发表于ECCV2022.
论文地址:https://arxiv.org/abs/2203.09517
源码地址:https://github.com/apchenstu/TensoRF
项目地址:https://apchenstu.github.io/TensoRF/
摘要
本文提出了TensoRF,一种建模和重建辐射场的新方法。不同于NeRF中纯粹使用了MLP,本文将场景的辐射场用4D张量表示,代表了一个3D体素网格,每个体素具有多通道特征。中心思想是将4D场景张量分解成多个紧凑的低秩张量分量。
在本文框架中应用传统的CP分解(将张量分解成具有紧凑的秩一向量)可以带来对普通NeRF的改进。为了进一步提高性能,本文引入一种新的向量矩阵分解(VM分解),它放宽了张量两种模式的低秩约束,并将张量分解为紧凑的向量和矩阵因子。
除了更好的渲染质量,和直接优化每体素特征的其他工作相比,本文模型显著降低了内存占用量。和NeRF相比具有CP分解的TensoRF可以实现快速重建(<30min),具有更好的渲染质量,更小的模型大小(<4MB)。具有VM分解的TensoRF进一步提高了渲染质量并超越了之前最先进的方法,同时减少了重建时间(<10min)并保留了紧凑的模型大小(<75MB)。

概述
建模和重建3D场景作为支持高质量图像合成的表示对于计算机视觉和图形学在很多应用领域中至关重要。
NeRF及其后续工作在将场景建模为辐射场方面取得了成功,并实现了具有高度复杂几何形状和依赖于视图的外观效果的场景的照片级真实感渲染。虽然纯基于MLP的NeRF模型需要较小的内存,但是它们需要很长时间(数个小数或数天)来训练。
本文提出一种新方法TensoRF,训练时间高效且内存占用紧凑,同时实现了最先进的渲染质量。
TensoRF将辐射场表示为显式的体素特征网格。注意,尚不清楚体素网格表示是否可以提高重建效率:虽然以前的工作使用了特征网格,但是它们需要大量的GPU内存来存储尺寸随着分辨率呈立方体增长的体素,有些甚至需要预先计算NeRF进行蒸馏,导致重建时间很长。
TensoRF解决了体素网格表示的低效率问题,产生了一系列简单而有效的方法。我们将特征网格自然地视为4D张量,其中三个模式对应于网格的XYZ轴,第四个模式代表特征通道维度。这开启了利用经典张量分解技术进行辐射场建模的可能性——这个技术已经广泛应用于各领域的高维数据分析和压缩。因此,这里建议将辐射场张量分解成多个低秩张量分量,从而获得准确而紧凑的场景表示。而且这里张量化辐射场的思想是通用的,可以应用与任何张量分解技术。
作者首先尝试了经典的CP分解。发现具有CP分解的TensoRF已经可以实现照片级真实感渲染,并产生比NeRF更紧凑的模型。但是实验上为了进一步提高复杂场景的重建质量,必须使用更多的成分因子,这样就会增加训练时间。
所以,作者又提出了一种VM分解技术,可以有效减少相同表达能力所需要的组件数量,从而实现更快的重建和更好的渲染。特别是受到了CP分解和block term分解的启发。和CP分解中纯向量的外积之和不同,这里考虑向量-矩阵外积之和。本质上,通过在矩阵因子中联合建模两个模式来放宽每个组件的两个模式的秩。虽然和CP分解相比增加了模型大小,但是使每个组件能够表达更高阶的更复杂的张量数据,从而显著减少辐射场建模中所需的组件数量。
通过CP/VM分解,TensoRF紧凑地编码体素网格中的空间变化特征。可以从特征中解码体积密度和与视角相关的颜色,支持体积辐射场渲染。由于张量表示离散数据,所以还可以使用高效的三线性插值来对连续场进行建模。该方法的表示支持具有不同解码功能的各种类型的逐体素特征,包括neural features(依赖MLP从特征中回归和视角相关的颜色)和 SH features(球谐函数特征,允许从固定的SH函数进行简单颜色计算,而不需要神经网络的表示)。
