案例4:脑部MRI图像分割
相关知识点:语义分割、医学图像处理(skimage, medpy)、可视化(matplotlib)
1 任务目标
1.1 任务简介
本次案例将使用深度学习技术来完成脑部MRI(磁共振)图像分割任务,即对于处理好的一张MRI图像,通过神经网络分割出其中病变的区域。本次案例使用的数据集来自Kaggle[1],共包含110位病人的MRI数据,每位病人对应多张通道数为3的.tif格式图像,其对应的分割结果为单通道黑白图像(白色为病变区域),示例如下。

第一行: MRI图像;第二行: 对应的分割标签
更详细的背景介绍请参考文献[2].
1.2 参考程序
本次案例提供了完整、可供运行的参考程序,来源于Kaggle[3]和GitHub[4],建议在参考程序的基础上进行修改来完成本案例。各个程序简介如下:
-
train.ipynb用来完成模型训练 -
inference.ipynb用来对训练后的模型进行推理 -
unet.py定义了U-Net网络结构,参考资料[5] -
loss.py定义了损失函数(Dice Loss),参考资料[6] -
dataset.py用来定义和读取数据集 -
transform.py用来预处理数据 -
utils.py定义了若干辅助函数 -
logger.py用来记录训练过程(使用TensorBoard[7]功能),包括损失函数曲线等参考程序对运行环境的要求如下,请自行调整环境至适配,否则可能无法运行:
torch==2.0.*
torchvision==0.15.*
ipykernel==6.26.*
matplotlib==3.8.*
medpy==0.4.*
scipy==1.11.*
numpy==1.23.* (1.24+版本无法运行,需要先降级)
scikit-image==0.22.*
imageio==2.31.*
tensorboard==2.15.*
tqdm==4.*
其它细节以及示例运行结果可直接参考Kaggle[3]和GitHub[4]。
1.3 要求和建议
在参考程序的基础上,使用深度学习技术,尝试提升该模型在脑部MRI图像上的分割效果,以程序最终输出的validation mean DSC值作为评价标准(参考程序约为90%)。可从网络结构(替换U-Net)、损失函数(替换Dice Loss)、训练过程(如优化器)等角度尝试改进,还可参考通用图像分割的一些技巧[8]。
1.4 注意事项
-
提交所有代码和一份案例报告;
-
案例报告应详细介绍所有改进尝试及对应的结果(包括DSC值和若干分割结果示例),无论是否成功提升模型效果,并对结果作出分析;
-
禁止任何形式的抄袭,借鉴开源程序务必加以说明。
1.5 参考资料
[1] Brain MRI数据集: https://www.kaggle.com/mateuszbuda/lgg-mri-segmentation
[2] Buda et al. Association of genomic subtypes of lower-grade gliomas with shape features automatically extracted by a deep learning algorithm. Computers in Biology and Medicine 2019.
[3] 示例程序: https://www.kaggle.com/mateuszbuda/brain-segmentation-pytorch
[4] 示例程序: https://github.com/mateuszbuda/brain-segmentation-pytorch
[5] Ronneberger et al. U-Net: Convolutional Networks for Biomedical Image Segmentation. MICCAI 2015.
[6] Dice Loss: https://zhuanlan.zhihu.com/p/86704421
[7] TensorBoard参考资料:https://www.tensorflow.org/tensorboard
[8] Minaee et al. Image Segmentation Using Deep Learning: A Survey. arXiv 2020.
2 通过云平台训练基础代码
本次实验由于运行时间较长,占用内存较大,所以选择了用学堂在线的 和鲸云平台 来进行训练。下面介绍是如何使用云平台训练基础代码的。
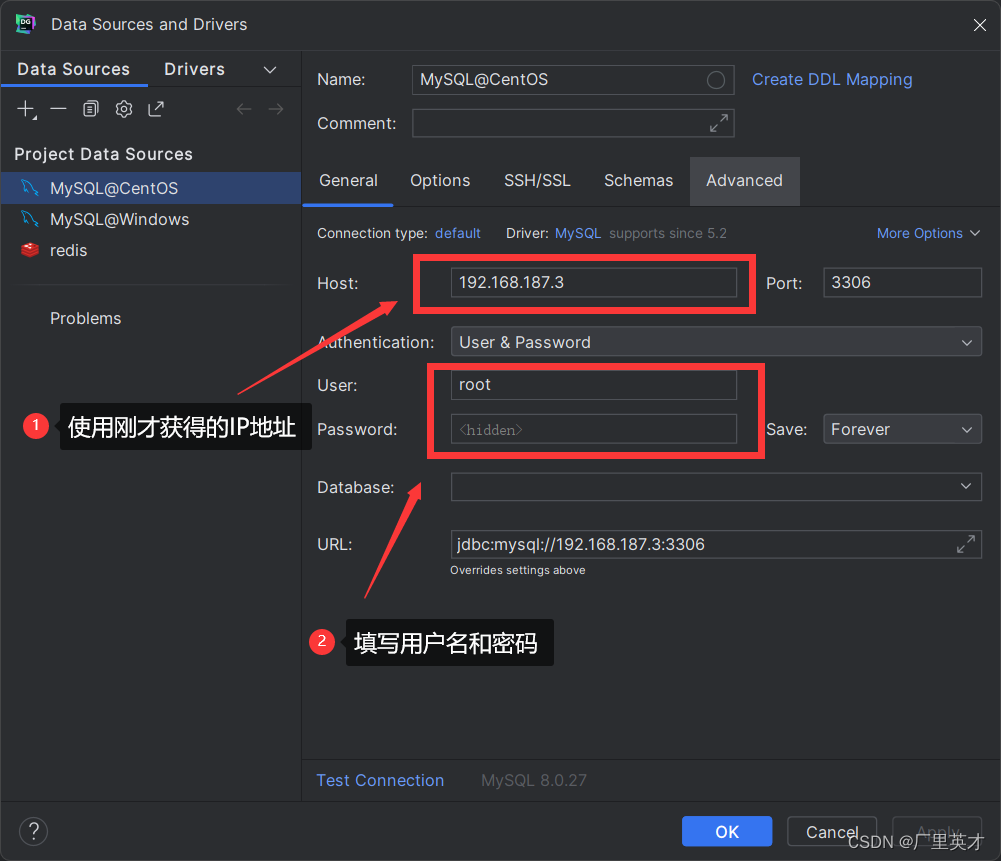
2.1 云平台环境配置
-
数据集接入
本次实验采用Brain MRI数据集,该数据集已被上传到了云平台的共享数据中,可以直接调用。

-
项目创建
此处没有采用直接fork作业中的文件,因为作业中的文件与本地有所不同,经对比,采用从学堂在线下载文件训练效果更好。
在我的空间里,点击新建,创建项目,输入项目名称,选择数据源,完成项目的创建。

-
环境配置
创建完成后,点击右上角齿轮按钮,配置项目环境。

选择
T4 GPU,基础环境选择Pytorch 2.0.1 Cuda11.7 Python3.10的版本。
点击,运行完成基础环境配置。然后导入从学堂在线下载的实验四文件。
按照其中
train.ipynb的内容安装其他依赖库。即在notebook里的代码格输入以下内容,注意前面要加!。!pip install ipykernel==6.26.* matplotlib==3.8.* medpy==0.4.* scipy==1.11.* numpy==1.23.* scikit-image==0.22.* imageio==2.31.* tensorboard==2.15.* tqdm==4.* -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 云平台项目训练
云平台支持在线训练和离线训练两种方式,其中在线训练要求网络保持通畅不能断网,离线训练最好在在线训练跑通后再进行训练。
- 在线训练
首先需要修改数据集地址,不然无法训练。在 train.ipynb 的 args 中,将 images 的路径替换成如下内容。
images = '../input/02039681/utf-8kaggle_3m/kaggle_3m'
默认训练轮次是100轮,实际上训练100轮太多了,20轮足矣。所以我选择将轮次更改成20轮。
epochs = 20,
在配置好后,在 train.ipynb 界面,点击任务栏的 运行所有 键,开始U-net模型的训练。

- 训练过程
训练结束后,会在 project 栏中,生成 log文件夹,存储训练日志,可以用TensorBoard查看训练过程,有loss、val_dsc、val_loss以下三个图表。



可以看到20轮训练,有点欠拟合,不过训练结果还算不错。
- 训练结果
训练结束后,在最后会显示 Best validation mean DSC 值。

可以看到,经过20轮的训练,在测试集得到最好的DSC达到了0.913458。
- 离线训练
离线训练首先需要将配置好的环境,保存成私有镜像。点击任务栏的 镜像 →保存当前环境 等待配置后,保存成功当前环境。

然后点击任务栏中的 离线任务,选择刚才配置好的镜像,即可进行离线训练。
离线训练时,可以从云平台侧边栏的离线任务中,查看离线任务的运行状态,包括内存、CPU占用等。

离线任务运行结束后,若运行的没有问题,则可以保存回原文件,得到在线任务提到的两个文件夹。
2.3 云平台项目测试
在训练结束后,选择 inference.ipynb 文件进行测试,按训练项目中的步骤,替换数据集路径。点击运行所有完成项目的测试。
在测试结束后,可以得到一个 dsc.png 图片记录了不同类别图像的DSC(迪斯相似系数)值。图中的红线为所有DSC值的均值,绿线为DSC值的中值。

Dice Similarity Coefficient (DSC) 是通过比较模型预测的分割结果与地面真实分割的重叠部分来衡量相似度的指标。它的计算公式如下:
D S C = 2 × ∣ Intersection ∣ ∣ Prediction ∣ + ∣ Ground Truth ∣ DSC = \frac{2 \times | \text{Intersection} |}{ | \text{Prediction} | + | \text{Ground Truth} |} DSC=∣Prediction∣+∣Ground Truth∣2×∣Intersection∣其中:
- $ \text{Intersection} $ 表示模型预测和背景真实分割的交集部分。
- $ | \text{Prediction} | $ 表示模型预测的分割的总像素数。
- $ | \text{Ground Truth} | $ 表示背景真实分割的总像素数。
并得到一个 predictions 文件夹,存储预测的一系列脑部MRI图像,其中红色为预测框,绿色为真实框。

云平台图片不能批量下载,只能一张一张下载查看图片,结果并不直观。
3 本地训练基础代码
由于云平台编辑代码不方便,图片需要下载才能查看等弊端,于是我又选择在本地训练。
3.1 本地环境配置
根据 train.ipynb 的步骤安装环境。
-
新建python 3.10环境
conda create -n hw4 python=3.10 -y conda activate hw4 -
安装torch,注意cuda版本适配
pip install torch==2.0.* torchvision==0.15.* --index-url https://download.pytorch.org/whl/cu117 -
安装其他依赖库
pip install ipykernel==6.26.* matplotlib==3.8.* medpy==0.4.* scipy==1.11.* numpy==1.23.* scikit-image==0.22.* imageio==2.31.* tensorboard==2.15.* tqdm==4.* -i https://pypi.tuna.tsinghua.edu.cn/simple
3.2 本地项目训练
-
修改数据集路径
将
images数据集路径修改为你的路径。images = './archive/kaggle_3m', -
项目训练
全部运行
train.ipynb,本次训练,训练100个epoch,最优结果如下。100%|██████████| 208/208 [01:19<00:00, 2.62it/s] 100%|██████████| 21/21 [00:07<00:00, 2.78it/s] epoch 100 | val_loss: 0.21832050595964705 epoch 100 | val_dsc: 0.9073074088508986 Best validation mean DSC: 0.914025在100轮的训练后,最佳DSC值为0.914025。
-
训练结果
模型训练结束得到训练日志,通过Tensorboard打开,得到结果如下。



