PyTorch深度学习实战(38)——StyleGAN详解与实现
- 0. 前言
- 1. StyleGAN
- 1.1 模型介绍
- 1.2 模型策略分析
- 2. 实现 StyleGAN
- 2.1 生成图像
- 2.2 风格迁移
- 小结
- 系列链接
0. 前言
StyleGAN (Style-Generative Adversarial Networks) 是生成对抗网络 (Generative Adversarial Networks, GAN) 的变体,是一种无监督学习模型,用于生成逼真且高分辨率的图像。与传统 GAN 不同,StyleGAN 引入了两个关键概念:样式迁移和逐渐增强。样式迁移允许生成网络控制图像的风格和外观,从而生成具有不同特征的图像。逐渐增强则是指生成网络逐层地生成图像,先生成粗略的细节,然后逐渐添加更多细节和结构,从而获得更加逼真的图像。本节中,将利用预训练的 StyleGAN2 模型执行风格迁移。
1. StyleGAN
1.1 模型介绍
相比于传统生成对抗网络 (Generative Adversarial Networks, GAN),StyleGAN 的主要优点在于其能够生成高分辨率的逼真图像,同时可以控制所生成图像的风格。StyleGAN 使用自适应实例规范化 (Adaptive Instance Normalization, AdaIN),可以从输入的噪声向量中学习多个层次的风格信息,并且可以通过调整生成网络的输入来控制所生成图像的风格。
在 StyleGAN 之前,GAN 面临的最大问题是生成的图像分辨率通常较小(通常为 64 x 64),尝试生成更大尺寸图像会导致生成网络或判别网络陷入局部最小值。ProGAN (Progressive GAN) 通过渐进式逐层增强的方式来生成高分辨率、逼真的图像,从而克服了传统 GAN 在高分辨率图像生成时面临的困难,为高质量图像生成奠定了基础。
具体来说,ProGAN 采用了分层的生成网络结构,每一层都包含一个生成网络和一个判别网络,同时每一层的输出分辨率也相应地增加。在训练过程中,逐渐增加图像的分辨率,直到达到所需的分辨率。这种逐渐增加分辨率的方法,可以使得模型在从低分辨率图像逐渐生成高分辨率图像的过程中逐渐学习更多的图像特征,从而生成更加逼真的图像。通过这种方式,ProGAN 已经能够成功地生成高达 1024x1024 像素的图像,其生成质量和逼真度已经接近甚至超越了人眼的识别限制:

尽管 ProGAN 成功地提高了生成图像的质量,但仍然难以控制生成图像的属性,例如性别和年龄等,主要是因为网络只有一个输入,为了解决这一问题,Tero Karras 等人提出了 StyleGAN。
StyleGAN 使用与 ProGAN 类似的训练方案,逐步生成图像,但每次网络增加时都会添加一组新的潜在输入,即网络在获得所需尺寸的图像前会接受多个潜在向量。在生成阶段给出的每个潜在向量都决定了在该网络阶段将生成的特征(图像风格):

在上图中,我们可以看到传统的图像生成方式与基于风格的生成网络之间的差别。在传统的生成网络中,只有一个输入;但基于风格的生成网络中采用以下机制:
- 创建一个大小为
1 x 512的随机噪声向量 z z z - 将其输入到风格网络(或映射网络)的辅助网络中,该网络创建大小为
18 x 512的张量 w w w - 生成(合成)网络包含
18个卷积层,每一层都将接受以下内容作为输入:- w ( A ) w(A) w(A) 的对应行
- 随机噪声向量 ( B ) (B) (B)
- 上一层的输出
其中,噪声 ( B ) (B) (B) 仅用于正则化。
以上三个组合将创建一个管道,该管道接收一个 1 x 512 向量并创建一个 1024 x 1024 图像。映射网络能够生成 18 x 512 向量,其中每个 1 x 512 向量(共 18 个)都能够图像的生成作出贡献。输入合成网络前几层的 1 x 512 向量(负责生成 4 x 4、8 x 8 的图像)有助于得到图像的整体姿态和大尺度特征(如姿势、面部形状等),并且会在后面几层得到增强;添加到中间层的向量(负责生成 16 x 16、32 x 32 和 64 x 64 图像)对应于小尺度特征,例如发型、睁眼或闭眼等;添加到最后几层的向量对应于图像的颜色方案和其他微观结构,在最后几层时,图像结构被保留,面部特征也被保留,只有图像级别的细节,例如光照条件等会发生变化。
1.2 模型策略分析
在本节中,我们将利用预训练的 StyleGAN2 模型执行风格迁移,以生成具有不同风格的图像,模型策略原理如下所示:
- 假设
w
1
w_1
w1 风格向量用于生成
face-1,而 w 2 w_2 w2 风格向量用于生成face-2,样式向量的形状都为18 x 512 -
w
2
w_2
w2 中的前几个向量(负责生成从
4 x 4到8 x 8分辨率的图像)被替换为来自 w 1 w_1 w1 的相应向量,这样我们就可以将低级特征(如面部姿态)从face-1迁移到face-2 - 如果
w
2
w_2
w2 的中间的风格向量(比如第
3到15——负责生成64 x 64到256 x 256分辨率的图像)被替换为 w 1 w_1 w1 中的风格向量,则可以迁移例如眼睛、鼻子等其他中级特征 - 如果最后几个风格向量(负责生成
512 x 512到1024 x 1024分辨率的图像)被替换,则肤色和背景等精细特征将会(不会显着影响面部整体特征)被迁移
了解了风格迁移的策略后,现在让我们了解如何使用 StyleGAN2 在自定义图像上执行风格迁移:
- 获取图像
- 对齐图像,以便存储图像中的面部区域
- 获取对齐图像的潜在向量
- 通过将随机潜在向量 (
1 x 512) 传递到映射网络生成图像
通过以上过程,得到两个图像:对齐图像和 StyleGAN2 网络生成的图像,然后将对齐图像的一些特征迁移到 StyleGAN2 网络生成的图像中。
2. 实现 StyleGAN
接下来,我们使用 PyTorch 实现以上策略,为了节省训练时间,从 gitcode 中获取预训练网络,下载后解压缩。
2.1 生成图像
(1) 获取预训练网络权重:
from pytorch_stylegan_encoder.InterFaceGAN.models.stylegan_generator import StyleGANGenerator
from pytorch_stylegan_encoder.models.latent_optimizer import PostSynthesisProcessing
import torch
import numpy as np
from matplotlib import pyplot as plt
from glob import glob
import cv2
synthesizer = StyleGANGenerator("stylegan_ffhq").model.synthesis
mapper = StyleGANGenerator("stylegan_ffhq").model.mapping
trunc = StyleGANGenerator("stylegan_ffhq").model.truncation
(2) 加载预训练的生成网络、合成网络和映射网络的权重:
post_processing = PostSynthesisProcessing()
post_process = lambda image: post_processing(image).detach().cpu().numpy().astype(np.uint8)[0]
(3) 定义函数根据随机向量生成图像:
def latent2image(latent):
img = post_process(synthesizer(latent))
img = img.transpose(1,2,0)
return img
(4) 生成随机向量:
rand_latents = torch.randn(1,512).cuda()
在以上代码中,通过映射网络传递随机的 1 x 512 维向量以生成 1 x 18 x 512 维向量,生成的 18 x 512 维向量决定了生成图像的风格。
(5) 根据随机向量生成图像:
plt.imshow(latent2image(trunc(mapper(rand_latents))))
plt.show()

2.2 风格迁移
接下来,我们将学习如何在以上生成图像和其他选择图像之间执行风格迁移,首先从 gitcode 中获取用于人脸对齐的程序并解压缩。
(1) 获取测试图像 (MyImage.jpg) 并将其对齐,对齐对于生成合适的潜在向量非常重要,因为 StyleGAN 生成的所有图像都以人脸为中心且特征明显,在 shell 中执行以下命令对齐测试图像:
$ mkdir -p stylegan-encoder/raw_images
$ mkdir -p stylegan-encoder/aligned_images
$ mv MyImage.jpg stylegan-encoder/raw_images
$ python stylegan-encoder/align_images.py stylegan-encoder/raw_images/ stylegan-encoder/aligned_images/
$ mv stylegan-encoder/aligned_images/* ./MyImage.jpg
(2) 查看对齐后的测试图像
from PIL import Image
img = Image.open('MyImage.jpg')
plt.imshow(np.array(img))
plt.title('original')
plt.show()

(3) 使用对齐图像生成潜在向量,这是一个识别潜在向量组合的过程,该组合使对齐图像与根据潜在向量生成的图像之间的差异最小化。
首先,在 shell 中执行以下命令:
$ python encode_image.py MyImage.jpg pred_dlatents_image.npy --use_latent_finder true --image_to_latent_path ../trained_models/image_to_latent.pt
encode_image.py 程序执行以下操作:
- 在潜在空间中创建一个随机向量 w w w
- 使用随机向量 w w w 生成图像
- 使用 VGG 感知损失(与神经风格迁移中的损失相同)将生成图像与原始输入图像进行比较
- 对随机向量 w w w 执行反向传播,减少损失
- 优化后的
w
w
w 向量将生成一张
VGG特征与输入图像几乎相同的图像,因此合成图像看起来与输入图像相似。
然后,继续编写代码:
pred_dlatents = np.load('pred_dlatents_image.npy')
pred_dlatent = torch.from_numpy(pred_dlatents).float().cuda()
pred_image = latent2image(pred_dlatent)
plt.imshow(pred_image)
plt.title('synthesized')
plt.show()

得到了与感兴趣图像相对应的潜在向量后,执行图像风格迁移。
(4) 执行风格迁移。
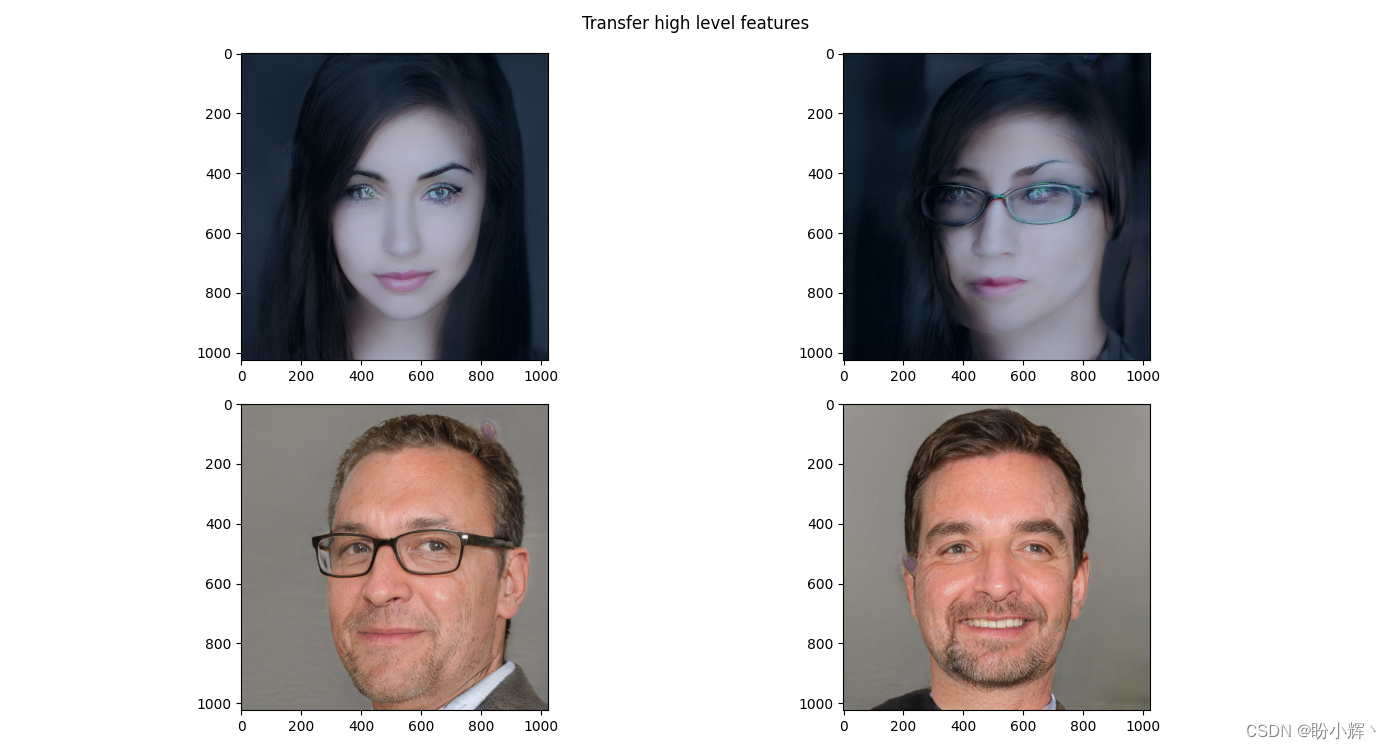
风格迁移的核心逻辑实际上是风格张量的部分迁移,即 18 x 512 风格张量中的 18 个子集。接下来,我们分别传输前两行、 3-15 行、15-18 行;由于每组向量负责生成图像的不同方面,因此每组交换的向量会交换图像中的不同特征:
idxs_to_swap = slice(0,3)
my_latents = torch.Tensor(np.load('pred_dlatents_image.npy', allow_pickle=True))
A, B = latent2image(my_latents.cuda()), latent2image(trunc(mapper(rand_latents)))
generated_image_latents = trunc(mapper(rand_latents))
x = my_latents.clone()
x[:,idxs_to_swap] = generated_image_latents[:,idxs_to_swap]
a = latent2image(x.float().cuda())
x = generated_image_latents.clone()
x[:,idxs_to_swap] = my_latents[:,idxs_to_swap]
b = latent2image(x.float().cuda())
plt.subplot(221)
plt.imshow(A)
plt.subplot(222)
plt.imshow(a)
plt.subplot(223)
plt.imshow(B)
plt.subplot(224)
plt.imshow(b)
plt.suptitle('Transfer high level features')
plt.show()
idxs_to_swap 分别作为 slice(4,15) 和 slice (15,18) 的输出如下:


(5) 接下来,我们需要推导一组风格向量,新向量仅改变测试图像的笑脸。为此,需要计算沿潜在向量z移动的正确方向。我们可以通过首先创建大量伪造图像来实现这一点,然后训练 SVM 分类器判断图像中的人物是否微笑,该 SVM 将创建一个超平面,划分笑脸与非笑脸,潜在向量
z
z
z 所需的移动方向将垂直于这个超平面,在 shell 中执行以下命令:
python InterFaceGAN/edit.py -m stylegan_ffhq -o results_new_smile -b InterFaceGAN/boundaries/stylegan_ffhq_smile_w_boundary.npy -i pred_dlatents_image.npy -s WP --steps 20
可视化生成图像:
generated_faces = glob('results_new_smile/*.jpg')
cols = len(generated_faces)
ix = 1
for im in sorted(generated_faces):
plt.subplot(1, cols, ix)
plt.imshow(cv2.cvtColor(cv2.imread(im,1), cv2.COLOR_BGR2RGB))
ix += 1
plt.show()
小结
StyleGAN 能够生成非常高分辨率人脸图像的关键在于,在增加分辨率的步骤中逐步增加生成网络和判别网络的复杂性,以便在每一步中,两个模型都可以很好地完成任务。我们学习了如何通过确保每个分辨率的特征由一个独立的输入(称为风格向量)来控制,从而操纵生成图像的风格,以及如何通过将图像之间的风格进行交换来操作不同图像的风格。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——从零开始实现SSD目标检测
PyTorch深度学习实战(24)——使用U-Net架构进行图像分割
PyTorch深度学习实战(25)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(26)——多对象实例分割
PyTorch深度学习实战(27)——自编码器(Autoencoder)
PyTorch深度学习实战(28)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(29)——变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(30)——对抗攻击(Adversarial Attack)
PyTorch深度学习实战(31)——神经风格迁移
PyTorch深度学习实战(32)——Deepfakes
PyTorch深度学习实战(33)——生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(34)——DCGAN详解与实现
PyTorch深度学习实战(35)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(36)——Pix2Pix详解与实现
PyTorch深度学习实战(37)——CycleGAN详解与实现