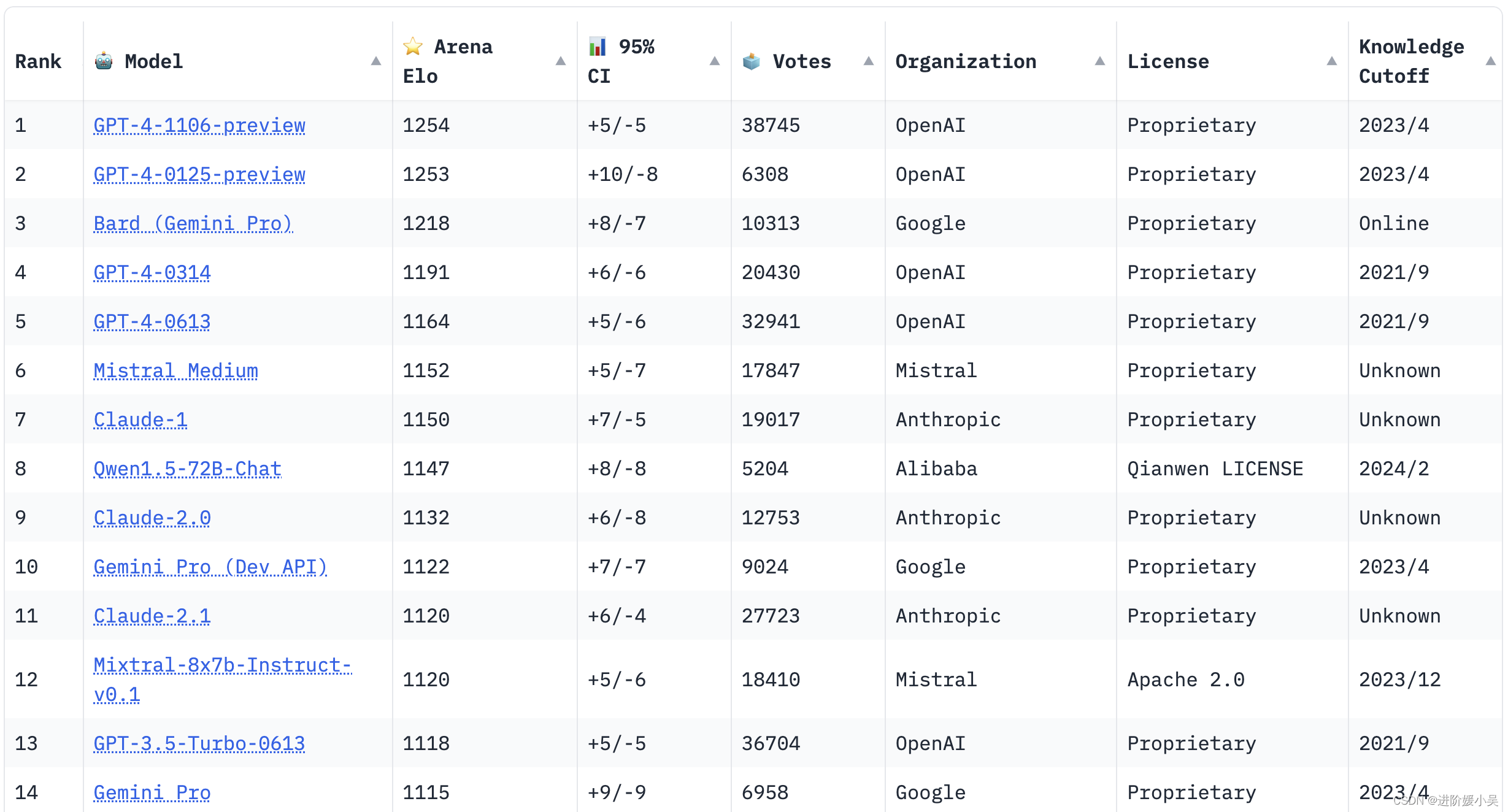
目录
一、背景
二、松果出行实时OLAP的演进
2.1 实时数仓1.0的架构
2.2 实时数仓2.0的架构
2.3 实时数仓3.0的架构
三、StarRocks 的引入
四、StarRocks在松果出行的应用
4.1 在订单业务中的应用
4.2 在车辆方向的应用
4.3 StarRocks “极速统一” 落地
4.4 StarRocks 与内部平台的融合
五、总结与规划
原文大佬的这篇StarRocks数仓建设案例有借鉴意义,这里摘抄下来用作学习和知识沉淀。
一、背景
松果出行作为一家面向未来的交通行业科技公司,业务数据涵盖支付、车辆、制造、营销、订单、广告等。凭借 StarRocks高效的多表关联以及实时更新能力,放弃了原有基于 Impala+Kudu 和 ClickHouse 的实时数仓构建模式,基于 StarRocks 实践了全新的实时数仓模式,大幅的降低了实时分析构建的复杂性。通过这个平台,我们不仅可以快速构建各种小时、分钟、秒级的看板指标以及数据服务,还能保证数据在导入准确的同时保持高性能。
在引入 StarRocks后,我们不断做减法,成功统一查询引擎、降低维护成本、提高数据取用灵活性。如今,StarRocks 已成为我们数据中台统一分析的底座。
二、松果出行实时OLAP的演进
作为对内对外的数据窗口的提供者,松果出行数据中台部门的职责是围绕数据集群、OLAP 引擎、离线 / 实时数仓、画像标签、数据治理、产品工具等,结合数据建模、人工智能、增强分析、数据可视化等技术,为业务的智能化分析决策提供支撑。
两轮电单车出行是我们的核心业务。业务链条主要包含投车、骑行、支付、换电、营销、挪车等很多环节。在这些过程中我们需要对中间过程中的变更做留存,也需要对最终的结果数据计算。既有针对车的、也有针对不同区域、订单的维度需求,需要定时或不定时提供多维度的数据。准实时、实时的数据需求也越来越多,越来越迫切。
松果出行数据中台采用的是经典的Lambda架构,离线跟实时是两套单独的体系;离线以 Hive、Spark、Presto、MySQL 为主,做数据清洗、计算、查询、展示使用,这套架构基本能满足离线分析的需求。对于实时场景的探索,主要经历了三个阶段:
2.1 实时数仓1.0的架构
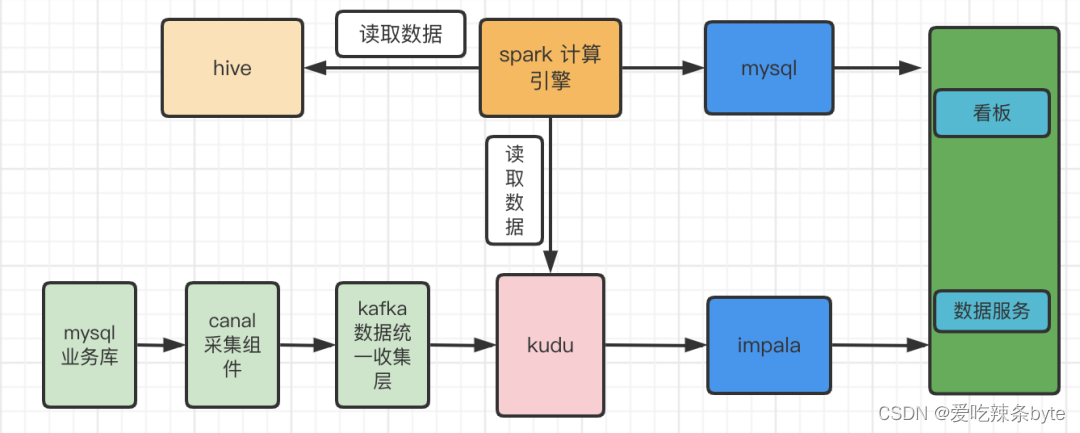
MySQL 业务库数据经 Canal 实时抽取并发送到Kafka再写入 Kudu,Spark定时从 Kudu 读取数据并计算,通过Impala进行查询,提供小时级看板指标到 BI,解决了业务对于小时级数据的分析需求。另外一部分数据经 Spark 计算后写入 MySQL,用作对外的数据服务。
但随着深入使用,这套方案也存在以下痛点:
- 需要单独开发维护一套 Spark 程序来读取 Kudu表,定时计算,维护成本高;
- Kudu表的创建、读取、修改都不是很方便,要花很多时间修改程序;
- 对于一些由多个原子指标组合衍生出来的指标无法快速实现;
- Impala + Kudu 的组件维护成本高;
- 无法获取每条变更日志所有变更状态的明细数据;
- 针对 Kudu 跟 Impala 的监控缺失;
- 大数据量的快速查询无法支撑。
2.2 实时数仓2.0的架构
为了解决以上痛点,我们又引入了实时2.0 的架构,如下图所示:

此方案数据采集阶段跟 1.0 架构相同,都是利用 Canal 组件实时抽取业务库数据到 Kafka,ETL阶段用Flink Stream+Flink SQL消费kafka做数据清洗和分层,DIM层数据存储在HBase和Mysql中,ODS,DWD等其他层数据放入Kafka,最后通过 Flink对数据进行关联、扩维、深度清洗后写入ClickHouse 对外提供查询。
在 2.0 架构中,用 ClickHouse 替换了 Kudu + Impala,主要利用ClickHouse 的如下功能:
- 丰富多样的表引擎可以支持不同业务查询;
- 利用任意合法表达式的分区操作进行裁剪,大大提高查询效率;
- 支持表级及列级过期设置,降低空间占用率;
- 支持不同压缩方式,提高查询速度;
- 类 SQL 语法,且支持多种不同组件,对外提供 HTTP、JDBC、ODBC 等不同链接方式,便于整合到不同工具链路当中;
- 丰富的函数库,可满足不同查询需求。
这套方案提供了小时级以及更小时间粒度的看板指标需求,解决了 1.0 方案的一部分痛点,在一段时间内可以满足业务需求。但随着应用的深入,这套方案也展现出一些问题:
- 更新删除能力差,去重能力差,导致数据准确性差;
- 组件维护成本高;
- 表结构变更成本高;
- 查询并发有限制;
- 分布式表的节点横向扩展差;
- 多表 Join 性能差。
2.3 实时数仓3.0的架构
为了解决以上问题,我们又引入了 StarRocks,实时架构演化了到了 3.0 方案:
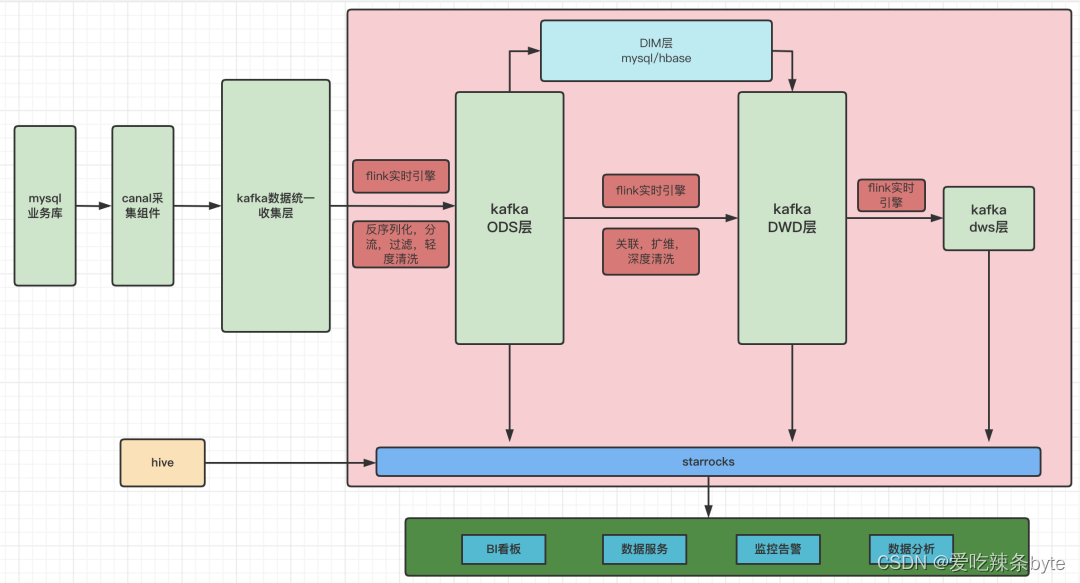
数据采集到Kafka之后,先是通过Flink Stream 进行反序列化、分流等操作,然后通过Flink SQL进行关联、扩维等,分为ODS、DIM、DWD、DWS层,其中DIM层存储在Mysql与HBase当中,其他层存储在kafka当中,层到层之间都是通过Flink来实现,所有数据的最终归口都在StarRocks。目前提供小时、分钟、秒级的看板指标及数据服务,历史数据和增量数据共同存储。3.0方案完美解决了 1.0跟 2.0方案的痛点,甚至超出了我们的预期。
三、StarRocks 的引入
引入 StarRocks 主要是为了解决 2.0 架构面临的痛点。总结下来,我们对新的 OLAP 引擎的期望主要包括下面几点:
- 不仅大宽表查询性能好,多表 Join 查询性能也非常优秀;
- 支持 SQL 和类 SQL 查询,方便业务使用;
- 支持批量、实时数据导入,满足历史数据和增量数据的提数需求;
- 支持数据的更新、过期等,支持表结构的快速变更;
- 支持大数据量的秒级查询响应;
- 有较好的并发支持能力;
- 可以兼容已有的数据架构,可以方便地与 HDFS、Hive、MySQL 等交互使用;
- 有较强的容灾能力,运维简单,部署快速;
四、StarRocks在松果出行的应用
4.1 在订单业务中的应用
订单分析是我们的核心业务场景之一。引入 StarRocks 后,整个链路设计如下:

历史数据用Broker Load从Hive直接导入StarRocks。增量数据通过Canal 抽取后再通过 Flink SQL 将订单表做字段补齐生成宽表后,直接用Routine Load 写入 StarRocks明细模型表,然后创建逻辑视图来满足不同维度的计算及所有状态的明细数据查询需求,在这层逻辑视图上,通过调度平台定时对数据加工汇总后Insert 到 StarRocks,作为数仓 ADS 层来满足不同团队的查询需求。
这套架构的好处是,我们只需要 Flink 做简单的 ETL 处理,后续业务计算在StarRocks 进行,避免数据重复消费,这样可以快速灵活地响应不同团队不同维度的需求,而不需要在对接新的需求时,重新设计方案来对接,从而降低开发工期、灵活适用不同场景。
目前,我们基于StarRocks 实现了秒级、小时级、天级的时间分析粒度,城市,大区,全国的区域分析粒度,供订单量、订单总金额、超时费、里程费、客单价等维度下 30 多种不同的指标。业务变更已完全不需要我们重新修改开发程序,数据验证也简单快速。作为数据中台部门,只需新建一个视图或者修改视图,,即可快速上线,提供数据支撑。在进行数据修复、异常追溯时也链路清晰,极大地提高了开发效率。
4.2 在车辆方向的应用
车辆是我们的核心资产。从车辆的投放,到挪车、换电、维修等,整个链路非常长,不同车辆的状态是我们关注的重点,整个数据链路如下:
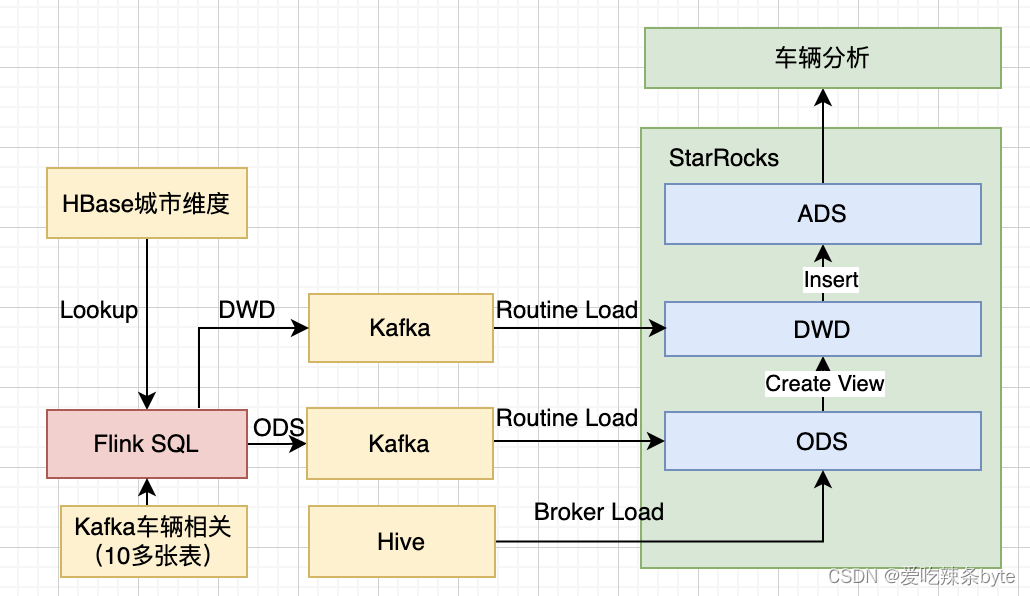
这条数据链路涉及10多张表,基本都是业务库数据。每张表要求的数据存储状态都不一样。比如实际投放车辆数,需要用到历史和实时的所有数据,中间会减去未投放的车辆数。而投放状态是时刻变化的,实际使用车辆数需要从订单表中增量获取当天被骑行的车辆数,可用车辆数则要从投放车辆数中减去那些维修、被收车、缺电等状态的车辆。这些状态的数据库表又是不同的业务团队所产生的,整合在一起非常繁琐。
如果用传统的实时数仓的模型,基于kafka+Flink窗口+状态无法实现这一复杂逻辑。如果用 Spark+Hive 的方式,数据的及时性无法保证,线上 Hadoop(集群压力会非常大,口径变更时修改也很复杂。
上述基于StarRocks搭建的数据链路,则解决了这些问题。对于能提前关联的数据,我们用 Flink SQL 打成大宽表入库,需要历史数据且状态时刻变化的数据全量从 Hive 导入 StarRocks,然后通过Canal 抽取增量数据到 Kafka ,再导入 StarRocks 来更新状态。在最上层创建逻辑视图,通过调度平台定时计算输出到ADS层,供业务方使用。当需要口径做变更,或者查看不同维度的车辆指标时,我们只需新建一个逻辑视图即可。
如今在车辆方向的应用,我们提供小时粒度的数据、20 多种不同的指标,给业务运营提供了扎实的数据支撑。
4.3 StarRocks “极速统一” 落地
基于StarRocks 在上述场景的成功应用,我们对其他场景的数据链路也进行了调整。目前 StarRocks 在数据中台的实时链路中应用非常广泛,已经是我们的重要基础。
大部分准实时、实时需求已接入这套体系。基于StarRocks的需求任务大概有 50 多个,提供了大概 150 多个指标、2T 多的数据。后续我们会将全部实时数据接入到 StarRocks,支撑实时数据分析、数据服务、指标展示、监控告警等方面的应用。
在接触并选用 StarRocks 之前,我们早期使用了很多组件:Druid、Kylin、ElasticSearch、Kudu、ClickHouse、Impala。这些组件的适用场景都不尽相同,语法以及能力也各有千秋。我们用 Druid 来预计算所有内部服务的埋点日志数据,但无法查看明细数据;用 Kudu 主键去重,来满足实时更新的业务数据去重需求,使用 Impala 或者 Presto 对外提供查询;用 ClickHouse 来存储实时埋点数据和业务数据,采用复杂语句来实现去重和窗口功能;用 Kylin 试点数据口径和维度相对固定的指标计算场景。总体而言,组件比较多,使用也比较混乱,不仅数据存储分散,占用有限的机器资源,而且每个组件的语法完全不一样,学习成本高。另外,各组件都需要单独搭建性能监控报警体系,后期的升级维护困难,运维压力很大。
经过改造后,整个实时链路都接入到StarRocks,StarRocks称为大数据通用 OLAP 的重要底座。
从数据源头来看,目前有以下源头:离线的Hive 数据,实时的Kafka 数据、Flink-Connector 的数据,MySQL/HDFS 的数据。这些都能通过StarRocks原生的Load方式进行数据导入。
在表的设计方面:
- 大部分表都按照时间字段进行了分区,使用常用的查询列以及关联的关键列作为分桶;
- 对于明细数据,由于数据量比较大,做了数据过期的设置;
- 使用UniqueKey 的replace_if_not_null对部分列进行更新,后续PrimaryKey 将支持部分列更新,我们也将进行更多实验;
-
