文章目录
-
- 一、RAG介绍
-
- 1)局限性
- 2)通过检索增强生成
- 二、RAG系统的基本搭建流程
-
- 1)搭建流程简介
- 2)文档的加载和切割
- 3)检索引擎
- 4)LLM接口封装
- 5)prompt模板
- 6)RAG Pipeline初探
- 7)关键字检索局限性
- 三、向量检索
-
- 1)文本向量
- 2)向量相似度计算
- 3)向量数据库
- 4)基于向量检索的RAG
- 5)若想换个国产模型
- 6)OpenAI新发布的两个Embedding模型
- 四、实战RAG进阶
-
- 1)文本分割的粒度
- 2)检索后排序
- 3)混合检索
- 4)RAG-Fusion
- 五、向量模型的本地部署
- 六、总结
-
- 1)离线步骤
- 2)在线步骤
一、RAG介绍
1)局限性
1、LLM 的知识不是实时的
2、LLM 可能不知道你私有的领域/业务知识
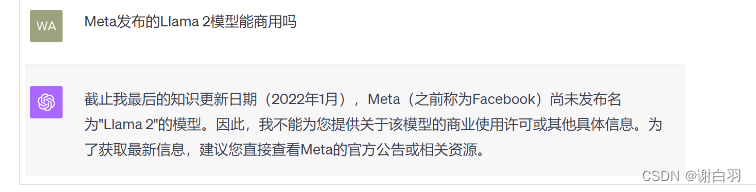
2)通过检索增强生成
- RAG定义:
RAG(Retrieval Augmented Generation)顾名思义,通过检索的方法来增强生成模型的能力。 - 示例
上传了对应PDF去解析
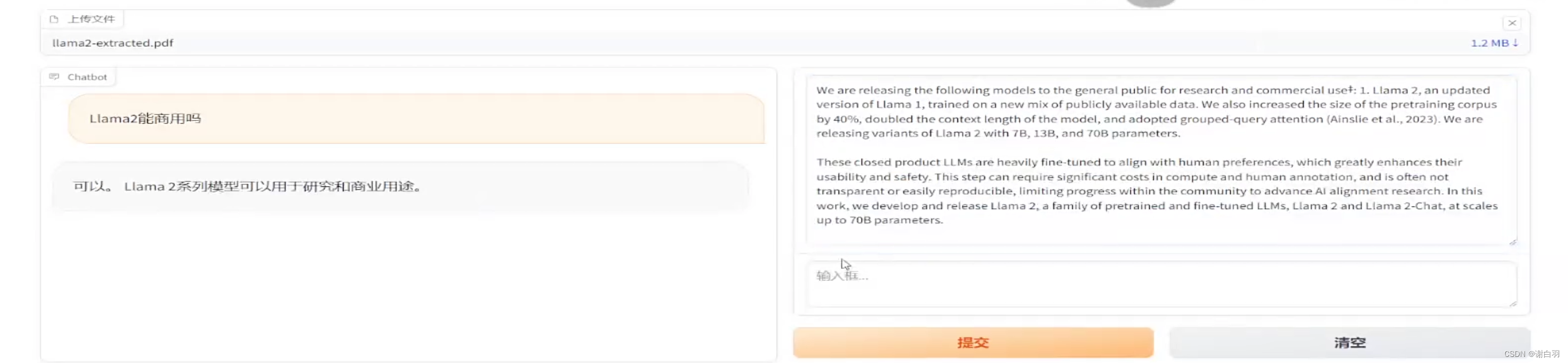
- 大概流程

二、RAG系统的基本搭建流程
1)搭建流程简介
搭建过程:
1、文档加载,并按一定条件切割成片段
2、将切割的文本片段灌入检索引擎
3、封装检索接口
4、构建调用流程:Query -> 检索 -> Prompt -> LLM -> 回复
2)文档的加载和切割
- 安装
pip install --upgrade openai
-------------------
# 安装 pdf 解析库
!pip install pdfminer.six
- 解析代码
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
def extract_text_from_pdf(filename, page_numbers=None, min_line_length=1):
'''从 PDF 文件中(按指定页码)提取文字'''
paragraphs = []
buffer = ''
full_text = ''
# 提取全部文本
for i, page_layout in enumerate(extract_pages(filename)):
# 如果指定了页码范围,跳过范围外的页
if page_numbers is not None and i not in page_numbers:
continue
for element in page_layout:
if isinstance(element, LTTextContainer):
full_text += element.get_text() + '\n'
# 按空行分隔,将文本重新组织成段落
lines = full_text.split('\n')
for text in lines:
if len(text) >= min_line_length:
buffer += (' '+text) if not text.endswith('-') else text.strip('-')
elif buffer:
paragraphs.append(buffer)
buffer = ''
if buffer:
paragraphs.append(buffer)
return paragraphs
#提取片段并打印
paragraphs = extract_text_from_pdf("llama2.pdf", min_line_length=10)
for para in paragraphs[:3]:
print(para+"\n")
- 回复
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron∗ Louis Martin† Kevin Stone† Peter Albert Amjad Almahairi Yasmine Babaei Nikolay Bashlykov Soumya Batra Prajjwal Bhargava Shruti Bhosale Dan Bikel Lukas Blecher Cristian Canton Ferrer Moya Chen Guillem Cucurull David Esiobu Jude Fernandes Jeremy Fu Wenyin Fu Brian Fuller Cynthia Gao Vedanuj Goswami Naman Goyal Anthony Hartshorn Saghar Hosseini Rui Hou Hakan Inan Marcin Kardas Viktor Kerkez Madian Khabsa Isabel Kloumann Artem Korenev Punit Singh Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich Yinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra Igor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi Alan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang Ross Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang Angela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic Sergey Edunov Thomas Scialom∗
GenAI, Meta
3)检索引擎
- 安装库
# 安装 ES 客户端
!pip install elasticsearch7
# 安装NLTK(文本处理方法库)
!pip install nltk
- 预先准备(安装停词方法和屏蔽警告)
from elasticsearch7 import Elasticsearch, helpers
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import nltk
import re
import warnings
warnings.simplefilter("ignore") # 屏蔽 ES 的一些Warnings
nltk.download('punkt') # 英文切词、词根、切句等方法
nltk.download('stopwords') # 英文停用词库
- 去停用词,取词根方法
def to_keywords(input_string):
'''(英文)文本只保留关键字'''
# 使用正则表达式替换所有非字母数字的字符为空格
no_symbols = re.sub(r'[^a-zA-Z0-9\s]', ' ', input_string)
word_tokens = word_tokenize(no_symbols)
# 加载停用词表
stop_words = set(stopwords.words('english'))
ps = PorterStemmer()
# 去停用词,取词根
filtered_sentence = [ps.stem(w)
for w in word_tokens if not w.lower() in stop_words]
return ' '.join(filtered_sentence)
- ES处理
1)将本文灌入检索引擎
# 1. 创建Elasticsearch连接
es = Elasticsearch(
hosts=['http://117.50.198.53:9200'], # 服务地址与端口
http_auth=("elastic", "FKaB1Jpz0Rlw0l6G"), # 用户名,密码
)
# 2. 定义索引名称
index_name = "teacher_demo_index_tmp"
# 3. 如果索引已存在,删除它(仅供演示,实际应用时不需要这步)
if es.indices.exists(index=index_name):
es.indices.delete(index=index_name)
# 4. 创建索引
es.indices.create(index=index_name)
# 5. 灌库指令
actions = [
{
"_index": index_name,
"_source": {
"keywords": to_keywords(para),
"text": para
}
}
for para in paragraphs
]
# 6. 文本灌库
helpers.bulk(es, actions)
2)实现关键字检索
def search(query_string, top_n=3):
# ES 的查询语言
search_query = {
"match": {
"keywords": to_keywords(query_string)
}
}
res = es.search(index=index_name, query=search_query, size=top_n)
return [hit["_source"]["text"] for hit in res["hits"]["hits"]]
results = search("how many parameters does llama 2 have?", 2)
for r in results:
print(r+"\n")
- ES回复
Llama 2 comes in a range of parameter sizes—7B, 13B, and 70B—as well as pretrained and fine-tuned variations.
1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (A