基本输入输出函数
input 函数
input 函数用于从标准输入(如键盘)接收用户输入的字符串。当 input 函数被调用时,程序会暂停执行,等待用户输入文本并按回车键。用户输入的文本会作为字符串返回给程序。input 函数还可以接收一个字符串作为参数,这个字符串会在等待输入时显示,作为提示信息(prompt)。
示例:
name = input("请输入你的名字: ")
print(f"你好, {name}!")
上面的代码会显示提示信息“请输入你的名字: ”,等待用户输入他们的名字,并在用户按下回车键后打印欢迎信息。
eval 函数
eval 函数用于执行一个字符串表达式,并返回表达式的值。这个函数可以动态地运行代码,但也带来了安全风险,因为执行的代码可以是任何东西,包括有害代码。因此,除非绝对必要且来源可靠,否则不建议使用 eval。
示例:
x = eval("5 + 7")
print(x)
这段代码会计算字符串 "5 + 7" 表达的表达式,并打印结果 12。
print 函数
print 函数用于在屏幕上输出信息。它可以接受多个参数,并且可以通过关键字参数来定制分隔符(sep)、结束符(end)。
示例:
print("Hello,", "world!", sep=" ", end="\n")
print("这是", "第二行。", sep=" ", end="\n")
这段代码首先打印 “Hello, world!”,然后打印 “这是 第二行。”。默认情况下,print 使用空格作为分隔符和换行符作为结束符,但这里我们显式地指定了它们,虽然它们是默认值。
综合示例
# 用户输入
user_input = input("请输入一个算术表达式: ")
# 计算并打印结果
result = eval(user_input)
print("计算结果为:", result)
format格式化
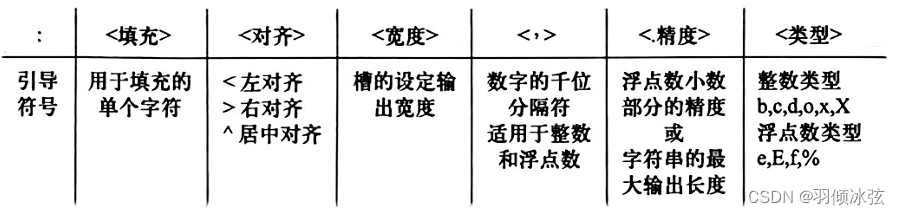
-
<冒号:>:这是分隔符,用来标示格式化表达式的开始。在冒号之前,可以有字段名或索引,它指示了要格式化的值;冒号后面是格式指定符,它告诉Python如何格式化值。 -
<填充>:这是一个可选的部分,用来指定一个字符,该字符将用于填充格式化的字符串。如果省略,通常空格字符会被用作填充。 -
<对齐>:有三种对齐方式:<(左对齐)、>(右对齐) 和^(居中对齐)。根据这个字符,格式化的文本将在指定宽度内按照相应方式对齐。 -
<宽度>:这是一个整数值,用来指定最小字段宽度。如果要格式化的文本比这个宽度短,将使用<填充>指定的字符填充到这个宽度。 -
<,>:这是一个可选的千位分隔符,用来为数字添加千位分隔,增加数字的可读性。 -
<精度>:用于浮点数和字符串,指定小数点后的位数或者字符串的最大长度。对于浮点数,它是小数点后的数字数量;对于字符串,它是要包含的最大字符数。 -
<类型>:指定了要格式化的值的类型。常见的类型包括b(二进制)、c(字符)、d(十进制整数)、o(八进制)、x(十六进制小写)、X(十六进制大写)、e(科学计数法小写)、E(科学计数法大写)、f(固定点数小数)、%(百分比格式)。
# 数字格式化:千位分隔符,保留两位小数,右对齐,总宽度为10
formatted_number = "{:>,.2f}".format(1234567.89)
# 字符串格式化:最大宽度为8,左对齐
formatted_string = "{:<8.8}".format("Hello World")
print(formatted_number) # 输出: '1,234,567.89'
print(formatted_string) # 输出: 'Hello Wo'
在数字格式化中,> 表示右对齐,, 是千位分隔符,.2f 是保留两位小数的固定点数格式。
在字符串格式化中,< 表示左对齐,8.8 表示最大字段宽度为8,最多使用8个字符。
字符串常用操作方法
-
str.lower()
- 描述:将字符串中的所有大写字母转换为小写字母。
- 例子:
text = "Python Programming" lower_text = text.lower() print(lower_text) # 输出: python programming
-
str.upper()
- 描述:将字符串中的所有小写字母转换为大写字母。
- 例子:
text = "Python Programming" upper_text = text.upper() print(upper_text) # 输出: PYTHON PROGRAMMING
-
str.split(sep=None)
- 描述:按照
sep指定的分隔符拆分字符串,如果没有指定sep,默认分隔符是空白字符(包括空格、换行'\n'、制表符'\t'等)。 - 例子:
text = "apple, banana, cherry" split_text = text.split(", ") print(split_text) # 输出: ['apple', 'banana', 'cherry']
- 描述:按照
-
str.count(sub)
- 描述:返回子串
sub在字符串中出现的次数。 - 例子:
text = "hello world" count_l = text.count('l') print(count_l) # 输出: 3
- 描述:返回子串
-
str.replace(old, new)
- 描述:将字符串中的
old子串替换为new。 - 例子:
text = "hello world" replaced_text = text.replace("world", "Python") print(replaced_text) # 输出: hello Python
- 描述:将字符串中的
-
str.center(width, fillchar)
- 描述:将字符串居中对齐,并使用
fillchar填充至宽度width。 - 例子:
text = "hello" centered_text = text.center(20, '*') print(centered_text) # 输出: *******hello********
- 描述:将字符串居中对齐,并使用
-
str.strip(chars)
- 描述:从字符串的开始和结束处删除
chars指定的字符集合。如果没有指定chars,默认删除空白字符。 - 例子:
text = " hello world " stripped_text = text.strip() print(stripped_text) # 输出: hello world
- 描述:从字符串的开始和结束处删除
-
str.join(iter)
- 描述:将
iter中的每个元素连接起来,每个元素之间用字符串str作为分隔。 - 例子:
words = ["Python", "Programming", "Is", "Fun"] joined_text = " ".join(words) print(joined_text) # 输出: Python Programming Is Fun
- 描述:将
列表常用操作方法
-
ls.append(x)
- 描述:在列表的末尾添加一个元素
x。 - 例子:
ls = [1, 2, 3] ls.append(4) print(ls) # 输出: [1, 2, 3, 4]
- 描述:在列表的末尾添加一个元素
-
ls.insert(i, x)
- 描述:在列表的
i位置插入元素x。 - 例子:
ls = [1, 2, 4] ls.insert(2, 3) # 在索引为2的位置插入数字3 print(ls) # 输出: [1, 2, 3, 4]
- 描述:在列表的
-
ls.clear()
- 描述:清除列表中的所有元素。
- 例子:
ls = [1, 2, 3] ls.clear() print(ls) # 输出: []
-
ls.pop(i)
- 描述:移除列表中的
i位置元素并返回这个元素。如果没有指定索引,pop方法将会移除并返回列表中的最后一个元素。 - 例子:
ls = [1, 2, 3, 4] pop_element = ls.pop(2) # 移除索引为2的元素 print(pop_element) # 输出: 3 print(ls) # 输出: [1, 2, 4]
- 描述:移除列表中的
-
ls.remove(x)
- 描述:移除列表中第一次出现的一个元素
x。如果该元素不存在,则抛出一个异常。 - 例子:
ls = [1, 2, 3, 2, 4] ls.remove(2) # 移除列表中第一个出现的元素2 print(ls) # 输出: [1, 3, 2, 4]
- 描述:移除列表中第一次出现的一个元素
-
ls.reverse()
- 描述:逆转列表中的元素顺序。
- 例子:
ls = [1, 2, 3, 4] ls.reverse() print(ls) # 输出: [4, 3, 2, 1]
-
ls.copy()
- 描述:生成一个新列表,复制
ls中的所有元素。 - 例子:
ls = [1, 2, 3] ls_copy = ls.copy() print(ls_copy) # 输出: [1, 2, 3]
- 描述:生成一个新列表,复制
字典常用操作方法
-
d.keys()
- 描述:返回一个包含字典所有键的视图对象。
- 例子:
d = {'a': 1, 'b': 2, 'c': 3} keys = d.keys() print(keys) # 输出: dict_keys(['a', 'b', 'c'])
-
d.values()
- 描述:返回一个包含字典所有值的视图对象。
- 例子:
d = {'a': 1, 'b': 2, 'c': 3} values = d.values() print(values) # 输出: dict_values([1, 2, 3])
-
d.items()
- 描述:返回一个包含所有(键,值)对的视图对象。
- 例子:
d = {'a': 1, 'b': 2, 'c': 3} items = d.items() print(items) # 输出: dict_items([('a', 1), ('b', 2), ('c', 3)])
-
d.get(key, default)
- 描述:返回字典中键
key对应的值,如果键不在字典中,则返回default。 - 例子:
d = {'a': 1, 'b': 2, 'c': 3} value = d.get('b', '不存在') print(value) # 输出: 2 value = d.get('z', '不存在') print(value) # 输出: 不存在
- 描述:返回字典中键
-
d.pop(key, default)
- 描述:移除字典中键
key对应的项,并返回其值。如果键不在字典中,则返回default。 - 例子:
d = {'a': 1, 'b': 2, 'c': 3} value = d.pop('b', '不存在') print(value) # 输出: 2 print(d) # 输出: {'a': 1, 'c': 3}
- 描述:移除字典中键
-
d.popitem()
- 描述:移除字典中的一个项,通常是最后加入的(key, value)对并返回它,用于实现堆栈和队列。
- 例子:
d = {'a': 1, 'b': 2, 'c': 3} item = d.popitem() print(item) # 输出: ('c', 3) print(d) # 输出: {'a': 1, 'b': 2}
-
d.clear()
- 描述:清除字典中的所有项。
- 例子:
d = {'a': 1, 'b': 2, 'c': 3} d.clear() print(d) # 输出: {}
open函数操作模式
-
'r'模式- 描述:以只读方式打开文件,如果文件不存在,则抛出
FileNotFoundError异常。 - 例子:
with open('example.txt', 'r') as file: content = file.read()
- 描述:以只读方式打开文件,如果文件不存在,则抛出
-
'w'模式- 描述:以写入方式打开文件,如果文件不存在则创建新文件,如果文件已存在则覆盖原有内容。
- 例子:
with open('example.txt', 'w') as file: file.write('New content')
-
'x'模式- 描述:如果文件不存在,则创建新文件并以写入模式打开。如果文件已存在,则抛出
FileExistsError异常。 - 例子:
try: with open('example.txt', 'x') as file: file.write('New content') except FileExistsError: print('File already exists.')
- 描述:如果文件不存在,则创建新文件并以写入模式打开。如果文件已存在,则抛出
-
'a'模式- 描述:以追加方式打开文件,如果文件不存在则创建新文件,如果文件存在则在文件末尾追加内容。
- 例子:
with open('example.txt', 'a') as file: file.write('\nAdditional content')
-
'b'模式- 描述:以二进制方式打开文件,通常与其他模式一起使用(如
'rb'或'wb')。 - 例子:
with open('example.bin', 'wb') as file: file.write(b'\x00\x01\x02')
- 描述:以二进制方式打开文件,通常与其他模式一起使用(如
-
't'模式- 描述:以文本方式打开文件,这是默认的模式,通常不需要显式指定。
- 例子:
with open('example.txt', 'rt') as file: # 't'可以省略 content = file.read()
-
'+'模式- 描述:与
'r'、'w'、'x'、'a'中的一个配合使用,表示同时需要读和写的功能。 - 例子:
with open('example.txt', 'r+') as file: file.write('Updated content') file.seek(0) content = file.read()
- 描述:与
功能和异同点:
-
'r','w','x', 和'a'模式主要用于控制文件的读写行为。它们的主要区别在于文件存在或不存在时的行为和文件内容的处理:'r'模式要求文件必须存在,否则会报错。'w'模式不要求文件存在,如果存在则覆盖,如果不存在则创建。'x'模式要求文件必须不存在,用于确保不覆盖已有的文件。'a'模式用于追加,不覆盖原有内容,无论文件存在与否。
-
'b'模式是一个附加模式,用于指定文件以二进制方式处理,与上述模式组合使用,如'rb'、'wb'等。 -
't'模式也是一个附加模式,用于指定文件以文本方式处理,是默认选项,通常省略。 -
'+'模式扩展了其他模式的功能,使得文件可以同时用于读写。它不单独使用,而是与其他模式结合使用,如'r+'、'w+'等。
读文件及文件指针
-
f.read(size=-1)- 描述:读取并返回文件中的数据。如果指定了
size参数,则最多读取size个字节的数据;如果没有指定size或指定为-1,则读取并返回文件中的所有数据。 - 例子:
with open('example.txt', 'r') as f: content = f.read() print(content)
- 描述:读取并返回文件中的数据。如果指定了
-
f.readline(size=-1)- 描述:读取文件中的一行数据。如果指定了
size参数,则读取该行中的size个字节的数据;如果没有指定size或指定为-1,则读取整行数据。 - 例子:
with open('example.txt', 'r') as f: line = f.readline() print(line)
- 描述:读取文件中的一行数据。如果指定了
-