由上图可知,100轮训练后,训练集和测试集的loss逐步降低,测试集精度逐步上升,训练结果还算不错。
3.3 本地项目测试
-
项目测试
修改好数据集路径后,全部运行
inference.ipynb。... 70%|███████ | 7/10 [00:05<00:02, 1.07it/s]C:\Users\Administrator\AppData\Local\Temp\ipykernel_15188\1157483797.py:12: UserWarning: ./predictions\kaggle_3m\TCGA_DU_5851_19950428-34.png is a low contrast image imsave(filepath, image) 100%|██████████| 10/10 [00:06<00:00, 1.52it/s] -
DSC测试
在测试结束后,会生成一张DSC图片。

由上图可知,除了
TCGA_HT_717文件,其他的测试DSC值都达到了0.9及以上,测试结果还算不错。 -
预测图片
本地运行后,可以得到一个
predictions文件夹,存储所有预测图片。可以通过以下代码,将同一系列的图片转换为gif图片,可以更直观的查看测试效果。
from PIL import Image import os def create_gif(image_folder, output_gif_path, prefix): images = [] # 获取文件夹中所有以 prefix 开头的图片文件 image_files = [file for file in os.listdir(image_folder) if file.startswith(prefix)] image_files.sort() # 按名称排序 for image_file in image_files: image_path = os.path.join(image_folder, image_file) img = Image.open(image_path) images.append(img) # 保存为 GIF 图片 images[0].save(output_gif_path+image_prefix+".gif", save_all=True, append_images=images[1:], duration=100, loop=0)通过代码,可以得到以下GIF图片。
-
TCGA_DU_6404
通过DSC测试可知,该样本脑部MRI图像测试结果最好,如下图所示,绿色与红色框几乎重合。

-
TCGA_CS_4944
通过DSC测试可知,该样本脑部MRI图像测试结果较为不错,如下图所示,绿色与红色框差异不大。

-
TCGA_HT_7616
通过DSC测试可知,该样本脑部MRI图像测试结果最差,如下图所示,绿色与红色框差异较大。

-
4 代码解析
本次实验采用U-Net架构,实现对脑部MRI图像的图像分割。
4.1 U-Net架构
U-Net 是一种用于图像分割的卷积神经网络,它由编码器和解码器两部分组成,形状类似字母 U,因此得名。

U-Net 的主要特点包括:
- 编码器-解码器结构:U-Net 由两部分组成,一个收缩路径(编码器)和一个对称的扩展路径(解码器)。编码器通过卷积和池化操作逐步减小特征图的尺寸,同时捕获图像的上下文信息。解码器通过上采样和卷积操作逐步恢复特征图的尺寸,同时保留和增强重要的空间信息。
- 跳跃连接:在编码器和解码器之间,U-Net 使用了跳跃连接(也称为长距离连接或残差连接),将编码阶段的特征图与解码阶段的对应特征图进行拼接。这种连接有助于解码器恢复更多的空间细节,从而提高分割精度。
- 上采样:在解码阶段,U-Net 使用了上采样操作(如转置卷积或上采样层)来逐步增大特征图的尺寸。这有助于恢复原始图像的分辨率,使得网络能够输出与输入图像尺寸相同的分割图。
- 多尺度特征融合:由于跳跃连接和编码器-解码器结构的结合,U-Net 能够有效地融合多尺度的特征信息。这对于处理具有不同尺寸和形状的目标非常重要。
- 轻量级和高效:尽管 U-Net 结构相对简单,但它在许多图像分割任务中表现出了出色的性能。此外,由于其轻量级的特性,U-Net 可以在有限的计算资源上实现高效的训练和推理。
4.2 U-Net代码解析
代码定义了一个UNet类,具体内容如下。
-
构造函数(
__init__)接受三个参数:in_channels:输入通道的数量(默认为3,适用于RGB图像)。out_channels:输出通道的数量(默认为1,用于二元分割)。init_features:初始特征的数量(默认为32)。
def __init__(self, in_channels=3, out_channels=1, init_features=32): super(UNet, self).__init__() -
编码器架构
- U-Net的编码器部分由四个块(
enc1到enc4)组成,每个块包含两个卷积层、批归一化和ReLU激活。 - 在每个编码器块后,应用最大池化层(
pool1到pool4)以减小空间维度。
features = init_features self.encoder1 = UNet._block(in_channels, features, name="enc1") self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) self.encoder2 = UNet._block(features, features * 2, name="enc2") self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) self.encoder3 = UNet._block(features * 2, features * 4, name="enc3") self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2) self.encoder4 = UNet._block(features * 4, features * 8, name="enc4") self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2) - U-Net的编码器部分由四个块(
-
中间层
瓶颈块(
bottleneck)是另一组包含两个卷积层、批归一化和ReLU激活的层,表示U-Net的中央层。self.bottleneck = UNet._block(features * 8, features * 16, name="bottleneck") -
解码器结构
- 解码器部分包含四个块(
dec4到dec1),每个块包含两个卷积层、批归一化和ReLU激活。 - 在每个解码器块后,应用转置卷积(
upconv4到upconv1)以上采样特征图。
self.upconv4 = nn.ConvTranspose2d( features * 16, features * 8, kernel_size=2, stride=2 ) self.decoder4 = UNet._block((features * 8) * 2, features * 8, name="dec4") self.upconv3 = nn.ConvTranspose2d( features * 8, features * 4, kernel_size=2, stride=2 ) self.decoder3 = UNet._block((features * 4) * 2, features * 4, name="dec3") self.upconv2 = nn.ConvTranspose2d( features * 4, features * 2, kernel_size=2, stride=2 ) self.decoder2 = UNet._block((features * 2) * 2, features * 2, name="dec2") self.upconv1 = nn.ConvTranspose2d( features * 2, features, kernel_size=2, stride=2 ) self.decoder1 = UNet._block(features * 2, features, name="dec1") - 解码器部分包含四个块(
-
前向传播
-
输入
x通过编码器块和池化层。def forward(self, x): enc1 = self.encoder1(x) enc2 = self.encoder2(self.pool1(enc1)) enc3 = self.encoder3(self.pool2(enc2)) enc4 = self.encoder4(self.pool3(enc3)) -
瓶颈应用于下采样的特征图。
bottleneck = self.bottleneck(self.pool4(enc4)) -
解码器块和转置卷积用于通过跳跃连接 (
torch.cat) 上采样特征。dec4 = self.upconv4(bottleneck) dec4 = torch.cat((dec4, enc4), dim=1) dec4 = self.decoder4(dec4) dec3 = self.upconv3(dec4) dec3 = torch.cat((dec3, enc3), dim=1) dec3 = self.decoder3(dec3) dec2 = self.upconv2(dec3) dec2 = torch.cat((dec2, enc2), dim=1) dec2 = self.decoder2(dec2) dec1 = self.upconv1(dec2) dec1 = torch.cat((dec1, enc1), dim=1) dec1 = self.decoder1(dec1) -
最后一层应用Sigmoid激活进行二元分割。
return torch.sigmoid(self.conv(dec1))
-
-
辅助方法
_block- 定义了一个静态方法
_block,用于创建包含两个卷积层、批归一化和ReLU激活的基本块。 - 该块被返回为
nn.Sequential模块。
@staticmethod def _block(in_channels, features, name): return nn.Sequential( OrderedDict( [ ( name + "conv1", nn.Conv2d( in_channels=in_channels, out_channels=features, kernel_size=3, padding=1, bias=False, ), ), (name + "norm1", nn.BatchNorm2d(num_features=features)), (name + "relu1", nn.ReLU(inplace=True)), ( name + "conv2", nn.Conv2d( in_channels=features, out_channels=features, kernel_size=3, padding=1, bias=False, ), ), (name + "norm2", nn.BatchNorm2d(num_features=features)), (name + "relu2", nn.ReLU(inplace=True)), ] ) ) - 定义了一个静态方法
4.3 训练函数代码
-
训练超参数
args = SimpleNamespace( device = 'cuda:0', batch_size = 16, epochs = 100, lr = 0.0001, workers = 0, vis_images = 200, vis_freq = 10, weights = './weights', logs = './logs', images = './archive/kaggle_3m', image_size = 256, aug_scale = 0.05, aug_angle = 15, )device: 指定模型训练的设备,这里设置为cuda:0,表示使用第一个 GPU。如果没有可用的 GPU,可以将其设置为cpu。batch_size: 每个训练批次中包含的样本数量,这里设置为 16。epochs: 训练的总轮数,这里设置为 100。lr: 学习率,即模型在每个训练步骤中权重更新的大小,这里设置为 0.0001。workers: 数据加载时的并行工作数,这里设置为 0,表示不使用多线程加载数据。vis_images: 每次可视化的图像数量,这里设置为 200。vis_freq: 可视化的频率,即每训练多少个批次可视化一次,这里设置为 10。weights: 模型权重的保存路径,这里设置为./weights。logs: 训练日志的保存路径,这里设置为./logs。images: 存储图像数据的路径,这里设置为./archive/kaggle_3m。image_size: 输入图像的大小,这里设置为 256。aug_scale: 数据增强的缩放参数,这里设置为 0.05。aug_angle: 数据增强的旋转角度参数,这里设置为 15。
-
读取数据
-
worker_init函数:这是一个用于多线程数据加载的初始化函数,确保每个线程有相同的随机种子。这里使用
np.random.seed来设置随机种子。# 读取数据 def worker_init(worker_id): np.random.seed(42 + worker_id) -
data_loaders函数:该函数用于创建训练和验证数据加载器,并返回训练和验证数据集的对象。
dataset_train, dataset_valid = datasets(args)调用datasets函数获取训练和验证数据集。- 然后使用
DataLoader创建两个数据加载器loader_train和loader_valid,分别用于训练和验证。这些加载器将数据集划分为批次,可以在模型训练时使用。 worker_init_fn=worker_init用于设置每个数据加载线程的随机种子。
def data_loaders(args): dataset_train, dataset_valid = datasets(args) loader_train = DataLoader( dataset_train, batch_size=args.batch_size, shuffle=True, drop_last=True, num_workers=args.workers, worker_init_fn=worker_init, ) loader_valid = DataLoader( dataset_valid, batch_size=args.batch_size, drop_last=False, num_workers=args.workers, worker_init_fn=worker_init, ) return dataset_train, dataset_valid, loader_train, loader_valid
