思维导图

输入输出,以及基础头文件
在c语言中我们常用scanf("%d",&n);和printf("%d\n",n);来输出一些变量和常量,在C++中我们可以用cin;和cout;来表示输入输出。
在C语言中输入输出有头文件,在C++也有头文件,只不过C++的头文件有一点奇怪,他首先是要包括一个输入输出流(即iostream,i表示cin中的i.o就是表示输出也就是cout,这个stream在英文中表示的是是水流的意思,在计算机的眼中,信息是像水一样流进计算机的,处理玩的信息是像水一样留出计算机的),所以这个头文件就叫左iostream,然后这个还要用一个using namespace std。这个是内存申请一个空间,并且将stdio.h中的函数放进去(虽然stdio.h的函数很少),哪里可以看到这个stdio.h呢,就是在namespace的后面std,这个就是stdio.h。
这是对数字和特殊字符的输出:
#include<iostream>
using namespace std;
int main()
{
int n=1;//下面这三种都是等价的
printf("%d %d\n",n,n+1);
cout<<n<<" "<<n+1<<endl;
cout<<n<<" "<< n+1<<"\n";
}接下来就是有关字符串
数值
最大值:0x3f3f3f3f(4个f,3个0)或者0x7fffffff(这里一共7个f)这两玩意都是表示最大值的意思,数量级是 .
#define INF 0x3f3f3f3f或者const int INF = 0x3f3f3f3f来使自己定义的变量inf(所以以后看到这个不要慌,这个就是表示最大值的意思)。
函数
s1.substr()函数
使用的方法就是:设置一个字符串s1,然后将这个字符串用‘.’连接起来,括号里面有两个变量,第一个变量需要开始的位置(往往是指下标,所以就需要减一),第二个变量是你需要的长度。用一个新的字符串来存储s1中你所需要的的这一段字符.
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s1;
cin>>s1;
string s2;
s2=s1.substr(1,4);//从下标为0的地方开始,直到长度为4
cout<<s2<<endl;
return 0;
} 
s1.find(ch)函数
这个是在字符串s1里面找到一个和ch一样的字符,并且返回其位置(注意这个是返回下标,所以是长度减1)
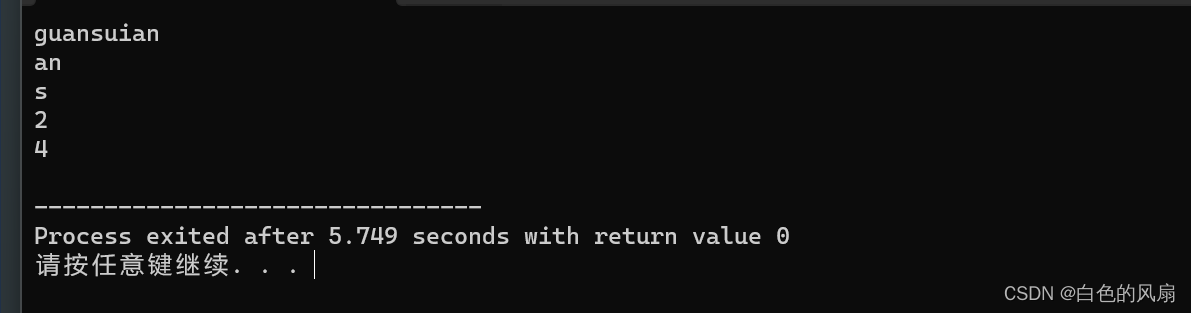
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s1,s2;
char ch;
cin>>s1;
cin>>s2;
cin>>ch;
int len1,len2;
len1=s1.find(s2);
len2=s1.find(ch);
cout << len1 << endl;
cout << len2 << endl;
return 0;
}
sort函数
sort函数中含有三个变量,第一个和第二个是需要排序的范围(就是数组名加上数字),然后第三个就是决定升序或者降序的,如果不进行填写就是代表着升序。头文件在include<algorithm>,这个英文单词也是算法的意思
#include<iostream>
#include<string.h>
#include<algorithm>
using namespace std;
int main()
{
int a[10];
for(int i=1;i<=5;i++)
cin>>a[i];
sort(a+1,a+5);
for(int i=1;i<=5;i++)
cout<<a[i]<<" ";
return 0;
}
降序就在最后面加上一个greater<int>()
升序就是在最后加一个less<int>() (或者可以什么都不写)
sort(a, a + n, greater<int>());//降序排列
sort(a, a + n, less<int>());//升序排列接下来就是有关如何用sort函数来编写对结构体的排序:
主要就是对结构体其中的某个元素进行排序,然后将结构体全部元素都进行一个排序,所以这里最关键的就是对“标准”的定义(大白话就是对哪一个元素排序)。
首先我们就需要构造一个结构体
struct node
{
int x,y,t;
} q[N];然后书写规则(这里就需要书写一个bool类型的函数)
bool cmp(node x,node y)
{
return x.t<y.t;//这个就是升序的标准
}然后再将这个标准放在sort函数中的最后一位
sort(q,q+m,cmp);find函数
头文件是include<algorithm>
这个头文件包含了很多函数,所以建议大家先去看看这个里面所有函数,以便在书写变量和函数名重合。函数格式:InputIterator find (InputIterator first, InputIterator last, const T& val);
first 和 last 为输入迭代器(迭代其就相当于一个是勺子,可以向一碗汤中送汤,也可以从汤中捞汤),[first, last) 用于指定该函数的查找范围;val 为要查找的目标元素。
另外,该函数会返回一个输入迭代器,当 find() 函数查找成功时,其指向的是在 [first, last) 区域内查找到的第一个目标元素;如果查找失败,则该迭代器的指向和 last 相同。
具体的时使用代码如下(由于还没又进一部学习vector,所以后面的我也看不懂)
#include <iostream> // std::cout
#include <algorithm> // std::find
#include <vector> // std::vector
using namespace std;
int main() {
//find() 函数作用于普通数组
char stl[] ="http://c.biancheng.net/stl/";
//调用 find() 查找第一个字符 'c'
char * p = find(stl, stl + strlen(stl), 'c');
//判断是否查找成功
if (p != stl + strlen(stl)) {
cout << p << endl;
}
//find() 函数作用于容器
std::vector<int> myvector{ 10,20,30,40,50 };
std::vector<int>::iterator it;
it = find(myvector.begin(), myvector.end(), 30);
if (it != myvector.end())
cout << "查找成功:" << *it;
else
cout << "查找失败";
return 0;
}strstr函数
map函数、
这个函数首先是底一个变量就是它的·类型这个类型就是
队列等头文件
1.这里要用到一个优先队列(stl),其本质就是用一个数组模拟的一个完全二叉树。
2.功能:拿出优先级最大的元素,这个优先级可以自己定义。
3.这个包括在头文件#include<queue>之中。
4.定义方式:priority_queue<int> que 尖括号说明里面存放的数是整型(这样定义就是大顶堆 值越大优先级越高)
5.关于优先队列的几种操作:1.que.size() 得到这个队列的元素数量
2.que.push(x) 插入
3.que.pop() 删除优先级最高的元素
4.que.top()访问优先级最高的元素(访问堆顶元素)
5.que.empty()判断堆是否为空
插入删除的时间复杂空间度都是为对数级,访问堆顶元素的时间复杂度为常数级别。
接下俩是堆优先队列的一些基础操作
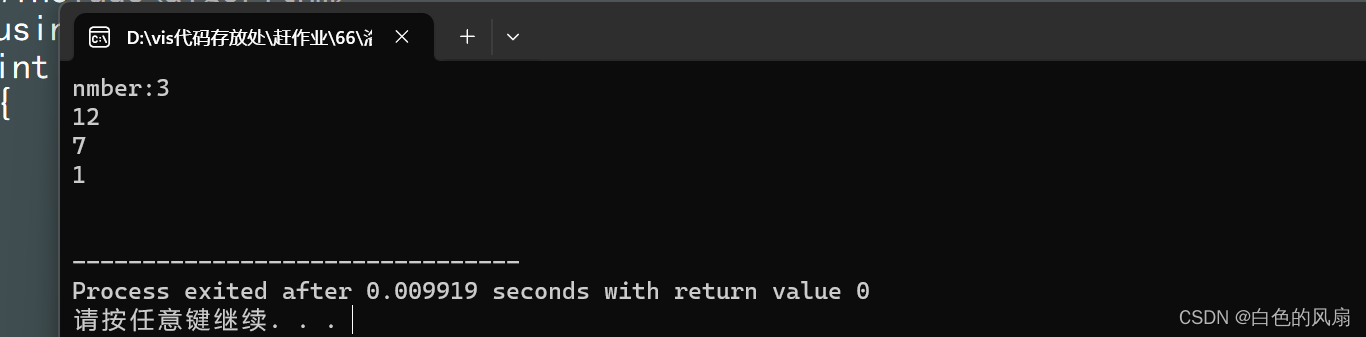
#include<iostream>
#include<queue>
#include<algorithm>
using namespace std;
int main()
{
priority_queue<int> que;
que.push(7);
que.push(1);
que.push(12);
printf("nmber:");
cout<<que.size()<<endl;
while(!que.empty())
{
cout<<que.top()<<endl;
que.pop();
}
cout<<endl;
return 0;
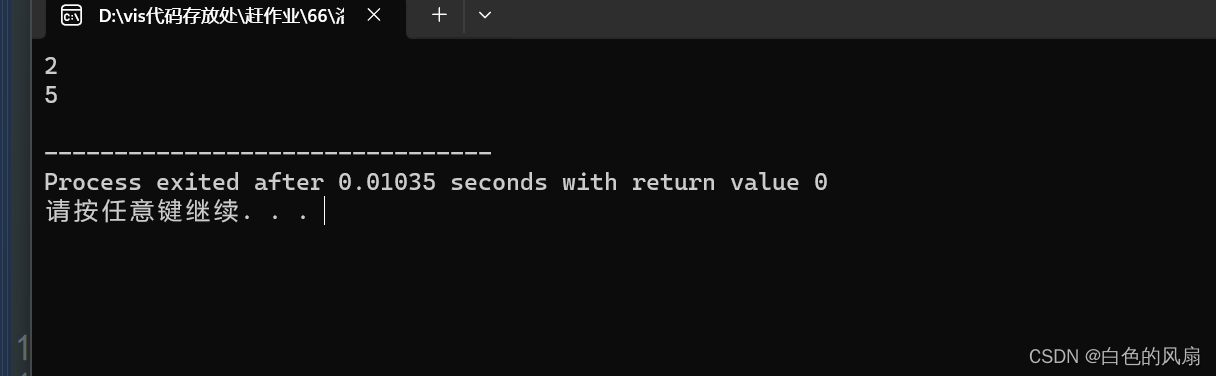
}输出数据如下(这样就可以使用堆排序)
 对于我们自定义
对于我们自定义
#include<iostream>
#include<queue>
#include<algorithm>
using namespace std;
struct node
{
int x,y;
bool operator< (const node &b) const{//运算符重新定义,注意这个运算符只能定义小于号
return this->x>b.x;//从大到小
}
};
int main()
{
priority_queue<node> que;
que.push((node){5,2});
que.push((node){2,4});
while(!que.empty())
{
cout<<que.top().x<<endl;
que.pop();
}
return 0;
}输出结果: