工具:
- Anaconda: anaconda.com/products/individual。我理解是一个基于Python的AI程序开发环境,其作用类似于google notebook。区别是google notebook是在网页上,而Anaconda一般是安装在自己的服务器上。
- Jupyter Notebooks
Anaconda激活深度学习的命令:
- conda activate deeplearning
介绍
Deep learning介绍
- 属于machine learning的范畴
- 3层及以上的神经网络
- 模拟人类处理数据和做出决策的行为
- 在过去几年指数级增长
- 以大规模数据处理和推理的进步为动力(GPUs)
线性回归 (Linear Regression)
y=ax+b, a is slope(斜率), b is intercept(截距)
逻辑回归(Logistic Regression)
y = f(ax+b), f是激活函数(Activation Function)
Perceptron(感知机)
- 是一个用于二分类问题的有监督学习的算法
- 类似于人脑中的一个细胞
- 对应于神经网络中的一个结点
- 基于逻辑回归
感知机公式:
w称为权重,b称为偏好,f为激活函数
人工神经网络(Artificial Neural Network, ANN)
- 感知机在神经网络中称为结点
- 按照层组织所有结点
- 每个结点均有权重,偏好以及激活函数
- 每个结点和下一层的所有结点相连
- 输入层,隐藏层,输出层
ANN结构
向量:ANN中的数据一般会用向量表示
采样,目标,特性:ANN中的一组数据称为采样,这个概念应该来自统计学。采样中,通常有一维数据是我们关注的最终结果,这一维称为目标。其余维度的数据称为特性。即可以理解为:在一组采样中,多个特性数据对应一个目标数据。
输入层
输入预处理
特性需要被转化为数字表示
| 输出类型 | 所需的处理 |
| 数字的 | 中心化和定标(centering and scaling) |
| 类别的 | 整数编码(integer encoding),独热编码(one-hot encoding) |
| 文本 | TF-IDF(词频-逆文本频率),嵌入(embedding) |
| 图像 | 像素-RGB表示(Pixels-RGB representation) |
| 语音 | 数字的时间序列(Time series of numbers) |
- 中心化:取某个特性的所有数据的平均值作为中心,这个特性的所有数据减去这个平均值
- 定标:特性的所有数据按照一定的比例缩放,使每个特性最终的数值都在统一的范围内。这是为了避免不同特性之间的基数本身存在差异,一起处理时会引入偏好
隐藏层
输入层和输出层中间的层都称为隐藏层
权重和偏好
- ANN中可以训练的参数
计算权重和偏好的个数:如果前一层的结点数为A,当前层的结点数为B,则这两层之间的权重个数为:A * B;偏好个数为B。
激活函数
流行的激活函数
| 激活函数 | 输出 |
| Sigmoid | 0~1 |
| Tanh | -1~1 |
| Rectified Linear Unit(ReLU) | 0当x <0; 否则为x |
| Softmax | 概率向量,其和为1 |
输出层
训练神经网络
初始化
数据被分为训练(Training),测试(Test),验证(Validation)三类
权重(weights)和偏好(bias)
方法:
- 零初始化:初始化为全零
- 随机初始化
前向传播(forward propagation)
预测值(Predication, y hat)是通过前向传播得到的
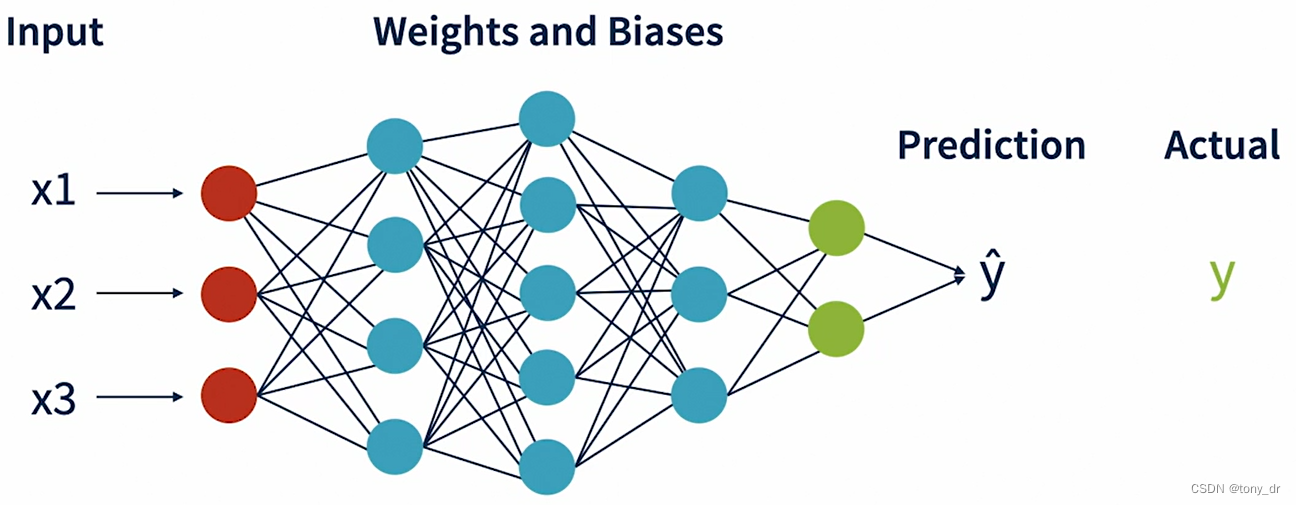
测量精确度和误差
损失和成本函数
- Loss Function: 测量单个采样的预测误差
- Cost Function: 测量一个采样集合的误差
成本函数
| 成本函数 | 应用 |
| 均方差(MSE) | 回归 |
| 根均方差(RMSE) | 回归 |
| 二进制交叉熵(Binary Cross Entropy) | 二分类 |
| 范畴交叉熵(Categorical Cross Entropy) | 多分类 |
怎样测量精确度
- 使用一个成本函数比较预测值和期望值之间的误差
- 基于误差使用反向传播调整权重
反向传播(Back Propagation)
反向传播怎样工作
- 和前向传播方向相反,从输出层开始
- 基于发现的误差,计算一个delta
- 将这个delta应用于误差和偏好上
- 基于新的误差和偏好,会得到一个新的误差,然后重复前面的步骤
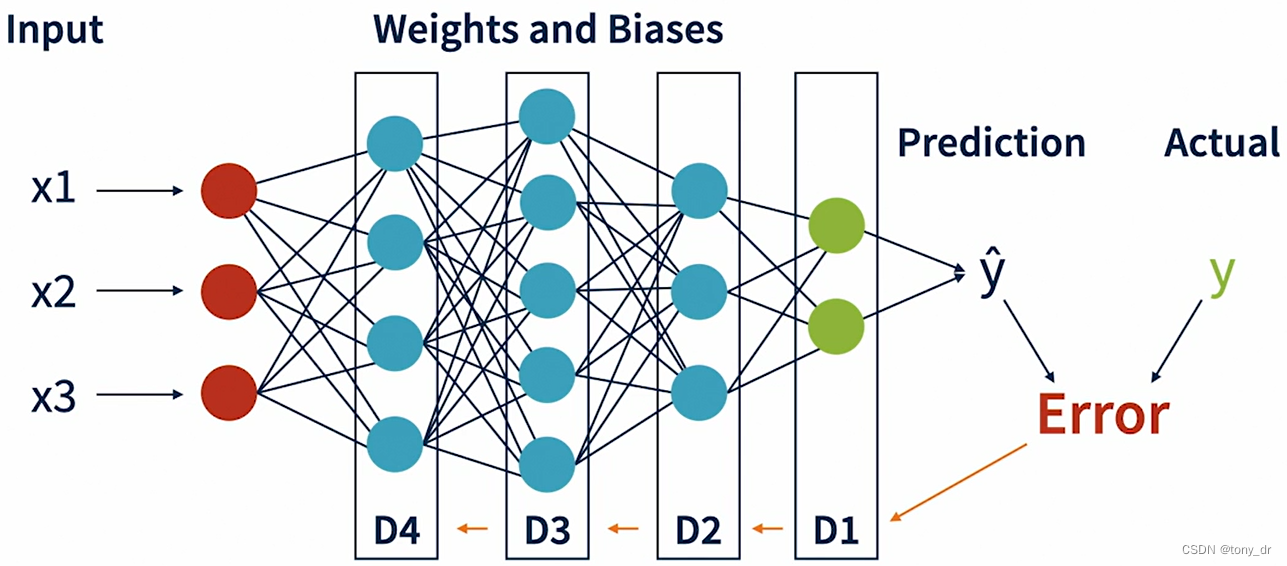
梯度下降(Gradient Descent)
在前面的模型中,通过不断地循环,使得权重和偏好被不断地优化,误差不断地减小,这个过程称为梯度下降。即不断重复下面的步骤:
- 前向传播
- 误差估计
- 反向传播
- 调整权重和偏好
会存在误差停止减少的情况,此时会有一些额外的超参数(Hyper Parameters)用于这种情况,超参数也可以用于加速或减速这个过程。
批和期(Batches and Epoch)
什么是批(Batch)
- 单次传递给ANN的一个采样集合
- 训练数据集可以分为一个或多个“批”
- 每一“批”都会有一次成本估计和参数更新,即对于下一批采样数据,会使用更新后的参数
批的大小
- 当批的大小等于训练集大小时,称为批梯度下降(Batch Gradient Decrease)
- 当批的大小小于训练集大小时,称为迷你批梯度下降(Mini-batch Gradient Decrease)
- 典型的批的大小有32,64,128等等
什么是期
- 对于整个训练集,需要发送给ANN的次数
- 每一期包含一个或多个批
- 对于同一个批,可能在不同的期中发送给ANN,但每次都会使用当前更新后的权重
- 当所有期完成后,训练过程结束
- 期的大小越大,则精确度越高,但训练时间会越久
注意:批的大小和期的大小都是超参数,可以通过调整来优化训练过程
例子:训练集中总共有1000个采样,批的大小为128,期的大小为50。请问期是多少?训练过程总共循环几次?
期: ceiling(1000/128) = 8
循环次数:8 * 50 = 400
验证和测试(Validation and Testing)
- 验证数据和测试数据通常都来源于原始数据,是从原始数据集中划分出来的。推荐的训练、验证、测试集数据量比例为8:1:1。
- 验证数据集用于训练过程,测试数据集用于最后的模型评价
- 在每个Epoch结束后,会将模型应用于验证数据集中,用于确保模型不会出现太大的偏差,调整模型(称为Fine-tuning)以待下一个Epoch的学习
- 在所有Epoch和Fine-tuning结束后,会将模型应用于测试数据集,用于评价模型
一个ANN模型
ANN模型是由一些参数表示的:
- 权重
- 偏好
ANN模型也由一些超参数表示的:
- 层数,每层的结点数,激活函数
- 成本函数,学习速率,优化因子
- 批的大小,期
预测过程
- 预处理和输入准备
- 将输入传给第一层
- 使用当前的权重,偏好和激活函数计算Y
- 传递给下一层
- 重复以上过程直到输出层
- 过程后处理输出,用于预测
重用已有的网络架构
大多数神经网络(NN)并非是从零开始创建的(created from scratch)。设计一个具有合适的层数和结点的NN是一个乏味的、重复的、耗时的过程。社区共享了很多知识和经验,可以拿来使用。
流行的网络架构:
- LeNet5:用于文本和手写识别
- AlexNet:卷积神经网络(Conventional Neural Network,CNN),用于图像识别
- ResNet: 也是CNN,用于图像识别,克服了一些传统CNN的限制
- VGG: 另一个流行的CNN
- LSTM:循环神经网络(Recurrent Neural Network),用于预测文本序列
- Transformers:是一个最新的架构,彻底改变了原生AI(generative AI)
使用可用的开源模型
开源模型
- 在开源社区共享,模型已经经过了充分地训练,包括参数和超参数
- Hugging face/ Github
- 很方便地下载
- 通常已经集成在了PyTorch/ TensorFlow中
选择开源模型
- 理解其目的和原始的使用场景
- 了解其训练基于的数据。数据可能是公共的;也可能是私有的、会涉及一些法律问题。
- 探索模型的适用范围和用法(Popularity and Usage)
- 复查许可(Licensing)和相关需求
- 下载模型
- 在你的使用场景中测试这个模型
深度学习示例
示例项目:Iris data set
Iris flower数据集是一个经典的用于分类问题的数据集,详见以下链接:
https://en.wikipedia.org/wiki/Iris_flower_data_set