张量辐射场可以从多视图图像有效地重建,并实现逼真的新颖视图合成。和之前直接重建体素的工作相比,张量分解将空间复杂度从O(n3)降到了O(n)(使用CP)或 O(n2)(使用VM),显著降低了内存占用。
注意,虽然是利用张量分解,但并不是在解决分解和压缩问题,而是基于梯度下降的重建问题,因为特征网格/张量是未知的。本质上,这里的CP/VM分解在优化中提供了低秩正则化,从而实现了高渲染质量。
通过各种实验设置对本文方法进行了评估,涵盖了CP和VM模型、不同数量的组件和网格分辨率。结果证实了所有模型都能够实现逼真的新视图合成结果,和以前最先进的方法相当或更好(图1 表1)。更重要的是,本文方法具有更高的计算和内存效率。所有的TensoRF模型均可以在30分钟内重建高质量辐射场。最快的VM分解模型需要不到10分钟,比NeRF快约100倍,同时所需内存少得多。
注意,和需要独特数据结构和定制CUDA内核的一些工作不同,本文模型的效率增量是通过pytorch实现获得的。该工作是第一个从张量角度看待辐射场建模,并将辐射场重建问题作为一项低秩张量重建的工作。
相关工作
张量分解
最广泛使用的分解是Tucker分解和CP分解,二者都可以看做是矩阵奇异值分解(SVD)的推广。CP分解可以看作特殊的Tucker分解,其核心张量是对角的。通过结合CP和Tucker分解,块项分解(BTD)及其许多变体被提出。这项工作中,直接应用了CP分解,此外引入了一种新的向量矩阵分解,也可以看做一种特殊的BTD。
场景表示和辐射场
各种场景表示,包括网格、点云、体积、隐函数,近年来得到了广泛的研究。很多神经表示的方法被提出用于高质量渲染或者自然信号表示。NeRF引入了辐射场来解决新颖的视图合成问题并实现照片级真实感质量。这种表达方式已经快速拓展并且应用于各种图形和视觉应用,包括生成模型、外观获取、表面重建、快速渲染、外观编辑、动态捕捉等。虽然NeRF具有逼真的渲染和紧凑的模型,但是它纯基于MLP的表示在重建和渲染速度缓慢方面存在局限性。最近一些方法在辐射场重建中利用了体素特征网格,实现了快速渲染。然而,这些基于网格的方法仍然需要较长的重建时间,甚至导致较高的内存成本,牺牲了NeRF的紧凑性。基于特征网格,本文提出一种新颖的张量场景表示,利用张量分解技术实现快速重建和紧凑建模。
其他方法设计了跨场景训练的通用网络模块,以实现图像相关的辐射场渲染和快速重建。本文方法侧重于辐射场表示,并且仅考虑每个场景的优化(类似NeRF)。本文方法已经可以实现高效的辐射场重建,而不需要任何跨场景的泛化。将通用设置的拓展留作未来工作。
同期工作
辐射场建模领域发展迅速。DVGO和Plenoxels也优化了特征的体素网格来实现快速辐射场重建。然而它们仍然像以前基于体素的方法一样直接优化每个体素的特征,因此需要大量内存。不同的是,本文方法将特征网格分解成紧凑的组件,并显著提高了内存效率。Instant-NGP使用多分辨率哈希进行高效编码,同样获得了很高的紧凑表达。该技术和本文基于饮食分解的技术是垂直的,这里的每个向量矩阵因子都可以用这种散列技术进行编码,这将作为未来的工作。EG3D使用了三平面表示3D GAN,它们的表示类似于VM分解,可以看作具有恒定向量的特殊版本。
CP和VM分解
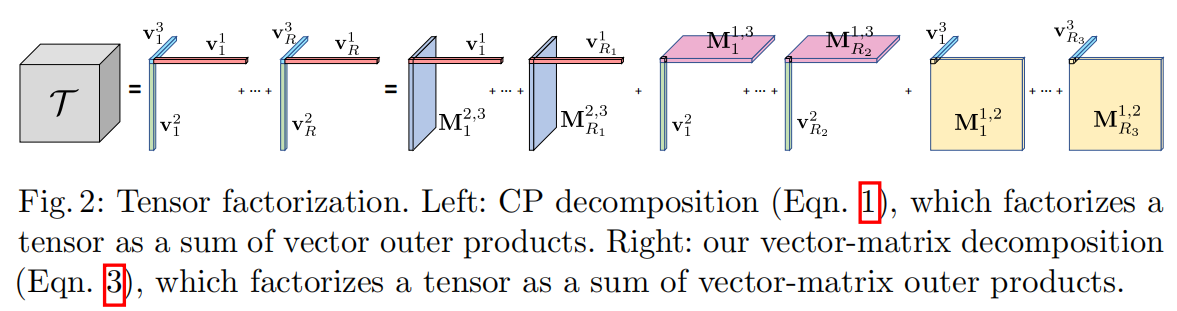
