欢迎来到《小5讲堂》,大家好,我是全栈小5。
这是《Sql Server》系列文章,每篇文章将以博主理解的角度展开讲解,
特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握。
温馨提示:博主能力有限,理解水平有限,若有不对之处望指正!

目录
- 前言
- 创建存储过程
- 创建格式
- 返回数据集
- 使用事务
- 修改存储过程
- 输出异常信息
- 正确代码
- 常见场景
- 目前现状
- 文章推荐
前言
上周有个小伙伴留言,让博主写一篇存储过程的知识点文章,
刚好趁此机会简单总结下存储过程,以及它的运用场景和现状。
存储过程可以写的很简答,也可以写的很复杂,看实际业务场景。
创建存储过程
创建格式
CREATE PROCEDURE procedure_name
@parameter1 data_type1 = default_value1,
@parameter2 data_type2 = default_value2,
...
AS
BEGIN
-- 存储过程的逻辑代码
END
存储过程的主要结构包含以下几个部分:
1.存储过程名称(procedure_name)
用于标识存储过程的唯一名称。
2.输入参数(@parameter1, @parameter2, …)
可选的输入参数,用于接收外部传入的值。每个参数包括参数名、数据类型和默认值(可选)。
3.存储过程逻辑
在 BEGIN 和 END 之间编写存储过程的实际逻辑代码,可以包括各种 SQL 查询、更新、插入、删除等操作。
返回数据集
创建一个存储过程,用于返回一个查询数据集,基于之前文章创建过的表进行查询,具体可以在文章底部跳转链接查询。
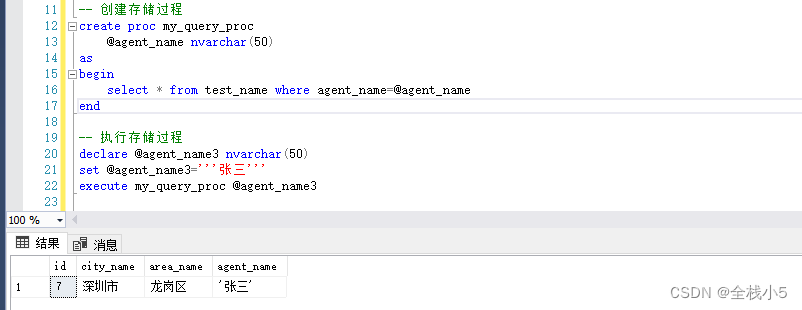
这里的存储过程关键词procedure,可以缩写成proc。使用execute关键词执行创建好的存储过程以及传参
-- 创建存储过程
create proc my_query_proc
@agent_name nvarchar(50)
as
begin
select * from test_name where agent_name=@agent_name
end
-- 执行存储过程
declare @agent_name3 nvarchar(50)
set @agent_name3='''张三'''
execute my_query_proc @agent_name3
使用事务
通过传递值,在存储过程中执行操作,添加记录并且使用事务功能,事务关键词transaction,同样可以进行简写为tran。
下面存储过程代码,直接给自增id赋值是会报错,从而导致事务回滚。
-- 使用事务
create proc my_tran_proc
@agent_name5 nvarchar(50)
as
begin
begin transaction; -- 开始事务
begin try
insert into test_name(id,city_name,area_name,agent_name)
values(1,'深圳市','龙岗区',@agent_name5)
end try
begin catch
rollback transaction; -- 回滚事务
end catch
select * from test_name where agent_name=@agent_name5
end
-- 执行存储过程
declare @agent_name6 nvarchar(50)
set @agent_name6='''张三'''
execute my_tran_proc @agent_name6
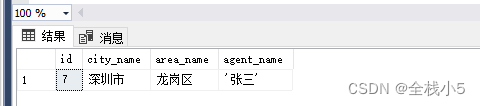
在上面语句存在了报错情况,但是没有输出异常信息,如果添加成功,那么是会返回两条记录
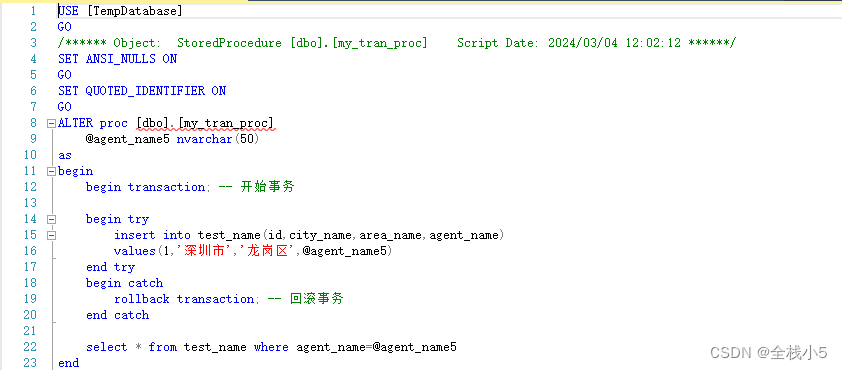
修改存储过程
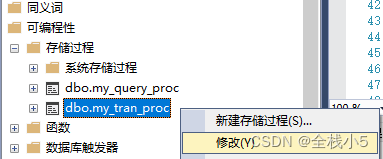
修改存储过程也很简答,通过可视化界面直接找到,在里面修改
输出异常信息
