专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!!
一、改进点介绍
AKConv是一种具有任意数量的参数和任意采样形状的可变卷积核,对不规则特征有更好的提取效果。
RepNCSPELAN4是YOLOv9中的特征提取模块,类似YOLOv5和v8中的C2f与C3模块。
二、RepNCSPELAN4-AKConv模块详解
2.1 模块简介
RepNCSPELAN4-AKConv的主要思想: 使用AKConv替换RepNCSPELAN4中的Conv模块。
三、 RepNCSPELAN4-AKConv模块使用教程
3.1 RepNCSPELAN4-AKConv模块的代码
class RepNCSP_AKConv(RepNCSP):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.cv1 = AKConv(c1, c_)
self.cv2 = AKConv(c1, c_)
self.cv3 = AKConv(2 * c_, c2) # optional act=FReLU(c2)
self.m = nn.Sequential(*(RepNBottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
class RepNCSPELAN4AKConv1(RepNCSPELAN4):
def __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__(c1, c2, c3, c4, c5)
self.cv1 = AKConv(c1, c3)
self.cv2 = nn.Sequential(RepNCSP_AKConv(c3//2, c4, c5), Conv(c4, c4, 3, 1))
self.cv3 = nn.Sequential(RepNCSP_AKConv(c4, c4, c5), Conv(c4, c4, 3, 1))
self.cv4 = AKConv(c3+(2*c4), c2)
from einops import rearrange
class AKConv(nn.Module):
def __init__(self, inc, outc, num_param=5, stride=1):
"""
初始化参数说明:
inc: 输入通道数, outc: 输出通道数, num_param:(卷积核)参数量, stride = 1:卷积步长默认为1, bias = None:默认无偏执
"""
super(AKConv, self).__init__()
self.num_param = num_param
self.stride = stride
self.conv = Conv(inc, outc, k=(num_param, 1), s=(num_param, 1) )
self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_full_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
# N is num_param.
offset = self.p_conv(x)
dtype = offset.data.type()
N = offset.size(1) // 2
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# resampling the features based on the modified coordinates.
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# bilinear
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
x_offset = self._reshape_x_offset(x_offset, self.num_param)
out = self.conv(x_offset)
return out
# generating the inital sampled shapes for the AKConv with different sizes.
def _get_p_n(self, N, dtype):
base_int = round(math.sqrt(self.num_param))
row_number = self.num_param // base_int
mod_number = self.num_param % base_int
p_n_x, p_n_y = torch.meshgrid(
torch.arange(0, row_number),
torch.arange(0, base_int), indexing='xy')
p_n_x = torch.flatten(p_n_x)
p_n_y = torch.flatten(p_n_y)
if mod_number > 0:
mod_p_n_x, mod_p_n_y = torch.meshgrid(
torch.arange(row_number, row_number + 1),
torch.arange(0, mod_number), indexing='xy')
mod_p_n_x = torch.flatten(mod_p_n_x)
mod_p_n_y = torch.flatten(mod_p_n_y)
p_n_x, p_n_y = torch.cat((p_n_x, mod_p_n_x)), torch.cat((p_n_y, mod_p_n_y))
p_n = torch.cat([p_n_x, p_n_y], 0)
p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)