CP和VM分解如图2所示。现在以3D张量为例讨论这两种分解。
CP decomposition
给定一个3D张量,CP分解将其分解为向量的外积之和。

CP分解将张量分解为多个向量,表示多个紧凑的秩一向量。CP可以直接应用于张量辐射场建模并生成高质量结果。然而由于过于紧凑,CP分解可能需要许多组件来对复杂场景进行建模,导致辐射场重建的计算成本很高。
VM decomposition
和利用纯向量因子的CP分解不同,VM分解将一个张量分解成多个向量和矩阵。
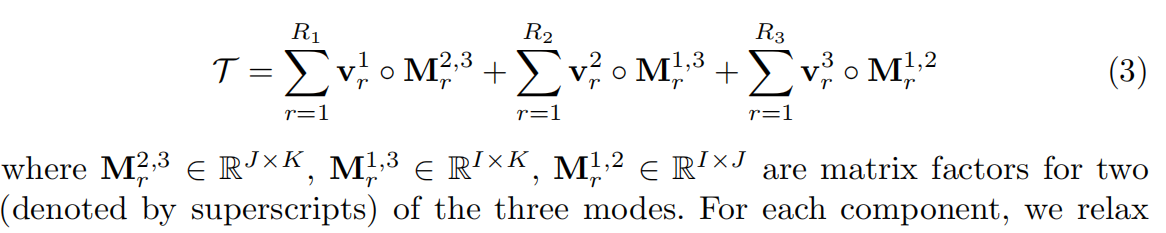
对于每个组件,将两个模式的秩放宽为任意大,同时将第三个模式限制为秩一。秩任意大的两个模式取决于矩阵的秩。一般的,和CP分解中使用单独的向量不同,这里是将每两个模式组合起来并用矩阵表示它们,从而允许使用较少数量的组件来充分参数化每个模式。R1 R2 R3可以进行不同的设置,并且应该根据每个模式的复杂性进行选择。VM分解可以看作是BTD的特例。
注意,这里的每个分量张量比CP分解中的一个分量具有更多的参数。虽然这会让紧凑性降低,但是VM分量张量可以表达比CP分量更复杂的高维数据,从而减少对相同复杂函数建模时所需的分量数量。另外,和密集网格表示相比VM分解仍然具有非常高的紧凑性。
用于场景建模的张量
在这项工作中,专注于建模和重建辐射场的任务。此时三个张量模式对应于XYZ轴。同时,在3D场景表示的背景下,对于大多数场景,认为R1=R2=R3=R,反映的事实就是场景可以沿着三个轴分布并同样复杂。
于是可以写成:
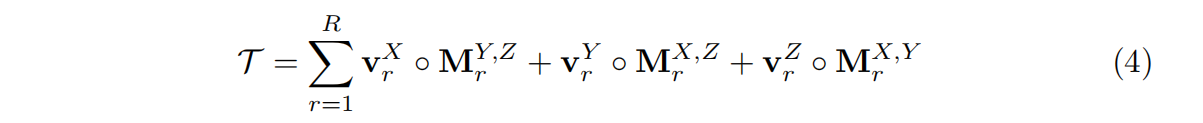
把V M合起来再简写一些:
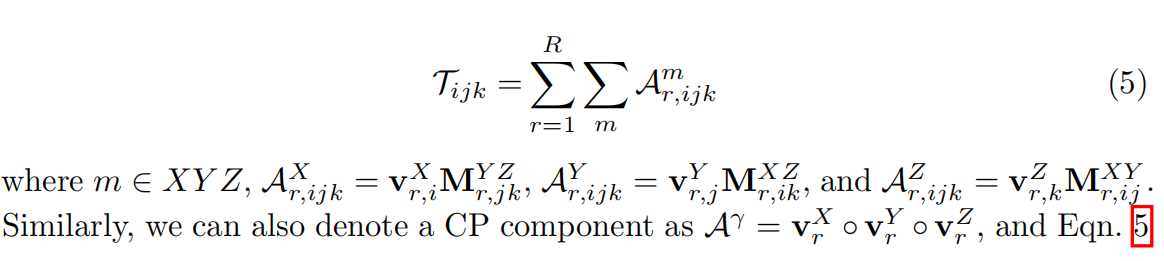
4. 张量辐射场表示
为简单起见,本章重点介绍TensoRF和VM分解。
4.1 特征网格和辐射场
该方法的目标是对辐射场进行建模。本质上是一个将任何3D位置
x
x
x和观察方向
d
d
d映射到其体积密度
σ
\sigma
σ和与视图相关的颜色
c
c
c的函数,支持用于体积渲染的可微分光线行进。
利用一个常规3D网格
G
G
G,每个体素有多通道的特征,来对此类函数进行建模。按照特征通道将其分割成几何网格
G
σ
G_{\sigma}
Gσ和外观网格
G
c
G_c
Gc,分别对体积密度和颜色进行建模。
本文方法支持外观网格
G
c
G_c
Gc中的各种类型的外观特征,具体取决于将外观特征向量和观察方向d转换成颜色c的预选函数S。例如,S可以是一个小的MLP,或者球谐函数(SH)。表1显示了MLP和SH函数都可以很好地与模型配合使用。另外,考虑单通道网格
G
σ
G_{\sigma}
Gσ,它的值直接表示体积密度,而不需要额外的转换函数。基于连续网格的辐射场可以写为:
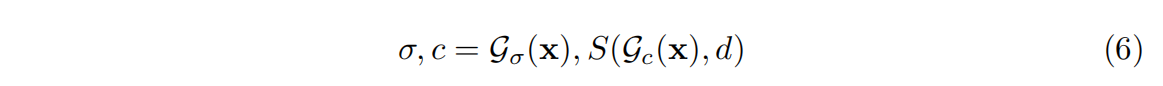
其中
G
σ
(
x
)
G_{\sigma}(x)
Gσ(x),
G
c
(
x
)
G_{c}(x)
Gc(x)表示位置x处两个网格的三线性插值特征。这里将
G
σ
G_{\sigma}
Gσ、
G
c
G_c
Gc建模为分解张量。
4.2 分解辐射场
G σ G_{\sigma} Gσ是3D张量(I × \times ×J × \times ×K),而 G c G_{c} Gc是4D张量(I × \times ×J × \times ×K × \times ×P)。IJK对应XYZ轴的分辨率,P对应外观特征通道的数量。然后将这些辐射场张量分解成紧凑的组件,特别是用VM分解。
