官方网址
源码:https://kafka.apache.org/downloads
快速开始:https://kafka.apache.org/documentation/#gettingStarted
springcloud整合
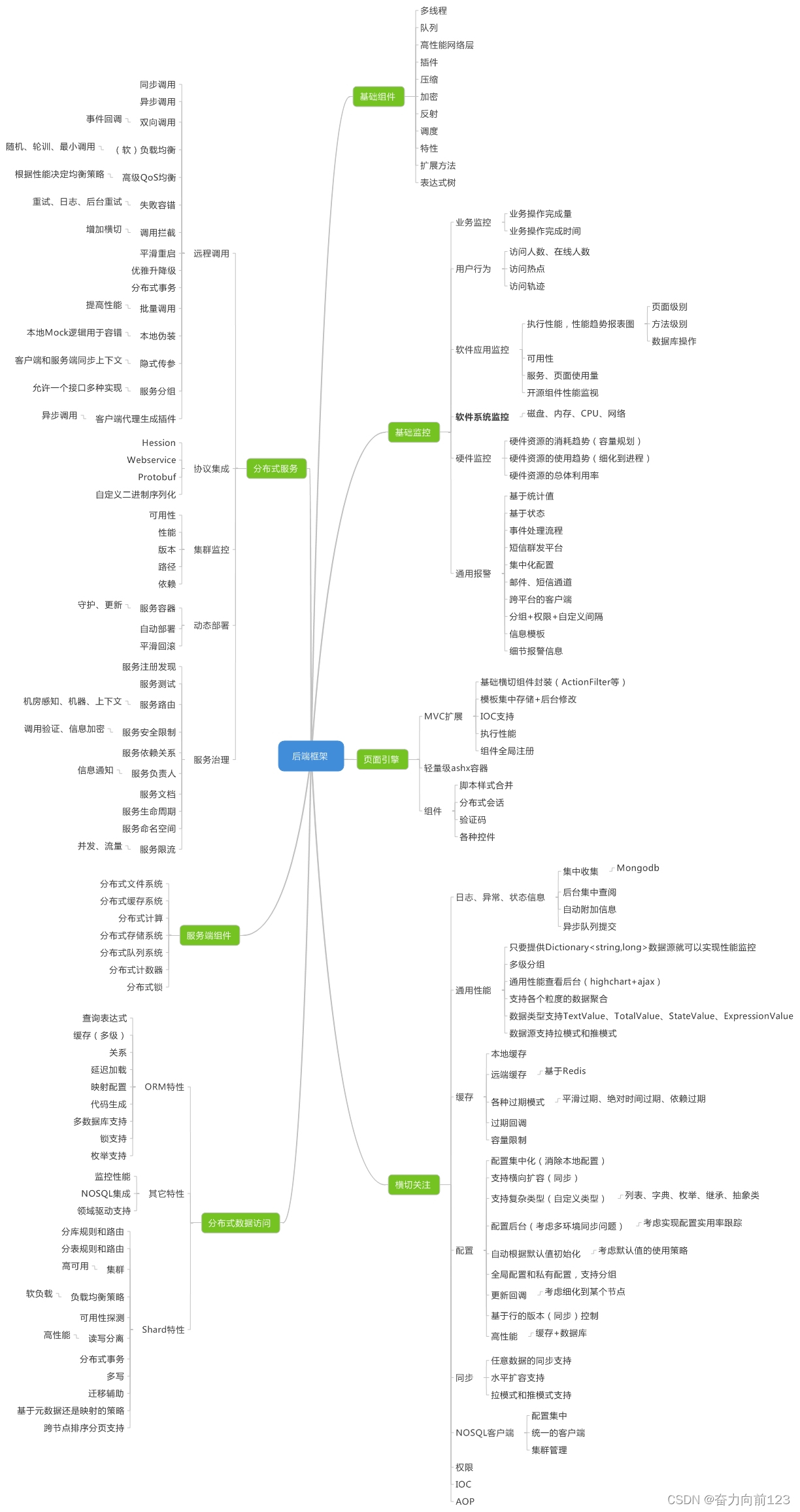
发送消息流程
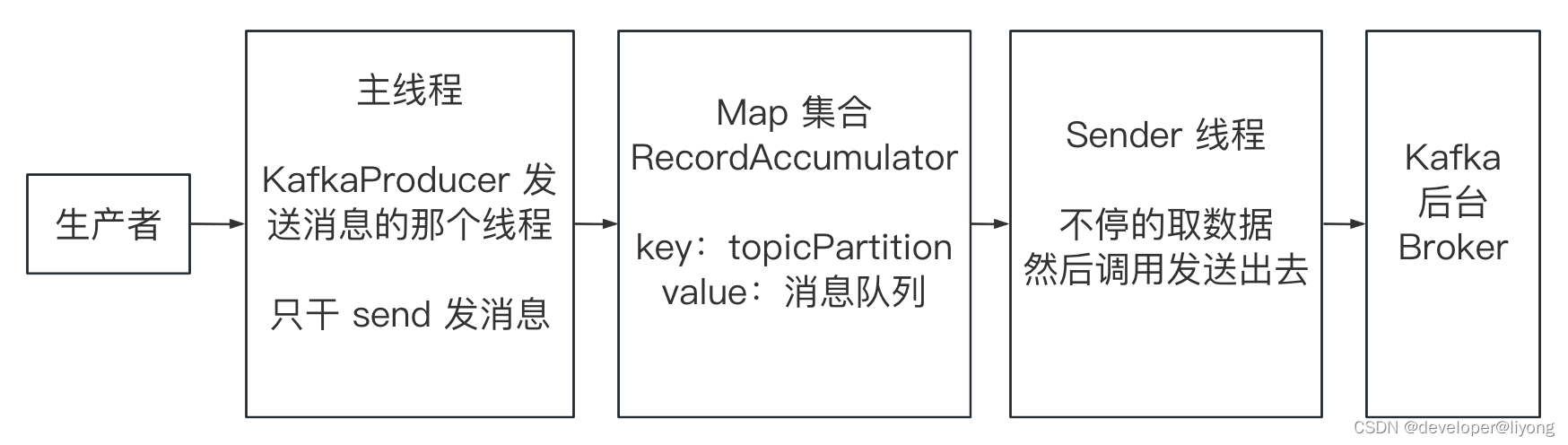
主线程:主线程只负责组织消息,如果是同步发送会阻塞,如果是异步发送需要传入一个回调函数。
Map集合:存储了主线程的消息。
Sender线程:真正的发送其实是sender去发送到broker中。
源码阅读
1 首先打开Producer.send()可以看到里面的内容
// 返回值是一个 Future 参数为ProducerRecord
Future<RecordMetadata> send(ProducerRecord<K, V> record);
// ProducerRecord定义了这些信息
// 主题
private final String topic;
// 分区
private final Integer partition;
// header
private final Headers headers;
private final K key;
private final V value;
// 时间戳
private final Long timestamp;
2 发送之前的前置处理
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
// 这里给开发者提供了前置处理的勾子
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
// 我们最终发送的是经过处理后的消息 并且如果是异步发送会有callback 这个是用户定义的
return doSend(interceptedRecord, callback);
}
3 进入真正的发送逻辑Future doSend()
- 由于是网络通信,所以我们要序列化,在这个函数里面就做了序列化的内容。
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
- 然后我们获取分区
// 然后这里又是一个策略者模式 也是由用户可以配置的 DefaultPartitioner UniformStickyPartitioner RoundRobinPartitioner 提供了这样三个分区器
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
4 到了我们的RecordAccumulator,也就是先由主线程发送到了RecordAccumulator
// 也就是对图中的Map集合
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
我们发现里面是用一个MAP存储的一个分区和ProducerBatch 是讲这个消息写到内存里面MemoryRecordsBuilder 通过这个进行写入
// 可以看到是一个链表实现的双向队列,也就是消息会按append的顺序写到 内存记录中去
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
5 接着我们看,我们append了以后,会有一个判断去唤醒sender线程,见下面的注释
// 如果说哦我们当前的 这个batch满了或者 我们创建了一个新的batch 这个时候唤醒 sender线程去发送数据
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
// 唤醒sender 去发送数据
this.sender.wakeup();
}
// 实现了Runnable 所以我们去看一下RUN方法的逻辑
public class Sender implements Runnable
好上来就是一个循环
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
接着进入runOnece方法,直接看核心逻辑
// 从RecordAccumulator 拿数据 然后发送
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
addToInflightBatches(batches);
// 中间省去了非核心逻辑
sendProduceRequests(batches, now);
如果继续跟踪的话最终是走到了selector.send()里面:
Send send = request.toSend(destination, header);
InFlightRequest inFlightRequest = new InFlightRequest(
clientRequest,
header,
isInternalRequest,
request,
send,
now);
this.inFlightRequests.add(inFlightRequest);
selector.send(send);
6 接着我们就要看返回逻辑了,可以看到在sendRequest里面sendProduceRequest方法是通过传入了一个回调函数处理返回的。
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
// 如果有返回
if (response.hasResponse()) {
ProduceResponse produceResponse = (ProduceResponse) response.responseBody();
for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {
TopicPartition tp = entry.getKey();
ProduceResponse.PartitionResponse partResp = entry.getValue();
ProducerBatch batch = batches.get(tp);
completeBatch(batch, partResp, correlationId, now, receivedTimeMs + produceResponse.throttleTimeMs());
}
this.sensors.recordLatency(response.destination(), response.requestLatencyMs());
}
追踪到ProducerBatch
if (this.finalState.compareAndSet(null, tryFinalState)) {
completeFutureAndFireCallbacks(baseOffset, logAppendTime, exception);
return true;
}
private void completeFutureAndFireCallbacks(long baseOffset, long logAppendTime, RuntimeException exception) {
// Set the future before invoking the callbacks as we rely on its state for the `onCompletion` call
produceFuture.set(baseOffset, logAppendTime, exception);
// execute callbacks
for (Thunk thunk : thunks) {
try {
if (exception == null) {
RecordMetadata metadata = thunk.future.value();
if (thunk.callback != null)
thunk.callback.onCompletion(metadata, null);
} else {
if (thunk.callback != null)
thunk.callback.onCompletion(null, exception);
}
} catch (Exception e) {
log.error("Error executing user-provided callback on message for topic-partition '{}'", topicPartition, e);
}
}
produceFuture.done();
}
Thunk 这个其实就是我们在Append的时候的回调:
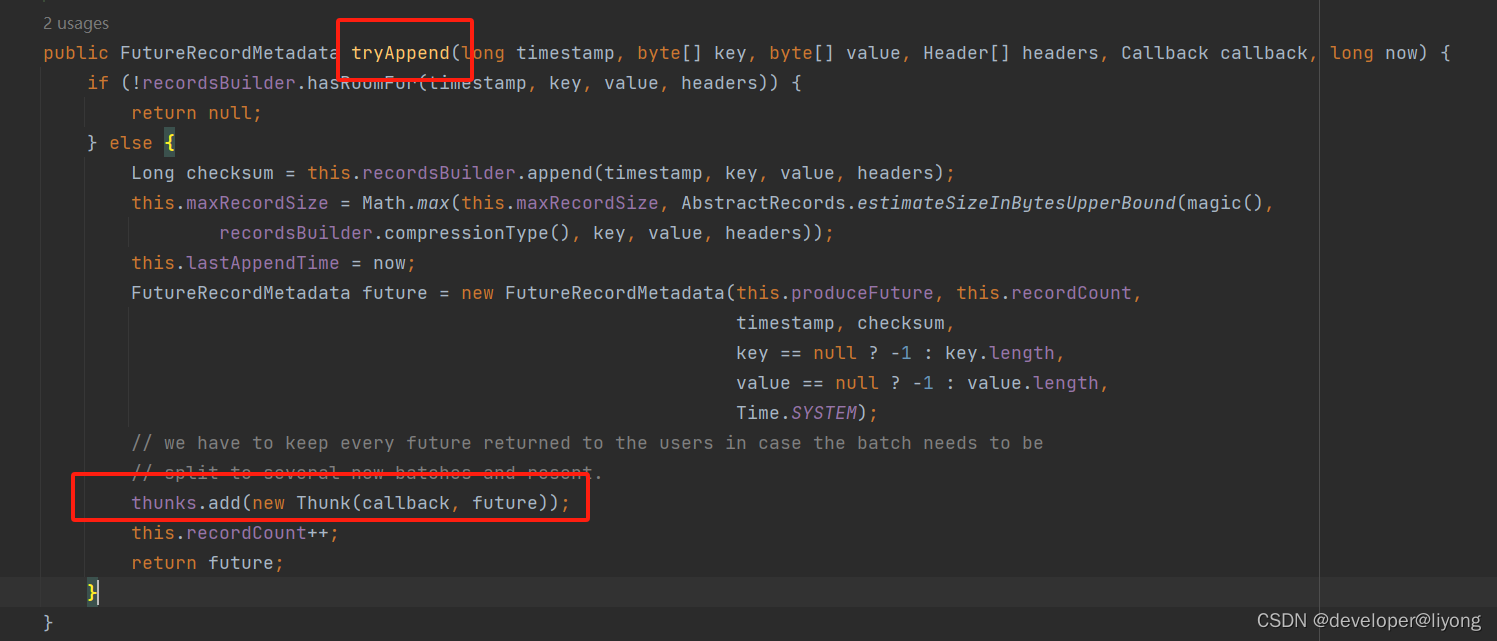
至此整个流程就完成了,从发送消息,到响应后回调我们的函数。