十一、
资源监控
1
、
free
内存监控
语 法:
free [-bkmotV][-s <
间隔秒数
>]
补充说明:
free
指令会显示内存的使用情况,包括实体内存,虚拟的交换文件内存,共享内存区段,以
及系统核心使用的缓冲区等。
参 数:
-b
以
Byte
为单位显示内存使用情况。
-k
以
KB
为单位显示内存使用情况。
-m
以
MB
为单位显示内存使用情况。
-o
不显示缓冲区调节列。
-s<
间隔秒数
>
持续观察内存使用状况。
-t
显示内存总和列。
-V
显示版本信息。

Mem:表示物理内存统计
-/+ buffers/cached:表示物理内存的缓存统计
Swap:表示硬盘上交换分区的使用情况
第 1 行 Mem: total:表示物理内存总量。
used:表示总计分配给缓存(包含 buffers 与 cache )使用的数量,但其中可能部分缓存并未实际使
用。
free:未被分配的内存。
shared:共享内存,一般系统不会用到,这里也不讨论。
buffers:系统分配但未被使用的 buffers 数量。
cached:系统分配但未被使用的 cache 数量。buffer 与 cache 的区别见后面。 total = used + free
第 2 行 -/+ buffers/cached: used:也就是第一行中的 used – buffers-cached 也是实际使用的内
存总量。
free:未被使用的 buffers 与 cache 和未被分配的内存之和,这就是系统当前实际可用内存。 free 2=
buffers1 + cached1 + free1 //free2 为第二行、buffers1 等为第一行
A buffer is something that has yet to be “written” to disk. A cache is something that has
been “read” from the disk and stored for later use 第 3 行: 第三行所指的是从应用程序角度
来看,对于应用程序来说,buffers/cached 是等于可用的,因为 buffer/cached 是为了提高文件读取
的性能,当应用程序需在用到内存的时候,buffer/cached 会很快地被回收。
所以从应用程序的角度来说,可用内存=系统 free memory+buffers+cached.
接下来解释什么时候内存会被交换,以及按什么方交换。
当可用内存少于额定值的时候,就会开会进行交换,如何看额定值(
RHEL4.0
):
#cat /proc/meminfo
交换将通过三个途径来减少系统中使用的物理页面的个数:
1.
减少缓冲与页面
cache
的大小,
2.
将系统
V
类型的内存页面交换出去,
3.
换出或者丢弃页面。
(Application
占用的内存页,也就是物理内存不足)。
事实上,少量地使用
swap
是不是影响到系统性能的。
下面是 buffers 与 cached 的区别:
buffers 是指用来给块设备做的缓冲大小,他只记录文件系统的 metadata 以及 tracking in-flight
pages.
cached 是用来给文件做缓冲。
那就是说:buffers 是用来存储,目录里面有什么内容,权限等等。
而 cached 直接用来记忆我们打开的文件 ,如果你想知道他是不是真的生效,你可以试一下,先后执行
两次命令#man X ,你就可以明显的感觉到第二次的开打的速度快很多。
实验:在一台没有什么应用的机器上做会看得比较明显。记得实验只能做一次,如果想多做请换一个文
件名。
#free
#man X
#free
#man X
#free
你可以先后比较一下 free 后显示 buffers 的大小。
另一个实验:
#free
#ls /dev
#free
你比较一下两个的大小,当然这个 buffers 随时都在增加,但你有 ls 过的话,增加的速度会变得快,
这个就是 buffers/chached 的区别。
因为 Linux 将你暂时不使用的内存作为文件和数据缓存,以提高系统性能,当你需要这些内存时,
系统会自动释放(不像 windows 那样,即使你有很多空闲内存,他也要访问一下磁盘中的 pagefiles)
使用 free 命令
将 used 的值减去 buffer 和 cache 的值就是你当前真实内存使用 ————– 对操作系统 来讲是
Mem 的参数.buffers/cached 都是属于被使用,所以它认为 free 只有 16936 .
对应用程序 来讲是(-/+ buffers/cach).buffers/cached 是等同可用的,因为 buffer/cached 是为 了
提高 程序执行的性能, 当程序使用内存时,buffer/cached 会很快地被使用。 所以,以应用来看看,
以(-/+ buffers/cache)的 free 和 used 为主.所以我们看这个就好了.另外告诉大家 一些常识.Linux
为了提高磁盘和内存存取效率, Linux 做了很多精心的设计, 除了对 dentry 进行缓存(用于 VFS,加速
文件路径名到 inode 的转换), 还采取了两种主要 Cache 方式:Buffer Cache 和 Page Cache。 前者针
对磁盘块的读写,后者针对文件 inode 的读写。这些 Cache 能有效缩短了 I/O 系统调用(比如
read,write,getdents)的时间。 记住内存是拿来用的,不是拿来看的. 不象 windows,无论你的真实物
理内存有多少,他都要拿硬盘交换 文件来读.这也就是 windows 为什么常常提示虚拟空间不足的原因.
你们想想,多无聊,在内存还有大部分 的时候,拿出一部分硬盘空间来充当内存.硬盘怎么会快过内存.
所以我们看 linux,只要不用 swap 的交换 空间,就不用担心自己的内存太少.如果常常 swap 用很多,可
能你就要考虑加物理内存了.这也是 linux 看 内存是否够用的标准哦
.
[root@scs-2 tmp]# free
total used free shared buffers cached
Mem: 3266180 3250004 16176 0 110652 2668236
-/+ buffers/cache: 471116 2795064
Swap: 2048276 80160 1968116
下面是对这些数值的解释:
total:
总计物理内存的大小。
used:
已使用多大。
free:
可用有多少。
Shared:
多个进程共享的内存总额。
Buffers/cached:
磁盘缓存的大小。
第三行
(-/+ buffers/cached):
used:
已使用多大。
free:
可用有多少。
第四行就不多解释了。
区别:第二行
(mem)
的
used/free
与第三行
(-/+ buffers/cache) used/free
的区别。 这两个的区别在于使用
的角度来看,第一行是从
OS
的角度来看,因为对于
OS
,
buffers/cached
都是属于被使用,所以他的可
用内存是
16176KB,
已用内存是
3250004KB,
其中包括,内核(
OS
)使用
+Application(X, oracle,etc)
使用的
+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,
buffers/cached
是等于可用的,因为
buffer/cached
是为了提高文件读取的性能,当应用程序需在用到内存的时候,
buffer/cached
会很快地被
回收。
所以从应用程序的角度来说,可用内存
=
系统
free memory+buffers+cached
。
如上例:
2795064=16176+110652+2668236
接下来解释什么时候内存会被交换,以及按什么方交换。 当可用内存少于额定值的时候,就会开会进
行交换。
如何看额定值:
cat /proc/meminfo
[root@scs-2 tmp]# cat /proc/meminfo
MemTotal: 3266180 kB
MemFree: 17456 kB
Buffers: 111328 kB
Cached: 2664024 kB
SwapCached: 0 kB
Active: 467236 kB
Inactive: 2644928 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 3266180 kB
LowFree: 17456 kB
SwapTotal: 2048276 kB
SwapFree: 1968116 kB
Dirty: 8 kB
Writeback: 0 kB
Mapped: 345360 kB
Slab: 112344 kB
Committed_AS: 535292 kB
PageTables: 2340 kB
VmallocTotal: 536870911 kB
VmallocUsed: 272696 kB
VmallocChunk: 536598175 kB
HugePages_Total: 0
HugePages_Free: 0
Hugepagesize: 2048 kB
用
free -m
查看的结果:
[root@scs-2 tmp]# free -m
total used free shared buffers cached
Mem: 3189 3173 16 0 107 2605
-/+ buffers/cache: 460 2729
Swap: 2000 78 1921
查看
/proc/kcore
文件的大小(内存镜像):
[root@scs-2 tmp]# ll -h /proc/kcore
-r-------- 1 root root 4.1G Jun 12 12:04 /proc/kcore
备注:
占用内存的测量
测量一个进程占用了多少内存,
linux
为我们提供了一个很方便的方法,
/proc
目录为我们提供了所有的
信息,实际上
top
等工具也通过这里来获取相应的信息。
/proc/meminfo
机器的内存使用信息
/proc/pid/maps pid
为进程号,显示当前进程所占用的虚拟地址。
/proc/pid/statm
进程所占用的内存
[root@localhost ~]# cat /proc/self/statm
654 57 44 0 0 334 0
输出解释
CPU
以及
CPU0
。。。的每行的每个参数意思(以第一行为例)为:
参数 解释
/proc//status
Size (pages)
任务虚拟地址空间的大小
VmSize/4
Resident(pages)
应用程序正在使用的物理内存的大小
VmRSS/4
Shared(pages)
共享页数
0
Trs(pages)
程序所拥有的可执行虚拟内存的大小
VmExe/4
Lrs(pages)
被映像到任务的虚拟内存空间的库的大小
VmLib/4
Drs(pages)
程序数据段和用户态的栈的大小 (
VmData+ VmStk
)
4
dt(pages) 04
查看机器可用内存
/proc/28248/>free
total used free shared buffers cached
Mem: 1023788 926400 97388 0 134668 503688
-/+ buffers/cache: 288044 735744
Swap: 1959920 89608 1870312
我们通过
free
命令查看机器空闲内存时,会发现
free
的值很小。这主要是因为,在
linux
中有这么一种
思想,内存不用白不用,因此它尽可能的
cache
和
buffer
一些数据,以方便下次使用。但实际上这些内
存也是可以立刻拿来使用的。
所以 空闲内存
=free+buffers+cached=total-used
2
、
vmstat
很显然从名字中我们就可以知道
vmstat
是一个查看虚拟内存(
Virtual Memory
)使用状况的工具,但
是怎样通过
vmstat
来发现系统中的瓶颈呢?在回答这个问题前,还是让我们回顾一下
Linux
中关于虚拟
内存相关内容。
2.1
、虚拟内存运行原理
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存
空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物
理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在
Linux
内存管理中,主要是通过“调页
Paging
”和“交换
Swapping
”来完成上述的内存调度。调页算
法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整
个进程,而不是部分页面,全部交换到磁盘上。
分页
(Page)
写入磁盘的过程被称作
Page-Out
,分页
(Page)
从磁盘重新回到内存的过程被称作
Page-In
。当
内核需要一个分页时,但发现此分页不在物理内存中
(
因为已经被
Page-Out
了
)
,此时就发生了分页错误
(
Page Fault
)。
当系统内核发现可运行内存变少时,就会通过
Page-Out
来释放一部分物理内存。经管
Page-Out
不是经
常发生,但是如果
Page-out
频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系
统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作
thrashing(
颠簸
)
。
2.2
、使用
vmstat
1.
用法
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
-a
:显示活跃和非活跃内存
-f
:显示从系统启动至今的
fork
数量 。
-m
:显示
slabinfo
-n
:只在开始时显示一次各字段名称。
-s
:显示内存相关统计信息及多种系统活动数量。
delay
:刷新时间间隔。如果不指定,只显示一条结果。
count
:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d
:显示磁盘相关统计信息。
-p
:显示指定磁盘分区统计信息
-S
:使用指定单位显示。参数有
k
、
K
、
m
、
M
,分别代表
1000
、
1024
、
1000000
、
1048576
字节(
byte
)。
默认单位为
K
(
1024 bytes
)
-V
:显示
vmstat
版本信息。
2.3
、实例
例子
1
:每
2
秒输出一条结果
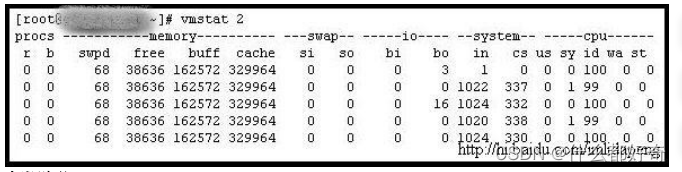
字段说明:
Procs
(进程):
r:
运行的和等待
(CPU
时间片
)
运行的进程数,这个值也可以判断是否需要增加
CPU(
长期大于
1)
b:
等待
IO
的进程数量,处于不可中断状态的进程数,常见的情况是由
IO
引起的
Memory
(内存):
swpd:
使用虚拟内存大小,切换到交换内存上的内存
(
默认以
KB
为单位
)
如果
swpd
的值不为
0
,或者还比较大,比如超过
100M
了,但是
si, so
的值长期为
0
,这种情况我
们可以不用担心,不会影响系统性能。
free:
空闲的物理内存
buff:
用作缓冲的内存大小
cache:
用作缓存的内存大小,文件系统的
cache
,如果
cache
的值大的时候,说明
cache
住的文件数
多,如果频繁访问到的文件都能被
cache
住,那么磁盘的读
IO bi
会非常小
Swap
:
si:
每秒从交换区写到内存的大小,交换内存使用,由磁盘调入内存
so:
每秒写入交换区的内存大小,交换内存使用,由内存调入磁盘
内存够用的时候,这
2
个值都是
0
,如果这
2
个值长期大于
0
时,系统性能会受到影响。磁盘
IO
和
CPU
资源都会被消耗。
常有人看到空闲内存
(free)
很少或接近于
0
时,就认为内存不够用了,实际上不能光看这一点的,还
要结合
si,so
,如果
free
很少,但是
si,so
也很少
(
大多时候是
0)
,那么不用担心,系统性能这时不会受
到影响的。
IO
:(现在的
Linux
版本块的大小为
1024bytes
)
bi:
每秒读取的块数,从块设备读入的数据总量
(
读磁盘
) (KB/s)
bo:
每秒写入的块数,写入到块设备的数据总理
(
写磁盘
) (KB/s)
随机磁盘读写的时候,这
2
个 值越大(如超出
1M
),能看到
CPU
在
IO
等待的值也会越大
system
:
in:
每秒中断数,包括时钟中断。
cs:
每秒上下文切换数。
上面这
2
个值越大,会看到由内核消耗的
CPU
时间会越多
CPU
(以百分比表示):
us:
用户进程消耗的
CPU
时间百分比,
us
的值比较高时,说明用户进程消耗的
CPU
时间多,但是如
果长期超过
50%
的使用,那么我们就该考虑优化程序算法或者进行加速了
sy:
内核进程消耗的
CPU
时间百分比,
sy
的值高时,说明系统内核消耗的
CPU
资源多,这并不是良
性的表现,我们应该检查原因。
id: CPU
处在空闲状态时间百分比
(
包括
IO
等待时间
)
wa: IO
等待消耗的
CPU
时间百分比,
wa
的值高时,说明
IO
等待比较严重,这可能是由于磁盘大量
作随机访问造成,也有可能是磁盘的带宽出现瓶颈
(
块操作
)
。
例子
2
:显示活跃和非活跃内存
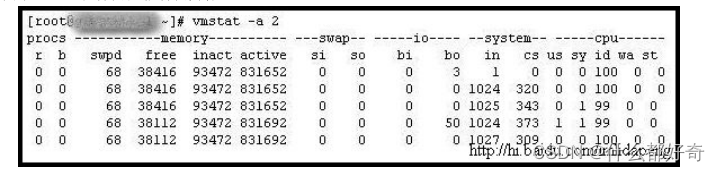
使用
-a
选项显示活跃和非活跃内存时,所显示的内容除增加
inact
和
active
外,其他显示内容与例子
1
相同。
字段说明:
Memory
(内存):
inact:
非活跃内存大小(当使用
-a
选项时显示)
active:
活跃的内存大小(当使用
-a
选项时显示)
注:如果
r
经常大于
4
,且
id
经常少于
40
,表示
cpu
的负荷很重,如果
bi
,
bo
长期不等于
0
,表示内
存不足,如果
disk
经常不等于
0
,且在
b
中的队列大于
3
,表示
io
性能不好。
CPU
问题现象:
1.)
如果在
processes
中运行的序列
(process r)
是连续的大于在系统中的
CPU
的个数表示系统现在运行比较
慢
,
有多数的进程等待
CPU.
2.)
如果
r
的输出数大于系统中可用
CPU
个数的
4
倍的话
,
则系统面临着
CPU
短缺的问题
,
或者是
CPU
的速
率过低
,
系统中有多数的进程在等待
CPU,
造成系统中进程运行过慢
.
3.)
如果空闲时间
(cpu id)
持续为
0
并且系统时间
(cpu sy)
是用户时间的两倍
(cpu us)
系统则面临着
CPU
资源
的短缺
.
解决办法
:
当发生以上问题的时候请先调整应用程序对
CPU
的占用情况
.
使得应用程序能够更有效的使用
CPU.
同
时可以考虑增加更多的
CPU.
关于
CPU
的使用情况还可以结合
mpstat, ps aux top prstat
–
a
等
等一些相应的命令来综合考虑关于具体的
CPU
的使用情况
,
和那些进程在占用大量的
CPU
时间
.
一般情
况下,应用程序的问题会比较大一些
.
比如一些
SQL
语句不合理等等都会造成这样的现象
.
内存问题现象
:
内存的瓶颈是由
scan rate (sr)
来决定的
.scan rate
是通过每秒的始终算法来进行页扫描的
.
如果
scan
rate(sr)
连续的大于每秒
200
页则表示可能存在内存缺陷
.
同样的如果
page
项中的
pi
和
po
这两栏表示每
秒页面的调入的页数和每秒调出的页数
.
如果该值经常为非零值
,
也有可能存在内存的瓶颈
,
当然
,
如果个
别的时候不为
0
的话
,
属于正常的页面调度这个是虚拟内存的主要原理
.
解决办法
:
1.
调节
applications & servers
使得对内存和
cache
的使用更加有效
.
2.
增加系统的内存
.
3. Implement priority paging in s in pre solaris 8 versions by adding line "set priority paging=1" in
/etc/system. Remove this line if upgrading from Solaris 7 to 8 & retaining old /etc/system file.
关于内存的使用情况还可以结
ps aux top prstat
–
a
等等一些相应的命令来综合考虑关于具体的内
存的使用情况
,
和那些进程在占用大量的内存
.
一般情况下,如果内存的占用率比较高
,
但是
,CPU
的占用
很低的时候
,
可以考虑是有很多的应用程序占用了内存没有释放
,
但是
,
并没有占用
CPU
时间
,
可以考虑
应用程序
,
对于未占用
CPU
时间和一些后台的程序
,
释放内存的占用
4.4
、案例
案例学习:
1
:在这个例子中
,
这个系统被充分利用
# vmstat 1
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy wa id
3 0 206564 15092 80336 176080 0 0 0 0 718 26 81 19 0 0
2 0 206564 14772 80336 176120 0 0 0 0 758 23 96 4 0 0
1 0 206564 14208 80336 176136 0 0 0 0 820 20 96 4 0 0
1 0 206956 13884 79180 175964 0 412 0 2680 1008 80 93 7 0 0
2 0 207348 14448 78800 175576 0 412 0 412 763 70 84 16 0 0
2 0 207348 15756 78800 175424 0 0 0 0 874 25 89 11 0 0
1 0 207348 16368 78800 175596 0 0 0 0 940 24 86 14 0 0
1 0 207348 16600 78800 175604 0 0 0 0 929 27 95 3 0 2
3 0 207348 16976 78548 175876 0 0 0 2508 969 35 93 7 0 0
4 0 207348 16216 78548 175704 0 0 0 0 874 36 93 6 0 1
4 0 207348 16424 78548 175776 0 0 0 0 850 26 77 23 0 0
2 0 207348 17496 78556 175840 0 0 0 0 736 23 83 17 0 0
0 0 207348 17680 78556 175868 0 0 0 0 861 21 91 8 0 1
根据观察值
,
我们可以得到以下结论:
1.
有大量的中断
(in)
和较少的上下文切换
(cs).
这意味着一个单一的进程在产生对硬件设备的请求
.
2.
进一步显示某单个应用
,user time(us)
经常在
85%
或者更多
.
考虑到较少的上下文切换
,
这个应用应该
还在处理器中被处理
.
3.
运行队列还在可接受的性能范围内
,
其中有
2
个地方
,
是超出了允许限制
.
2
:在这个例子中
,
内核调度中的上下文切换处于饱和
# vmstat 1
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy wa id
2 1 207740 98476 81344 180972 0 0 2496 0 900 2883 4 12 57 27
0 1 207740 96448 83304 180984 0 0 1968 328 810 2559 8 9 83 0
0 1 207740 94404 85348 180984 0 0 2044 0 829 2879 9 6 78 7
0 1 207740 92576 87176 180984 0 0 1828 0 689 2088 3 9 78 10
2 0 207740 91300 88452 180984 0 0 1276 0 565 2182 7 6 83 4
3 1 207740 90124 89628 180984 0 0 1176 0 551 2219 2 7 91 0
4 2 207740 89240 90512 180984 0 0 880 520 443 907 22 10 67 0
5 3 207740 88056 91680 180984 0 0 1168 0 628 1248 12 11 77 0
4 2 207740 86852 92880 180984 0 0 1200 0 654 1505 6 7 87 0
6 1 207740 85736 93996 180984 0 0 1116 0 526 1512 5 10 85 0
0 1 207740 84844 94888 180984 0 0 892 0 438 1556 6 4 90 0
根据观察值
,
我们可以得到以下结论:
1.
上下文切换数目高于中断数目
,
说明
kernel
中相当数量的时间都开销在上下文切换线程
.
2.
大量的上下文切换将导致
CPU
利用率分类不均衡
.
很明显实际上等待
io
请求的百分比
(wa)
非常高
,
以及
user time
百分比非常低
(us).
3.
因为
CPU
都阻塞在
IO
请求上
,
所以运行队列里也有相当数目的可运行状态线程在等待执行
.
3
、
iostat
用途:报告中央处理器(
CPU
)统计信息和整个系统、适配器、
tty
设备、磁盘和
CD-ROM
的输入/
输出统计信息。
语法:
iostat [ -c | -d ] [ -k ] [ -t | -m ] [ -V ] [ -x [ device ] ] [ interval [ count ] ]
描述:
iostat
命令用来监视系统输入/输出设备负载,这通过观察与它们的平均传送速率相关的物
理磁盘的活动时间来实现。
iostat
命令生成的报告可以用来更改系统配置来更好地平衡物理磁盘和适配
器之间的输入/输出负载。
参数:
-c
为汇报
CPU
的使用情况;
-d
为汇报磁盘的使用情况;
-k
表示每秒按
kilobytes
字节显示数据;
-m
表示每秒按
M
字节显示数据;
-t
为打印汇报的时间;
-v
表示打印出版本信息和用法;
-x device
指定
要统计的设备名称,默认为所有的设备;
interval
指每次统计间隔的时间;
count
指按照这个时间间隔统
计的次数。
iostat
结果解析
rrqm/s:
每秒进行
merge
的读操作数目。即
delta(rmerge)/s
wrqm/s:
每秒进行
merge
的写操作数目。即
delta(wmerge)/s
r/s:
每秒完成的读
I/O
设备次数。即
delta(rio)/s
w/s:
每秒完成的写
I/O
设备次数。即
delta(wio)/s
rsec/s:
每秒读扇区数。即
delta(rsect)/s
wsec/s:
每秒写扇区数。即
delta(wsect)/s
rkB/s:
每秒读
K
字节数。是
rsect/s
的一半,因为每扇区大小为
512
字节。
wkB/s:
每秒写
K
字节数。是
wsect/s
的一半。
avgrq-sz:
平均每次设备
I/O
操作的数据大小
(
扇区
)
。即
delta(rsect+wsect)/delta(rio+wio)
avgqu-sz:
平均
I/O
队列长度。即
delta(aveq)/s/1000 (
因为
aveq
的单位为毫秒
)
。
await:
平均每次设备
I/O
操作的等待时间
(
毫秒
)
。即
delta(ruse+wuse)/delta(rio+wio)
svctm:
平均每次设备
I/O
操作的服务时间
(
毫秒
)
。即
delta(use)/delta(rio+wio)
%util:
一秒中有百分之多少的时间用于
I/O
操作,或者说一秒中有多少时间
I/O
队列是非空的。即
delta(use)/s/1000 (
因为
use
的单位为毫秒
)
如果
%util
接近
100%
,说明产生的
I/O
请求太多,
I/O
系统已经满负荷,该磁盘可能存在瓶颈。
比较重要的参数
%util:
一秒中有百分之多少的时间用于
I/O
操作,或者说一秒中有多少时间
I/O
队列是非空的
svctm:
平均每次设备
I/O
操作的服务时间
await:
平均每次设备
I/O
操作的等待时间
avgqu-sz:
平均
I/O
队列长度
如果
%util
接近
100%,
表明
i/o
请求太多
,i/o
系统已经满负荷
,
磁盘可能存在瓶颈
,
一般
%util
大于
70%,i/o
压
力就比较大
,
读取速度有较多的
wait.
同时可以结合
vmstat
查看查看
b
参数
(
等待资源的进程数
)
和
wa
参数
(IO
等待所占用的
CPU
时间的百分比
,
高过
30%
时
IO
压力高
)
。
要理解这些性能指标我们先看下图
IO
的执行过程的各个参数
上图的左边是
iostat
显示的各个性能指标,每个性能指标都会显示在一条虚线之上,这表明这个性
能指标是从虚线之上的那个读写阶段开始计量的,比如说图中的
w/s
从
Linux IO scheduler
开始穿过硬盘
控制器
(CCIS/3ware)
,这就表明
w/s
统计的是每秒钟从
Linux IO scheduler
通过硬盘控制器的写
IO
的数量。
结合上图对读
IO
操作的过程做一个说明,在从
OS Buffer Cache
传入到
OS Kernel(Linux IO scheduler)
的读
IO
操作的个数实际上是
rrqm/s+r/s
,直到读
IO
请求到达
OS Kernel
层之后,有每秒钟有
rrqm/s
个
读
IO
操作被合并,最终转送给磁盘控制器的每秒钟读
IO
的个数为
r/w
;在进入到操作系统的设备层
(/dev/sda)
之后,计数器开始对
IO
操作进行计时,最终的计算结果表现是
await
,这个值就是我们要的
IO
响应时间了;
svctm
是在
IO
操作进入到磁盘控制器之后直到磁盘控制器返回结果所花费的时间,这
是一个实际
IO
操作所花的时间,当
await
与
svctm
相差很大的时候,我们就要注意磁盘的
IO
性能了;
而
avgrq-sz
是从
OS Kernel
往下传递请求时单个
IO
的大小,
avgqu-sz
则是在
OS Kernel
中
IO
请求队列的
平均大小。
现在我们可以将
iostat
输出结果和我们上面讨论的指标挂钩了
设备
IO
操作
:
总
IO(io)/s = r/s(
读
) +w/s(
写
) =1.46 + 25.28=26.74
平均每次设备
I/O
操作只需要
0.36
毫秒完成
,
现在却需要
10.57
毫秒完成,因为发出的请求太多
(
每秒
26.74
个
)
,假如请求时同时发出的,可以这样计算平均等待时间
:
平均等待时间
=
单个
I/O
服务器时间
*(1+2+...+
请求总数
-1)/
请求总数
每秒发出的
I/0
请求很多
,
但是平均队列就
4,
表示这些请求比较均匀
,
大部分处理还是比较及时
svctm
一般要小于
await (
因为同时等待的请求的等待时间被重复计算了
)
,
svctm
的大小一般和磁盘性
能有关,
CPU/
内存的负荷也会对其有影响,请求过多也会间接导致
svctm
的增加。
await
的大小一般
取决于服务时间
(svctm)
以及
I/O
队列的长度和
I/O
请求的发出模式。如果
svctm
比较接近
await
,
说明
I/O
几乎没有等待时间;如果
await
远大于
svctm
,说明
I/O
队列太长,应用得到的响应时间变
慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核
elevator
算
法,优化应用,或者升级
CPU
。
队列长度
(avgqu-sz)
也可作为衡量系统
I/O
负荷的指标,但由于
avgqu-sz
是按照单位时间的平均值,所
以不能反映瞬间的
I/O
洪水。
I/O
系统
vs.
超市排队
举一个例子,我们在超市排队
checkout
时,怎么决定该去哪个交款台呢
?
首当是看排的队人数,
5
个
人总比
20
人要快吧
?
除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星
期食品的大妈,那么可以考虑换个队排了。还有就是收银员的速度了,如果碰上了连钱都点不清楚的新
手,那就有的
等了。另外,时机也很重要,可能
5
分钟前还人满为患的收款台,现在已是人去楼空,这时候交款可
是很爽啊,当然,前提是那过去的
5
分钟里所做的事情比排队要有意义
(
不过我还没发现什么事情比
排队还无聊的
)
。
I/O
系统也和超市排队有很多类似之处
:
r/s+w/s
类似于交款人的总数
平均队列长度
(avgqu-sz)
类似于单位时间里平均排队人的个数
平均服务时间
(svctm)
类似于收银员的收款速度
平均等待时间
(await)
类似于平均每人的等待时间
平均
I/O
数据
(avgrq-sz)
类似于平均每人所买的东西多少
I/O
操作率
(
%
util)
类似于收款台前有人排队的时间比例。
我们可以根据这些数据分析出
I/O
请求的模式,以及
I/O
的速度和响应时间。
一个例子
# iostat -x 1
avg-cpu:
%
user
%
nice
%
sys
%
idle
16.24 0.00 4.31 79.44
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm
%
util
/dev/cciss/c0d0
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p1
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p2
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
上面的
iostat
输出表明秒有
28.57
次设备
I/O
操作
: delta(io)/s = r/s +w/s = 1.02+27.55 = 28.57 (
次
/
秒
)
其中写操作占了主体
(w:r = 27:1)
。
平均每次设备
I/O
操作只需要
5ms
就可以完成,但每个
I/O
请求却需要等上
78ms
,为什么
?
因为发
出的
I/O
请求太多
(
每秒钟约
29
个
)
,假设这些请求是同时发出的,那么平均等待时间可以这样计算
:
平均等待时间
=
单个
I/O
服务时间
* ( 1 + 2 + ... +
请求总数
-1) /
请求总数
应用到上面的例子
:
平均等待时间
= 5ms * (1+2+...+28)/29 = 70ms
,和
iostat
给出的
78ms
的平均等待
时间很接近。这反过来表明
I/O
是同时发起的。每秒发出的
I/O
请求很多
(
约
29
个
)
,平均队列却不
长
(
只有
2
个 左右
)
,这表明这
29
个请求的到来并不均匀,大部分时间
I/O
是空闲的。一秒中有
14.29
% 的时间
I/O
队列中是有请求的,也就是说,
85.71
% 的时间里
I/O
系统无事可做,所有
29
个
I/O
请求都在
142
毫秒之内处理掉了。
delta(ruse+wuse)/delta(io) = await = 78.21 => delta(ruse+wuse)/s =78.21 * delta(io)/s = 78.21*28.57 = 2232.8
,
表明每秒内的
I/O
请求总共需要等待
2232.8ms
。所以平均队列长度应为
2232.8ms/1000ms = 2.23
,而
iostat
给出的平均队列长度
(avgqu-sz)
却为
22.35
,为什么
?!
因为
iostat
中有
bug
,
avgqu-sz
值应为
2.23
,
而不是
22.35
。
4
、
uptime
uptime
命令用于查看服务器运行了多长时间以及有多少个用户登录,快速获知服务器的负荷情况。
uptime
的输出包含一项内容是
load average
,显示了最近
1
,
5
,
15
分钟的负荷情况。它的值代表等待
CPU
处理的进程数,如果
CPU
没有时间处理这些进程,
load average
值会升高;反之则会降低。
load average
的最佳值是
1
,说明每个进程都可以马上处理并且没有
CPU cycles
被丢失。对于单
CPU
的机器,
1
或者
2
是可以接受的值;对于多路
CPU
的机器,
load average
值可能在
8
到
10
之间。也可以使用
uptime
命
令来判断网络性能。例如,某个网络应用性能很低,通过运行
uptime
查看服务器的负荷是否很高,如
果不是,那么问题应该是网络方面造成的。
以下是
uptime
的运行实例:
9:24am up 19:06, 1 user, load average: 0.00, 0.00, 0.00
也可以查看
/proc/loadavg
和
/proc/uptime
两个文件,注意不能编辑
/proc
中的文件,要用
cat
等命令来查
看,如:
liyawei:~ # cat /proc/loadavg
0.0 0.00 0.00 1/55 5505
uptime
命令用法十分简单:直接输入
# uptime
例:
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
1
可以被认为是最优的负载值。负载是会随着系统不同改变得。单
CPU
系统
1-3
和
SMP
系统
6-10
都是
可能接受的。
另外还有一个参数
-V
,是用来查询版本的。
(
注意是大写的字母
v)
[linux @ localhost]$ uptime -V
procps version 3.2.7
[linux @ localhost]$ uptime
显示结果为:
10:19:04 up 257 days, 18:56, 12 users, load average: 2.10, 2.10,2.09
显示内容说明:
10:19:04 //
系统当前时间
up 257 days, 18:56 //
主机已运行时间
,
时间越大,说明你的机器越稳定。
12 user //
用户连接数,是总连接数而不是用户数
load average //
系统平均负载,统计最近
1
,
5
,
15
分钟的系统平均负载
那么什么是系统平均负载呢? 系统平均负载是指在特定时间间隔内运行队列中的平均进程数。如
果每个
CPU
内核的当前活动进程数不大于
3
的话,那么系统的性能是良好的。如果每个
CPU
内核的任
务数大于
5
,那么这台机器的性能有严重问题。如果你的
linux
主机是
1
个双核
CPU
的话,当
Load Average
为
6
的时候说明机器已经被充分使用了。
5
、
W
w
命令主要是查看当前登录的用户,这个命令相对来说比较简单。我们来看一下截图。

在上面这个截图里面呢,第一列
user
,代表登录的用户,第二列,
tty
代表用户登录的终端号,因为在
linux
中并不是只有一个终端的,
pts/2
代表是图形界面的第二个终端(这仅是个人意见,网上的对
pts
的看法可能有些争议)。第三列
FROM
代表登录的地方,如果是远程登录的,会显示
ip
地址,
:0
表示的
是
display 0:0
,意思就是主控制台的第一个虚拟终端。第四列
login@
代表登录的时间,第五列的
IDLE
代表系统的闲置时间。最后一列
what
是代表正在运行的进程,因为我正在运行
w
命令,所以咋
root
显示
w
。
5
、
mpstat
mpstat
(
RHEL5
默认不安装)
mpstat
是
MultiProcessor Statistics
的缩写,是实时系统监控工具。其报告与
CPU
的一些统计信息,
这些信息存放在
/proc/stat
文件中。在多
CPUs
系统里,其不但能查看所有
CPU
的平均状况信息,而且
能够查看特定
CPU
的信息。下面只介绍
mpstat
与
CPU
相关的参数,
mpstat
的语法如下:
mpstat [-P {|ALL}] [internal [count]]
参数的含义如下:
-P {|ALL}
表示监控哪个
CPU
,
cpu
在
[0,cpu
个数
-1]
中取值
internal
相邻的两次采样的间隔时间
count
采样的次数,
count
只能和
delay
一起使用
当没有参数时,
mpstat
则显示系统启动以后所有信息的平均值。有
interval
时,第一行的信息自系
统启动以来的平均信息。
从第二行开始,输出为前一个
interval
时间段的平均信息。与
CPU
有关的输出的含义如下:
[oracle@Test ~]$ mpstat -P ALL
Linux 2.6.18-194.el5 (Test.linux.com) 2010
年
06
月
22
日
09
时
18
分
18
秒
CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
09
时
18
分
18
秒
all 0.06 0.00 0.43 0.78 0.00 0.00 0.00 98.71 1069.35
09
时
18
分
18
秒
0 0.05 0.00 0.36 0.17 0.02 0.00 0.00 99.41 1032.01
09
时
18
分
18
秒
1 0.04 0.00 0.42 0.07 0.00 0.00 0.00 99.47 0.26
09
时
18
分
18
秒
2 0.11 0.00 0.28 0.08 0.00 0.00 0.00 99.52 0.00
09
时
18
分
18
秒
3 0.07 0.00 0.48 0.05 0.00 0.00 0.00 99.39 0.01
09
时
18
分
18
秒
4 0.08 0.00 0.19 5.63 0.00 0.02 0.00 94.08 24.51
09
时
18
分
18
秒
5 0.05 0.00 0.63 0.11 0.00 0.00 0.00 99.21 0.22
09
时
18
分
18
秒
6 0.07 0.00 0.45 0.10 0.00 0.01 0.00 99.36 12.33
09
时
18
分
18
秒
7 0.05 0.00 0.64 0.07 0.00 0.00 0.00 99.24 0.00
参数 解释 从
/proc/stat
获得数据
CPU
处理器
ID
user
在
internal
时间段里,用户的
CPU
时间(
%
) ,不包含
nice
值为负 进程
(usr/total)*100
nice
在
internal
时间段里,
nice
值为负进程的
CPU
时间(
%
)
(nice/total)*100
system
在
internal
时间段里,核心时间(
%
)
(system/total)*100
iowait
在
internal
时间段里,硬盘
IO
等待时间(
%
)
(iowait/total)*100
irq
在
internal
时间段里,硬中断时间(
%
)
(irq/total)*100
soft
在
internal
时间段里,软中断时间(
%
)
(softirq/total)*100
idle
在
internal
时间段里,
CPU
除去等待磁盘
IO
操作外的因为任何原因而空闲的时间闲置时间(
%
)
(idle/total)*100
intr/s
在
internal
时间段里,每秒
CPU
接收的中断的次数
intr/total)*100
CPU
总的工作时间
=total_cur=user+system+nice+idle+iowait+irq+softirq
total_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirq
user=user_cur – user_pre
total=total_cur-total_pre
其中
_cur
表示当前值,
_pre
表示
interval
时间前的值。上表中的所有值可取到两位小数点。
范例
1
:
average mode (
粗略信息
)
当
mpstat
不带参数时,输出为从系统启动以来的平均值。
[work@builder linux-2.6.14]$ mpstat
Linux 2.6.9-5.31AXsmp (builder.redflag-linux.com) 12/16/2005
09:38:46 AM CPU %user %nice %system %iowait %irq %soft %idle intr/s
09:38:48 AM all 23.28 0.00 1.75 0.50 0.00 0.00 74.47 1018.59
范例
2:
每
2
秒产生了
2
个处理器的统计数据报告
下面的命令可以每
2
秒产生了
2
个处理器的统计数据报告,一共产生三个
interval
的信息,然后再给出
这三个
interval
的平均信息。默认时,输出是按照
CPU
号排序。第一个行给出了从系统引导以来的所有
活跃数据。接下来每行对应一个处理器的活跃状态。
[root@server yum_dir]# mpstat -P ALL 2 3
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
09:34:20 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
09:34:22 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1001.49
09:34:22 PM 0 0.00 0.00 0.50 0.00 0.00 0.00 0.00 99.50 1001.00
09:34:22 PM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
09:34:22 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
09:34:24 PM all 0.00 0.00 0.25 0.00 0.00 0.00 0.00 99.75 1005.00
09:34:24 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1005.50
09:34:24 PM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
09:34:24 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
09:34:26 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1001.49
09:34:26 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1001.00
09:34:26 PM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
Average: all 0.00 0.00 0.08 0.00 0.00 0.00 0.00 99.92 1002.66
Average: 0 0.00 0.00 0.17 0.00 0.00 0.00 0.00 99.83 1002.49
Average: 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
范例
3
:比较带参数和不带参数的
mpstat
的结果。
在后台开一个
2G
的文件
# cat 1.img &
然后在另一个终端运行
mpstat
命令
[root@server ~]# cat 1.img &
[1] 6934
[root@server ~]# mpstat
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:31 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:31 PM all 0.07 0.02 0.25 0.21 0.01 0.04 0.00 99.40 1004.57
[root@server ~]# mpstat
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:35 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:35 PM all 0.07 0.02 0.25 0.21 0.01 0.04 0.00 99.39 1004.73
[root@server ~]# mpstat
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:39 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:39 PM all 0.07 0.02 0.25 0.21 0.01 0.04 0.00 99.38 1004.96
[root@server ~]# mpstat
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:44 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:44 PM all 0.07 0.02 0.26 0.21 0.01 0.05 0.00 99.37 1005.20
[root@server ~]# mpstat 3 10
Linux 2.6.18-164.el5 (server.sys.com) 01/04/2010
10:17:55 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:17:58 PM all 13.12 0.00 20.93 0.00 1.83 9.80 0.00 54.32 2488.08
10:18:01 PM all 10.82 0.00 19.30 0.83 1.83 9.32 0.00 57.90 2449.83
10:18:04 PM all 10.95 0.00 20.40 0.17 1.99 8.62 0.00 57.88 2384.05
10:18:07 PM all 10.47 0.00 18.11 0.00 1.50 8.47 0.00 61.46 2416.00
10:18:10 PM all 11.81 0.00 22.63 0.00 1.83 11.98 0.00 51.75 2210.60
10:18:13 PM all 6.31 0.00 10.80 0.00 1.00 5.32 0.00 76.58 1795.33
10:18:19 PM all 1.75 0.00 3.16 0.75 0.25 1.25 0.00 92.85 1245.18
10:18:22 PM all 11.94 0.00 19.07 0.00 1.99 8.29 0.00 58.71 2630.46
10:18:25 PM all 11.65 0.00 19.30 0.50 2.00 9.15 0.00 57.40 2673.91
10:18:28 PM all 11.44 0.00 21.06 0.33 1.99 10.61 0.00 54.56 2369.87
Average: all 9.27 0.00 16.18 0.30 1.50 7.64 0.00 65.11 2173.54
[root@server ~]#
上两表显示出当要正确反映系统的情况,需要正确使用命令的参数。
vmstat
和
iostat
也需要注意这一
问题。
6
、
pmap
pmap
命令可以显示进程的内存映射,使用这个命令可以找出造成内存瓶颈的原因。
# pmap -d PID
显示
PID
为
47394
进程的内存信息。
# pmap -d 47394
输出样例:
47394: /usr/bin/php-cgi
Address Kbytes Mode Offset Device Mapping
0000000000400000 2584 r-x-- 0000000000000000 008:00002 php-cgi
0000000000886000 140 rw--- 0000000000286000 008:00002 php-cgi
00000000008a9000 52 rw--- 00000000008a9000 000:00000 [ anon ]
0000000000aa8000 76 rw--- 00000000002a8000 008:00002 php-cgi
000000000f678000 1980 rw--- 000000000f678000 000:00000 [ anon ]
000000314a600000 112 r-x-- 0000000000000000 008:00002 ld-2.5.so
000000314a81b000 4 r---- 000000000001b000 008:00002 ld-2.5.so
000000314a81c000 4 rw--- 000000000001c000 008:00002 ld-2.5.so
000000314aa00000 1328 r-x-- 0000000000000000 008:00002 libc-2.5.so
000000314ab4c000 2048 ----- 000000000014c000 008:00002 libc-2.5.so
.....
......
00002af8d48fd000 4 rw--- 0000000000006000 008:00002 xsl.so
00002af8d490c000 40 r-x-- 0000000000000000 008:00002 libnss_files-2.5.so
00002af8d4916000 2044 ----- 000000000000a000 008:00002 libnss_files-2.5.so
00002af8d4b15000 4 r---- 0000000000009000 008:00002 libnss_files-2.5.so
00002af8d4b16000 4 rw--- 000000000000a000 008:00002 libnss_files-2.5.so
00002af8d4b17000 768000 rw-s- 0000000000000000 000:00009 zero (deleted)
00007fffc95fe000 84 rw--- 00007ffffffea000 000:00000 [ stack ]
ffffffffff600000 8192 ----- 0000000000000000 000:00000 [ anon ]
mapped: 933712K writeable/private: 4304K shared: 768000K
最后一行非常重要:
* mapped: 933712K
内存映射所占空间大小
* writeable/private: 4304K
私有地址空间大小
* shared: 768000K
共享地址空间大小
7
、
sar
sar
是一个优秀的一般性能监视工具,它可以输出
Linux
所完成的几乎所有工作的数据。
sar
命令在
sysetat rpm
中提供。示例中使用
sysstat
版本
5.0.5
,这是稳定的最新版本之一。关于版本和下载信息,
请访问
sysstat
主页
http://perso.wanadoo.fr/sebastien.godard/
。
sar
可以显示
CPU
、运行队列、磁盘
I/O
、分页(交换区)、内存、
CPU
中断、网络等性能数据。最重要
的
sar
功能是创建数据文件。每一个
Linux
系统都应该通过
cron
工作收集
sar
数据。该
sar
数据文件为
系统管理员提供历史性能信息。这个功能非常重要,它将
sar
和其他性能工具区分开。如果一个夜晚批
处理工作正常运行两次,直到下一个早上才会发现这种情况(除非被叫醒)。我们需要具备研究
12
小时
以前的性能数据的能力。
sar
数据收集器提供了这种能力。
sar
命令行的常用格式:
sar [options] [-A] [-o file] t [n]
在命令行中,
n
和
t
两个参数组合起来定义采样间隔和次数,
t
为采样间隔,是必须有的参数,
n
为采样次数,是可选的,默认值是
1
,
-o file
表示将命令结果以二进制格式存放在文件中,
file
在此处
不是关键字,是文件名。
options
为命令行选项,
sar
命令的选项很多,下面只列出常用选项:
-A
:所有报告的总和。
-u
:
CPU
利用率
-v
:进程、
I
节点、文件和锁表状态。
-d
:硬盘使用报告。
-r
:没有使用的内存页面和硬盘块。
-g
:串口
I/O
的情况。
-b
:缓冲区使用情况。
-a
:文件读写情况。
-c
:系统调用情况。
-R
:进程的活动情况。
-y
:终端设备活动情况。
-w
:系统交换活动。
7.1
、
CPU
统计数据
sar -u
输出显示
CPU
信息。
-u
选项是
sar
的默认选项。该输出以百分比显示
CPU
的使用情况。表
3-2
解释该输出。
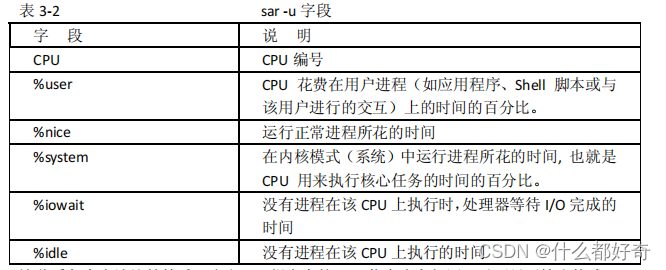
这些看起来应该比较熟悉,它和
top
报告中的
CPU
信息内容相同。以下显示输出格式:
[oracle@Test ~]$ sar -u -o aixi 60 5
Linux 2.6.18-194.el5 (Test.linux.com) 06/22/10
13:41:25 CPU %user %nice %system %iowait %steal %idle
13:42:25 all 0.28 0.00 0.21 1.17 0.00 98.34
13:43:25 all 0.23 0.00 0.16 1.14 0.00 98.46
13:44:25 all 0.27 0.00 0.21 1.40 0.00 98.12
13:45:25 all 0.26 0.00 0.19 0.99 0.00 98.56
13:46:25 all 0.32 0.00 0.23 1.39 0.00 98.05
Average: all 0.27 0.00 0.20 1.22 0.00 98.31
每
60
秒采样一次,连续采样
5
次,观察
CPU
的使用情况,并将采样结果以二进制形式存入当前目
录下的文件
aixi
中
在所有的显示中,我们应主要注意
%wio
和
%idle
,
%wio
的值过高,表示硬盘存在
I/O
瓶颈,
%idle
值高,表示
CPU
较空闲,如果
%idle
值高但系统响应慢时,有可能是
CPU
等待分配内存,此时应加大内
存容量。
%idle
值如果持续低于
10
,那么系统的
CPU
处理能力相对较低,表明系统中最需要解决的资源
是
CPU
。另外任何
sar
报告的第一列都是时间戳。
如果要查看二进制文件
aixi
中的内容,则需键入如下
sar
命令:
# sar -u -f aixi
可见,
sar
命令即可以实时采样,又可以对以往的采样结果进行查询。
我们本来可以研究使用
-f
选项通过
sadc
创建的文件。这个
sar
语法显示
sar -f/var/log/ sa/sa21
的输出:
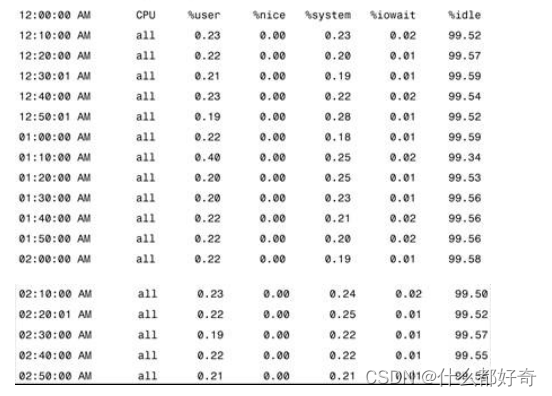
在多
CPU Linux
系统中,
sar
命令也可以为每个
CPU
分解该信息,如以下
sar -u -P ALL 5 5
输出所示:
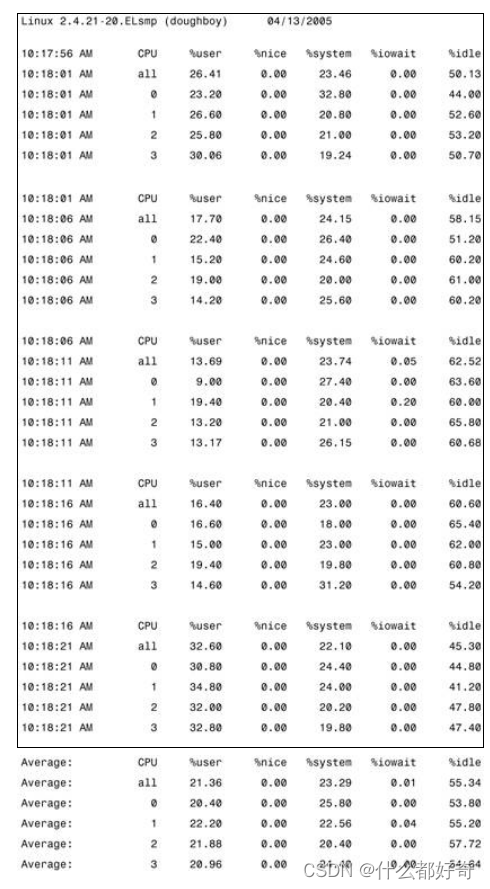
磁盘
I/O
统计数据
sar
是一个研究磁盘
I/O
的优秀工具。以下是
sar
磁盘
I/O
输出的一个示例。
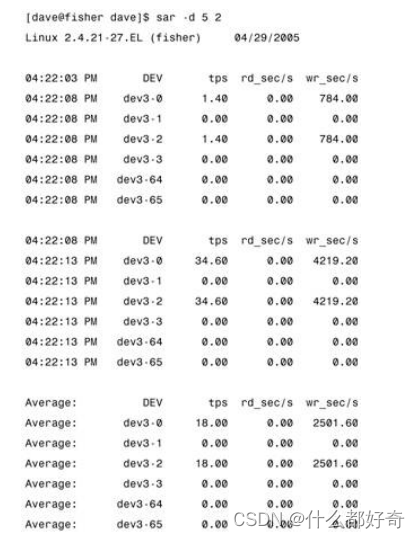
第一行
-d
显示磁盘
I/O
信息,
5 2
选项是间隔和迭代,就像
sar
数据收集器那样。表
3-3
列出了字段和说
明。
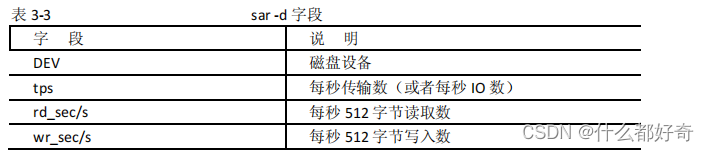
512
只是一个测量单位,不表示所有磁盘
I/O
均使用
512
字节块。
DEV
列是
dev#-#
格式的磁盘设备,其中
第一个
#
是设备主编号,第二个
#
是次编号或者连续编号。对于大于
2.5
的内核,
sar
使用次编号。例如,
在
sar -d
输出中看到的
dev3-0
和
dev3-1
。它们对应于
/dev/hda
和
/dev/hdal
。请看
/dev
中的以下各项:
/dev/hda
有主编号
3
和次编号
0
。
hda1
有主编号
3
和次编号
1
。
3.2.4
网络统计数据
sar
提供四种不同的语法选项来显示网络信息。
-n
选项使用四个不同的开关:
DEV
、
EDEV
、
SOCK
和
FULL
。
DEV
显示网络接口信息,
EDEV
显示关于网络错误的统计数据,
SOCK
显示套接字信息,
FULL
显示所有三
个开关。它们可以单独或者一起使用。表
3-4
显示通过
-n DEV
选项报告的字段。
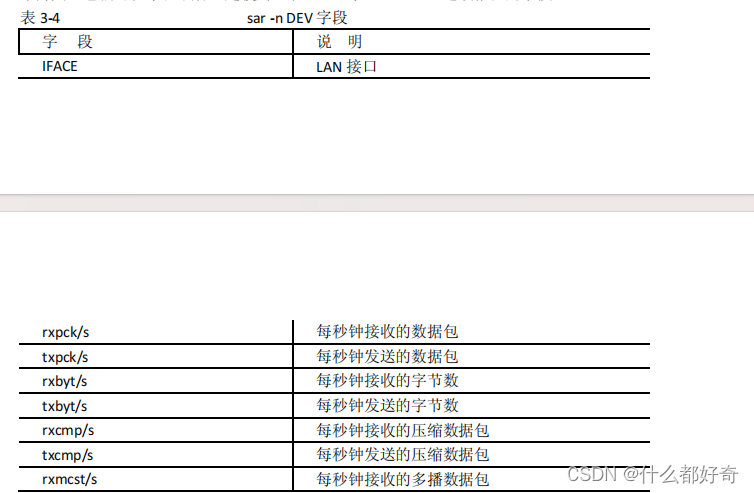
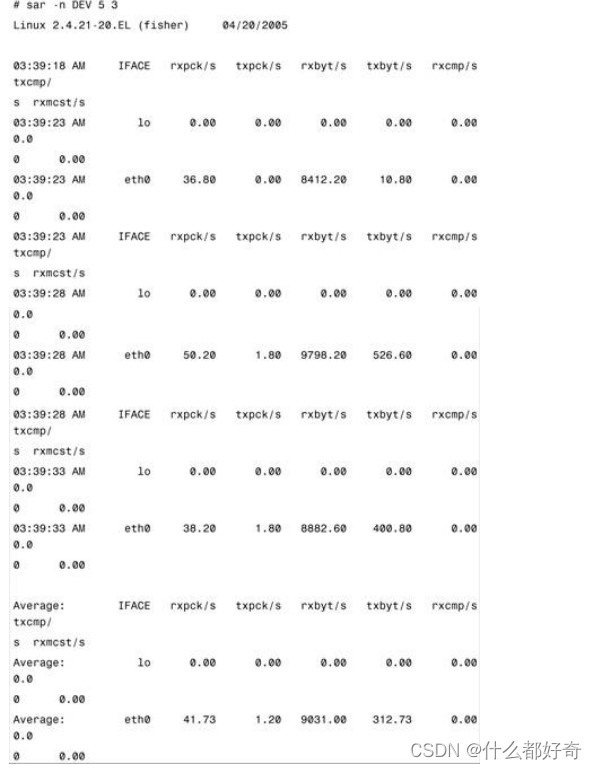
以下是使用
-n DEV
选项的
sar
输出:
关于网络错误的信息可以用 sar -n EDEV 显示。表 3-5 列出了显示的字段。
表 3-5 sar -n EDEV 字段

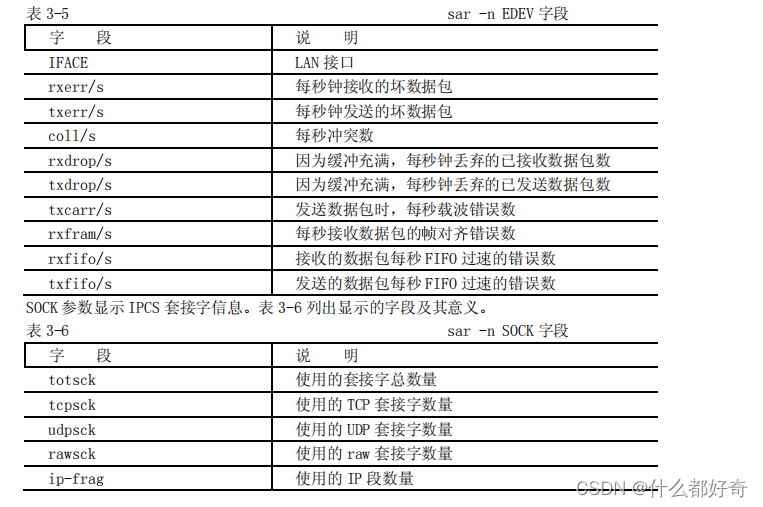
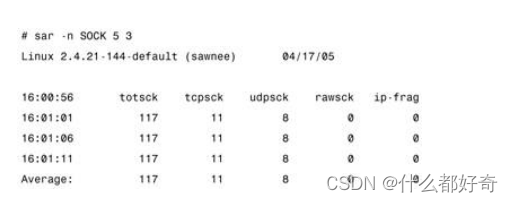
sar 可以产生许多其他报告。我们有必要仔细阅读 sar(1)手册页,查看是否有自己需要的其他报告
例二:使用命行 sar -v t n
例如,每 30 秒采样一次,连续采样 5 次,观察核心表的状态,需键入如下命令:
# sar -v 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
10:33:23 proc-sz ov inod-sz ov file-sz ov lock-sz (-v)
10:33:53 305/ 321 0 1337/2764 0 1561/1706 0 40/ 128
10:34:23 308/ 321 0 1340/2764 0 1587/1706 0 37/ 128
10:34:53 305/ 321 0 1332/2764 0 1565/1706 0 36/ 128
10:35:23 308/ 321 0 1338/2764 0 1592/1706 0 37/ 128
10:35:53 308/ 321 0 1335/2764 0 1591/1706 0 37/ 128
显示内容包括:
proc-sz:目前核心中正在使用或分配的进程表的表项数,由核心参数 MAX-PROC 控制。
inod-sz:目前核心中正在使用或分配的 i 节点表的表项数,由核心参数 MAX-INODE 控制。
file-sz: 目前核心中正在使用或分配的文件表的表项数,由核心参数 MAX-FILE 控制。
ov:溢出出现的次数。
Lock-sz:目前核心中正在使用或分配的记录加锁的表项数,由核心参数 MAX-FLCKRE 控制。
显示格式为
实际使用表项/可以使用的表项数
显示内容表示,核心使用完全正常,三个表没有出现溢出现象,核心参数不需调整,如果出现溢出
时,要调整相应的核心参数,将对应的表项数加大。
例三:使用命行 sar -d t n
例如,每 30 秒采样一次,连续采样 5 次,报告设备使用情况,需键入如下命令:
# sar -d 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
11:06:43 device %busy avque r+w/s blks/s avwait avserv (-d)
11:07:13 wd-0 1.47 2.75 4.67 14.73 5.50 3.14
11:07:43 wd-0 0.43 18.77 3.07 8.66 25.11 1.41
11:08:13 wd-0 0.77 2.78 2.77 7.26 4.94 2.77
11:08:43 wd-0 1.10 11.18 4.10 11.26 27.32 2.68
11:09:13 wd-0 1.97 21.78 5.86 34.06 69.66 3.35
Average wd-0 1.15 12.11 4.09 15.19 31.12 2.80
显示内容包括:
device: sar 命令正在监视的块设备的名字。
%busy: 设备忙时,传送请求所占时间的百分比。
avque: 队列站满时,未完成请求数量的平均值。
r+w/s: 每秒传送到设备或从设备传出的数据量。
blks/s: 每秒传送的块数,每块 512 字节。
avwait: 队列占满时传送请求等待队列空闲的平均时间。
avserv: 完成传送请求所需平均时间(毫秒)。
在显示的内容中,wd-0 是硬盘的名字,%busy 的值比较小,说明用于处理传送请求的有效时间太少,
文件系统效率不高,一般来讲,%busy 值高些,avque 值低些,文件系统的效率比较高,如果%busy 和
avque 值相对比较高,说明硬盘传输速度太慢,需调整。
例四:使用命行 sar -b t n
例如,每 30 秒采样一次,连续采样 5 次,报告缓冲区的使用情况,需键入如下命令:
# sar -b 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
14:54:59 bread/s lread/s %rcache bwrit/s lwrit/s %wcache pread/s pwrit/s (-b)
14:55:29 0 147 100 5 21 78 0 0
14:55:59 0 186 100 5 25 79 0 0
14:56:29 4 232 98 8 58 86 0 0
14:56:59 0 125 100 5 23 76 0 0
14:57:29 0 89 100 4 12 66 0 0
Average 1 156 99 5 28 80 0 0
显示内容包括:
bread/s: 每秒从硬盘读入系统缓冲区 buffer 的物理块数。
lread/s: 平均每秒从系统 buffer 读出的逻辑块数。
%rcache: 在 buffer cache 中进行逻辑读的百分比。
bwrit/s: 平均每秒从系统 buffer 向磁盘所写的物理块数。
lwrit/s: 平均每秒写到系统 buffer 逻辑块数。
%wcache: 在 buffer cache 中进行逻辑读的百分比。
pread/s: 平均每秒请求物理读的次数。
pwrit/s: 平均每秒请求物理写的次数。
在显示的内容中,最重要的是%cache 和%wcache 两列,它们的值体现着 buffer 的使用效率,%rcache
的值小于 90 或者%wcache 的值低于 65,应适当增加系统 buffer 的数量,buffer 数量由核心参数 NBUF
控制,使%rcache 达到 90 左右,%wcache 达到 80 左右。但 buffer 参数值的多少影响 I/O 效率,增加
buffer,应在较大内存的情况下,否则系统效率反而得不到提高。
例五:使用命行 sar -g t n
例如,每 30 秒采样一次,连续采样 5 次,报告串口 I/O 的操作情况,需键入如下命令:
# sar -g 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 11/22/2001
17:07:03 ovsiohw/s ovsiodma/s ovclist/s (-g)
17:07:33 0.00 0.00 0.00
17:08:03 0.00 0.00 0.00
17:08:33 0.00 0.00 0.00
17:09:03 0.00 0.00 0.00
17:09:33 0.00 0.00 0.00
Average 0.00 0.00 0.00
显示内容包括:
ovsiohw/s:每秒在串口 I/O 硬件出现的溢出。
ovsiodma/s:每秒在串口 I/O 的直接输入输出通道高速缓存出现的溢出。
ovclist/s :每秒字符队列出现的溢出。
在显示的内容中,每一列的值都是零,表明在采样时间内,系统中没有发生串口 I/O 溢出现象。
sar 命令的用法很多,有时判断一个问题,需要几个 sar 命令结合起来使用,比如,怀疑 CPU 存在
瓶颈,可用 sar -u 和 sar -q 来看,怀疑 I/O 存在瓶颈,可用 sar -b、sar -u 和 sar-d 来看。
--------------------------------------------------------------------------------
Sar
-A 所有的报告总和
-a 文件读,写报告
-B 报告附加的 buffer cache 使用情况
-b buffer cache 使用情况
-c 系统调用使用报告
-d 硬盘使用报告
-g 有关串口 I/O 情况
-h 关于 buffer 使用统计数字
-m IPC 消息和信号灯活动
-n 命名 cache
-p 调页活动
-q 运行队列和交换队列的平均长度
-R 报告进程的活动
-r 没有使用的内存页面和硬盘块
-u CPU 利用率
-v 进程,i 节点,文件和锁表状态
-w 系统交换活动
-y TTY 设备活动
-a 报告文件读,写报告
sar –a 5 5
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/07/2002
11:45:40 iget/s namei/s dirbk/s (-a)
11:45:45 6 2 2
11:45:50 91 20 28
11:45:55 159 20 18
11:46:00 157 21 19
11:46:05 177 30 35
Average 118 18 20
iget/s 每秒由 i 节点项定位的文件数量
namei/s 每秒文件系统路径查询的数量
dirbk/s 每秒所读目录块的数量
*这些值越大,表明核心花在存取用户文件上的时间越多,它反映着一些程序和应用文件系统产生
的负荷。一般地,如果 iget/s 与 namei/s 的比值大于 5,并且 namei/s 的值大于 30,则说明文件系统
是低效的。这时需要检查文件系统的自由空间,看看是否自由空间过少。
-b 报告缓冲区(buffer cache)的使用情况
sar -b 2 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/07/2002
13:51:28 bread/s lread/s %rcache bwrit/s lwrit/s %wcache pread/s pwrit/s (-b)
13:51:30 382 1380 72 131 273 52 0 0
13:51:32 378 516 27 6 22 72 0 0
13:51:34 172 323 47 39 57 32 0 0
Average 310 739 58 58 117 50 0 0
bread/s 平均每秒从硬盘(或其它块设备)读入系统 buffer 的物理块数
lread/s 平均每秒从系统 buffer 读出的逻辑块数
%rcache 在 buffer cache 中进行逻辑读的百分比(即 100% - bread/lreads)
bwrit/s 平均每秒从系统 buffer 向磁盘(或其它块设备)所写的物理块数
lwrit/s 平均每秒写到系统 buffer 的逻辑块数
%wcache 在 buffer cache 中进行逻辑写的百分比(即 100% - bwrit/lwrit).
pread/sgu 平均每秒请求进行物理读的次数
pwrit/s 平均每秒请求进行物理写的次数
*所显示的内容反映了目前与系统 buffer 有关的读,写活。在所报告的数字中,最重要的是%rcache
和%wcache(统称为 cache 命中率)两列,它们具体体现着系统 buffer 的效率。衡量 cache 效率的标准
是它的命中率值的大小。
*如果%rcache 的值小于 90 或者%wcache 的值低于 65,可能就需要增加系统 buffer 的数量。如果
在系统的应用中,系统的 I/O 活动十分频繁,并且在内存容量配置比较大时,可以增加 buffer cache,
使%rcache 达到 95 左右,%wcache 达到 80 左右。
*系统 buffer cache 中,buffer 的数量由核心参数 NBUF 控制。它是一个要调的参数。系统中 buffer
数量的多少是影响系统 I/O 效率的瓶颈。要增加系统 buffer 数量,则要求应该有较大的内存配置。否
则一味增加 buffer 数量,势必减少用户进程在内存中的运行空间,这同样会导致系统效率下降。
-c 报告系统调用使用情况
sar -c 2 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/07/2002
17:02:42 scall/s sread/s swrit/s fork/s exec/s rchar/s wchar/s (-c)
17:02:44 2262 169 141 0.00 0.00 131250 22159
17:02:46 1416 61 38 0.00 0.00 437279 6464
17:02:48 1825 43 25 0.00 0.00 109397 42331
Average 1834 91 68 0.00 0.00 225975 23651
scall/s 每秒使用系统调用的总数。一般地,当 4~6 个用户在系统上工作时,每秒大约 30 个左右。
sread/s 每秒进行读操作的系统调用数量。
swrit/s 每秒进行写操作的系统调用数量。
fork/s 每秒 fork 系统调用次数。当 4~6 个用户在系统上工作时,每秒大约 0.5 秒左右。
exec/s 每秒 exec 系统调用次数。
rchar/s 每秒由读操作的系统调用传送的字符(以字节为单位)。
wchar/s 每秒由写操作的系统调用传送的字符(以字节为单位)。
*如果 scall/s 持续地大于 300,则表明正在系统中运行的可能是效率很低的应用程序。在比较典
型的情况下,进行读操作的系统调用加上进行写操作的系统调用之和,约是 scall 的一半左右。
-d 报告硬盘使用情况
sar -d 2 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/07/2002
17:27:49 device %busy avque r+w/s blks/s avwait avserv (-d)
17:27:51 ida-0 6.93 1.00 13.86 259.41 0.00 5.00
ida-1 0.99 1.00 17.33 290.10 0.00 0.57
17:27:53 ida-0 75.50 1.00 54.00 157.00 0.00 13.98
ida-1 9.50 1.00 12.00 75.00 0.00 7.92
17:27:55 ida-0 7.46 1.00 46.77 213.93 0.00 1.60
ida-1 17.41 1.00 57.71 494.53 0.00 3.02
Average ida-0 29.85 1.00 38.14 210.28 0.00 7.83
ida-1 9.29 1.00 29.02 286.90 0.00 3.20
device 这是 sar 命令正在监视的块设备的名字。
%busy 设备忙时,运行传送请求所占用的时间。这个值以百分比表示。
avque 在指定的时间周期内,没有完成的请求数量的平均值。仅在队列被占满时取这个值。
r+w/s 每秒传送到设备或者从设备传送出的数据量。
blks/s 每秒传送的块数。每块 512 个字节。
avwait 传送请求等待队列空闲的平均时间(以毫秒为单位)。仅在队列被占满时取这个值。
avserv 完成传送请求所需平均时间(以毫秒为单位)
*ida-0 和 ida-1 是硬盘的设备名字。在显示的内容中,如果%busy 的值比较小,说明用于处理传
送请求的有效时间太少,文件系统的效率不高。要使文件系统的效率得到优化,应使%busy 的数值相对
高一些,而 avque 的值应该低一些。
-g 报告有关串口 I/O 情况
sar -g 3 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/13/2002
11:10:09 ovsiohw/s ovsiodma/s ovclist/s (-g)
11:10:12 0.00 0.00 0.00
11:10:15 0.00 0.00 0.00
11:10:18 0.00 0.00 0.00
Average 0.00 0.00 0.00
ovsiohw/s 每秒在串囗 I/O 硬件出现的溢出。
ovsiodma/s 每秒在串囗 I/O 的直接输入,输出信道高速缓存出现的溢出。
ovclist/s 每秒字符队列出现的溢出。
-m 报告进程间的通信活动(IPC 消息和信号灯活动)情况
sar -m 4 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/13/2002
13:24:28 msg/s sema/s (-m)
13:24:32 2.24 9.95
13:24:36 2.24 21.70
13:24:40 2.00 36.66
Average 2.16 22.76
msg/s 每秒消息操作的次数(包括发送消息的接收信息)。
sema/s 每秒信号灯操作次数。
*信号灯和消息作为进程间通信的工具,如果在系统中运行的应用过程中没有使用它们,那么由
sar 命令报告的 msg 和 sema 的值都将等于 0.00。如果使用了这些工具,并且其中或者 msg/s 大于 100,
或者 sema/s 大于 100,则表明这样的应用程序效率比较低。原因是在这样的应用程序中,大量的时间
花费在进程之间的沟通上,而对保证进程本身有效的运行时间必然产生不良的影响。
-n 报告命名缓冲区活动情况
sar -n 4 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/13/2002
13:37:31 c_hits cmisses (hit %) (-n)
13:37:35 1246 71 (94%)
13:37:39 1853 81 (95%)
13:37:43 969 56 (94%)
Average 1356 69 (95%)
c_hits cache 命中的数量。
cmisses cache 未命中的数量。
(hit %) 命中数量/(命中数理+未命中数量)。
*不难理解,(hit %)值越大越好,如果它低于 90%,则应该调整相应的核心参数。
-p 报告分页活动
sar -p 5 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/13/2002
13:45:26 vflt/s pflt/s pgfil/s rclm/s (-p)
13:45:31 36.25 50.20 0.00 0.00
13:45:36 32.14 58.48 0.00 0.00
13:45:41 79.80 58.40 0.00 0.00
Average 49.37 55.69 0.00 0.00
vflt/s 每秒进行页面故障地址转换的数量(由于有效的页面当前不在内存中)。
pflt/s 每秒来自由于保护错误出现的页面故障数量(由于对页面的非法存,取引起的页面故障)。
pgfil/s 每秒通过”页—入”满足 vflt/s 的数量。
rclm/s 每秒由系统恢复的有效页面的数量。有效页面被增加到自由页面队列上。
*如果 vflt/s 的值高于 100,可能预示着对于页面系统来说,应用程序的效率不高,也可能分页
参数需要调整,或者内存配置不太合适。
-q 报告进程队列(运行队列和交换队列的平均长度)情况
sar -q 2 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/13/2002
14:25:50 runq-sz %runocc swpq-sz %swpocc (-q)
14:25:52 4.0 50
14:25:54 9.0 100
14:25:56 9.0 100
Average 7.3 100
runq-sz 准备运行的进程运行队列。
%runocc 运行队列被占用的时间(百分比)
swpq-sz 要被换出的进程交换队列。
%swpocc 交换队列被占用的时间(百分比)。
*如果%runocc 大于 90,并且 runq-sz 的值大于 2,则表明 CPU 的负载较重。其直接后果,可能使
系统的响应速度降低。如果%swpocc 大于 20,表明交换活动频繁,将严重导致系统效率下降。解决的办
法是加大内存或减少缓存区数量,从而减少交换及页—入,页—出活动。
-r 报告内存及交换区使用情况(没有使用的内存页面和硬盘块)
sar -r 2 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/14/2002
10:14:19 freemem freeswp availrmem availsmem (-r)
10:14:22 279729 6673824 93160 1106876
10:14:24 279663 6673824 93160 1106876
10:14:26 279661 6673824 93160 1106873
Average 279684 6673824 93160 1106875
freemem 用户进程可以使用的内存页面数,4KB 为一个页面。
freeswp 用于进程交换可以使用的硬盘盘块,512B 为一个盘块。
-u CPU 利用率
sar -u 2 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/14/2002
10:27:23 %usr %sys %wio %idle (-u)
10:27:25 2 3 8 88
10:27:27 3 3 5 89
10:27:29 0 0 0 100
Average 2 2 4 92
.
%usr cpu 处在用户模式下时间(百分比)
%sys cpu 处在系统模式下时间(百分比)
%wio cpu 等待输入,输出完成(时间百分比)
%idle cpu 空闲时间(百分比)
*在显示的内容中,%usr 和 %sys 这两个值一般情况下对系统无特别影响,%wio 的值不能太高,
如果%wio 的值过高,则 CPU 花在等待输入,输出上的时间太多,这意味着硬盘存在 I/O 瓶颈。如果%idle
的值比较高,但系统响应并不快,那么这有可能是 CPU 花时间等待分配内存引起的。%idle 的值可以较
深入帮助人们了解系统的性能,在这种情况上,%idle 的值处于 40~100 之间,一旦它持续低于 30,则
表明进程竟争的主要资源不是内存而是 CPU。
*在有大量用户运行的系统中,为了减少 CPU 的压力,应该使用智能多串卡,而不是非智能多串卡。
智能多串卡可以承担 CPU 的某些负担。
*此外,如果系统中有大型的作业运行,应该把它们合理调度,错开高峰,当系统相对空闲时再运
行。
-v 报告系统表的内容(进程,i 节点,文件和锁表状态)
sar -v 2 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/14/2002
10:56:46 proc-sz ov inod-sz ov file-sz ov lock-sz (-v)
10:56:48 449/ 500 0 994/4147 0 1313/2048 0 5/ 128
10:56:50 450/ 500 0 994/4147 0 1314/2048 0 5/ 128
10:56:52 450/ 500 0 994/4147 0 1314/2048 0 5/ 128
proc-sz 目前在核心中正在使用或分配的进程表的表项数
inod-sz 目前在核心中正在使用或分配的 i 节点表的表项数
file-sz 目前在核心中正在使用或分配的文件表的表项数
ov 溢出出现的次数
lock-sz 目前在核心中正在使用或分配的记录加锁的表项数
*除 ov 外,均涉及到 unix 的核心参数,它们分别受核心参数 NPROC,NIMODE,NFILE 和 FLOCKREC
的控制。
*显示格式为:
实际使用表项/整个表可以使用的表项数
比如,proc-sz 一列所显示的四个数字中,分母的 100 是系统中整个进程表的长度(可建立 100 个
表项),分子上的 24,26 和 25 分别是采样的那一段时间所使用的进程表项。inod-sz,file-sz 和 lock-sz
三列数字的意义也相同。
三列 ov 的值分别对应进程表,i 节点表和文件表,表明目前这三个表都没有出现溢出现象,当出
现溢出时,需要调整相应的核心参数,将对应表加大。
-w 系统交换活动
sar -w 2 3
SCO_SV scosvr 3.2v5.0.5 PentII(D)ISA 06/14/2002
11:22:05 swpin/s bswin/s swpot/s bswots pswch/s (-w)
11:22:07 0.00 0.0 0.00 0.0 330
11:22:09 0.00 0.0 0.00 0.0 892
11:22:11 0.00 0.0 0.00 0.0 1053
Average 0.00 0.0 0.00 0.0 757
swpin/s 每秒从硬盘交换区传送进入内存的次数。
bswin/s 每秒为换入而传送的块数。
swpot/s 每秒从内存传送到硬盘交换区的次数。
bswots 每秒为换出而传送的块数。
pswch/s 每秒进程交换的数量。
*swpin/s,bswin/s,swpot/s 和 bswots 描述的是与硬盘交换区相关的交换活动。交换关系到系
统的效率。交换区在硬盘上对硬盘的读,写操作比内存读,写慢得多,因此,为了提高系统效率就应该
设法减少交换。通常的作法就是加大内存,使交换区中进行的交换活动为零,或接近为零。如果 swpot/s
的值大于 1,预示可能需要增加内存或减少缓冲区(减少缓冲区能够释放一部分自由内存空间)。
8
、
proc
文件系统
"proc 文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为
访问系统内核数据的操作提供接口。用户和应用程序可以通过 proc 得到系统的信息,并可以改变内核
的某些参数。"
这里将介绍如何从/proc 文件系统中获取与防火墙相关的一些性能参数,以及如何通过/proc 文件系统
修改内核的相关配置。
1、从/proc 文件系统获取相关的性能参数
cpu 使用率:/proc/stat
内存使用情况: /proc/meminfo
网络负载信息:/proc/net/dev
相应的计算方法:(摘自:什么是 proc 文件系统)
(1) 处理器使用率
(2) 内存使用率
(3) 流入流出数据包
(4) 整体网络负载
这些数据分别要从/proc/stat、/proc/net/dev、/proc/meminfo 三个文件中提取。如里有问题或对要
提取的数据不太清楚,可以使用 man proc 来查看 proc 文件系统的联机手册。
(1) 处理器使用率
这里要从/proc/stat 中提取四个数据:用户模式(user)、低优先级的用户模式(nice)、内核模式(system)
以及空闲的处理器时间(idle)。它们均位于/proc/stat 文件的第一行。CPU 的利用率使用如下公式来
计算。
CPU 利用率 = 100 *(user + nice + system)/(user + nice + system +
idle)
(2) 内存使用率
这里需要从/proc/meminfo 文件中提取两个数据,当前内存的使用量(cmem)以及内存总量(amem)。
内存使用百分比 = 100 * (cmem / umem)
(3)网络利用率
为了得到网络利用率的相关数据,需要从/proc/net/dev 文件中获得两个数据:从本机输出的数据包数,
流入本机的数据包数。它们都位于这个文件的第四行。
性能收集程序开始记录下这两个数据的初始值,以后每次获得这个值后均减去这个初始值即为从集群启
动开始从本节点通过的数据包。
利用上述数据计算出网络的平均负载,方法如下:
平均网络负载 = (输出的数据包+流入的数据包) / 2
2. 通过/proc 文件系统调整相关的内核配置
允许 ip 转发 /proc/sys/net/ipv4/ip_forward
禁止 ping/proc/sys/net/ipv4/icmp_echo_ignore_all
可以在命令行下直接往上述两个“文件”里头写入"1"来实现相关配置,如果写入"0"将取消相关配置。
不过在系统重启以后,这些配置将恢复默认设置,所以,如果想让这些修改生效,可以把下面的配置直
接写入/etc/profile 文件,或者其他随系统启动而执行的程序文件中。
1.echo 1 > /proc/sys/net/ipv4/ip_forward
2.echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
如果需要获取其他的性能参数,或者需要对内核进行更多的配置,可以参考 proc 文件系统介绍,也可
以直接通过 man proc 查看相关的信息。