3D几何张量
G
σ
G_{\sigma}
Gσ因式分解成:
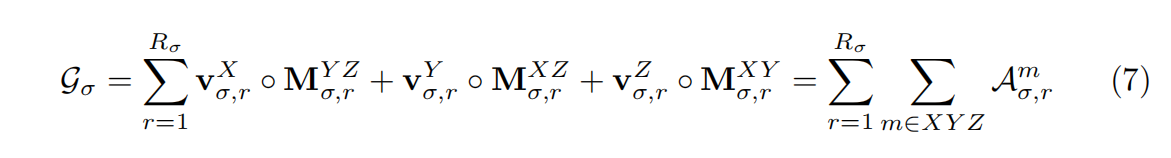
而
G
c
G_{c}
Gc多了一个维度,对应特征通道维度。和XYZ维度相比,它一般更低维,也就是有更低的秩。所以在分解时不会将该维度与矩阵因子中的其他维度结合起来,而是只使用向量(用
b
r
b_r
br表示)用于分解中的该维度:
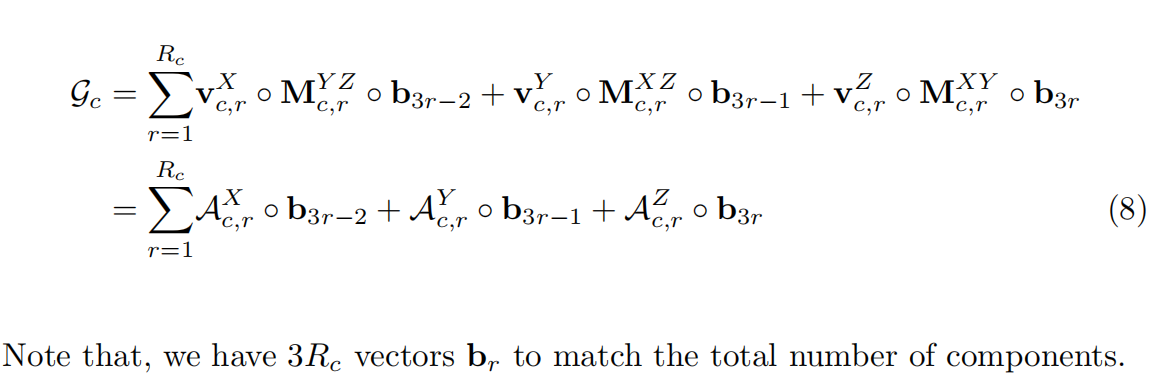
有
3
R
c
3R_c
3Rc个向量
b
r
b_r
br来匹配组件的总数。
总的来说,将整个张量辐射场分解成了
3
R
σ
+
3
R
c
3R_\sigma+3R_c
3Rσ+3Rc个矩阵和
3
R
σ
+
6
R
c
3R_\sigma+6R_c
3Rσ+6Rc个向量。
通常,采用
R
σ
,
R
c
<
<
I
,
J
,
K
R_\sigma,R_c<<I,J,K
Rσ,Rc<<I,J,K,从而获得紧凑的表示,可以编码高分辨率密集网格。
本质上,XYZ轴的向量和矩阵因子描述了场景沿着对应轴的几何和外观的空间分布。另一方面,外观特征轴向量
b
r
b_r
br表示全局外观相关性。将所有的
b
r
b_r
br作为列堆叠在一起,得到一个
P
×
3
R
c
P\times3R_c
P×3Rc的矩阵B,这个矩阵B也可以看作是一个全局外观字典,抽象了整个场景的外观共性。
4.3 高效的特征评估
本文基于分解的模型可以以低成本计算每个体素的特征向量,每个XYZ轴向量/矩阵因子只需要一个值。另外还为模型使用了高效的三线性插值,从而产生连续场。
- 直接评价
通过VM分解,单个体素的密度值可以通过下面的等式直接有效地评估:
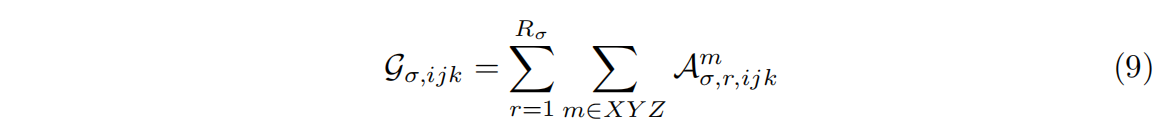
这里计算每个A只需要对其相应向量和矩阵因子中的两个值进行索引和相乘。
对于外观网格
G
c
G_c
Gc,需要计算完整的P通道特征向量,着色函数S需要该特征向量作为输入,对应于固定索引处的
G
c
G_c
Gc的一维切片:
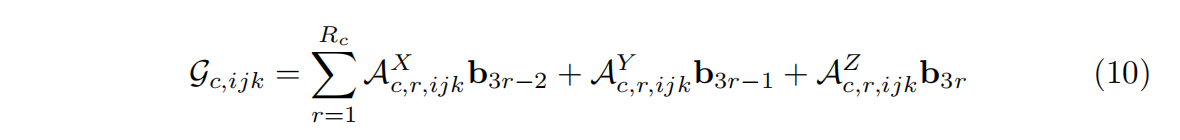
特征模式没有额外索引,因为计算完整的向量。通过重新排序计算继续简化方程10. 这样不仅是形式上简化,在实践中实现也更简单。当并行计算大量体素时,首先计算并链接所有体素的A作为矩阵中的列向量,然后和共享矩阵B相乘一次。
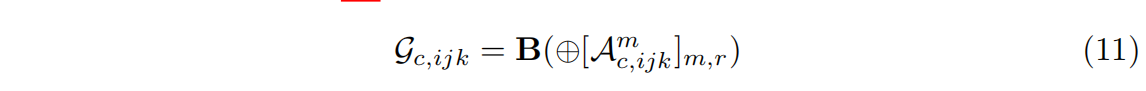
- 三线性插值
简单地实现三线性插值成本很高,因为需要评估8个张量值并进行插值,和计算单个张量元素相比计算量增加8倍。然而,对分量张量进行三线性插值自然等价于对相应轴进行线性/双线性插值其向量/矩阵因子,这得益于三线性插值和外积的线性之美。
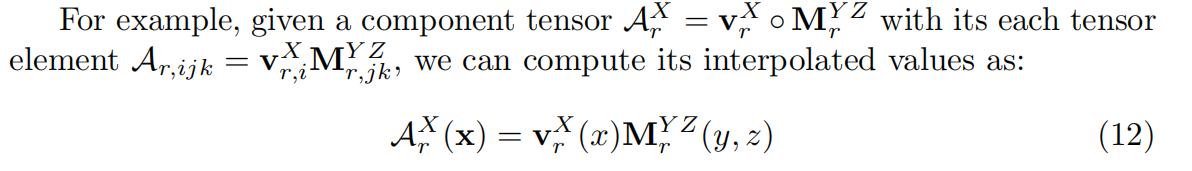

4.4 渲染和重建
因式分解张量辐射场可以表示为:
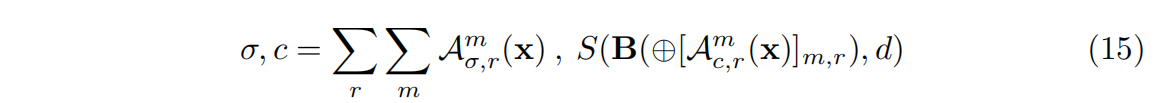
给定任何3D位置和观察方向,可以获得连续的体积密度和与视图相关的颜色值。这允许高质量的辐射场重建和渲染。注意,该方程是通用的,并描述了具有CP、VM分解的TensoRF。使用VM进行辐射场重建和渲染的完整流程如图3所示:

-
体积渲染
为了渲染图像,遵循NeRF使用可微体积渲染。对于每个像素,沿着一条射线行进,沿射线采样Q个着色点并通过以下方式计算像素颜色:
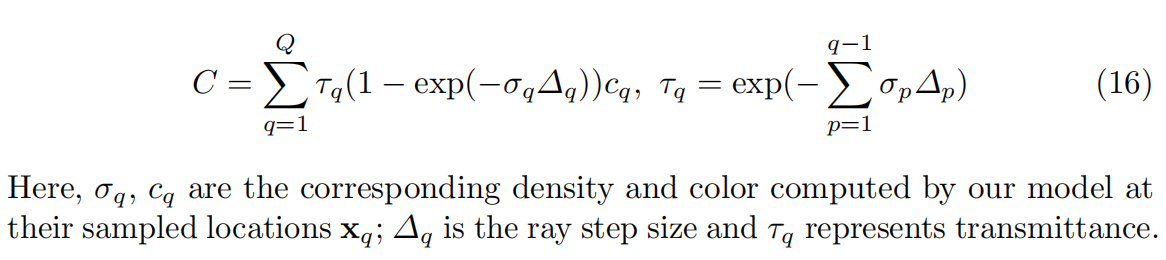 (
τ
q
:
\tau_q:
τq: 透射率)
(
τ
q
:
\tau_q:
τq: 透射率) -
重建
给定一组具有已知相机姿势的多视图输入图像,张量辐射场通过梯度下降针对每个场景进行优化,最大限度地减少L2渲染损失,只使用GT像素颜色作为监督。这里的辐射场通过张量分解来解释,并通过一组全局向量和矩阵进行建模,作为在优化中关联和正则化整个场的基本因素。但有时会导致过拟合和局部最小值问题,从而导致异常值或观测值较少区域中产生噪声。本文利用压缩感知中常用的标准正则化项,包括向量和矩阵因子上的L1范数损失和TV(总变分)损失,来有效地解决这些问题。只应用L1稀疏性损失对大多数数据集就足够了,但对于输入图像很少或不完美捕获条件得到的真实数据集,TV损失比L1损失更有效。
为了进一步提高质量并避免局部最小值,还应用了从粗到细(coarse-to-fine)的重建。和之前需要对其稀疏选择的体素集进行独特细分的从粗到细的技术不同,这里是通过简单地对XYZ-轴向量和矩阵因子进行线性和双线性上采样来实现的。
5. 实现细节
- TensoRF用pytorch实现,不需要定制CUDA内核。
- 特征解码函数S实现为MLP或者SH函数,两者都使用P=27个特征。对于SH,对应于具有RGB通道的3阶SH系数;对于MLP,使用了有两个FC层(128通道隐藏层)和ReLU激活函数。
- 张量因子初始学习率是0.02,MLP解码器初始学习率是0.001。
- 在单个Tesla V100 GPU(16GB)上优化模型T步,batch size=4096 pixel rays
- 特征网格总数为 N 3 N^3 N3个体素,每个维度的实际分辨率根据边界框形状计算。为了实现coarse-to-fine的重建,从 N 0 = 128 N_0=128 N0=128的低分辨率网格开始,然后在2000,3000,4000,5500,7000步的时候对向量和矩阵进行线性和双线性上采样,其中体素数量在对数空间中在 N 0 3 N_0^3 N03和 N 3 N^3 N3之间插值。
6. 实验
首先分析本文的分解技术、组件数量、网格分辨率和优化步数。
然后将本文方法和之前以及同期的工作在360° objects和forward-facing数据集上进行对比。
不同TensoRF模型的分析
使用不同数量的组件和网格体素的CP和VM分解在Synthetic NeRF数据集上评估。表2显示了每个模型的平均渲染PSNR,重建时间和模型大小。
实验中对所有变体使用相同的MLP解码函数,并以4096的batchsize优化每个模型30K步。
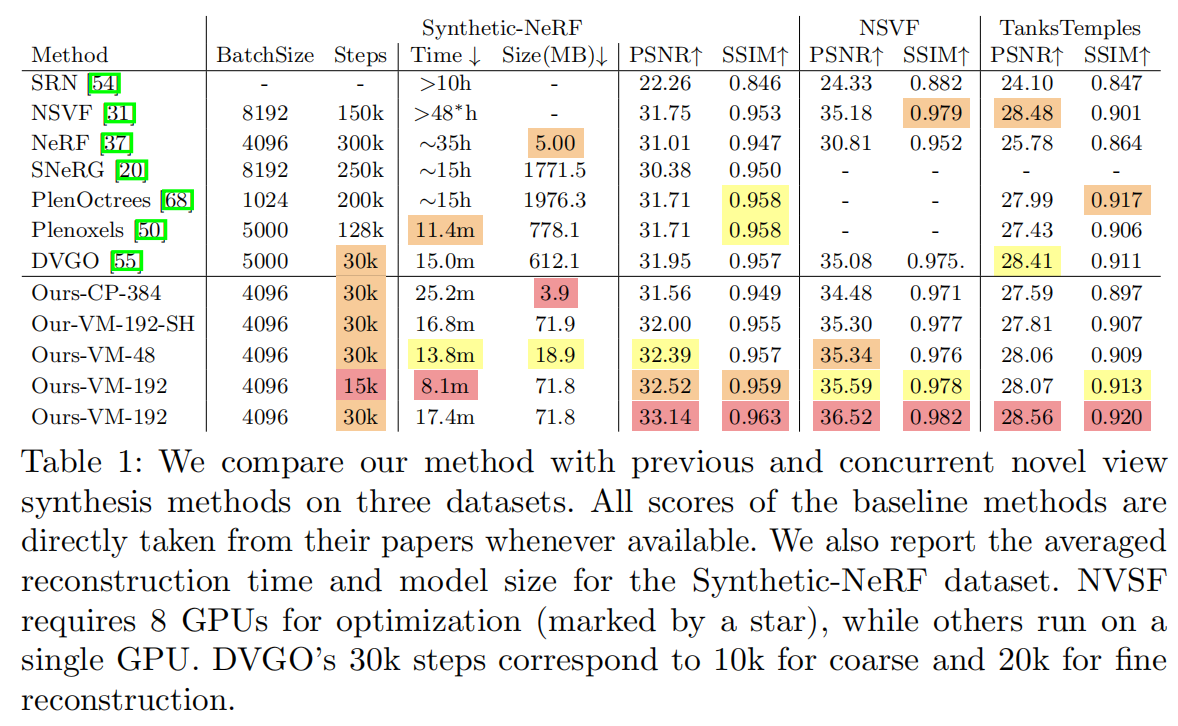
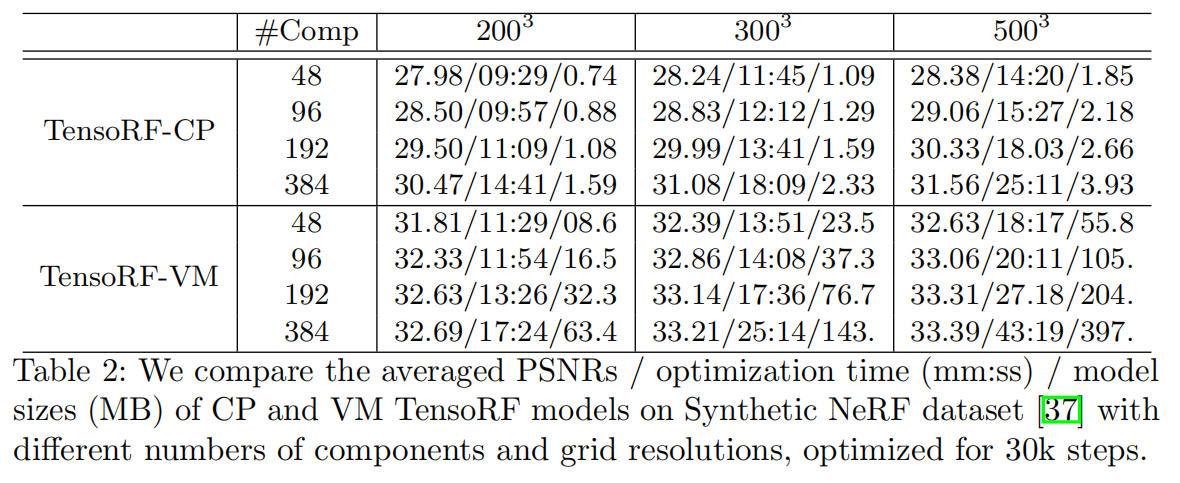
TensoRF-CP和TensoRF-VM都通过更多的组件或更高的网格分辨率实现了更好的渲染质量。TensoRF-CP实现超紧凑建模,即使是具有384个组件和
50
0
3
500^3
5003个体素的最大模型也只需要不到4MB。该CP模型在所有CP变体中实现了最佳渲染质量,PSNR搞到31.56,甚至优于普通的NeRF(表1)。
另一方面,由于TensoRF-VM在每个组件中压缩了更多的参数,所以实现了明显由于TensoRF-CP的渲染质量,即使是只有48个组件和 20 0 3 200^3 2003个体素的最小模型特能胜过更多组件和体素的最佳CP模型。这个最小的VM模型仅需要8.6MB,PSNR为31.81,已经高于NeRF和许多其他方法。
对于TensoRF-VM模型,192个组件一般就足够了,将数量加倍后只会带来边际改善。具有 30 0 3 300^3 3003体素的TensoRF-VM已经可以实现高PSNR的同时保持紧凑的模型大小。提高分辨率会进一步提高质量,也会加大模型尺寸。
所有TensoRF模型都可以实现非常快速的重建。除了最大的VM模型之外,其他都在不到30分钟内完成重建,明显优于其他方法。
优化步数
使用不同优化步数进一步评估本文方法,来获得具有
30
0
3
300^3
3003体素下的最佳CP和VM模型。
表3里是重建结果的PSNR和重建时间。这里的所有模型都是优化步数越多,实现的渲染质量越高。紧凑型CP-384甚至可以在60K步之后实现>32的PSNR,高于表1中所有先前方法。VM模型可以通过很少的步骤快速实现高渲染质量,只要15K步,许多模型就实现了达到最先进水平的高PSNR。

360°场景对比
将本文方法和最先进的视图合成方法进行比较,包括:SRN、NeRF、NSVF、SNeRG、PlenOctrees、Plenoxels、DVGO。本文方法使用了最佳CP模型和具有48和128个分量的 30 0 3 300^3 3003体素的VM模型和它们进行比较。还展示了用球谐着色函数的192分量的VM模型。表1展示了在三个具有挑战性的数据集上的定量结果对比。其中显示了模型对应的batchsize、优化步数、时间和模型大小。
本文所有模型在所有三个数据集上都优于NeRF,同时大大减少优化时间和步骤。其中最好的VM-192模型甚至可以在所有数据集上实现最佳的PSNR和SSIM。本文方法还可以实现更高质量的渲染、具有更多的外观和几何细节以及更少的异常值(图4)。

本文模型更高效,所有模型都需要不到75MB的空间,并在30分钟内重建。和NeRF需要约1.5天的优化时间相比,相当于超过70倍的速度。本文的CP模型比NeRF更紧凑。
SNeRG和PlenOctrees模型需要预训练类似于NeRF的MLP,同样需要很长的重建时间。
DVGO和Plenoxels是同期工作,也可以实现小于15分钟的快速重建。但是这两种方法都是基于体素的方法并直接优化体素值,因此会导致模型尺寸巨大,就像之前的基于体素的方法(SNeRG和PlenOctrees)。
相比之下,本文分解特征网络并使用紧凑的向量和矩阵进行建模,使得模型尺寸显著减小。其中VM-192模型甚至比DVGO和Plenoxels更快地重建,只要15K步,并在大多数情况下实现更好的质量。事实上Plenoxels的快速重建依赖于CUDA实现快速优化更多的步数(比本文>4倍)。本文通过pytorch实现,话费的重建时间和Plenoxels相当甚至更少。本文的SH模型本质上表示和Plenoxels相同的底层特征网格,但仍然可以通过更少的步骤实现更紧凑的建模和更好的质量,显示出基于分解的建模的优势。通常地,本文方法可以同时实现快速重建、紧凑建模和照片级真实感渲染。
前向场景
本文方法还可以实现前向场景的高效高质量的辐射场重建。在LLFF是聚集上展示了两个VM模型的定量结果,和NeRF、Plenoxels进行了比较(表4)。
结论
本文提出一种用于高质量场景重建和渲染的新方法。提出了一种新颖的场景表示——TensoRF,利用张量分解技术将辐射场紧凑地建模和重建为因式分解的低秩张量分量。虽然TensoRF适应经典的张量分解技术(如CP分解),本文引入了一种新的向量矩阵分解,可以带来更好的重建质量和更快的优化速度。方法可以在每个场景用<30min的时间实现高效重建,和(>20h的)NeRF相比可以实现更好的渲染质量。此外,基于张量分解的方法实现了高度紧凑型,内存占用远小于许多其他基于体素网格的方法。
附加材料
A. TensoRF表示细节
图5说明了张量辐射场的特征网格和张量因子(CP和VM分解)。

component数量
张量分类总数 #Comp:
- TensoRF-CP: ( R σ + R c R_\sigma+R_c Rσ+Rc)
- TensoRF-VM: 3(
R
σ
+
R
c
R_\sigma+R_c
Rσ+Rc)(因为VM具有三种类型的分量)
所有用于CP的R是用于VM的3倍,来实现表2中所示的相同数量的分量。
实验还发现,当
R
σ
R_\sigma
Rσ足够大(>8)时,使用
R
σ
<
R
c
R_\sigma<R_c
Rσ<Rc通常比
R
σ
=
R
c
R_\sigma=R_c
Rσ=Rc更好。
特别是对于TensoRF-VM:
#Comp=48时:
R
σ
=
R
c
=
8
R_\sigma=R_c=8
Rσ=Rc=8
#Comp=96时:
R
σ
=
8
,
R
c
=
24
R_\sigma=8, R_c=24
Rσ=8,Rc=24
#Comp=192时:
R
σ
=
16
,
R
c
=
48
R_\sigma=16, R_c=48
Rσ=16,Rc=48
#Comp=384时:
R
σ
=
32
,
R
c
=
96
R_\sigma=32, R_c=96
Rσ=32,Rc=96
这里假设XYZ三个空间维度同样复杂,使用R1=R2=R3=R.
前向的设置
对于所有360°对象数据集使用 R1=R2=R3 的设置。对于前向场景,在三个维度上显然不同。尤其是在NDC空间,X和Y空间模式包含更多的外观信息,这些信息可在渲染视点可见。因此对X-Y平面使用更多的分量,对应于
A
Z
=
v
Z
◦
M
X
,
Y
A^Z=v^Z◦M^{X,Y}
AZ=vZ◦MX,Y。在这种情况下,这些
A
Z
A^Z
AZ 分量也可以看做是神经MPIs的特殊压缩版本。
表4中使用的值:
#Comp=48: Rσ,1 = Rσ,2 = 4, Rσ,2 =16, Rc,1 = Rc,2 = 4, Rc,2 = 16;
#Comp=96: Rσ,1 = Rσ,2 = 4, Rσ,2 = 16, Rc,1 = Rc,2 = 16, Rc,48 = 16.
(?这里没看懂)
B. 更多实现细节
损失函数
如4.4节所述,我们应用了L2渲染损失和附加正则化项来优化辐射场重建的张量因子,损失函数表示为:
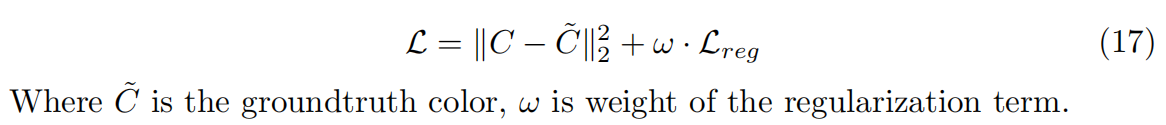
为了鼓励张量因子参数的稀疏性,应用了标准L1正则化,我们发现这可以有效提高外部视图质量并消除最终渲染中的异常值。注意,和之前使用Cauchy损失或熵损失不同,这里的L1正则化器简单得多,并且直接应用于张量因子的参数。仅将L1稀疏性损失应用于密度参数就足够了:

其中后面两项是所有元素的绝对值之和,N是参数总数,
N
=
R
σ
(
I
⋅
J
+
I
⋅
K
+
J
⋅
K
+
I
+
J
+
K
)
N=R_\sigma(I · J +I · K +J · K +I +J + K)
N=Rσ(I⋅J+I⋅K+J⋅K+I+J+K)。
我们对合成NeRF和合成NSVF数据集使用 ω = 0.0004 的 L1稀疏性损失。表5是对L1损失的消融实验。
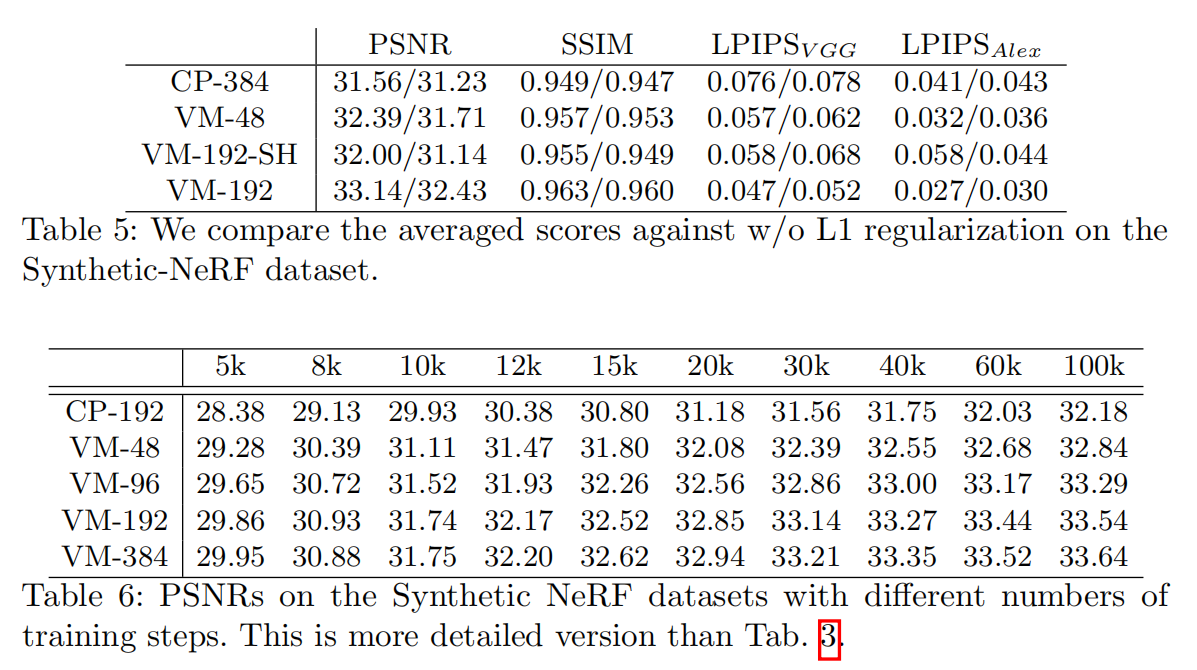
对于输入图像很少(比如LLFF)或捕获条件不完美的真实数据集,我们发现使用TV loss比L1稀疏损失更有效:
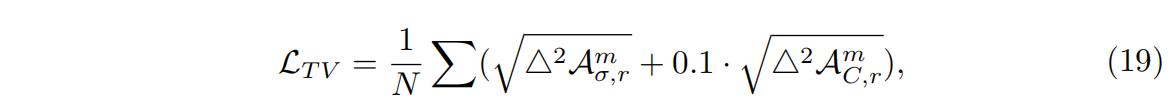
这里的
△
2
△^2
△2是矩阵/向量因子中相邻值的平方差。我们对TV损失中的外观参数使用一个更小的权重(0.1)。当使用TV损失时ω = 1。
二值占用体积
为了便于重建,我们在2000和4000步时计算一个二值占用mask网格,由中间模型预测出的体积密度来计算,来避免在空白空间中进行计算。
对于不提供边界框的数据集,我们从一个保守的大框开始,利用在2000步计算的占用mask来重新计算更紧凑的边界框,用它来缩小和重新采样张量因子,从而获得更精确的结果。
对于LLFF数据集中的前向场景,应用NDC变换将场景限制在透射锥上。
更多细节
如第2节所述,图5所示,使用隐藏层中有128个通道的小型两层MLP作为神经解码函数。
该MLP的输入包含观察方向和由张量因子恢复的特征(不使用XYZ位置)。
和NeRF/NSVF类似,TensoRF也在观察方向和特征上应用频率编码(sin cos函数)。但不像NeRF使用10个频率,这里只用2个。
优化过程中,还应用了指数学习率衰减,来让重建完成时优化更稳定。具体的,在每个训练步骤中都会衰减初始学习率,直到优化结束时衰减0.1倍。
C. 更多验证
表5,表6的消融实验。
D. 讨论
事实上,密集特征网格表示的重建问题相对来说是过度参数化/欠确定的。例如,具有27通道的
30
0
3
300^3
3003网格有>700M的参数,而100个800*800的图像仅提供64M的像素用于监督。因此许多设计选择——包括修剪空像素,从粗到精重建和添加额外损失,这些都在TensoRF和同期其他工作中类似地使用——本质上都是在减少或约束参数空间和避免过拟合。
一般来说,低秩正则化对于解决许多重建问题至关重要,例如矩阵补全、压缩感知、去噪;张量分解也被广泛应用于tensor completion,和我们的任务类似。张量分解自然提供了低秩约束并减少了参数。同样也有利于辐射场重建。
此外,TensoRF代表了5D辐射场函数,可以表达场景几何形状和外观;所以,我们相信4D张量通常是低秩的,因为3D场景通常包含许多不同位置的相似几何结构和材料属性。
注意,在各种外观采集任务中,类似的低秩约束已经成功应用于重建其他函数,包括重照明中的4D光传输函数和材料重建中的6D SVBRDF函数(其中常见的想法是对一组稀疏的基础BRDF进行建模,这类似于我们对矩阵B中的特征维度中的向量分量进行建模)。我们从一个新颖的角度将低秩约束和神经网络结合起来,进行基于张量的辐射场重建。TensoRF本质上是使用全局基础分量对场景进行建模,发现跨空间和特征维度的场景几何形状和外观共性。
E. 局限性和未来工作
本文方法实现了360°物体和前向场景的高质量辐射场重建;然而,目前仅支持具有单个边界框的有界场景,并且无法处理具有前景和背景内容的无界场景。
将本文方法和NeRF++等技术相结合,分别对常规框内的前景场和在球面坐标空间中定义的另一个框内的背景场进行建模,可以潜在地拓展本文方法,解决无界场景。尽管本文在单个场景优化方面取得了成功,但未来一个有趣的方向是在大规模数据集上发现和学习跨场景的一般性基础因子,利用数据先验进一步提高质量或启动其他应用比如GANs(如在GRAF/GIRRAF,EG3D中所做的。)
A u t h o r : C h i e r Author: Chier Author:Chier