都是负担在很多app上,当我们输入某些内容时候,它会立即做一些补全操作,
如果我想实现上述的需求,我们就可以使用ES提供的Suggesters Api。那Suggesters是如何做到的那?简单来说,Suggesters会将输入的文本拆分为token(token就是根据规则切分文本后一个个词),然后在索引里面查找相似的Term,根据使用场景不同,ES提供了以下4种Suggester:
- Term Suggester:基于单纯的纠错补全
- Phrase Suggester:基于短语的纠错补全
- Completion Suggester:自动补全单词,输入词语的前半部分,自动补全单词
- Context Suggester:基于上下文的补全提示,可以实现上下文感知推荐
Term Suggester
Term Suggester 提供了**基于单词的纠错、补全功能,其工作原理是基于编辑距离(edit distance)来运作的,编辑距离的核心思想就是一个词需要改变多少个字符就可以和另外一个词一致。所以如何一个词转换为原词所需要改动的字符数越少,它越有可能是最佳匹配。比如,**linux和linux,为了吧linux转变为linux需要改变一个字符“v”,所以其编辑距离为1
Term Suggester工作的时候,会将输入的文本切分成一个个单词(我们称之为token),然后根据每个单词提供建议,所以其不会考虑输入文本间各个单词的关系。
先来一个示例:

如上图所示:用户搜索了“kernel architture”,其中“architture”是错误的拼写。Suggester Api需要在“suggest”块中指定参数:
- “my_suggest”: 这个是我们自定义的名称
- “text”:指定了需要产生建议的文本,一般是用户的输入内容
- “term”: 表示使用的是Term Suggester Api,如果是Phrase Suggeseter用的是’phrase’
- “suggest_mode”: 设置建议的模式
- missing:如果索引中存在就不进行建议,默认
- popular: 推荐出现频率更高的词
- always:不管是否存在,都进行建议
- “field”: 指定从哪个文档上获取建议,上例中,是从书名(name)中获取建议
- “analyzer”: 指定分词器来对输入文本进行分词,默认与fileld指定的字段设置的分词器一样
- “size”: 为每个单词提供的最大建议数
- “sort”: 建议结果排序的方式,有以下两个选项
- score:先按相似性得分排序,然后按文档频率排序,最后按词项本身(字母顺序的等)排序。
- frequencry: 先按文档频率排序,然后按相似性得分排序,最后按词项本身排序
返回结果:
从返回结果可以看出,对于每个词语的建议结果,放在了 “options”数组中。如果一个词语有多个建议,那么就按照sort参数指定的方式进行排序。实例中,由于“kernel”这个词是存在的,并且 suggest_mode为“missing”,所以不进行建议,其options为空
Phrase Suggester
Term Suggester产生的建议是基于每个单词的,如果想要对整个短语或者一句话建议,Term Suggester就有点无能为力了,所以我们就会使用Phrase Suggester Api来获取与用户输入相似的内容
Phrase Suggester在Term Suggester的基础上增加了一些额外的逻辑,因为是短语形式的建议,所以会考量多个Term间的关系,比如相邻的程度、词频等。
下面是一个示例:
返回结果: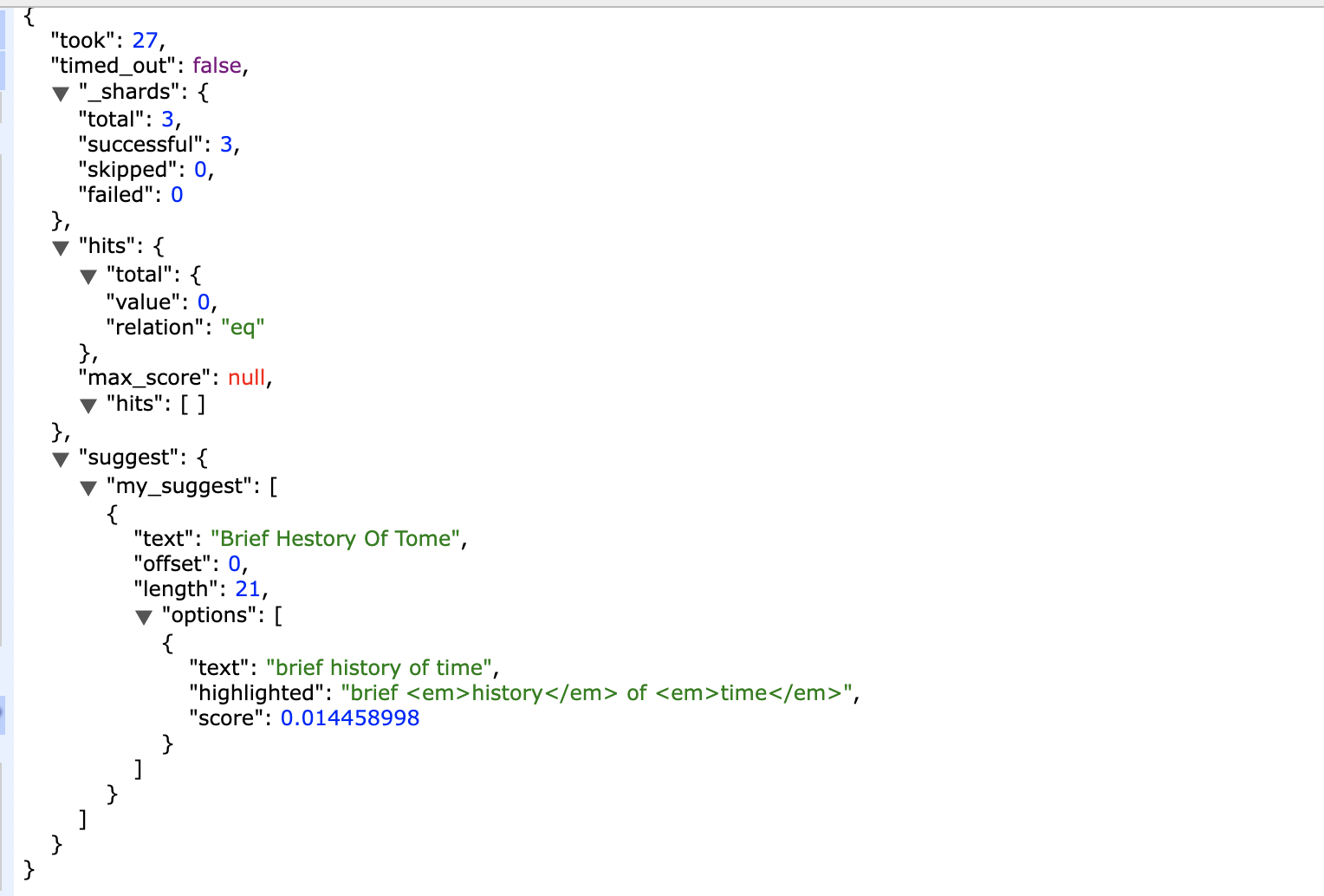
这个就比较简单,定义了使用Phrase使用的建议字段为name,返回结果里面options 返回了一个短语列表,并且因为“history”和“time”在一个文档里出现过,其可信度相对于其他来说更高,所以得分更高。因为我们使用“highlight”选项,所以返回结果中被替换的词语会高亮显示
Phrase Suggester还有其他一些参数:
- max_error:指定最多可以拼写错误的词语的个数
- confidence:其作用用来控制返回结果条数的,如果用户输入的数据的得分为N,那么返回结果的得分需要大于N * confidence。confidence默认值为1.0
- highlight:高亮后被修改后的词语
Completion Suggester
Completion Suggester提供了自动补全的功能,其应用场景是用户每输入一个字符就需要返回匹配的结果给用户。在并发量大、用户输入速度快的时候,对服务的吞吐量来说是个不小的挑战。所以Completion Suggester不能像上面的Suggester Api那样简单通过倒排索引实现,比如使用其他高效的数据结构和算法才能满足要求
Completion Suggester在实现的时候会将analyze(将文本分词,并且去除没用的词语,例如is、at这种词语)后的数据结构,构建为FST并且和索引存放在一起。FST(finite-state transducer)是一种高效的前缀查询索引,由于FST天生为前缀查询而生,所以其非常适合实现自动补全的功能。ES会将整个FST加载到内存中,所以在使用FST进行前缀查询的时候效率是非常高效的。
在使用Completion Suggester前需要定义Mapping,对应的字段需要使用“completion” type。下面我们来构建一个新的books_completion索引,其Mapping和测试数据如下:
PUT books_completion
{
"mappings": {
"properties": {
"book_id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "standard"
},
"name_completion": {
"type": "completion"
},
"author": {
"type": "keyword"
},
"intro": {
"type": "text"
},
"price": {
"type": "double"
},
"date": {
"type": "date"
}
}
},
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
PUT books_completion/_doc/1
{
"book_id": "4ee82462",
"name": "Dive into the Linux kernel architecture",
"name_completion": "Dive into the Linux kernel architecture",
"author": "Wolfgang Mauerer",
"intro": "The content is comprehensive and in-depth, appreciate the infinite scenery of the Linux kernel.",
"price": 19.9,
"date": "2010-06-01"
}
PUT books_completion/_doc/2
{
"book_id": "4ee82463",
"name": "A Brief History Of Time",
"name_completion": "A Brief History Of Time",
"author": "Stephen Hawking",
"intro": "A fascinating story that explores the secrets at the heart of time and space.",
"price": 9.9,
"date": "1988-01-01"
}
PUT books_completion/_doc/3
{
"book_id": "4ee82464",
"name": "Beginning Linux Programming 4th Edition",
"name_completion": "Beginning Linux Programming 4th Edition",
"author": "Neil Matthew、Richard Stones",
"intro": "Describes the Linux system and other UNIX-style operating system on the program development",
"price": 12.9,
"date": "2010-06-01"
}
来个示例:
返回结果: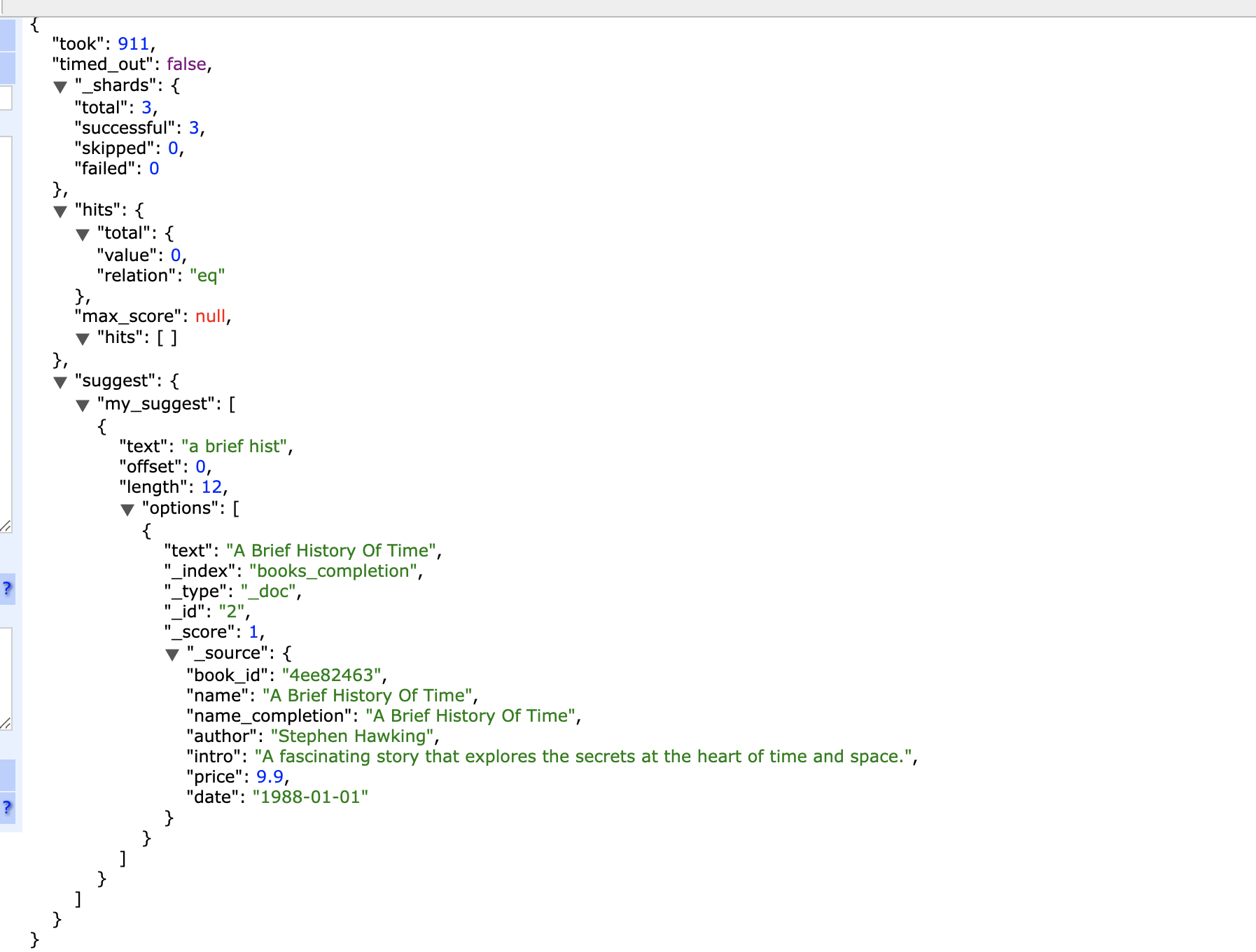
如上示例,在“my_suggest”中,“prefix”指定了需要匹配的前缀数据,“completion”中的“fileld”指定了需要匹配文档的哪个字段,返回结果中的“options”包含了整个文档的数据
需要注意的是,Completion Suggester在索引数据的时候经过了analyze阶段,所以使用不同的analyzer会造成构建FST的数据不同,例如某些词(is、at等)被去除、某些词被转换等。
Context Suggester
Context Suggster是Completion Suggeseter的扩展,可以实现上下文感知推荐。列入当我们在编程类型的数据中查询“liun”的时候,可以返回linux编程相关的书籍,但在任务自传类型的书籍中,将会返回linus的自传。要实现这个功能,可以在文档中加入分类信息,帮助我们做精准推荐
ES支持两种类型的上下文:
- Category:任意字符串的分类
- Geo:地理位置信息
下面我们看看如何基于任意字符串的分类来做上下文推荐。同样,在使用Context Suggester前,首先要创建mapping,然后在数据中加入相关的 Context 信息。下面是使用 Context Suggester 时的 Mapping:
#删除原来的索引
DELETE books_context
# 创建用于测试 Context Suggester 的索引
PUT books_context
{
"mappings": {
"properties": {
"book_id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "standard"
},
"name_completion": {
"type": "completion",
"contexts": [
{
"name": "book_type",
"type": "category"
}
]
},
"author": {
"type": "keyword"
},
"intro": {
"type": "text"
},
"price": {
"type": "double"
},
"date": {
"type": "date"
}
}
},
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
# 导入测试数据
PUT books_context/_doc/4
{
"book_id": "4ee82465",
"name": "Linux Programming",
"name_completion": {
"input": ["Linux Programming"],
"contexts": {
"book_type": "program"
}
},
"author": "Richard Stones",
"intro": "Happy to Linux Programming",
"price": 10.9,
"date": "2022-06-01"
}
PUT books_context/_doc/5
{
"book_id": "4ee82466",
"name": "Linus Autobiography",
"name_completion": {
"input": ["Linus Autobiography"],
"contexts": {
"book_type": "autobiography"
}
},
"author": "Linus",
"intro": "Linus Autobiography",
"price": 14.9,
"date": "2012-06-01"
}
如上所示的Mapping中,其中“name_completion”的类型还是为“completion”,在“context”中有2个字段,其中“type”为上下文的类型,就是上面说的Category和Geo,本例子中使用了Category。而“name”则为上下文的名称, 本例子为“book_type”
导入的数据中,“name_completion”中的“input”字段用于内容匹配。“book_type”的值有多个,“program”是编程类的,“autobiography”是自传类的
我们拿一个案例试一下;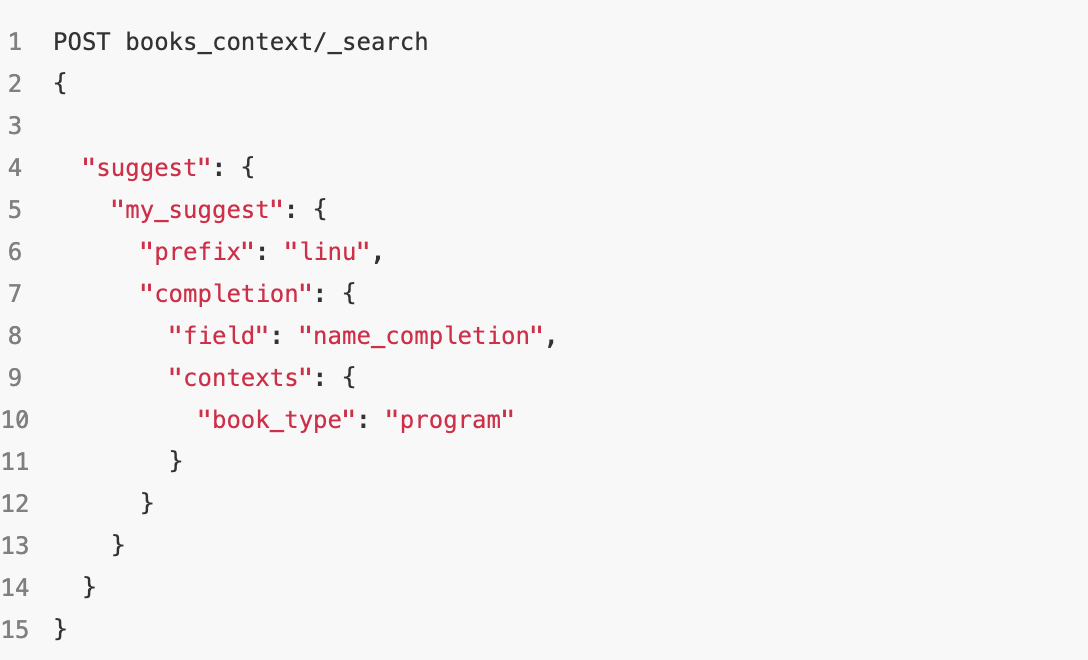
返回的结果数据:







![OSError: [WinError 1455] 页面文件太小,无法完成操作。](https://img-blog.csdnimg.cn/direct/a7b1f46f246d4ac6aff9716c792ef187.png)