由于sklearn提供了load_iris(),因此我们使用这个方法直接导入Iris数据集。
运行环境:google notebook(用法见初识Google Colab Jupyter Notebook),程序如下:
1. 加载数据和预处理
import pandas as pd
import os
import tensorflow as tf
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
#Number of data to show
NB_TO_SHOW=5
# Use load_iris in sklearn to load Iris Flower Data Set directly
iris_data = load_iris()
print("\nLoaded Data:\n-------------------------------")
print(iris_data.data.shape)
#from sklearn import preprocessing
#label_encoder = preprocessing.LabelEncoder()
# Separate feature and target variables
X_data = iris_data.data
Y_data = iris_data.target
print("\nFeatures before scaling:\n-------------------------------")
print(X_data[0:NB_TO_SHOW])
print("\nTarget before scaling:\n-------------------------------")
print(Y_data[0:NB_TO_SHOW])
# Create a scaler model that is fit on the input data
scaler = StandardScaler().fit(X_data)
# Scale the numeric feature variables
X_data = scaler.transform(X_data)
# Convert target variable as a one-hot-encoding array
Y_data = tf.keras.utils.to_categorical(Y_data, 3)
print("\nFeatures after scaling:\n-------------------------------")
print(X_data[0:NB_TO_SHOW])
print("\nTarget after scaling:\n-------------------------------")
print(Y_data[0:NB_TO_SHOW])
# Split the training and test data
X_train,X_test,Y_train,Y_test = train_test_split(X_data, Y_data, test_size=0.10)
print(X_train.shape, Y_train.shape, X_test.shape, Y_test.shape)2. 创建模型
from tensorflow import keras
NB_CLASSES=3
#Create a sequential model in Keras
model = keras.models.Sequential()
#Add the first hidden layer
model.add(keras.layers.Dense(128, #Number of nodes
input_shape=(4,), #Number of input variables
name="Hidden-Layer-1", #Logical name
activation='relu')) #activation function
#Add the second hidden layer
model.add(keras.layers.Dense(128, #Number of nodes
name="Hidden-Layer-2", #Logical name
activation='relu')) #activation function
#Add an output layer with softmax
model.add(keras.layers.Dense(NB_CLASSES, #Number of nodes
name="Output-Layer", #Logical name
activation='softmax')) #activation function
#Compile the model with loss & metrics
model.compile(loss='categorical_crossentropy',
metrics=['accuracy'])
#Print the model meta-data
model.summary()
3. 训练模型
# Make it verbose so we can see the progress
VERBOSE=1
# Setup Hyper Parameters for training
# Set Batch size
BATCH_SIZE=16
# Set number of epochs
EPOCHS=10
# Set validataion split. 20% of the training data will be used for validation
# after each epoch
VALIDATION_SPLIT=0.2
print("\nTraining Progress:\n-------------------------------")
# Fit the model.
history=model.fit(X_train,
Y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
verbose=VERBOSE,
validation_split=VALIDATION_SPLIT)
print("\nAccuracy during Training:\n-------------------------------")
import matplotlib.pyplot as plt
# Plot accuracy of the model after each epoch
pd.DataFrame(history.history)["accuracy"].plot(figsize=(8,5))
plt.title("Accuracy improvements with Epoch")
plt.show()
# Evaluate the model
print("\nEvalulation against Test Dataset:\n-------------------------------")
model.evaluate(X_test, Y_test)4. 保存模型
使用google notebook,不需要保存模型;如果自己安装Jupyter Notebook,可以保存这个模型到本地。
# Saveing a model
#model.save("iris_save")
# Loading a Model
#loaded_model = keras.models.load_model("iris_save")
# Print Model Summary
#loaded_model.summary()5. 使用训练好的模型预测新数据
# Raw prediction data
prediction_input=[[6.6, 3, 4.4, 1.4]]
#Scale prediction data with the same scaling model
scaled_input = scaler.transform(prediction_input)
# Get raw prediction probabilities
raw_prediction = model.predict(scaled_input)
print("Raw Prediction Output (Probabilities): ", raw_prediction)
# Find prediction
prediction = np.argmax(raw_prediction)
#print("Prediction is ", label_encoder.inverse_transform([prediction]))
print("Prediction is: ", iris_data.target_names[prediction])