f.readlines(hint=-1)- 描述:读取文件中所有行,并作为每一行的列表返回。如果指定了
hint参数,则读取近似hint字节的行数。 - 例子:
with open('example.txt', 'r') as f: lines = f.readlines() print(lines)
- 描述:读取文件中所有行,并作为每一行的列表返回。如果指定了
-
f.seek(offset)- 描述:在文件中移动文件指针到
offset指定的位置。offset的值:0表示文件开头;2表示文件结尾。 - 例子:
with open('example.txt', 'r') as f: f.seek(0) # 移动到文件开头 first_line = f.readline() f.seek(5) # 移动到文件第5个字节 from_fifth_byte = f.read() print(first_line) print(from_fifth_byte)
- 描述:在文件中移动文件指针到
写文件
-
f.write(s)- 描述:向文件中写入一个字符串
s。 - 例子:
with open('example.txt', 'w') as f: f.write('Hello, World!')
在这个例子中,我们打开(或创建)了一个名为
example.txt的文件,并以写入模式'w'打开。然后,我们使用write方法写入字符串'Hello, World!'到文件中。 - 描述:向文件中写入一个字符串
-
f.writelines(lines)- 描述:将一个字符串列表
lines写入到文件中,不会自动添加行间隔符,如换行符。 - 例子:
lines = ['Hello, World!', 'Welcome to Python.'] with open('example.txt', 'w') as f: f.writelines(line + '\n' for line in lines)
在这个例子中,我们首先创建了一个字符串列表
lines,包含两行文字。然后,我们打开(或创建)了一个名为example.txt的文件,并以写入模式'w'打开。使用writelines方法,我们迭代lines列表,并为每个字符串添加一个换行符\n,然后写入到文件中。这样做是因为writelines不会自动添加换行符,所以我们需要手动添加它们。 - 描述:将一个字符串列表
这两种写入方法提供了文件输出的灵活性:write 方法适合写入单个字符串,而 writelines 适用于写入多个字符串。注意,使用 write 或 writelines 方法时,如果文件已经存在,则其内容将被覆盖,除非文件是以追加模式 'a' 打开的。
random库
-
seed(a=None):import random random.seed(1) # 设置随机数生成器的种子为1 -
random():random_value = random.random() # 生成一个[0.0, 1.0)之间的随机浮点数 -
randint(a, b):random_integer = random.randint(1, 10) # 生成一个[1, 10]之间的随机整数 -
getrandbits(k):random_bits = random.getrandbits(8) # 生成一个随机的8位二进制数 -
randrange(start, stop[, step]):random_range = random.randrange(0, 10, 2) # 生成一个[0, 10)之间以2为步长的随机数 -
uniform(a, b):random_uniform = random.uniform(1.5, 4.5) # 生成一个[1.5, 4.5]之间的随机浮点数 -
choice(seq):random_choice = random.choice(['apple', 'banana', 'cherry']) # 从列表中随机选择一个元素 -
shuffle(seq):items = [1, 2, 3, 4, 5] random.shuffle(items) # 打乱列表中的元素顺序 -
sample(pop, k):random_sample = random.sample(range(100), 5) # 从0到99的数字中随机抽取5个不重复的数字
jieba库
-
jieba.lcut(s):import jieba words = jieba.lcut("结巴分词,返回一个列表形式的分词结果") -
jieba.lcut(s, cut_all=True):words_full_mode = jieba.lcut("全模式分词,返回一个列表形式的分词结果", cut_all=True) -
jieba.lcut_for_search(s):words_search_mode = jieba.lcut_for_search("搜索引擎模式分词,返回一个列表形式的分词结果") -
jieba.add_word(w):jieba.add_word("添加词语进分词库")

![OSError: [WinError 1455] 页面文件太小,无法完成操作。](https://img-blog.csdnimg.cn/direct/a7b1f46f246d4ac6aff9716c792ef187.png)