控制 Routine Load导入频率在 10-15s,降低后台合并的频率。
在运维方面:
- 针对 FE,配置了 VIP 代理,保证查询请求的高可用,同时也保证查询请求负载均衡,不至于单节点承受高频次请求;
- 目前使用的是社区版,我们自己实现了针对 FE、BE、Routine Load 任务的监控告警;
- 用 Grafana 搭建了指标监控大盘
在性能方面:
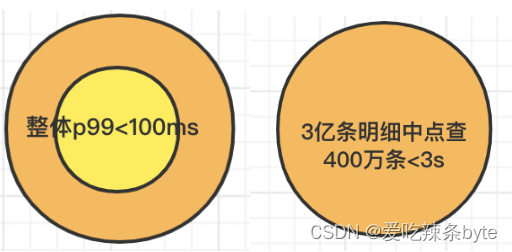
以前我们使用了很多不同类型的查询引擎,不断做加法,大多数时候都要忙于处理各种组件的异常。现在引入 StarRocks 后,不断做减法,最终统一查询引擎、降低维护成本、提高数据取用灵活性。
4.4 StarRocks 与内部平台的融合
StarRocks 现在也作为一个基础数据库,融合在了松果出行的数据分析平台和数据资产平台中。在这些平台中,作为工具的底层基础框架,StarRocks 为业务发挥着重要的支撑作用。
当然,在使用过程中我们也发现了一些小问题:
-
String 类型的数据长度有限制,对于某些长度较大的字段智能过滤或者无法适用;
-
物化视图不能支持复杂条件的聚合计算;
-
动态分区表的分区目前只支持天、周、月,不能支持年的粒度。
五、总结与规划
使用 StarRocks 后,不仅我们前期的业务痛点得到了解决,实时 OLAP 分析的需求也被更好地满足。同时,将多组件收敛到 StarRocks,不仅满足了多样化的业务需求,也极大降低了使用和运维成本。
接下来我们将进一步优化StarRocks的使用性能和使用场景:
- 更多的离线业务从 Hive/Presto 迁移过来,支撑更多的离线业务;
- 进一步收敛 OLAP 引擎,将 ClickHouse 的所有任务迁移到 StarRocks;
- 充分利用 StarRocks 的优越性能进行多业务的多维分析;
- 优化我们的表、任务,充分利用物化视图的能力;
- 完善对 StarRocks 指标的监控;
- 将 StarRocks 嵌入更多的平台工具当中,使建表导数等更加智能化;
- 探索实时标签在 StarRocks 中的运用。
参考文章:
松果出行 x StarRocks:实时数仓新范式的实践之路 - StarRocks的个人空间 - OSCHINA - 中文开源技术交流社区