😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔笔记来自B站UP主Ele实验室的《小白也能听懂的人工智能原理》。
🔔本文讲解激活函数:给机器注入灵魂,一起卷起来叭!
目录
- 一、“分类”
- 二、代码实现
一、“分类”
人在思考的过程中,往往不会产生精确的数值估计,而常做的事情是分类。

比如给你一块馒头,你会说这么大的我能吃饱,这么大的我吃不饱,我们更倾向于把馒头分为“吃饱”和“吃不饱”这两类:
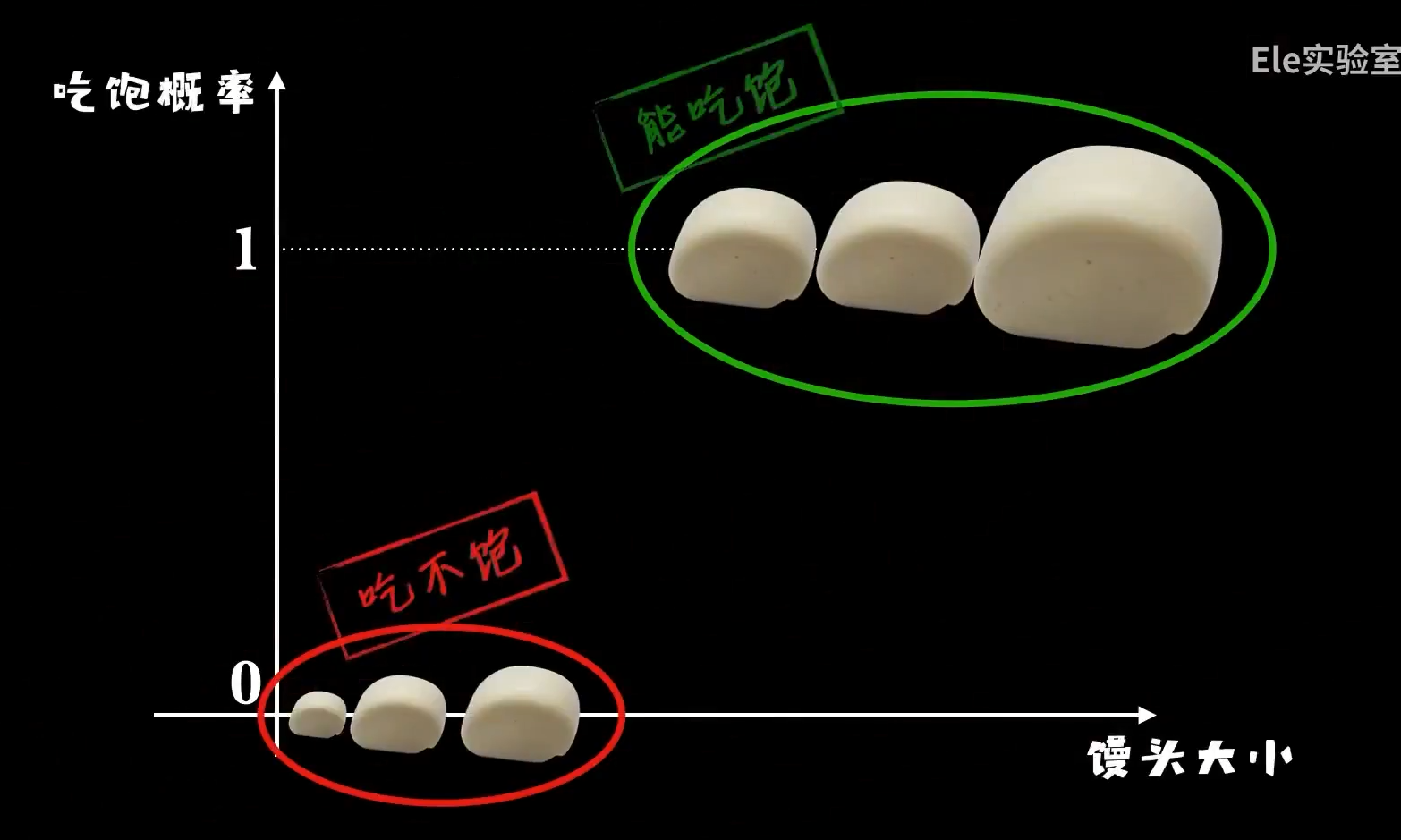
而不会在大脑中构建出一条精确的函数曲线:
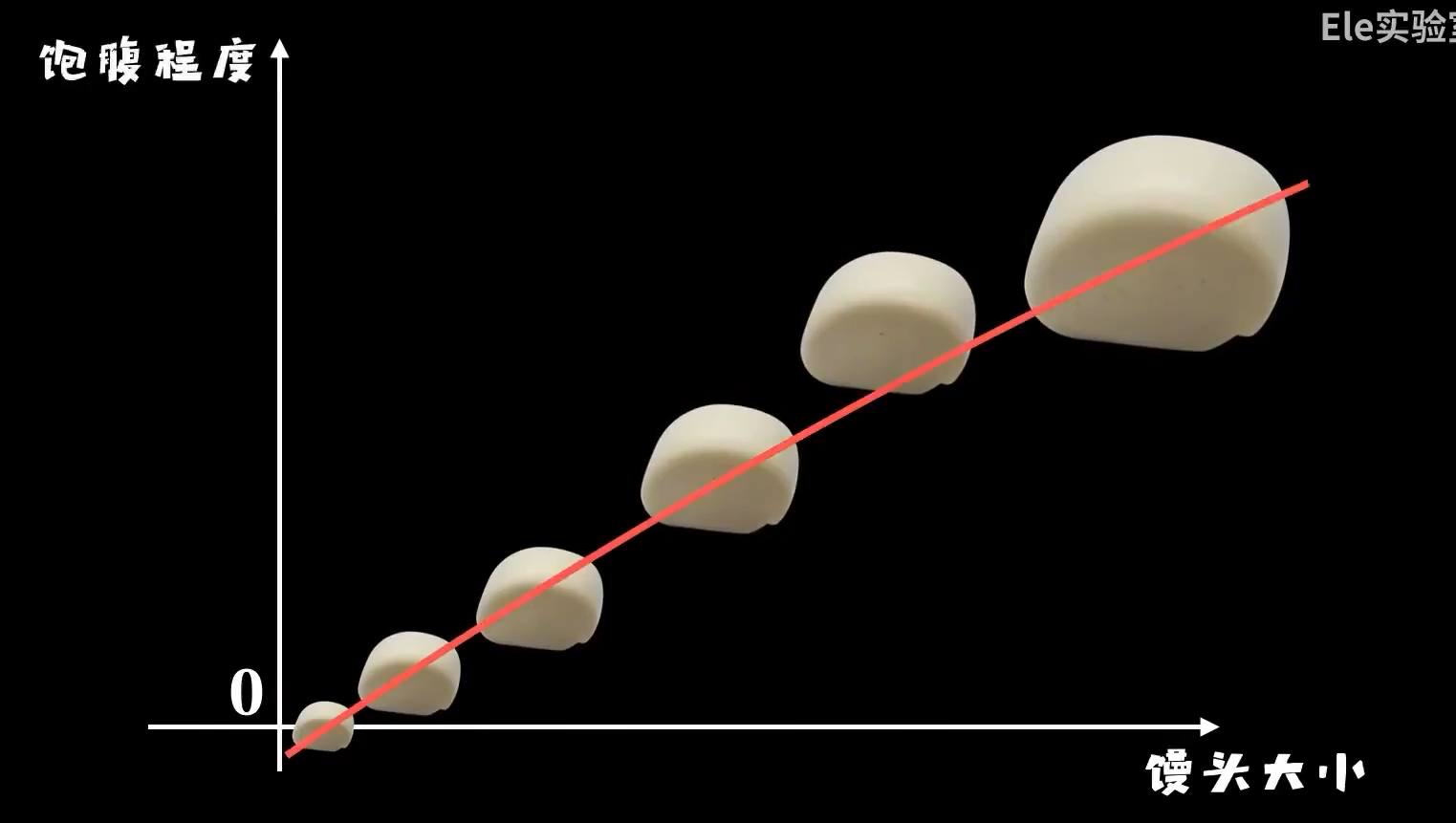
对于一个事物,简单的贴标签比仔细的计算更符合我们的生物本能:

也就是说:

同样对于小蓝,也是如此,假如小蓝抗毒能力为0.8:
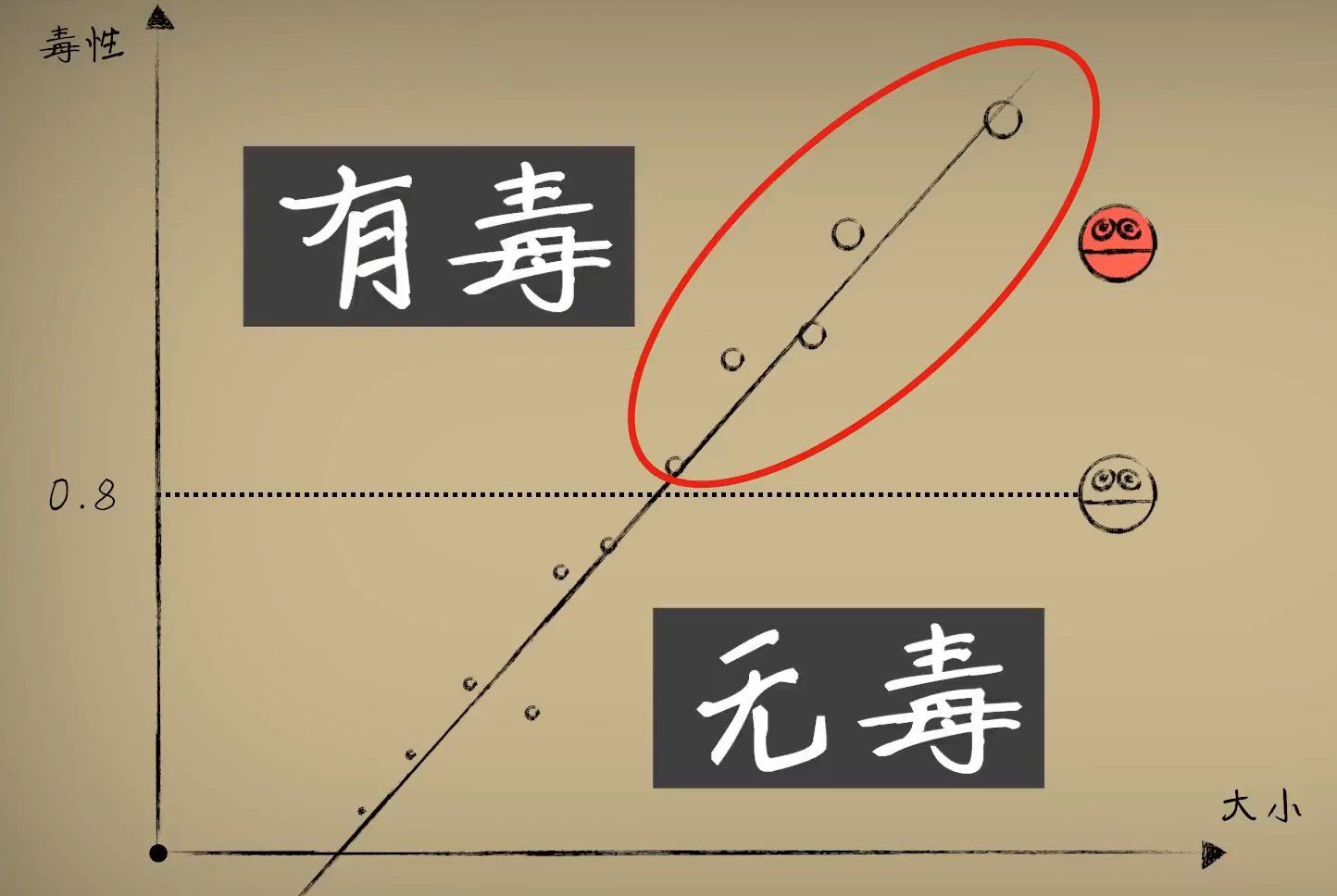
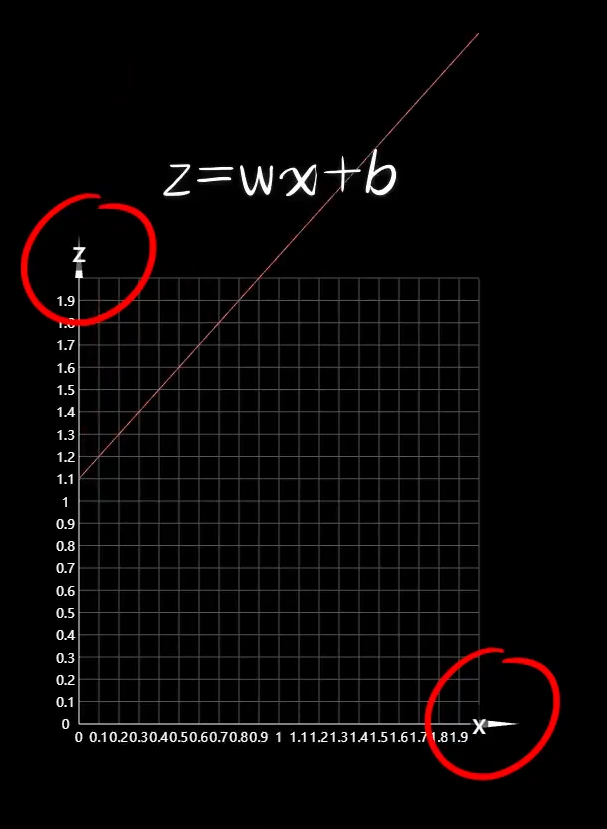
那么怎么表示这样的关系呢?机制如你,想到分段函数:
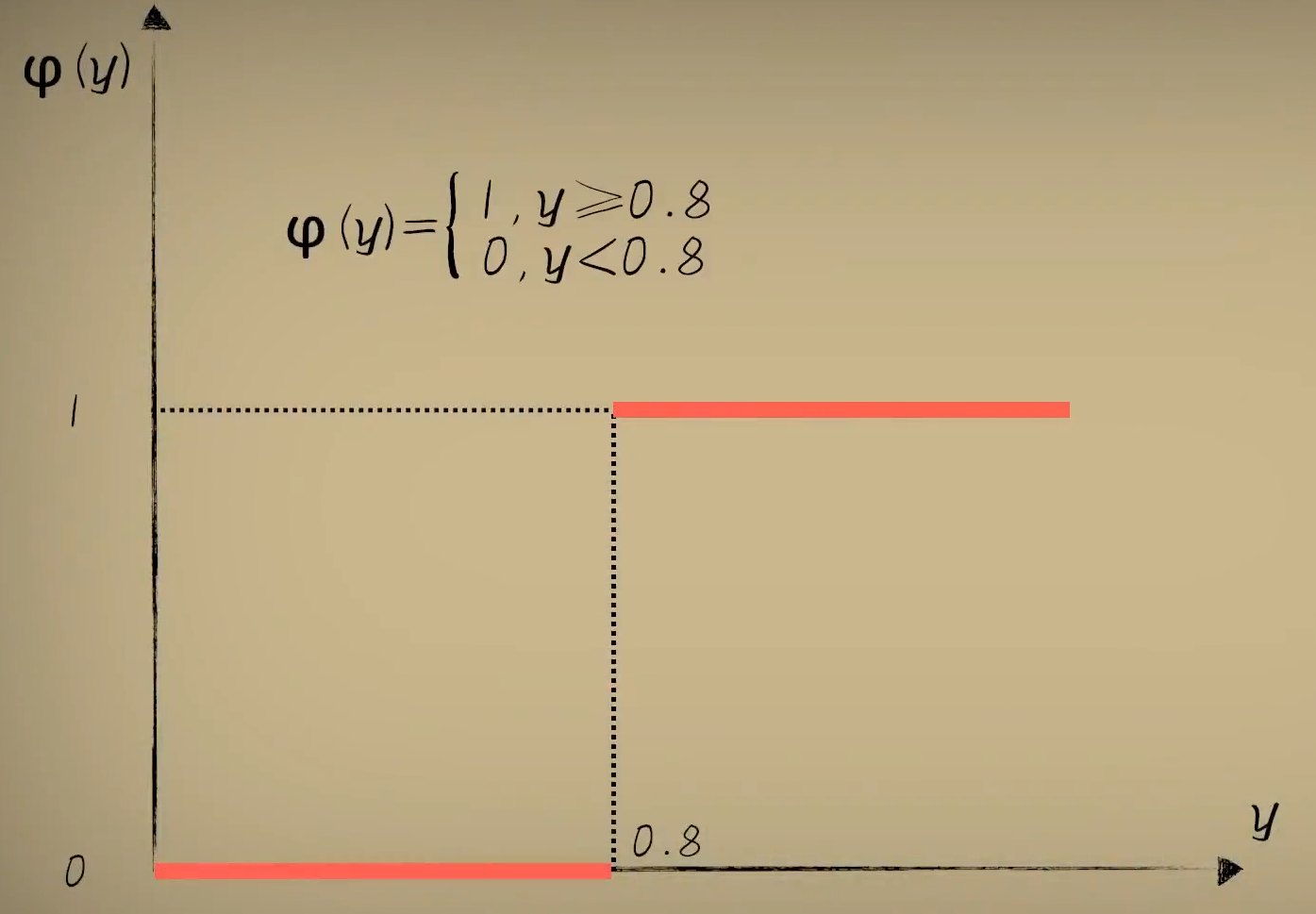
远的不说,这个大括号看着就很头疼,看着就是个不好处理的家伙。
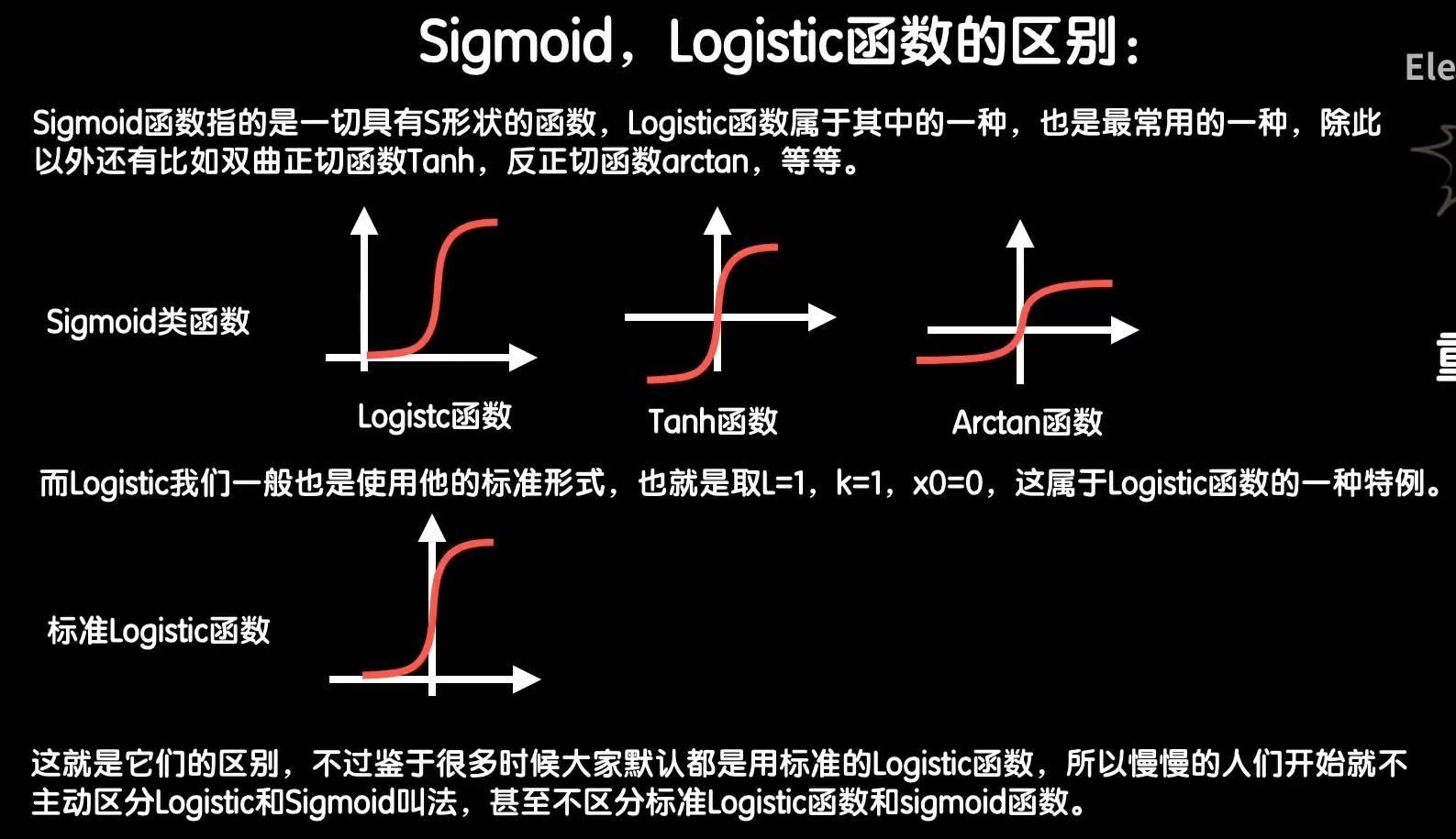
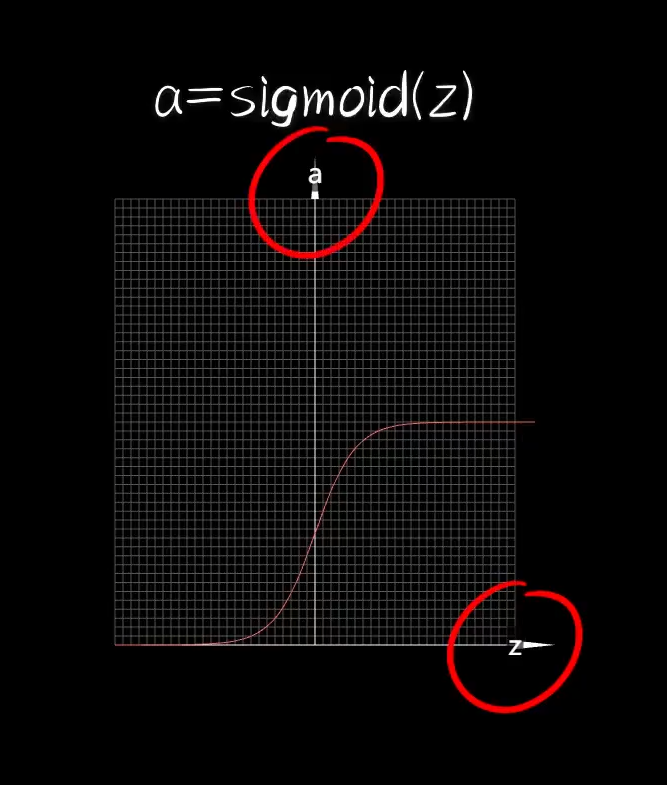
我们接下来,看一种更为优雅的Logistic函数:
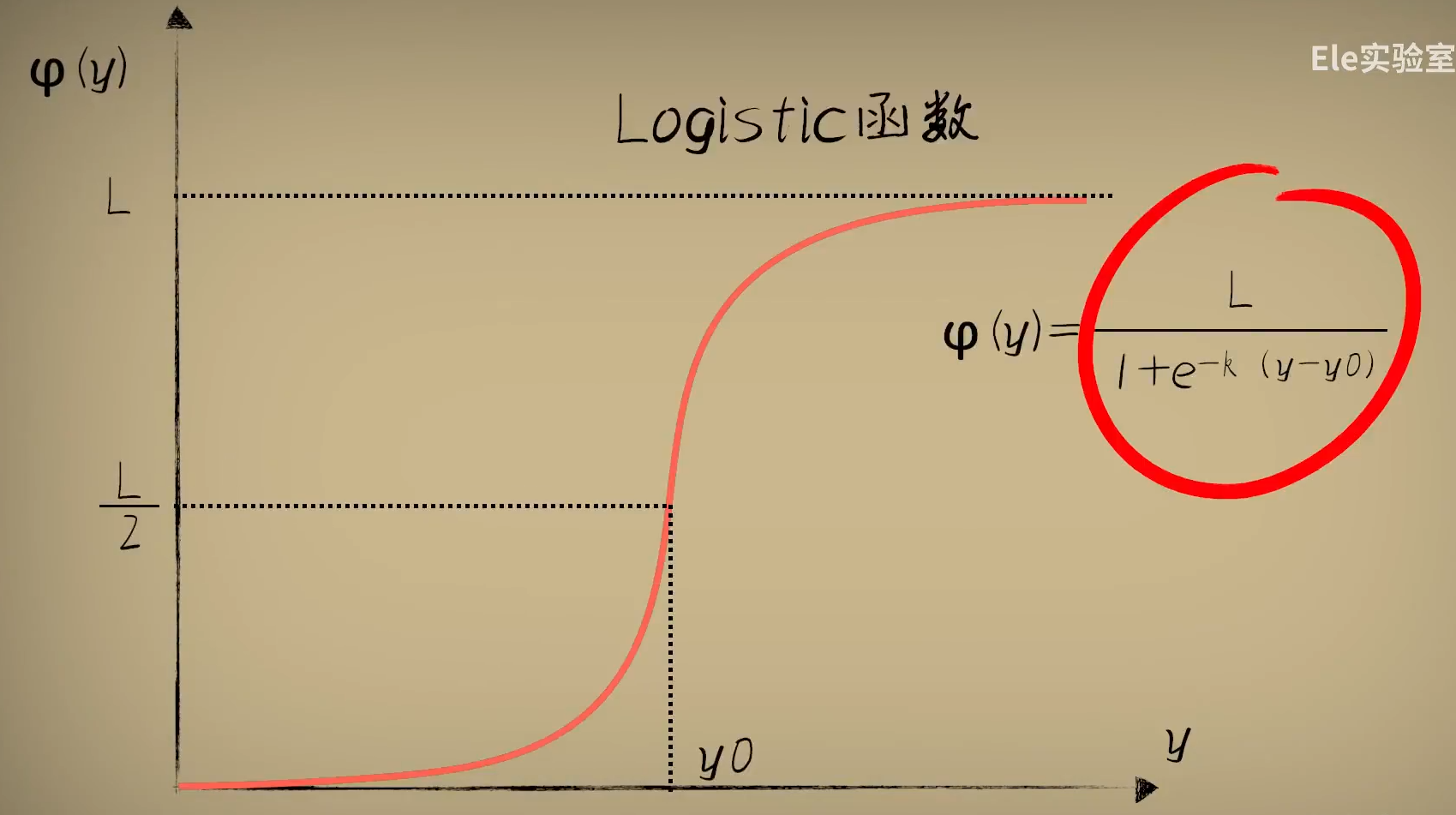
不过我们一般会采用标准的Logistic函数,L=1,k=1,y0=0
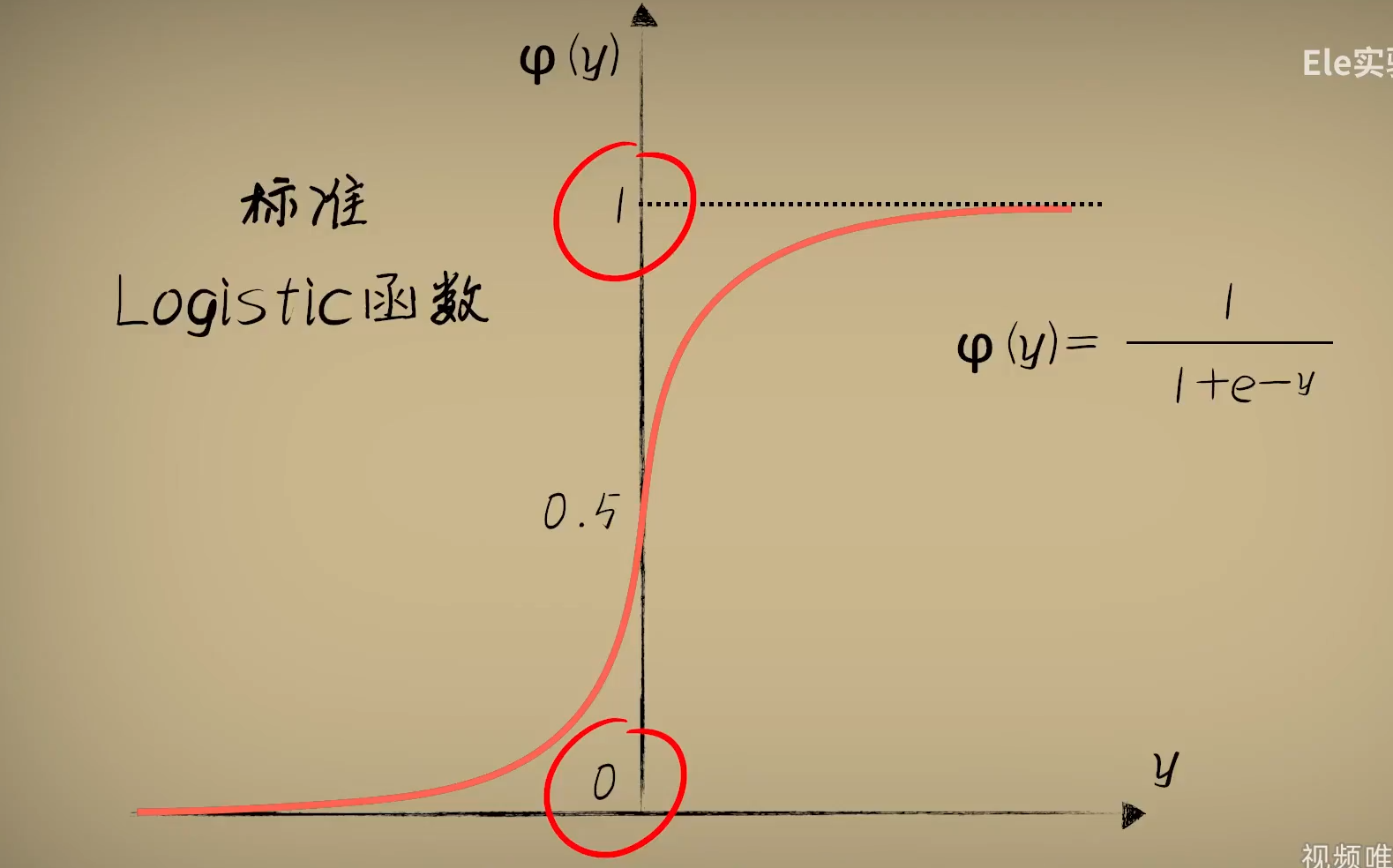
可以看出来这个函数的计算结果始终在0到1之间,他的名字也暗示了这一点:很适合做逻辑判断,即分类。
知识补充:
此时这里函数关系为:
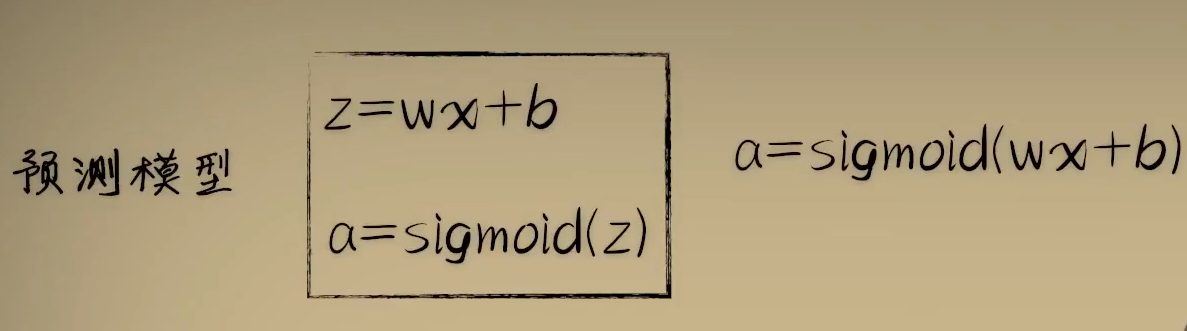