-
-
数据集定义
-
datasets函数:-
该函数用于定义训练和验证数据集,并返回它们的对象。
-
调用
Dataset类来创建训练和验证数据集,传递了一些参数如images_dir、subset、image_size、transform等。
# 数据集定义 def datasets(args): train = Dataset( images_dir=args.images, subset="train", image_size=args.image_size, transform=transforms(scale=args.aug_scale, angle=args.aug_angle, flip_prob=0.5), ) valid = Dataset( images_dir=args.images, subset="validation", image_size=args.image_size, random_sampling=False, ) return train, valid -
-
-
数据处理
-
dsc_per_volume函数:- 这是一个用于计算 Dice Similarity Coefficient(DSC)的函数,其中
validation_pred是预测的分割结果,validation_true是真实的分割结果,patient_slice_index是患者每个切片的索引。 - 该函数对每个样本计算 DSC,并将结果存储在
dsc_list中返回。
def dsc_per_volume(validation_pred, validation_true, patient_slice_index): dsc_list = [] num_slices = np.bincount([p[0] for p in patient_slice_index]) index = 0 for p in range(len(num_slices)): y_pred = np.array(validation_pred[index : index + num_slices[p]]) y_true = np.array(validation_true[index : index + num_slices[p]]) dsc_list.append(dsc(y_pred, y_true)) index += num_slices[p] return dsc_list - 这是一个用于计算 Dice Similarity Coefficient(DSC)的函数,其中
-
log_loss_summary函数:- 该函数用于记录损失值到日志中,通常用于可视化和监控训练过程。这里使用了
logger.scalar_summary函数来记录损失值。
def log_loss_summary(logger, loss, step, prefix=""): logger.scalar_summary(prefix + "loss", np.mean(loss), step) - 该函数用于记录损失值到日志中,通常用于可视化和监控训练过程。这里使用了
-
makedirs函数:- 用于创建存储模型权重和日志的目录。调用
os.makedirs函数来创建目录,如果目录已存在则不会报错。
def makedirs(args): os.makedirs(args.weights, exist_ok=True) os.makedirs(args.logs, exist_ok=True) - 用于创建存储模型权重和日志的目录。调用
-
snapshotargs函数:- 该函数用于保存实验参数到一个 JSON 文件中,这样可以在后续的实验中追溯实验的设置。调用
json.dump将参数写入 JSON 文件。
def snapshotargs(args): args_file = os.path.join(args.logs, "args.json") with open(args_file, "w") as fp: json.dump(vars(args), fp) - 该函数用于保存实验参数到一个 JSON 文件中,这样可以在后续的实验中追溯实验的设置。调用
-
-
加载数据集
根据上面的函数,建立数据集,与训练日志,加载数据集并对数据集内容进行预处理。
makedirs(args) snapshotargs(args) device = torch.device("cpu" if not torch.cuda.is_available() else args.device) dataset_train, dataset_valid, loader_train, loader_valid = data_loaders(args) loaders = {"train": loader_train, "valid": loader_valid} -
初始化Unet模型
-
UNet模型初始化
unet = UNet(in_channels=Dataset.in_channels, out_channels=Dataset.out_channels) unet.to(device) -
Dice Loss初始化
创建了一个Dice Loss的实例
dsc_loss,用于度量分割模型的性能。dsc_loss = DiceLoss() best_validation_dsc = 0.0 -
定义优化器
创建了一个Adam优化器,用于更新UNet模型的参数。
optimizer = optim.Adam(unet.parameters(), lr=args.lr) -
日志记录器初始化
创建了一个日志记录器
logger,用于记录训练过程中的信息,如训练和验证损失。logger = Logger(args.logs) -
训练参数初始化
初始化训练和验证损失列表,创建了两个空列表
loss_train和loss_valid,用于存储每个训练和验证步骤的损失值。初始化训练步数,用于跟踪训练过程中的步数。
loss_train = [] loss_valid = [] step = 0
-
-
模型训练
-
循环训练
两个嵌套的循环,外层循环迭代训练的轮数,内层循环迭代训练和验证阶段。
for epoch in range(args.epochs): for phase in ["train", "valid"]: # ... -
模型模式设置
根据当前阶段(训练或验证)设置模型的模式,对于训练模式,启用 Batch Normalization 和 Dropout 等层的训练行为;对于验证模式,关闭这些层的训练行为以避免随机性。
if phase == "train": unet.train() else: unet.eval() -
损失和优化器初始化
初始化 Adam 优化器和 Dice Loss 损失函数。
optimizer = optim.Adam(unet.parameters(), lr=args.lr) dsc_loss = DiceLoss() best_validation_dsc = 0.0 -
数据加载和处理
通过
loaders加载训练或验证数据,并将数据移动到指定的计算设备。for i, data in enumerate(tqdm.tqdm(loaders[phase])): x, y_true = data x, y_true = x.to(device), y_true.to(device) -
模型前向传播和损失计算
使用 UNet 模型进行前向传播,计算预测结果
y_pred并计算 Dice Loss。y_pred = unet(x) loss = dsc_loss(y_pred, y_true) -
反向传播和优化
如果是训练阶段,则执行反向传播和参数优化更新。
if phase == "train": loss_train.append(loss.item()) loss.backward() optimizer.step() -
验证阶段损失和性能评估
在验证阶段,记录验证集的损失,计算 Dice 相似性系数,并保存模型权重如果当前性能更好。
if phase == "valid": loss_valid.append(loss.item()) # ... -
可视化和日志记录
if (epoch % args.vis_freq == 0) or (epoch == args.epochs - 1): # ... -
性能指标记录和保存最佳模型
如果当前验证性能更好,则保存当前的 UNet++ 模型权重。
if mean_dsc > best_validation_dsc: best_validation_dsc = mean_dsc torch.save(unet.state_dict(), os.path.join(args.weights, "unet.pt")) -
最终输出
在训练完成后,输出最佳验证集 Dice 相似性系数。
print("Best validation mean DSC: {:4f}".format(best_validation_dsc))
-
5 代码优化
5.1 优化loss
我分别采用 SoftIoULoss 和 Calc Loss 来替代 Dice Loss,结果如下。
-
SoftIoULoss
SoftIoULoss 是一种用于语义分割任务的损失函数,它是在 IoU(Intersection over Union) 的基础上进行了平滑处理,以便更好地优化训练过程。IoU是一种常用的指标,用于衡量预测结果和真实标签之间的相似度。
SoftIoULoss = 1 − ∑ i = 1 N pred i target i + ϵ ∑ i = 1 N pred i + ∑ i = 1 N target i − ∑ i = 1 N pred i target i + ϵ \text{SoftIoULoss} = 1 - \frac{\sum_{i=1}^N \text{pred}_i \text{target}_i + \epsilon}{\sum_{i=1}^N \text{pred}_i + \sum_{i=1}^N \text{target}_i - \sum_{i=1}^N \text{pred}_i \text{target}_i + \epsilon} SoftIoULoss=1−∑i=1Npredi+∑i=1Ntargeti−∑i=1Npreditargeti+ϵ∑i=1Npreditargeti+ϵ
其中, N N N 是像素的总数, pred i \text{pred}_i predi和 target i \text{target}_i targeti分别是第 i i i个像素的预测值和真实值, ϵ \epsilon ϵ是一个很小的正数,用于避免除零错误。下面是SoftIoULoss的代码实现
def SoftIoULoss(pred, target, epsilon=1e-6): # 将预测值缩放到0到1之间 pred = torch.sigmoid(pred) # 设置一个平滑因子,避免除零错误 smooth = epsilon # 计算预测值和真实值之间的交集 intersection = pred * target # 计算预测值和真实值之间的并集 union = pred + target - intersection # 计算IoU iou = (intersection.sum() + smooth) / (union.sum() + smooth) # 计算SoftIoULoss loss = 1 - iou.mean() return loss采用 SoftIoULoss 作为损失函数,最终训练结果如下,DSC值有所下降,说明该损失函数表现不如Dice Loss。
Best validation mean DSC: 0.874558各样本测试得到的DSC图如下所示。

