4:count
可选参数,表示是要替换的最大次数,而且必须是非负整数,该参数默认为0,即所有的匹配都会被替换;
参数5:flags
可选参数,表示编译时用的匹配模式(如忽略大小写、多行模式等),数字形式,默认为0。
'''
二、Python正则表达式模块
(一)正则表达式处理字符串主要有四大功能
匹配 查看一个字符串是否符合正则表达式的语法,一般返回true或者false
获取 正则表达式来提取字符串中符合要求的文本
替换 查找字符串中符合正则表达式的文本,并用相应的字符串替换
分割 使用正则表达式对字符串进行分割。
(二) Python中re模块使用正则表达式的两种方法
使用re.compile(r, f)方法生成正则表达式对象,然后调用正则表达式对象的相应方法。这种做法的好处是生成正则对象之后可以多次使用。
re模块中对正则表达式对象的每个对象方法都有一个对应的模块方法,唯一不同的是传入的第一个参数是正则表达式字符串。此种方法适合于只使用一次的正则表达式。
(三)正则表达式对象的常用方法
rx.findall(s,start, end):
返回一个列表,如果正则表达式中没有分组,则列表中包含的是所有匹配的内容,
如果正则表达式中有分组,则列表中的每个元素是一个元组,元组中包含子分组中匹配到的内容,但是没有返回整个正则表达式匹配的内容
rx.finditer(s, start, end):
返回一个可迭代对象
对可迭代对象进行迭代,每一次返回一个匹配对象,可以调用匹配对象的group()方法查看指定组匹配到的内容,0表示整个正则表达式匹配到的内容
rx.search(s, start, end):
返回一个匹配对象,倘若没匹配到,就返回None
search方法只匹配一次就停止,不会继续往后匹配
rx.match(s, start, end):
如果正则表达式在字符串的起始处匹配,就返回一个匹配对象,否则返回None
rx.sub(x, s, m):
返回一个字符串。每一个匹配的地方用x进行替换,返回替换后的字符串,如果指定m,则最多替换m次。对于x可以使用/i或者/g<id>id可以是组名或者编号来引用捕获到的内容。
模块方法re.sub(r, x, s, m)中的x可以使用一个函数。此时我们就可以对捕获到的内容推过这个函数进行处理后再替换匹配到的文本。
rx.subn(x, s, m):
与re.sub()方法相同,区别在于返回的是二元组,其中一项是结果字符串,一项是做替换的个数。
rx.split(s, m):
分割字符串,返回一个列表,用正则表达式匹配到的内容对字符串进行分割
如果正则表达式中存在分组,则把分组匹配到的内容放在列表中每两个分割的中间作为列表的一部分,如:
rx = re.compile(r"(\d)[a-z]+(\d)")
s = "ab12dk3klj8jk9jks5"
result = rx.split(s)
返回['ab1', '2', '3', 'klj', '8', '9', 'jks5']
rx.flags():正则表达式编译时设置的标志
rx.pattern():正则表达式编译时使用的字符串
(四)匹配对象的属性与方法
m.group(g, ...)
返回编号或者组名匹配到的内容,默认或者0表示整个表达式匹配到的内容,如果指定多个,就返回一个元组
m.groupdict(default)
返回一个字典。字典的键是所有命名的组的组名,值为命名组捕获到的内容
如果有default参数,则将其作为那些没有参与匹配的组的默认值。
m.groups(default)
返回一个元组。包含所有捕获到内容的子分组,从1开始,如果指定了default值,则这个值作为那些没有捕获到内容的组的值
m.lastgroup()
匹配到内容的编号最高的捕获组的名称,如果没有或者没有使用名称则返回None(不常用)
m.lastindex()
匹配到内容的编号最高的捕获组的编号,如果没有就返回None。
m.start(g)
当前匹配对象的子分组是从字符串的那个位置开始匹配的,如果当前组没有参与匹配就返回-1
m.end(g)
当前匹配对象的子分组是从字符串的那个位置匹配结束的,如果当前组没有参与匹配就返回-1
m.span()
返回一个二元组,内容分别是m.start(g)和m.end(g)的返回值
m.re()
产生这一匹配对象的正则表达式
m.string()
传递给match或者search用于匹配的字符串
m.pos()
搜索的起始位置。即字符串的开头,或者start指定的位置(不常用)
m.endpos()
搜索的结束位置。即字符串的末尾位置,或者end指定的位置(不常用)
(五) 总结
对于正则表达式的匹配功能,Python没有返回true和false的方法,但可以通过对match或者search方法的返回值是否是None来判断
对于正则表达式的搜索功能,如果只搜索一次可以使用search或者match方法返回的匹配对象得到,对于搜索多次可以使用finditer方法返回的可迭代对象来迭代访问
对于正则表达式的替换功能,可以使用正则表达式对象的sub或者subn方法来实现,也可以通过re模块方法sub或者subn来实现,区别在于模块的sub方法的替换文本可以使用一个函数来生成
对于正则表达式的分割功能,可以使用正则表达式对象的split方法,需要注意如果正则表达式对象有分组的话,分组捕获的内容也会放到返回的列表中
match = re.compile('<tr>.*?target="_blank">(.*?)</a></td>.*?<td>(.*?)</td>.*?<button type="button" nowrap="nowrap".*?title="(.*?)">(.*?)</button>.*?nowrap="nowrap">(.*?)</td>' +'.*?<button.*?>(.*?)</button>.*?</tr>', re.S)
contents = re.findall(match, page_html)
w匹配的仅仅是中文,数字,字母,对于国人来讲,仅匹配中文时常会用到,见下
匹配中文字符的正则表达式: [u4e00-u9fa5]
或许你也需要匹配双字节字符,中文也是双字节的字符
匹配双字节字符(包括汉字在内):[^x00-xff]
注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1) 更多常用正则表达式匹配规则:
英文字母:[a-zA-Z]
数字:[0-9]
匹配中文,英文字母和数字及_:
^[u4e00-u9fa5_a-zA-Z0-9]+$
同时判断输入长度:
[u4e00-u9fa5_a-zA-Z0-9_]{4,10}
^[wu4E00-u9FA5uF900-uFA2D]*$
1、一个正则表达式,只含有汉字、数字、字母、下划线不能以下划线开头和结尾:
^(?!_)(?!.*?_$)[a-zA-Z0-9_u4e00-u9fa5]+$
其中: ^ 与字符串开始的地方匹配
(?!_) 不能以_开头
(?!.*?_$) 不能以_结尾
[a-zA-Z0-9_u4e00-u9fa5]+ 至少一个汉字、数字、字母、下划线
$ 与字符串结束的地方匹配
************************放在程序里前面加@,
否则需要加\进行转义 @"^(?!_)(?!.*?_$)[a-zA-Z0-9_u4e00-u9fa5]+$"
(或者:@"^(?!_)w*(?<!_)$" 或者 @" ^[u4E00-u9FA50-9a-zA-Z_]+$ " )
2、只含有汉字、数字、字母、下划线,下划线位置不限:
^[a-zA-Z0-9_u4e00-u9fa5]+$
3、由数字、26个英文字母或者下划线组成的字符串
^w+$
4、2~4个汉字
@"^[u4E00-u9FA5]{2,4}$";
5、
^[w-]+(.[w-]+)*@[w-]+(.[w-]+)+$
用:(Abc)+ 来分析: XYZAbcAbcAbcXYZAbcAb
特定中文 匹配
问题描述:匹配“美丽乡村”中的一个字符或几个,如果是多个字符,顺序不能改变,如“丽乡”
解决过程:
之前知道匹配中文字符串,正则表达式中使用的是unicode编码的范围,如/^[x{4e00}-x{9fa5}]+$/u
想着特定字符是否可以不用转换成unicode编码,于是写出正则 '/^[美]{0,1}[丽]{0,1}[乡]{0,1}[村}]{0,1}$/u',总不能正确匹配
于是把汉字改成unicode编码,正则 /^[\x{7f8e}]{0,1}[\x{4e3d}]{0,1}[\x{4e61}]{0,1}[\x{6751}]{0,1}$/u 匹配成功
unicode-escape
Python中,unicode是内存编码集,将数据从内存存储到文件中时,需要先将数据编码为其他编码集,例如:UTF-8、GBK等。
1:str.encode():将字符串转换为其raw bytes形式。
2:bytes.decode():将raw bytes转换为字符串形式。
utf8StrToUnicode
回车符\r 和 换行符\n两种标记,如果只是去除\n,并不会起效果,需要replace('\n', '').replace('\r', '')配合使用
去除\u3000 使用 str.replace(u'\u3000',u' ')
去除空格replace(" ","")
常见非英文字符Unicode编码范围:
u4e00-u9fa5 (中文)
u0800-u4e00 (日文)
uac00-ud7ff(韩文)
send_time = re.findall('[\\u7eff]',soup.text )
var reg = /([/][^/]+)$/;
var blueurl = blueurl.replace(reg, "");
var reg2 = /([^/]+)$/;
var bluefile = blueurl.match(reg2)[1];
第一个正则获取最后一个/之前全部内容,
第二个正则获取最后一个/之后全部内容。
正则表达式中group()方法
group()方法的分组索引从1开始;默认索引为0,表示匹配到的结果
cannot use a string pattern on a bytes-like object
数据类型为bytes,时,就会包这个错误,因为它需要的是字符串
https://blog.csdn.net/kong_gu_you_lan/article/details/113062057
# re.S
# ((?<=exp).+) exp 后
# (.+(?=exp)) exp前边所有字符
# (?!exp) 不是exp
# \d{3} 数字
# \d{3}(?!\d) 匹配3位数字后非数字的结果
# (?<!exp) 前面不是exp的位置
# (?<![0-9])123 (?!<\d)123 123前面是非数字的结果
# (.*?)
'''
. - 除换行符以外的所有字符。
^ - 字符串开头。
$ - 字符串结尾。
\d,\w,\s - 匹配数字、字符、空格。
\D,\W,\S - 匹配非数字、非字符、非空格。
[abc] - 匹配 a、b 或 c 中的一个字母。
[a-z] - 匹配 a 到 z 中的一个字母。
[^abc] - 匹配除了 a、b 或 c 中的其他字母。
aa|bb - 匹配 aa 或 bb。
? - 0 次或 1 次匹配。
* - 匹配 0 次或多次。
+ - 匹配 1 次或多次。
{n} - 匹配 n次。
{n,} - 匹配 n次以上。
{m,n} - 最少 m 次,最多 n 次匹配。
(expr) - 捕获 expr 子模式,以 \1 使用它。
(?:expr) - 忽略捕获的子模式。
(?=expr) - 正向预查模式 expr。
(?!expr) - 负向预查模式 expr。
'''
![[Flutter get_cli] 配置 sub_folder:false报错](https://img-blog.csdnimg.cn/direct/b4b8bb363b7b42bc96c6ab4fbffd0d10.png)