通过上一步修改存储过程后,再执行存储过程,切换到消息即可查看到输出的错误信息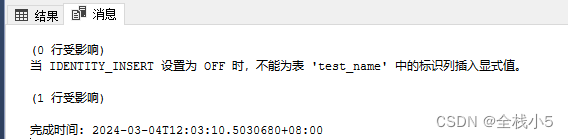
正确代码
-- 使用事务
alter proc my_tran_proc
@agent_name5 nvarchar(50)
as
begin
begin transaction; -- 开始事务
begin try
insert into test_name(city_name,area_name,agent_name)
values('深圳市','龙岗区',@agent_name5)
end try
begin catch
rollback transaction; -- 回滚事务
declare @errorMessage nvarchar(4000) = error_message();
print(@errorMessage)
end catch
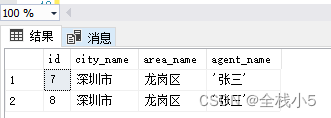
select * from test_name where agent_name=@agent_name5
end
-- 执行存储过程
declare @agent_name6 nvarchar(50)
set @agent_name6='''张三'''
execute my_tran_proc @agent_name6
常见场景
SQL Server 存储过程的运用场景很多,
主要可分为以下几类:
1.执行复杂的数据处理操作
当需要进行复杂的数据处理时,可能需要多次查询、更新、插入、删除等操作。将这些操作封装在一个存储过程中可以简化代码的编写,提高效率,并且可以重复使用相同的代码逻辑。
2.提高数据库性能
存储过程可以被预编译,并且可以缓存执行计划,这样可以降低数据库服务器的负载并提高查询的执行效率。
3.简化应用程序代码
通过调用存储过程,应用程序可以将逻辑转移至数据库端,简化代码,提高效率,并且可以更容易地对数据库进行管理和维护。
4.加强数据安全性
存储过程可以设置权限控制,限制对数据库的访问权限,确保敏感数据的安全性,防止非法的操作。
5.实现事务操作
对于需要实现事务的数据库操作,可以使用存储过程来组织多个操作,确保事务的原子性。
总之,SQL Server 存储过程是一种强大而灵活的工具,可以用于解决各种不同的数据库需求,提高应用程序的效率和安全性。
目前现状
现在越来越多的公司在实际应用中减少了对存储过程的大量使用。博主在接触到的公司也确实是如此,也看实际业务情况。
这种趋势的主要原因包括:
1.ORM(对象关系映射)框架的普及和成熟
ORM框架(如Entity Framework、Hibernate等)的发展使得应用程序更倾向于采用对象关系映射的方式来处理数据操作,而不是直接使用存储过程。ORM框架可以将数据库表映射为对象,简化了数据访问层的开发和维护。
2.API 和微服务架构的兴起
随着微服务架构的流行,越来越多的公司将业务逻辑封装在独立的 API 中,而不是通过存储过程来实现。API 提供了更灵活的方式来访问和处理数据,同时也更易于扩展和维护。
3.更多的业务逻辑移到应用层
随着业务需求的不断变化,很多公司倾向于将更多的业务逻辑放在应用层实现,而不是存储过程中。这样可以更容易地控制和修改业务逻辑,也减少了对数据库的依赖。
尽管如此,存储过程仍然在某些特定场景下发挥着重要作用,比如处理复杂的数据逻辑、实现事务控制、提高数据库性能等。
因此,并不是所有的公司都完全弃用存储过程,而是根据具体的需求和情况决定是否使用存储过程。
文章推荐
【新星计划回顾】第六篇学习计划-通过自定义函数和存储过程模拟MD5数据
【新星计划回顾】第四篇学习计划-自定义函数、存储过程、随机值知识点
【Sql Server】Update中的From语句,以及常见更新操作方式
【Sql server】假设有三个字段a,b,c 以a和b分组,如何查询a和b唯一,但是c不同的记录
【Sql Server】新手一分钟看懂在已有表基础上修改字段默认值和数据类型
总结:温故而知新,不同阶段重温知识点,会有不一样的认识和理解,博主将巩固一遍知识点,并以实践方式和大家分享,若能有所帮助和收获,这将是博主最大的创作动力和荣幸。也期待认识更多优秀新老博主。