与基于Dice Loss训练集上的Loss曲线,验证集上的DSC、Loss曲线对比,结果如下所示。



由图可知,基于 SoftIoULoss 训练的Unet模型,训练集和测试集的loss基本没有降低,测试集的DSC曲线始终在基于 Dice Loss 训练的下方。说明该任务不适合使用 SoftIoULoss 进行训练。
-
calc loss
calc loss 是一种用于计算图像分割任务的损失函数,它结合了 二元交叉熵损失(BCE Loss) 和 Dice损失(Dice Loss) 。BCE Loss用于衡量预测值和真实值之间的逐像素的差异,Dice Loss用于衡量预测值和真实值之间的重叠区域的比例。bce_weight是一个超参数,用于控制两种损失的权重。
calc loss可以同时考虑像素级别和区域级别的分割性能,提高分割的准确性和鲁棒性。
其计算公式如下:
calc loss = BCE Loss ∗ bce weight + Dice Loss ∗ ( 1 − bce weight ) \text{calc loss} = \text{BCE Loss} * \text{bce weight} + \text{Dice Loss} * (1 - \text{bce weight}) calc loss=BCE Loss∗bce weight+Dice Loss∗(1−bce weight)
其中,BCE Loss和Dice Loss的计算公式分别为:
$$
\text{BCE Loss} = -\frac {1} {N} \sum_ {i=1}^ {N} \left [y_ {i} \log p_ {i} + (1 - y_ {i}) \log (1 - p_ {i})\right]\
\text{Dice Loss} = 1 - \frac {2 \sum_ {i=1}^ {N} y_ {i} p_ {i} + \epsilon} {\sum_ {i=1}^ {N} y_ {i} + \sum_ {i=1}^ {N} p_ {i} + \epsilon}
$$
其中,
N
N
N是像素的总数,
y
i
y_ {i}
yi和
p
i
p_ {i}
pi分别是第
i
i
i个像素的真实值和预测值,
ϵ
\epsilon
ϵ是一个很小的正数,用于避免除零错误。
下面是calc loss的代码实现:
def calc_loss(prediction, target, bce_weight=0.5):
# 计算BCE Loss,使用logits作为输入,避免重复计算sigmoid
bce = F.binary_cross_entropy_with_logits(prediction, target)
# 计算sigmoid,将logits转换为概率
prediction = F.sigmoid(prediction)
# 计算Dice Loss,使用自定义的dice_loss函数
dice = dice_loss(prediction, target)
# 计算总的损失,根据bce_weight的值进行加权
loss = bce * bce_weight + dice * (1 - bce_weight)
return loss
采用 calc loss 作为损失函数,最终训练结果如下,DSC值有细微提升,说明该损失函数表现比 Dice Loss略有提升。
Best validation mean DSC: 0.915542
各样本测试得到的DSC图如下所示。

与基于Dice Loss训练集上的Loss曲线,验证集上的DSC、Loss曲线对比,结果如下所示。



由图可知,基于 Calc Loss 的loss曲线,在训练集和测试集上,都收敛在了一个较大的值,但是从测试集上DSC曲线来看,模型效果与 Dice Loss 不相上下。
5.2 添加注意力机制(Attention)
我在Unet的每个解码器模块,添加了注意力模块,基于注意力机制的 U-Net 网络旨在通过 Attention Gate 帮助模型更有效地聚焦于图像中的重要区域,提高图像分割的性能。
-
基于注意力机制的Unet网络
基于注意力机制的Unet网络是一种用于图像分割的深度学习模型,它在经典的Unet网络的基础上增加了注意力门(Attention Gate)模块,用于自动学习在不同尺度上关注哪些特征。

注意力门模块的作用是根据输入的两个特征图,生成一个注意力权重图,用于对其中一个特征图进行加权,从而突出目标区域,抑制背景区域。注意力门模块可以嵌入到Unet网络的上采样路径中,与下采样路径中的特征图进行融合,提高分割的精度和鲁棒性。
-
代码设计
以下是AttentionGate类的代码,它包含一个卷积层和 Sigmoid 激活函数。
- 通过对两个输入张量执行卷积,然后使用双线性插值将结果上采样到与第二个输入张量相同的大小,最后通过 Sigmoid 激活函数产生一个介于 0 到 1 之间的权重。
- 通过将这个权重应用于第二个输入张量,产生了加强的特征图,这有助于模型更好地关注感兴趣的区域。
class AttentionGate(nn.Module): def __init__(self, in_channels, out_channels): super(AttentionGate, self).__init__() self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0) self.sigmoid = nn.Sigmoid() def forward(self, x1, x2): g = self.conv(x1) g = F.interpolate(g, size=x2.size()[2:], mode='bilinear', align_corners=False) x = x2 * self.sigmoid(g) return x以下是解码器模块代码,在每个解码器块中,通过使用 AttentionGate 增强的特征图与对应的编码器块的特征图进行连接。这种连接方式旨在使解码器能够更好地利用编码器中学到的信息。
def __init__(self, in_channels=3, out_channels=1, init_features=32): ... # Attention Gates self.attention_gate1 = AttentionGate(features, features) self.attention_gate2 = AttentionGate(features * 2, features * 2) self.attention_gate3 = AttentionGate(features * 4, features * 4) self.attention_gate4 = AttentionGate(features * 8, features * 8) ... def forward(self, x): ... # Attention gates dec4 = self.upconv4(bottleneck) dec4 = self.attention_gate4(enc4, dec4) dec4 = torch.cat((dec4, enc4), dim=1) dec4 = self.decoder4(dec4) ... dec1 = self.upconv1(dec2) dec1 = self.attention_gate1(enc1, dec1) dec1 = torch.cat((dec1, enc1), dim=1) dec1 = self.decoder1(dec1) ... -
性能分析
训练结束后,基于Attention的Unet网络得到的Best mean DSC值如下,比Unet网络较好。
Best validation mean DSC: 0.914510各样本测试得到的DSC图如下所示。

与Unet网络在训练集上的Loss曲线,验证集上的DSC、Loss曲线对比,结果如下所示。



由上图可知,添加注意力机制后的模型,收敛速度更快,在收敛后,测试集测试DSC值更稳定,效果更好。
5.3 ResUnet
我创建了一个基于 ResNet34 架构的 U-Net 模型,采用了预训练的ResNet34模型作为编码器,结合了 ResNet34 的强大特征提取能力和 U-Net 结构的特征融合机制,通过上采样和特征图融合操作进行细化,用于图像分割任务。
-
ResNet34
ResNet34 包含34层卷积层和全连接层,相对于传统的网络结构,其深度相对较大,属于残差网络(Residual Network,简称 ResNet)系列之一。通过引入残差块(Residual Blocks)的概念,成功地解决了深层神经网络训练过程中的梯度消失和梯度爆炸问题,使得训练非常深的网络变得可行。
-
代码设计
-
编码器架构
使用预训练的 ResNet34 模型,将其前卷积层(
conv1)、批归一化层(bn1)、ReLU 激活层(relu)、最大池化层(maxpool)以及四个残差块(layer1到layer4)作为编码器部分。Encoder 的输出是具有不同尺寸的特征图,其中
e1是第一个残差块的输出,e2是第二个残差块的输出,以此类推。filters = [64, 128, 256, 512] resnet = models.resnet34(pretrained=pretrained) self.firstconv = resnet.conv1 self.firstbn = resnet.bn1 self.firstrelu = resnet.relu self.firstmaxpool = resnet.maxpool self.encoder1 = resnet.layer1 self.encoder2 = resnet.layer2 self.encoder3 = resnet.layer3 self.encoder4 = resnet.layer4 -
解码器架构
使用自定义的
DecoderBlock类来构建解码器部分。每个解码器块都包括上采样操作和特征图融合操作,其中上采样使用nn.ConvTranspose2d实现。将解码器块按照从深层到浅层的顺序进行连接,最终得到
d4,d3,d2和d1,分别对应不同层次的解码器块的输出。self.decoder4 = DecoderBlock(512, filters[2]) self.decoder3 = DecoderBlock(filters[2], filters[1]) self.decoder2 = DecoderBlock(filters[1], filters[0]) self.decoder1 = DecoderBlock(filters[0], filters[0])
-
-
性能分析
训练结束后基于ResNet34的Unet网络得到的Best mean DSC值如下,与Unet网络相近。
Best validation mean DSC: 0.911739各样本测试得到的DSC图如下所示。

与Unet网络在训练集上的Loss曲线,验证集上的DSC、Loss曲线对比,结果如下所示。



由上图可以看出,基于ResNet34的UNet网络的收敛速度非常快,在训练集和测试集的loss都比UNet网络的要低,且测试集上该网络的DSC值也收敛更快,更平稳,但峰值与Unet相似。
5.3 Unet++
最后,我尝试了采用结构比较复杂的Unet++进行训练。
-
Unet++
Unet++(Neted Unet)是对传统U-Net架构的扩展和改进,旨在提高分割任务的性能。UNet++ 在U-Net的基础上引入了密集和多尺度的连接,以便更好地融合不同层次的特征。这包括从浅层到深层的连接,以及在同一层级上的多个分支。

UNet++ 的核心思想是将多个U-Net结构嵌套在一起,形成一个金字塔状的结构。每个U-Net结构被视为一个“子网”,并且每个子网都有自己的编码器和解码器,它们通过特征金字塔连接进行信息交换。
在UNet++中,通过每个子网的解码器部分将来自其他子网的信息集成到当前子网中。这种集成机制有助于更好地利用不同层次和尺度的信息,提高模型的表达能力。
-
代码设计
-
初始化函数
__init__函数定义了 UNet_Nested 类的初始化,包括输入通道数(in_channels)、输出类别数(n_classes)、特征缩放比例(feature_scale)、是否使用反卷积(is_deconv)、是否使用批归一化(is_batchnorm)以及是否使用密集连接(is_ds)等参数。class UNet_Nested(nn.Module): def __init__(self, in_channels=1, n_classes=2, feature_scale=2, is_deconv=True, is_batchnorm=True, is_ds=True): super(UNet_Nested, self).__init__() self.in_channels = in_channels self.feature_scale = feature_scale self.is_deconv = is_deconv self.is_batchnorm = is_batchnorm self.is_ds = is_ds -
特征缩放和网络结构定义
在初始化函数中,首先根据特征缩放比例计算每个层级的特征通道数。
filters = [64, 128, 256, 512, 1024] filters = [int(x / self.feature_scale) for x in filters]然后定义下采样操作。
# downsampling self.maxpool = nn.MaxPool2d(kernel_size=2) self.conv00 = unetConv2(self.in_channels, filters[0], self.is_batchnorm) self.conv10 = unetConv2(filters[0], filters[1], self.is_batchnorm) self.conv20 = unetConv2(filters[1], filters[2], self.is_batchnorm) self.conv30 = unetConv2(filters[2], filters[3], self.is_batchnorm) self.conv40 = unetConv2(filters[3], filters[4], self.is_batchnorm)定义上采样操作。
# upsampling self.up_concat01 = unetUp(filters[1], filters[0], self.is_deconv) self.up_concat11 = unetUp(filters[2], filters[1], self.is_deconv) self.up_concat21 = unetUp(filters[3], filters[2], self.is_deconv) self.up_concat31 = unetUp(filters[4], filters[3], self.is_deconv) self.up_concat02 = unetUp(filters[1], filters[0], self.is_deconv, 3) self.up_concat12 = unetUp(filters[2], filters[1], self.is_deconv, 3) self.up_concat22 = unetUp(filters[3], filters[2], self.is_deconv, 3) self.up_concat03 = unetUp(filters[1], filters[0], self.is_deconv, 4) self.up_concat13 = unetUp(filters[2], filters[1], self.is_deconv, 4) self.up_concat04 = unetUp(filters[1], filters[0], self.is_deconv, 5) -
前向传播函数:
forward函数定义了整个网络的前向传播过程。在前向传播中,通过一系列的卷积和上采样操作,将输入的特征图经过多个列的特征提取和上采样连接,最终得到分割的结果。每个列内的特征上采样与相邻列的特征进行连接,实现了多层次的特征融合,有助于提高网络对不同尺度和层级的信息的捕获能力。
def forward(self, inputs): # column : 0 X_00 = self.conv00(inputs) # 16*512*512 maxpool0 = self.maxpool(X_00) # 16*256*256 X_10= self.conv10(maxpool0) # 32*256*256 maxpool1 = self.maxpool(X_10) # 32*128*128 X_20 = self.conv20(maxpool1) # 64*128*128 maxpool2 = self.maxpool(X_20) # 64*64*64 X_30 = self.conv30(maxpool2) # 128*64*64 maxpool3 = self.maxpool(X_30) # 128*32*32 X_40 = self.conv40(maxpool3) # 256*32*32 # column : 1 X_01 = self.up_concat01(X_10,X_00) X_11 = self.up_concat11(X_20,X_10) X_21 = self.up_concat21(X_30,X_20) X_31 = self.up_concat31(X_40,X_30) # column : 2 X_02 = self.up_concat02(X_11,X_00,X_01) X_12 = self.up_concat12(X_21,X_10,X_11) X_22 = self.up_concat22(X_31,X_20,X_21) # column : 3 X_03 = self.up_concat03(X_12,X_00,X_01,X_02) X_13 = self.up_concat13(X_22,X_10,X_11,X_12) # column : 4 X_04 = self.up_concat04(X_13,X_00,X_01,X_02,X_03) -
最终输出:
最终输出通过四个独立的卷积层(
final_1到final_4)进行,然后这些输出通过相加平均得到final,作为最终的分割结果。# final layer final_1 = self.final_1(X_01) final_2 = self.final_2(X_02) final_3 = self.final_3(X_03) final_4 = self.final_4(X_04) final = (final_1+final_2+final_3+final_4)/4 -
密集连接:
is_ds参数控制是否使用密集连接(Dense Connection),即每个上采样层都使用前面所有层的特征图。if self.is_ds: return final else: return final_4
-
-
性能分析
Unet++网络训练处来效果很差,训练100epoch,得到最佳的DSC值只有0.024。
Best validation mean DSC: 0.024353各样本测试得到的DSC图如下所示。

可以看出每个类别训练出的效果都非常差,查看具体预测出的图像,发现学习出来预测的图片却只在病灶区域边缘圈出了几个点,而不是圈出了整个区域。

-
CS_4944样本预测图像

-
HT_7692样本预测图像。

与Unet网络在训练集上的Loss曲线,验证集上的DSC、Loss曲线对比,结果如下所示。



可以看出,Unet++的Loss值在训练集和测试集上都比UNet的低很多,但是训练未能使得其在测试集的DSC表现有任何变好。通过询问助教得知,这样的结果可能是因为模型参数过多,训练时并没有把所有参数都学习收敛,因此模型性能就会比较差。
-
6 总结
对比所有模型结果的训练、测试的loss曲线与测试集上的DSC曲线,结果如下。



实验可知,通过添加注意力机制、采用CalcLoss,可以提高提取特征能力。采用ResNet34预训练模型,可以加快训练收敛速度。SoftIoULoss不适合该项目的训练,而UNet++因为模型过于复杂,也不适合该项目的训练。
参考
研习U-Net - 知乎 (zhihu.com)
Unet-Segmentation-Pytorch-Nest-of-Unets/Models.py at master · bigmb/Unet-Segmentation-Pytorch-Nest-of-Unets (github.com)
ShawnBIT/UNet-family: Paper and implementation of UNet-related model. (github.com)
Andy-zhujunwen/UNET-ZOO: including unet,unet++,attention-unet,r2unet,cenet,segnet ,fcn. (github.com)