我们梳理一下这三个函数:
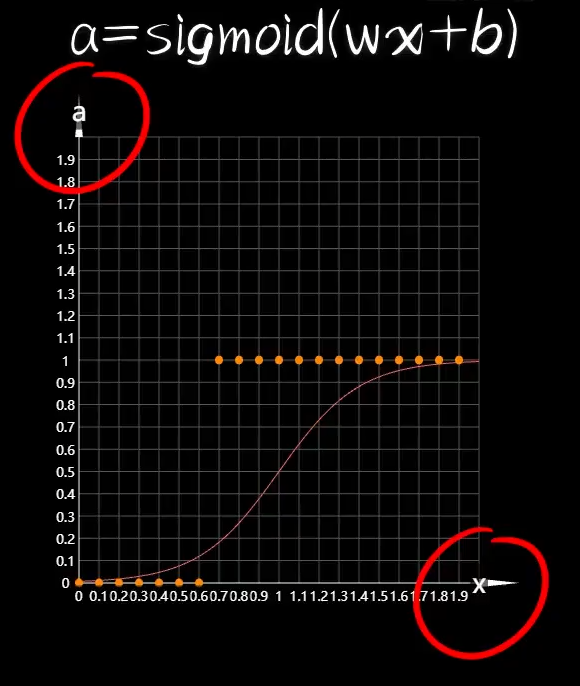
接下来,我们按照之前的方法,分别e对w、b求偏导,然后合成:

补充Logistic函数的求导:
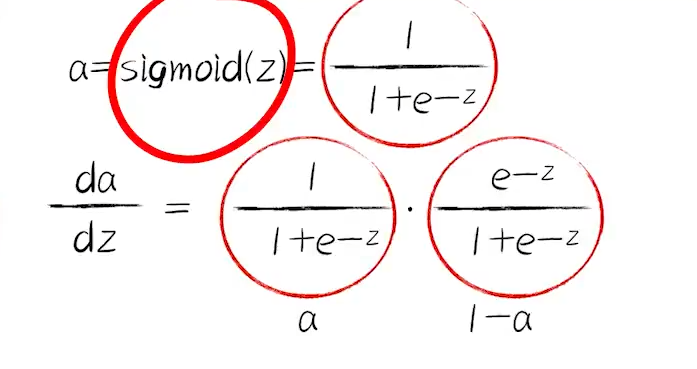
理解复合函数求导中从外到内的这一过程,这有助于我们后续理解神经网络的精髓:
深度学习的开山鼻祖,他们在1986年引入的反向传播算法成为了现代神经网络的基石:

反向传播算法发明在1961年,不过在此之前人们对多层感知器、深度神经网络都持悲观的态度:

他们曾这样说:

正如一位大佬所说:“很多看似显而易见的想法,只有在事后,才变得显而易见。”

二、代码实现
豆豆数据集模拟:dataset.py
import numpy as np
def get_beans(counts):
xs = np.random.rand(counts)
xs = np.sort(xs)
ys = np.zeros(counts)
for i in range(counts):
x = xs[i]
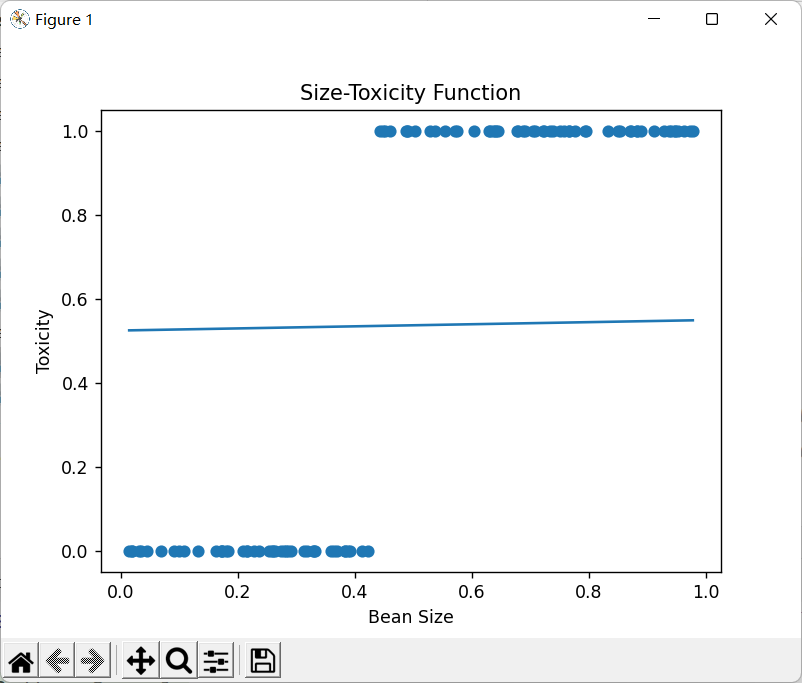
yi = 0.7*x+(0.5-np.random.rand())/50+0.5
if yi > 0.8:
ys[i] = 1
return xs,ys
豆豆毒性分布如下:
加入激活函数后的梯度随机下降算法:activation.py
import dataset
import matplotlib.pyplot as plt
import numpy as np
# 豆豆数量m
m = 100
xs, ys = dataset.get_beans(m)
# 配置图像
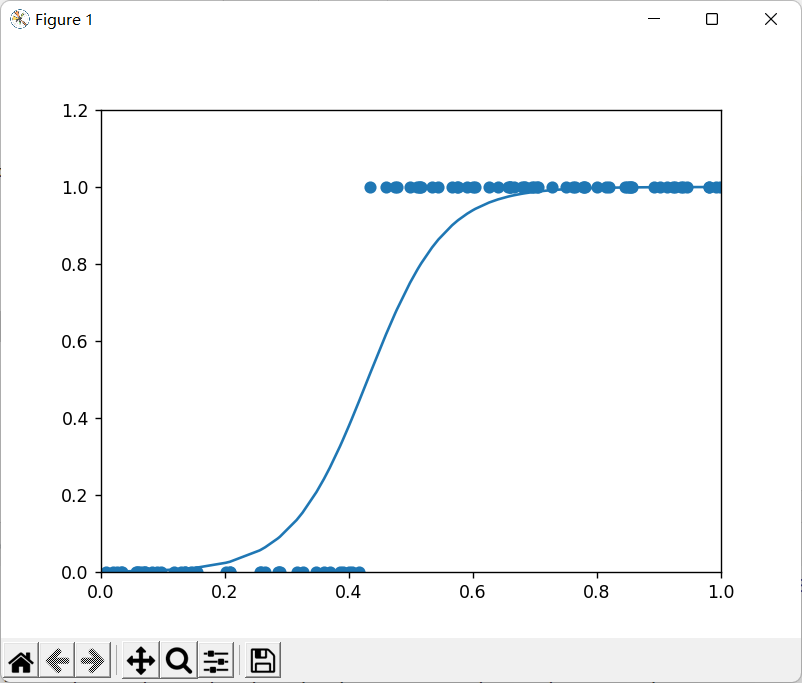
plt.title("Size-Toxicity Function", fontsize=12)
plt.xlabel("Bean Size")
plt.ylabel("Toxicity")
plt.scatter(xs, ys)
w = 0.1
b = 0.1
z = w * xs + b
a = 1 / (1 + np.exp(-z)) # 加入激活函数
plt.plot(xs, a)
plt.show()
# alpha为学习率
alpha = 0.01
# 训练5000次
for _ in range(5000):
for i in range(100):
x = xs[i]
y = ys[i]
# 三个函数
z = w * x + b
a = 1 / (1 + np.exp(-z))
e = (y - a) ** 2
# 对w和b求偏导
deda = -2 * (y - a)
dadz = a * (1 - a)
dzdw = x
dzdb = 1
dedw = deda * dadz * dzdw
dedb = deda * dadz * dzdb
w = w - alpha * dedw
b = b - alpha * dedb
if _ % 100 == 0:
# 绘制动态
plt.clf() ## 清空窗口
plt.scatter(xs, ys)
z = w * xs + b
a = 1 / (1 + np.exp(-z)) # 加入激活函数
plt.xlim(0, 1)
plt.ylim(0, 1.2)
plt.plot(xs, a)
plt.pause(0.01) # 暂停0.01秒
相关代码仓库链接,欢迎Star:传送门