return p_n
# no zero-padding
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(0, h * self.stride, self.stride),
torch.arange(0, w * self.stride, self.stride), indexing='xy')
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
# Stacking resampled features in the row direction.
@staticmethod
def _reshape_x_offset(x_offset, num_param):
b, c, h, w, n = x_offset.size()
x_offset = rearrange(x_offset, 'b c h w n -> b c (h n) w')
return x_offset3.2 在YOlO v9中的添加教程
阅读YOLOv9添加模块教程或使用下文操作
1. 将YOLOv9工程中models下common.py文件中的最下行(否则可能因类继承报错)增加模块的代码。
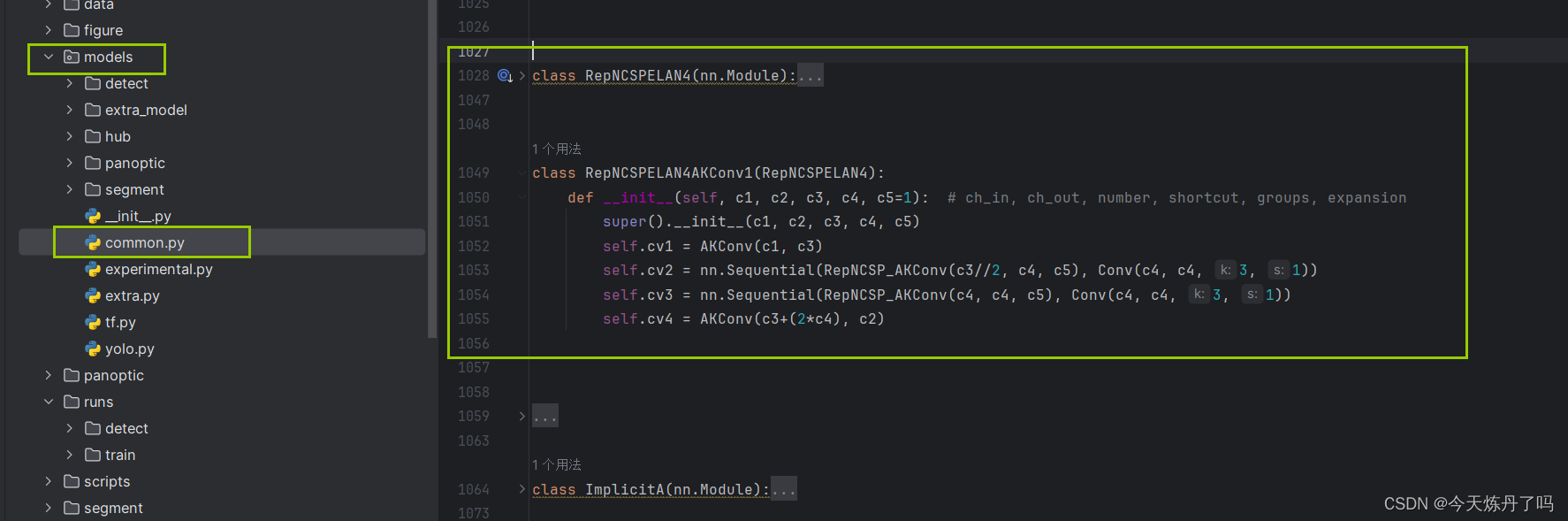
2. 将YOLOv9工程中models下yolo.py文件中的第681行(可能因版本变化而变化)增加以下代码。

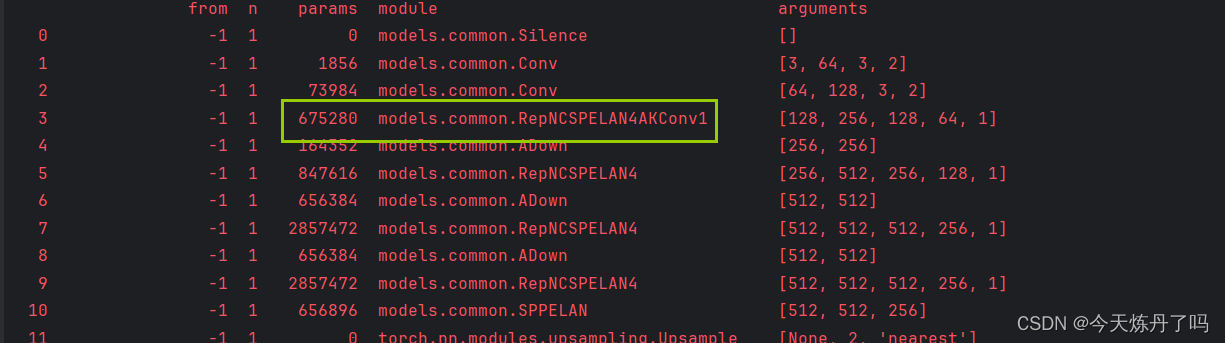
RepNCSPELAN4, SPPELAN, RepNCSPELAN4AKConv1}:3.3 运行配置文件
# YOLOv9
# Powered bu https://blog.csdn.net/StopAndGoyyy
# parameters
nc: 80 # number of classes
#depth_multiple: 0.33 # model depth multiple
depth_multiple: 1 # model depth multiple
#width_multiple: 0.25 # layer channel multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4AKConv1, [256, 128, 64, 1]], # 3
# avg-conv down
[-1, 1, ADown, [256]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
# avg-conv down
[-1, 1, ADown, [512]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
# avg-conv down
[-1, 1, ADown, [512]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
]
# YOLOv9 head
head:
[
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 10
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)
# avg-conv-down merge
[-1, 1, ADown, [256]],
[[-1, 13], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)
# avg-conv-down merge
[-1, 1, ADown, [512]],
[[-1, 10], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)
# multi-level reversible auxiliary branch
# routing
[5, 1, CBLinear, [[256]]], # 23
[7, 1, CBLinear, [[256, 512]]], # 24
[9, 1, CBLinear, [[256, 512, 512]]], # 25
# conv down
[0, 1, Conv, [64, 3, 2]], # 26-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 27-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28
# avg-conv down fuse
[-1, 1, ADown, [256]], # 29-P3/8
[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31
# avg-conv down fuse
[-1, 1, ADown, [512]], # 32-P4/16
[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34
# avg-conv down fuse
[-1, 1, ADown, [512]], # 35-P5/32
[[25, -1], 1, CBFuse, [[2]]], # 36
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37
# detection head
# detect
[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]
3.4 训练过程
欢迎关注!


![[Unity3d] 网络开发基础【个人复习笔记/有不足之处欢迎斧正/侵删】](https://img-blog.csdnimg.cn/direct/f8d1c73dfde143618e9e8074fd31067a.png)