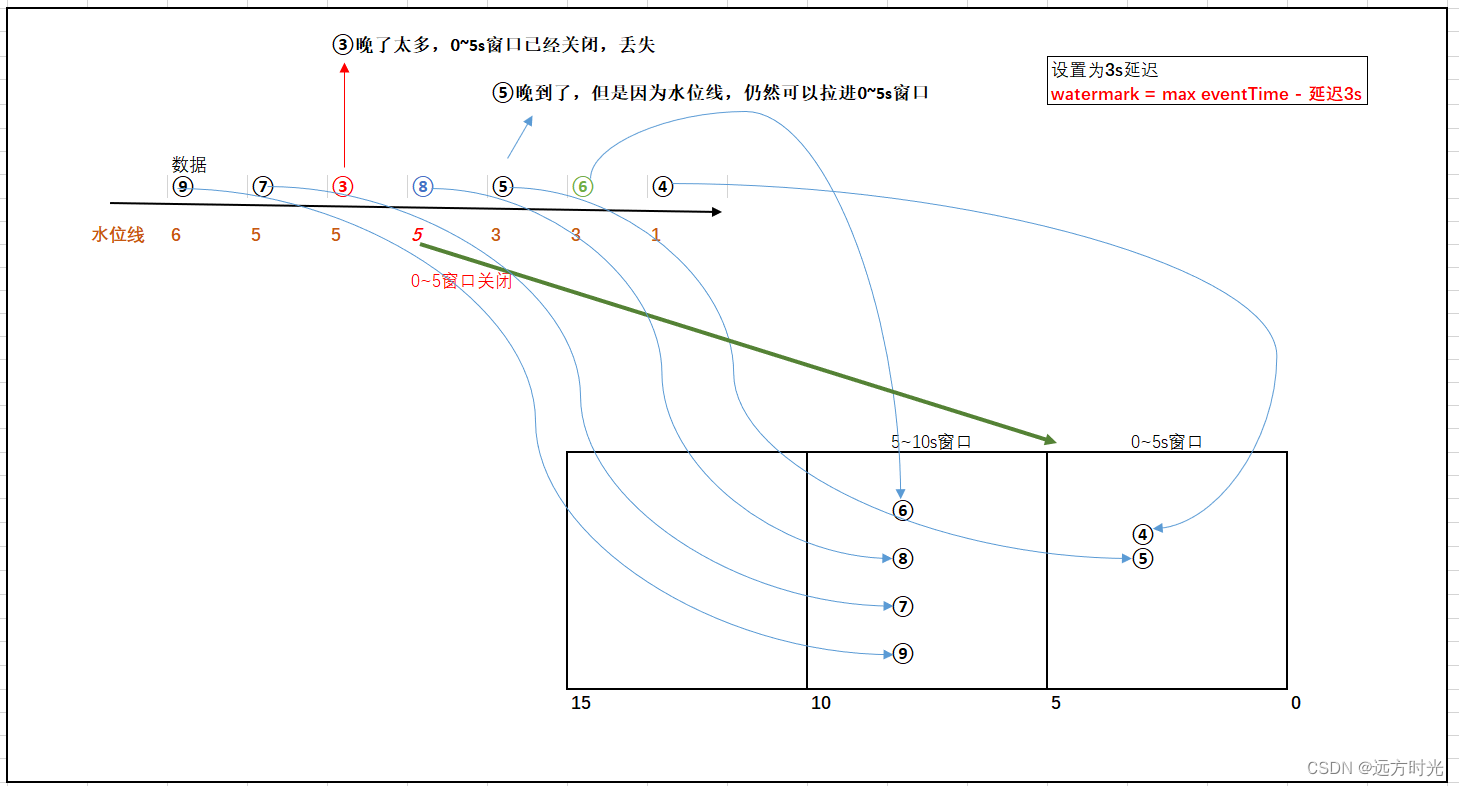
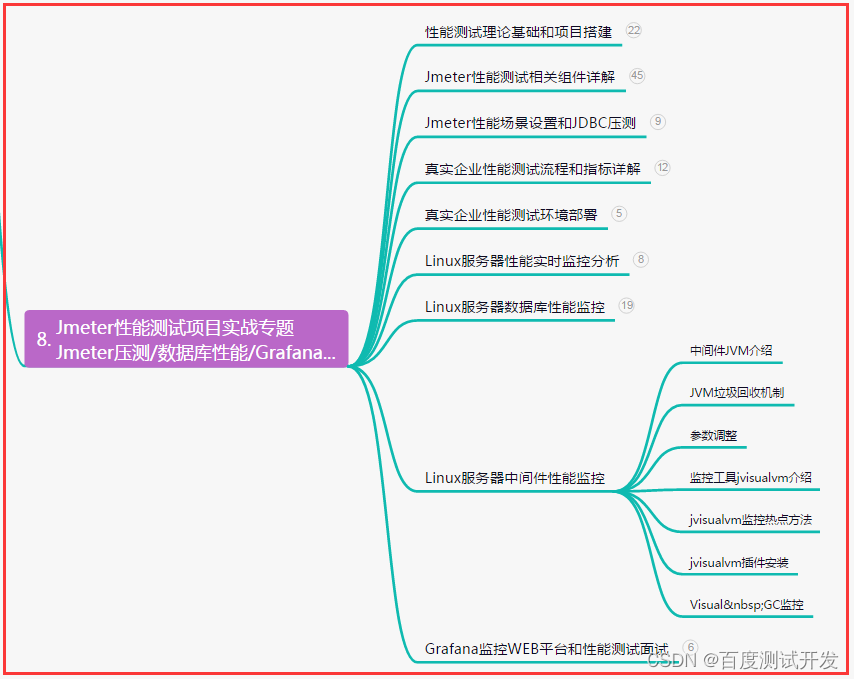
1 目标
为什么要用代理池
- 许多网站有专门的反爬虫措施,可能遇到封IP等问题。
- 互联网上公开了大量免费代理,利用好资源。
- 通过定时的检测维护同样可以得到多个可用代理。
代理池的要求
- 多站抓取,异步检测
- 定时筛选,持续更新
- 提供接口,易于提取
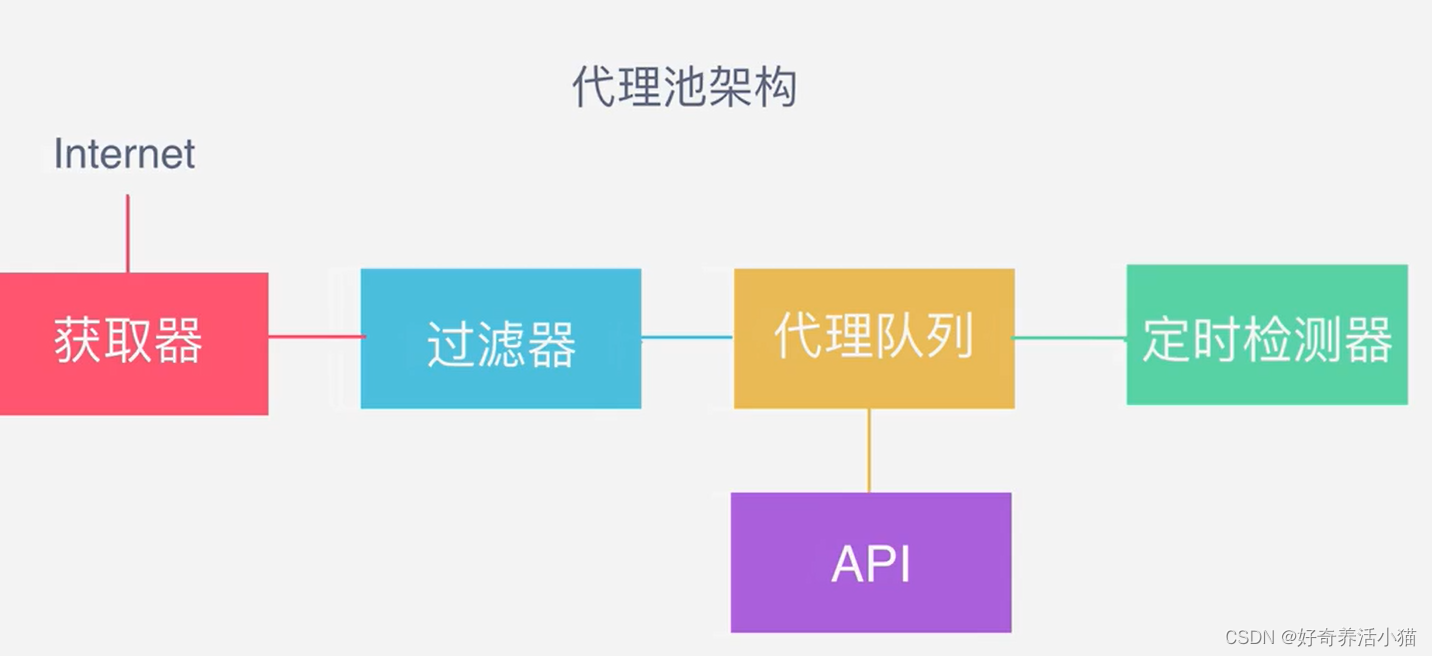
2 流程框架
代理池架构:
3 实战
代码下载
github一位大神的源码作为参考:https://github.com/germey/proxypool
flask运行需要安装:
virtualenv是一个虚拟的Python环境构建器。它帮助用户并行创建多个Python环境。因此,它可以避免不同版本的库之间的兼容性问题。
# 以下命令用于安装virtualenv:
pip install virtualenv
# 安装后,将在文件夹中创建新的虚拟环境。
mkdir newproj
cd newproj
virtualenv venv
# 要在 Windows 上激活相应的环境,可以使用以下命令:
venv\scripts\activate
# 现在准备在这个环境中安装Flask:
pip install Flask
目录结构及介绍
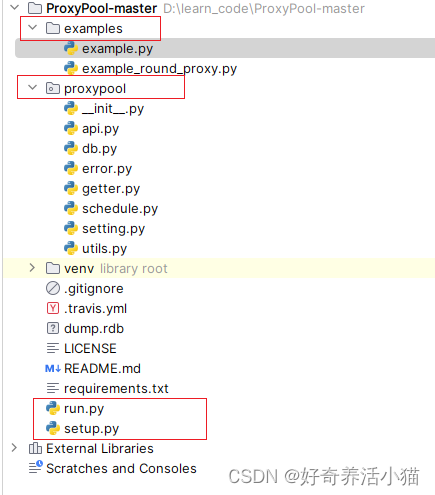
examples目录是示例
proxypool:程序的源代码
run:程序入口
setup:安装代理池,代理池安装到python包
run.py:
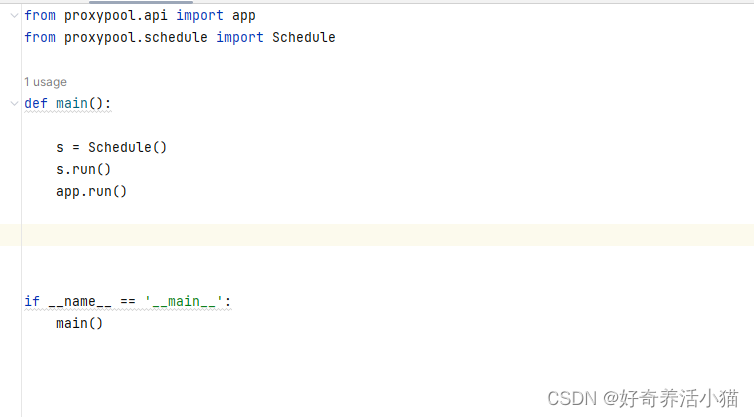 运行一个调度器schedule,运行一个接口api
运行一个调度器schedule,运行一个接口api
schedule.py
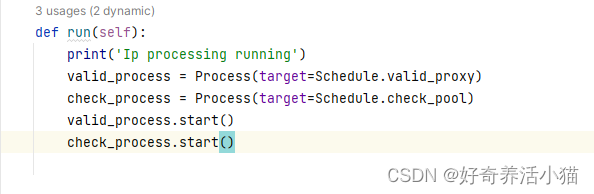
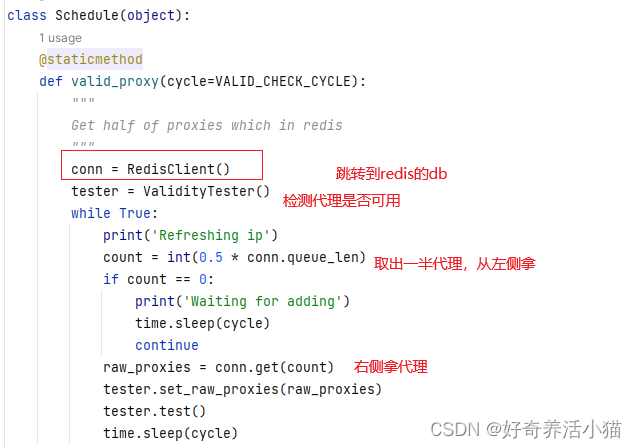
Schedule.valid_proxy:网上获取代理,筛选代理,存到数据库
Schedule.check_pool:定时检查清理代理

set_raw_proxies:存放可用代理数组
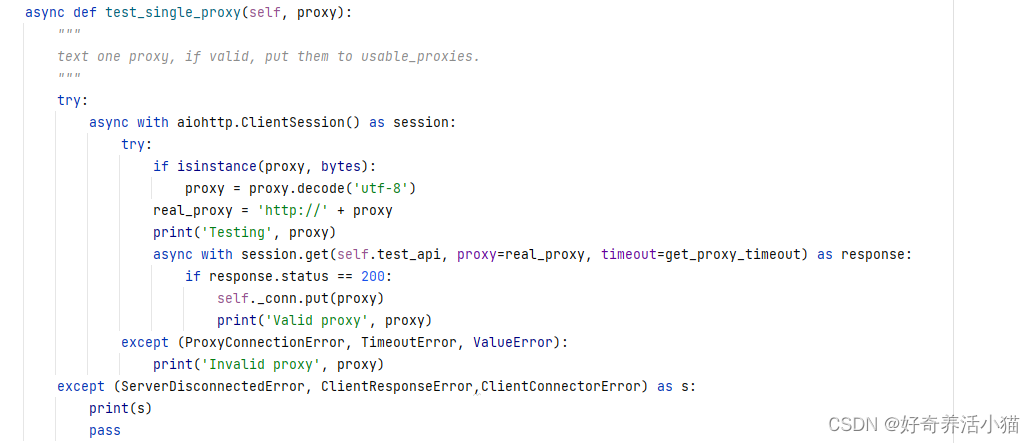
async:异步检测
test_single_proxy:测试单个代理
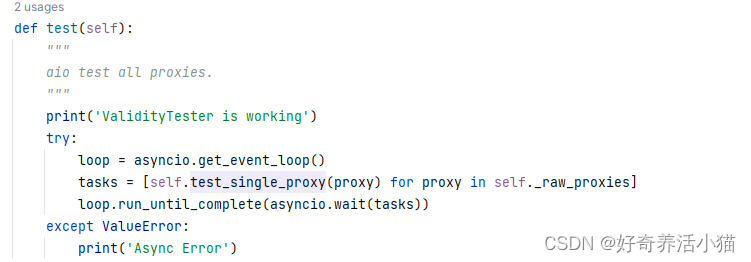
test:测试代理是否可用

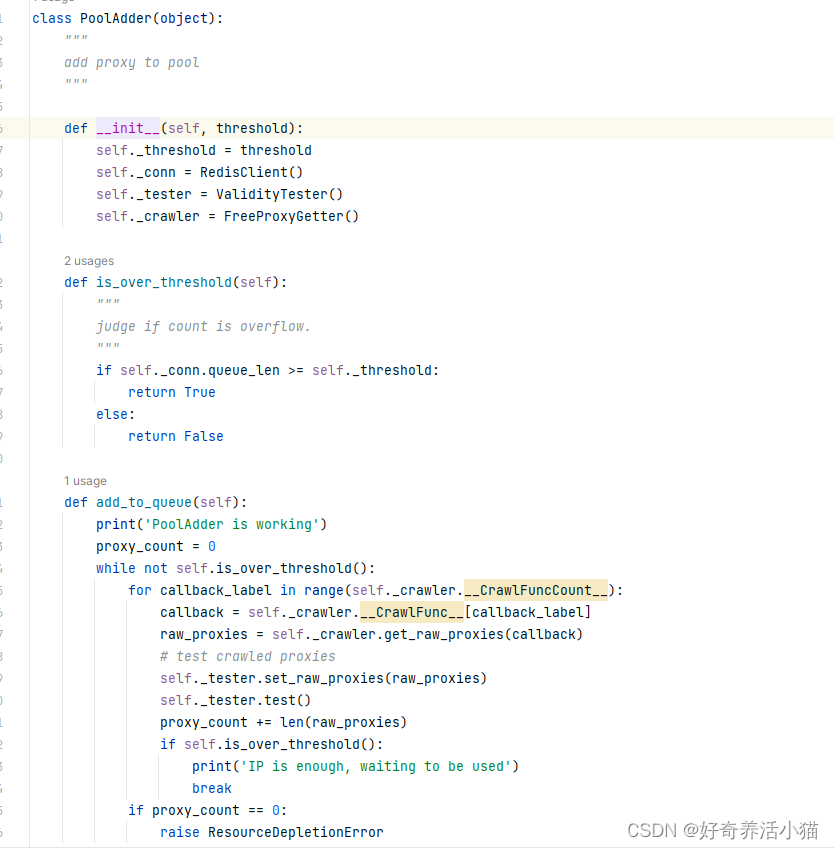
FreeProxyGetter():各大网站抓取代理的类
is_over_threshold:代理池满没满
callback:动态拿到crawl_方法的名称
db.py
redis队列的一些操作:
连接数据库:
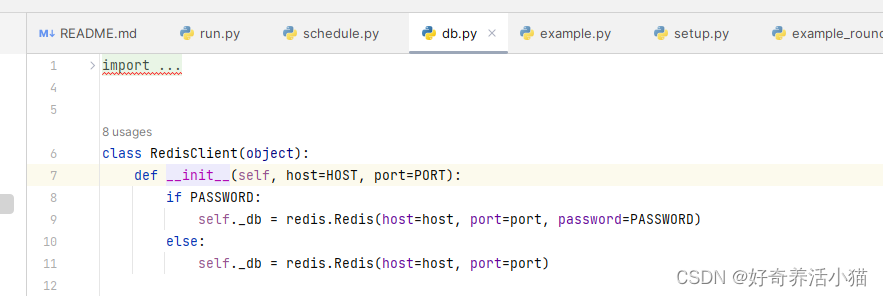
从数据库获取代理:
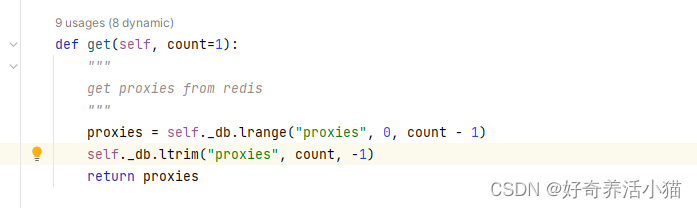
上图是:从左侧批量(count)获取多少个代理。
插入代理:

上图是:将新代理放入右侧,所以右侧代理比左侧代理新。
api获取最新可用代理:

获取代理数量及更新:

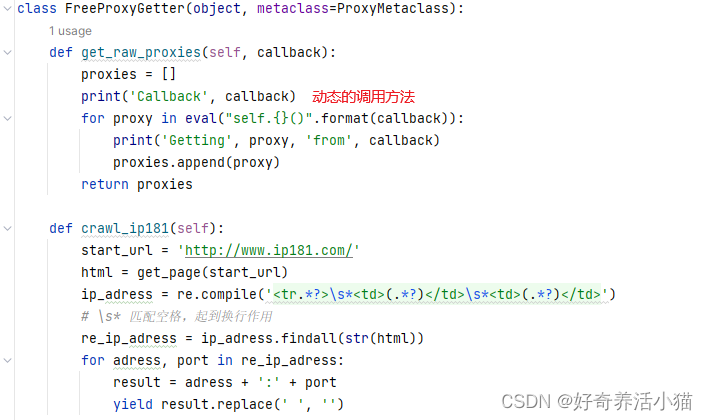
getter.py

添加属性,将方法名汇总起来。
crawl_的方法放入列表
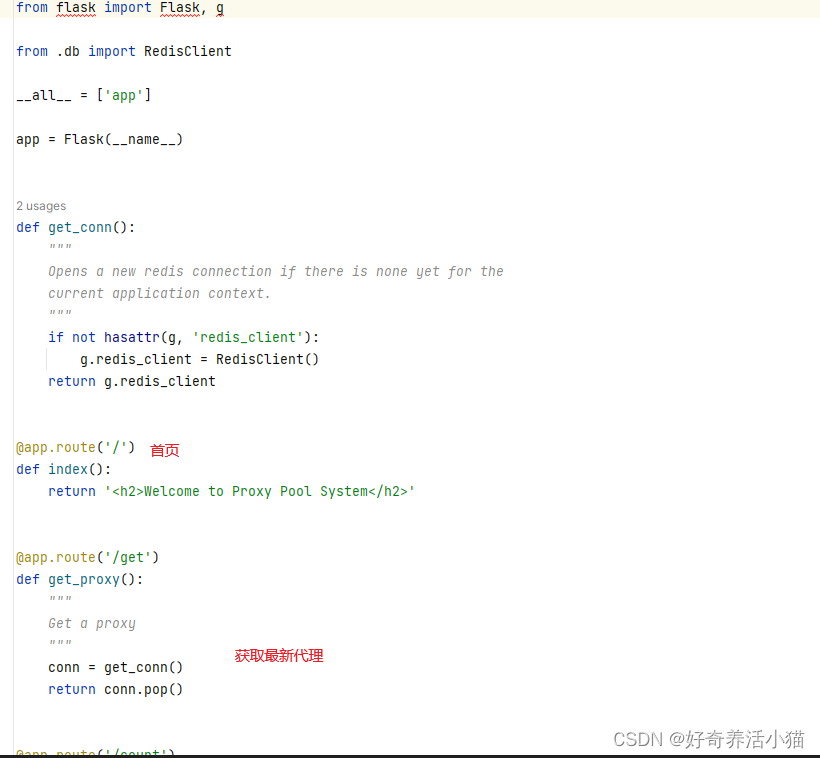
api.py
总结
动态获取方式和使用挺好玩的。

![[Vulnhub]靶场 Red](https://img-blog.csdnimg.cn/direct/908c0ef3ca7a40c38b753475fd84516d.png)